Kubernetes 資源拓?fù)涓兄{(diào)度優(yōu)化
作者 | 騰訊星辰算力團(tuán)隊(duì)
1.背景
1.1 問題源起
近年來,隨著騰訊內(nèi)部自研上云項(xiàng)目的不斷發(fā)展,越來越多的業(yè)務(wù)開始使用云原生方式托管自己的工作負(fù)載,容器平臺(tái)的規(guī)模因此不斷增大。以 Kubernetes 為底座的云原生技術(shù)極大推動(dòng)了云原生領(lǐng)域的發(fā)展,已然成為各大容器平臺(tái)事實(shí)上的技術(shù)標(biāo)準(zhǔn)。在云原生場(chǎng)景下,為了最大化實(shí)現(xiàn)資源共享,單臺(tái)宿主機(jī)往往會(huì)運(yùn)行多個(gè)不同用戶的計(jì)算任務(wù)。如果在宿主機(jī)內(nèi)沒有進(jìn)行精細(xì)化的資源隔離,在業(yè)務(wù)負(fù)載高峰時(shí)間段,多個(gè)容器往往會(huì)對(duì)資源產(chǎn)生激烈的競(jìng)爭(zhēng),可能導(dǎo)致程序性能的急劇下降,主要體現(xiàn)為:
- 資源調(diào)度時(shí)頻繁的上下文切換時(shí)間
- 頻繁的進(jìn)程切換導(dǎo)致的 CPU 高速緩存失效
因此,在云原生場(chǎng)景下需要針對(duì)容器資源分配加以精細(xì)化的限制,確保在 CPU 利用率較高時(shí),各容器之間不會(huì)產(chǎn)生激烈競(jìng)爭(zhēng)從而引起性能下降。
1.2 調(diào)度場(chǎng)景
騰訊星辰算力平臺(tái)承載了全公司的 CPU 和 GPU 算力服務(wù),擁有著海量多類型的計(jì)算資源。當(dāng)前,平臺(tái)承載的多數(shù)重點(diǎn)服務(wù)偏離線場(chǎng)景,在業(yè)務(wù)日益增長(zhǎng)的算力需求下,提供源源不斷的低成本資源,持續(xù)提升可用性、服務(wù)質(zhì)量、調(diào)度能力,覆蓋更多的業(yè)務(wù)場(chǎng)景。然而,Kubernetes 原生的調(diào)度與資源綁定功能已經(jīng)無法滿足復(fù)雜的算力場(chǎng)景,亟需對(duì)資源進(jìn)行更加精細(xì)化的調(diào)度,主要體現(xiàn)為:
(1)Kubernetes 原生調(diào)度器無法感知節(jié)點(diǎn)資源拓?fù)湫畔?dǎo)致 Pod 生產(chǎn)失敗
kube-scheduler 在調(diào)度過程中并不感知節(jié)點(diǎn)的資源拓?fù)洌?dāng) kube-scheduler 將 Pod 調(diào)度到某個(gè)節(jié)點(diǎn)后,kubelet 如果發(fā)現(xiàn)節(jié)點(diǎn)的資源拓?fù)溆H和性要求無法滿足時(shí),會(huì)拒絕生產(chǎn)該 Pod,當(dāng)通過外部控制環(huán)(如 deployment)來部署 Pod 時(shí),則會(huì)導(dǎo)致 Pod 被反復(fù)創(chuàng)建-->調(diào)度-->生產(chǎn)失敗的死循環(huán)。
(2)基于離線虛擬機(jī)的混部方案導(dǎo)致的節(jié)點(diǎn)實(shí)際可用 CPU 核心數(shù)變化
面對(duì)運(yùn)行在線業(yè)務(wù)的云主機(jī)平均利用率較低的現(xiàn)實(shí),為充分利用空閑資源,可將離線虛擬機(jī)和在線虛擬機(jī)混合部署,解決公司離線計(jì)算需求,提升自研上云資源平均利用率。在保證離線不干擾在線業(yè)務(wù)的情況下,騰訊星辰算力基于自研內(nèi)核調(diào)度器 VMF 的支持,可以將一臺(tái)機(jī)器上的閑時(shí)資源充分利用起來,生產(chǎn)低優(yōu)先級(jí)的離線虛擬機(jī)。由于 VMF 的不公平調(diào)度策略,離線虛擬機(jī)的實(shí)際可用核心數(shù)受到在線虛擬機(jī)的影響,隨著在線業(yè)務(wù)的繁忙程度不斷變化。因此,kubelet 通過 cadvisor 在離線宿主機(jī)內(nèi)部采集到的 CPU 核心數(shù)并不準(zhǔn)確,導(dǎo)致了調(diào)度信息出現(xiàn)偏差。

cvm-architecture
(3)資源的高效利用需要更加精細(xì)化的調(diào)度粒度
kube-scheduler 的職責(zé)是為 Pod 選擇一個(gè)合適的 Node 完成一次調(diào)度。然而,想對(duì)資源進(jìn)行更高效的利用,原生調(diào)度器的功能還遠(yuǎn)遠(yuǎn)不夠。在調(diào)度時(shí),我們希望調(diào)度器能夠進(jìn)行更細(xì)粒度的調(diào)度,比如能夠感知到 CPU 核心、GPU 拓?fù)洹⒕W(wǎng)絡(luò)拓?fù)涞鹊龋沟觅Y源利用方式更加合理。
2.預(yù)備知識(shí)
2.1 cgroups 之 cpuset 子系統(tǒng)
cgroups 是 Linux 內(nèi)核提供的一種可以限制單個(gè)進(jìn)程或者多個(gè)進(jìn)程所使用資源的機(jī)制,可以對(duì) CPU、內(nèi)存等資源實(shí)現(xiàn)精細(xì)化的控制。Linux 下的容器技術(shù)主要通過 cgroups 來實(shí)現(xiàn)資源控制。
在 cgroups 中,cpuset 子系統(tǒng)可以為 cgroups 中的進(jìn)程分配獨(dú)立的 CPU 和內(nèi)存節(jié)點(diǎn)。通過將 CPU 核心編號(hào)寫入 cpuset 子系統(tǒng)中的 cpuset.cpus文件中或?qū)?nèi)存 NUMA 編號(hào)寫入 cpuset.mems文件中,可以限制一個(gè)或一組進(jìn)程只使用特定的 CPU 或者內(nèi)存。
幸運(yùn)的是,在容器的資源限制中,我們不需要手動(dòng)操作 cpuset 子系統(tǒng)。通過連接容器運(yùn)行時(shí)(CRI)提供的接口,可以直接更新容器的資源限制。
// ContainerManager contains methods to manipulate containers managed by a
// container runtime. The methods are thread-safe.
type ContainerManager interface {
// ......
// UpdateContainerResources updates the cgroup resources for the container.
UpdateContainerResources(containerID string, resources *runtimeapi.LinuxContainerResources) error
// ......
}
2.2 NUMA 架構(gòu)
非統(tǒng)一內(nèi)存訪問架構(gòu)(英語:Non-uniform memory access,簡(jiǎn)稱 NUMA)是一種為多處理器的電腦設(shè)計(jì)的內(nèi)存架構(gòu),內(nèi)存訪問時(shí)間取決于內(nèi)存相對(duì)于處理器的位置。在 NUMA 下,處理器訪問它自己的本地內(nèi)存的速度比非本地內(nèi)存(內(nèi)存位于另一個(gè)處理器,或者是處理器之間共享的內(nèi)存)快一些。現(xiàn)代多核服務(wù)器大多采用 NUMA 架構(gòu)來提高硬件的可伸縮性。

numa-architecture
從圖中可以看出,每個(gè) NUMA Node 有獨(dú)立的 CPU 核心、L3 cache 和內(nèi)存,NUMA Node 之間相互連接。相同 NUMA Node 上的 CPU 可以共享 L3 cache,同時(shí)訪問本 NUMA Node 上的內(nèi)存速度更快,跨 NUMA Node 訪問內(nèi)存會(huì)更慢。因此,我們應(yīng)當(dāng)為 CPU 密集型應(yīng)用分配同一個(gè) NUMA Node 的 CPU 核心,確保程序的局部性能得到充分滿足。
2.3 Kubernetes 調(diào)度框架
Kubernetes 自 v1.19 開始正式穩(wěn)定支持調(diào)度框架,調(diào)度框架是面向 Kubernetes 調(diào)度器的一種插件架構(gòu),它為現(xiàn)有的調(diào)度器添加了一組新的“插件”API,插件會(huì)被編譯到調(diào)度器之中。這為我們自定義調(diào)度器帶來了福音。我們可以無需修改 kube-scheduler 的源代碼,通過實(shí)現(xiàn)不同的調(diào)度插件,將插件代碼與 kube-scheduler 編譯為同一個(gè)可執(zhí)行文件中,從而開發(fā)出自定義的擴(kuò)展調(diào)度器。這樣的靈活性擴(kuò)展方便我們開發(fā)與配置各類調(diào)度器插件,同時(shí)無需修改 kube-scheduler 的源代碼的方式使得擴(kuò)展調(diào)度器可以快速更改依賴,更新到最新的社區(qū)版本。

scheduling-framework-extensions
調(diào)度器的主要擴(kuò)展點(diǎn)如上圖所示。我們擴(kuò)展的調(diào)度器主要關(guān)心以下幾個(gè)步驟:
(1)PreFilter 和 Filter
這兩個(gè)插件用于過濾出不能運(yùn)行該 Pod 的節(jié)點(diǎn),如果任何 Filter 插件將節(jié)點(diǎn)標(biāo)記為不可行,該節(jié)點(diǎn)都不會(huì)進(jìn)入候選集合,繼續(xù)后面的調(diào)度流程。
(2)PreScore、Score 和 NormalizeScore
這三個(gè)插件用于對(duì)通過過濾階段的節(jié)點(diǎn)進(jìn)行排序,調(diào)度器將為每個(gè)節(jié)點(diǎn)調(diào)用每個(gè)評(píng)分插件,最終評(píng)分最高的節(jié)點(diǎn)將會(huì)作為最終調(diào)度結(jié)果被選中。
(3)Reserve 和 Unreserve
這個(gè)插件用于在 Pod 真正被綁定到節(jié)點(diǎn)之前,對(duì)資源做一些預(yù)留工作,保證調(diào)度的一致性。如果綁定失敗則通過 Unreserve 來釋放預(yù)留的資源。
(4)Bind
這個(gè)插件用于將 Pod 綁定到節(jié)點(diǎn)上。默認(rèn)的綁定插件只是為節(jié)點(diǎn)指定 spec.nodeName 來完成調(diào)度,如果我們需要擴(kuò)展調(diào)度器,加上其他的調(diào)度結(jié)果信息,就需要禁用默認(rèn) Bind 插件,替換為自定義的 Bind 插件。
3.國內(nèi)外技術(shù)研究現(xiàn)狀
目前 Kubernetes 社區(qū)、Volcano 開源社區(qū)均有關(guān)于拓?fù)涓兄嚓P(guān)的解決方案,各方案有部分相同之處,但各自都有局限性,無法滿足星辰算力的復(fù)雜場(chǎng)景。
3.1 Kubernetes 社區(qū)
Kubernetes 社區(qū) scheduling 興趣小組針對(duì)拓?fù)涓兄{(diào)度也有過一套解決方案,這個(gè)方案主要是由 RedHat 來主導(dǎo),通過scheduler-plugins和node-feature-discovery配合實(shí)現(xiàn)了考慮節(jié)點(diǎn)拓?fù)涞恼{(diào)度方法。社區(qū)的方法僅僅考慮節(jié)點(diǎn)是否能夠在滿足 kubelet 配置要求的情況下,完成調(diào)度節(jié)點(diǎn)篩選和打分,并不會(huì)執(zhí)行綁核,綁核操作仍然交給 kubelet 來完成,相關(guān)提案在這里。具體實(shí)現(xiàn)方案如下:
- 節(jié)點(diǎn)上的 nfd-topology-updater 通過 gRPC 上報(bào)節(jié)點(diǎn)拓?fù)涞?nfd-master 中(周期 60s)。
- nfd-master 更新節(jié)點(diǎn)拓?fù)渑c分配情況到 CR 中(NodeResourceTopology)。
- 擴(kuò)展 kube-scheduler,進(jìn)行調(diào)度時(shí)考慮 NodeTopology。
- 節(jié)點(diǎn) kubelet 完成綁核工作。
該方案存在較多的問題,不能解決生產(chǎn)實(shí)踐中的需求:
- 具體核心分配依賴 kubelet 完成,因此調(diào)度器只會(huì)考慮資源拓?fù)湫畔ⅲ⒉粫?huì)選擇拓?fù)洌{(diào)度器沒有資源預(yù)留。這導(dǎo)致了節(jié)點(diǎn)調(diào)度與拓?fù)湔{(diào)度不在同一個(gè)環(huán)節(jié),會(huì)引起數(shù)據(jù)不一致問題。
- 由于具體核心分配依賴 kubelet 完成,所以已調(diào)度 Pod 的拓?fù)湫畔⑿枰揽?nfd-worker 每隔 60s 匯報(bào)一次,導(dǎo)致拓?fù)浒l(fā)現(xiàn)過慢因此使得數(shù)據(jù)不一致問題更加嚴(yán)重,參見這里。
- 沒有區(qū)分需要拓?fù)溆H和的 pod 和普通的 pod,容易造成開啟拓?fù)涔δ艿墓?jié)點(diǎn)高優(yōu)資源浪費(fèi)。
3.2 Volcano 社區(qū)
Volcano 是在 Kubernetes 上運(yùn)行高性能工作負(fù)載的容器批量計(jì)算引擎,隸屬于 CNCF 孵化項(xiàng)目。在 v1.4.0-Beta 版本中進(jìn)行了增強(qiáng),發(fā)布了有關(guān) NUMA 感知的特性。與 Kubernetes 社區(qū) scheduling 興趣小組的實(shí)現(xiàn)方式類似,真正的綁核并未單獨(dú)實(shí)現(xiàn),直接采用的是 kubelet 自帶的功能。具體實(shí)現(xiàn)方案如下:
- resource-exporter 是部署在每個(gè)節(jié)點(diǎn)上的 DaemonSet,負(fù)責(zé)節(jié)點(diǎn)的拓?fù)湫畔⒉杉⒐?jié)點(diǎn)信息寫入 CR中(Numatopology)。
- Volcano 根據(jù)節(jié)點(diǎn)的 Numatopology,在調(diào)度 Pod 時(shí)進(jìn)行 NUMA 調(diào)度感知。
- 節(jié)點(diǎn) kubelet 完成綁核工作。
該方案存在的問題基本與 Kubernetes 社區(qū) scheduling 興趣小組的實(shí)現(xiàn)方式類似,具體核心分配依賴 kubelet
完成。雖然調(diào)度器盡力保持與 kubelet 一致,但因?yàn)闊o法做資源預(yù)留,仍然會(huì)出現(xiàn)不一致的問題,在高并發(fā)場(chǎng)景下尤其明顯。
3.3 小結(jié)
基于國內(nèi)外研究現(xiàn)狀的結(jié)果進(jìn)行分析,開源社區(qū)在節(jié)點(diǎn)資源綁定方面還是希望交給 kubelet,調(diào)度器盡量保證與 kubelet 的一致,可以理解這比較符合社區(qū)的方向。因此,目前各個(gè)方案的典型實(shí)現(xiàn)都不完美,無法滿足騰訊星辰算力的要求,在復(fù)雜的生產(chǎn)環(huán)境中我們需要一套更加穩(wěn)健、擴(kuò)展性更好的方案。因此,我們決定從各個(gè)方案的架構(gòu)優(yōu)點(diǎn)出發(fā),探索出一套更加強(qiáng)大的、貼合騰訊星辰算力實(shí)際場(chǎng)景的資源精細(xì)化調(diào)度增強(qiáng)方案。
4.問題分析
4.1 離線虛擬機(jī)節(jié)點(diǎn)實(shí)際可用 CPU 核心數(shù)變化
從 1.2 節(jié)中我們可以知道,騰訊星辰算力使用了基于離線虛擬機(jī)的混部方案,節(jié)點(diǎn)實(shí)際的 CPU 可用核心數(shù)會(huì)收到在線業(yè)務(wù)的峰值影響從而變化。因此,kubelet 通過 cadvisor 在離線宿主機(jī)內(nèi)部采集到的 CPU 核心數(shù)并不準(zhǔn)確,這個(gè)數(shù)值是一個(gè)固定值。因此,針對(duì)離線資源我們需要調(diào)度器通過其他的方式來獲取節(jié)點(diǎn)的實(shí)際算力。

cvm
目前調(diào)度和綁核都不能到離線虛擬機(jī)的實(shí)際算力,導(dǎo)致任務(wù)綁定到在線干擾比較嚴(yán)重的 NUMA node,資源競(jìng)爭(zhēng)非常嚴(yán)重使得任務(wù)的性能下降。

cvm-2
幸運(yùn)的是,我們?cè)谖锢頇C(jī)上可以采集到離線虛擬機(jī)每個(gè) NUMA node 上實(shí)際可用的 CPU 資源比例,通過折損公式計(jì)算出離線虛擬機(jī)的實(shí)際算力。接下來就只需要讓調(diào)度器在調(diào)度時(shí)能夠感知到 CPU 拓?fù)湟约皩?shí)際算力,從而進(jìn)行分配。
4.2 精細(xì)化調(diào)度需要更強(qiáng)的靈活性
通過 kubelet 自帶的 cpumanager 進(jìn)行綁核總是會(huì)對(duì)該節(jié)點(diǎn)上的所有 Pod 均生效。只要 Pod 滿足 Guaranteed 的 QoS 條件,且 CPU 請(qǐng)求值為整數(shù),都會(huì)進(jìn)行綁核。然而,有些 Pod 并不是高負(fù)載類型卻獨(dú)占 CPU,這種方式的方式很容易造成開啟拓?fù)涔δ艿墓?jié)點(diǎn)高優(yōu)資源浪費(fèi)。
同時(shí),對(duì)于不同資源類型的節(jié)點(diǎn),其拓?fù)涓兄囊笠彩遣灰粯拥摹@纾浅剿懔Φ馁Y源池中也含有較多碎片虛擬機(jī),這部分節(jié)點(diǎn)不是混部方式生產(chǎn)出來的,相比而言資源穩(wěn)定,但是規(guī)格很小(如 8 核 CVM,每個(gè) NUMA Node 有 4 核)。由于大多數(shù)任務(wù)規(guī)格都會(huì)超過 4 核,這類資源就在使用過程中就可以跨 NUMA Node 進(jìn)行分配,否則很難匹配。
因此,拓?fù)涓兄{(diào)度需要更強(qiáng)的靈活性,適應(yīng)各種核心分配與拓?fù)涓兄獔?chǎng)景。
4.3 調(diào)度方案需要更強(qiáng)的擴(kuò)展性
調(diào)度器在抽象拓?fù)滟Y源時(shí),需要考慮擴(kuò)展性。對(duì)于今后可能會(huì)需要調(diào)度的擴(kuò)展資源,如各類異構(gòu)資源的調(diào)度,也能夠在這套方案中輕松使用,而不僅僅是 cgroups 子系統(tǒng)中含有的資源。
4.4 避免超線程帶來的 CPU 競(jìng)爭(zhēng)問題
在 CPU 核心競(jìng)爭(zhēng)較為激烈時(shí),超線程可能會(huì)帶來更差的性能。更加理想的分配方式是將一個(gè)邏輯核分配給高負(fù)載應(yīng)用,另一個(gè)邏輯核分配給不繁忙的應(yīng)用,或者是將兩個(gè)峰谷時(shí)刻相反的應(yīng)用分配到同一個(gè)物理核心上。同時(shí),我們避免將同一個(gè)應(yīng)用分配到同一個(gè)物理核心的兩個(gè)邏輯核心上,這樣很可能造成 CPU 競(jìng)爭(zhēng)問題。
5.解決方案
為了充分解決上述問題,并考慮到未來的擴(kuò)展性,我們?cè)O(shè)計(jì)了一套精細(xì)化調(diào)度的方案,命名為 cassini。整套解決方案包含三個(gè)組件和一個(gè) CRD,共同配合完成資源精細(xì)化調(diào)度的工作。
注:cassini這個(gè)名稱來源于知名的土星探測(cè)器卡西尼-惠更斯號(hào),對(duì)土星進(jìn)行了精準(zhǔn)無誤的探測(cè),借此名來象征更加精準(zhǔn)的拓?fù)浒l(fā)現(xiàn)與調(diào)度。
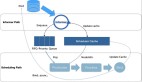
5.1 總體架構(gòu)

solution
各模塊職責(zé)如下:
- cassini-master:從外部系統(tǒng)負(fù)責(zé)收集節(jié)點(diǎn)特性(如節(jié)點(diǎn)的 offline_capacity,節(jié)點(diǎn)電力情況),作為 controller 采用
Deployment 方式運(yùn)行。 - scheduler-plugins:新增調(diào)度插件的擴(kuò)展調(diào)度器替換原生調(diào)度器,在節(jié)點(diǎn)綁定的同時(shí)還會(huì)分配拓?fù)湔{(diào)度結(jié)果,作為靜態(tài) Pod 在每個(gè) master 節(jié)點(diǎn)上運(yùn)行。
調(diào)度整體流程如下:
(1)cassini-worker啟動(dòng),收集節(jié)點(diǎn)上的拓?fù)滟Y源信息。
(2)創(chuàng)建或更新 NodeResourceTopology(NRT)類型的 CR 資源,用于記錄節(jié)點(diǎn)拓?fù)湫畔ⅰ?/p>
(3)讀取 kubelet 的 cpu_manager_state 文件,將已有容器的 kubelet 綁核結(jié)果 patch 到 Pod annotations 中。
(4)cassini-master 根據(jù)外部系統(tǒng)獲取到的信息來更新對(duì)應(yīng)節(jié)點(diǎn)的 NRT 對(duì)象。
(5)擴(kuò)展調(diào)度器 scheduler-plugins 執(zhí)行 Pod 調(diào)度,根據(jù) NRT 對(duì)象感知到節(jié)點(diǎn)的拓?fù)湫畔ⅲ{(diào)度 Pod 時(shí)將拓?fù)湔{(diào)度結(jié)構(gòu)寫到 Pod annotations 中。
(6)節(jié)點(diǎn) kubelet 監(jiān)聽并準(zhǔn)備啟動(dòng) Pod。
(7)節(jié)點(diǎn) kubelet 調(diào)用容器運(yùn)行時(shí)接口啟動(dòng)容器。
(8)cassini-worker 周期性地訪問 kubelet 的 10250 端口來 List 節(jié)點(diǎn)上的 Pod 并從 Pod annotations 中獲取調(diào)度器的拓?fù)湔{(diào)度結(jié)果。
(9)cassini-worker 調(diào)用容器運(yùn)行時(shí)接口來更改容器的綁核結(jié)果。
整體可以看出,cassini-worker 在節(jié)點(diǎn)上收集更詳細(xì)的資源拓?fù)湫畔ⅲ琧assini-master 從外部系統(tǒng)集中獲取節(jié)點(diǎn)資源的附加信息。scheduler-plugins 擴(kuò)展了原生調(diào)度器,以這些附加信息作為決策依據(jù)來進(jìn)行更加精細(xì)化的調(diào)度,并將結(jié)果寫到 Pod annotations 中。最終,cassini-worker 又承擔(dān)了執(zhí)行者的職責(zé),負(fù)責(zé)落實(shí)調(diào)度器的資源拓?fù)湔{(diào)度結(jié)果。
5.2 API 設(shè)計(jì)
NodeResourceTopology(NRT)是用于抽象化描述節(jié)點(diǎn)資源拓?fù)湫畔⒌?Kubernetes CRD,這里主要參考了 Kubernetes
社區(qū) scheduling 興趣小組的設(shè)計(jì)。每一個(gè) Zone 用于描述一個(gè)抽象的拓?fù)鋮^(qū)域,ZoneType 來描述其類型,ResourceInfo 來描述 Zone 內(nèi)的資源總量。
// Zone represents a resource topology zone, e.g. socket, node, die or core.
type Zone struct {
// Name represents the zone name.
// +required
Name string `json:"name" protobuf:"bytes,1,opt,name=name"`
// Type represents the zone type.
// +kubebuilder:validation:Enum=Node;Socket;Core
// +required
Type ZoneType `json:"type" protobuf:"bytes,2,opt,name=type"`
// Parent represents the name of parent zone.
// +optional
Parent string `json:"parent,omitempty" protobuf:"bytes,3,opt,name=parent"`
// Costs represents the cost between different zones.
// +optional
Costs CostList `json:"costs,omitempty" protobuf:"bytes,4,rep,name=costs"`
// Attributes represents zone attributes if any.
// +optional
Attributes map[string]string `json:"attributes,omitempty" protobuf:"bytes,5,rep,name=attributes"`
// Resources represents the resource info of the zone.
// +optional
Resources *ResourceInfo `json:"resources,omitempty" protobuf:"bytes,6,rep,name=resources"`
}
注意到,為了更強(qiáng)的擴(kuò)展性,每個(gè) Zone 內(nèi)加上了一個(gè) Attributes 來描述 Zone 上的自定義屬性。如 4.1 節(jié)中所示,我們將采集到的離線虛擬機(jī)實(shí)際算力寫入到 Attributes 字段中,來描述每個(gè) NUMA Node 實(shí)際可用算力。
5.3 調(diào)度器設(shè)計(jì)

plugin擴(kuò)展調(diào)度器在原生調(diào)度器基礎(chǔ)上擴(kuò)展了新的插件,大體如下所示:
- Filter:讀取 NRT 資源,根據(jù)每個(gè)拓?fù)鋬?nèi)的實(shí)際可用算力以及 Pod 拓?fù)涓兄髞砗Y選節(jié)點(diǎn)并選擇拓?fù)洹?/li>
- Score:根據(jù) Zone 個(gè)數(shù)打分來打分,Zone 越多分越低(跨 Zone 會(huì)帶來性能損失)。
- Reserve:在真正綁定前做資源預(yù)留,避免數(shù)據(jù)不一致,kube-scheduler 的 cache 中也有類似的 assume 功能。
- Bind:禁用默認(rèn)的 Bind 插件,在 Bind 時(shí)加入 Zone 的選擇結(jié)果,附加在 annotations 中。
通過 TopologyMatch 插件使得調(diào)度器在調(diào)度時(shí)能夠考慮節(jié)點(diǎn)拓?fù)湫畔⒉⑦M(jìn)行拓?fù)浞峙洌⑼ㄟ^ Bind 插件將結(jié)果附加在 annotations 中。
值得一提的是,這里還額外實(shí)現(xiàn)了關(guān)于節(jié)點(diǎn)電力調(diào)度等更多維度調(diào)度的調(diào)度器插件,本篇中不作展開討論,感興趣的同學(xué)可以私戳我了解。
5.4 master 設(shè)計(jì)
cassini-master 是中控組件,從外部來采集一些節(jié)點(diǎn)上無法采集的資源信息。我們從物理上采集到離線虛擬機(jī)的實(shí)際可用算力,由 cassini-master 負(fù)責(zé)將這類結(jié)果附加到對(duì)應(yīng)節(jié)點(diǎn)的 NRT 資源中。該組件將統(tǒng)一資源收集的功能進(jìn)行了剝離,方便更新與擴(kuò)展。
5.5 worker 設(shè)計(jì)
cassini-worker 是一個(gè)較為復(fù)雜的組件,作為 DaemonSet 在每個(gè)節(jié)點(diǎn)上運(yùn)行。它的職責(zé)分兩部分:
(1)采集節(jié)點(diǎn)上的拓?fù)滟Y源。(2)執(zhí)行調(diào)度器的拓?fù)湔{(diào)度結(jié)果。
5.5.1 資源采集
資源拓?fù)洳杉饕峭ㄟ^從 /sys/devices下采集系統(tǒng)相關(guān)的硬件信息,并創(chuàng)建或更新到 NRT 資源中。該組件會(huì) watch 節(jié)點(diǎn) kubelet 的配置信息并上報(bào),讓調(diào)度器感知到節(jié)點(diǎn)的 kubelet 的綁核策略、預(yù)留資源等信息。
由于硬件信息幾乎不變化,默認(rèn)會(huì)較長(zhǎng)時(shí)間采集一次并更新。但 watch 配置的事件是實(shí)時(shí)的,一旦 kubelet 配置后會(huì)立刻感知到,方便調(diào)度器根據(jù)節(jié)點(diǎn)的配置進(jìn)行不同的決策。
5.5.2 拓?fù)湔{(diào)度結(jié)果執(zhí)行
拓?fù)湔{(diào)度結(jié)果執(zhí)行是通過周期性地 reconcile 來完成制定容器的拓?fù)浞峙洹?/p>
(1)獲取 Pod 信息
為了防止每個(gè)節(jié)點(diǎn)的 cassini-worker都 watch kube-apiserver 造成 kube-apiserver 的壓力,cassini-worker改用周期性訪問 kubelet 的 10250 端口的方式,來 List 節(jié)點(diǎn)上的 Pod 并從 Pod annotations 中獲取調(diào)度器的拓?fù)湔{(diào)度結(jié)果。同時(shí),從 status 中還可以獲取到每個(gè)容器的 ID 與狀態(tài),為拓?fù)滟Y源的分配創(chuàng)建了條件。
(2)記錄 kubelet 的 CPU 綁定信息
在 kubelet 開啟 CPU 核心綁定時(shí),擴(kuò)展調(diào)度器將會(huì)跳過所有的 TopologyMatch插件。此時(shí) Pod annotations 中不會(huì)包含拓?fù)湔{(diào)度結(jié)果。在 kubelet 為 Pod 完成 CPU 核心綁定后,會(huì)將結(jié)果記錄在 cpu_manager_state文件中,cassini-worker 讀取該文件,并將 kubelet 的綁定結(jié)果 patch 到 Pod annotations 中,供后續(xù)調(diào)度做判斷。
(3)記錄 CPU 綁定信息
根據(jù) cpu_manager_state文件,以及從 annotations 中獲取的 Pod 的拓?fù)湔{(diào)度結(jié)果,生成自己的 cassini_cpu_manager_state 文件,該文件記錄了節(jié)點(diǎn)上所有 Pod 的核心綁定結(jié)果。
(4)執(zhí)行拓?fù)浞峙?/strong>
根據(jù) cassini_cpu_manager_state 文件,調(diào)用容器運(yùn)行時(shí)接口,完成最終的容器核心綁定工作。
6.優(yōu)化結(jié)果
根據(jù)上述精細(xì)化調(diào)度方案,我們對(duì)一些線上的任務(wù)進(jìn)行了測(cè)試。此前,用戶反饋任務(wù)調(diào)度到一些節(jié)點(diǎn)后計(jì)算性能較差,且由于 steal_time升高被頻繁驅(qū)逐。在替換為拓?fù)涓兄{(diào)度的解決方案后,由于拓?fù)涓兄{(diào)度可以細(xì)粒度地感知到每個(gè) NUMA 節(jié)點(diǎn)的離線實(shí)際算力(offline_capacity),任務(wù)會(huì)被調(diào)度到合適的 NUMA 節(jié)點(diǎn)上,測(cè)試任務(wù)的訓(xùn)練速度可提升至原來的 3 倍,與業(yè)務(wù)在高優(yōu) CVM 的耗時(shí)相當(dāng),且訓(xùn)練速度較為穩(wěn)定,資源得到更合理地利用。
同時(shí),在使用原生調(diào)度器的情況下,調(diào)度器無法感知離線虛擬機(jī)的實(shí)際算力。當(dāng)任務(wù)調(diào)度到某個(gè)節(jié)點(diǎn)上后,該節(jié)點(diǎn)
steal_time會(huì)因此升高,任務(wù)無法忍受這樣的繁忙節(jié)點(diǎn)就會(huì)由驅(qū)逐器發(fā)起 Pod 的驅(qū)逐。在此情況下,如果采用原生調(diào)度器,將會(huì)引起反復(fù)驅(qū)逐然后反復(fù)調(diào)度的情況,導(dǎo)致 SLA 收到較大影響。經(jīng)過本文所述的解決方案后,可將 CPU 搶占的驅(qū)逐率大大下降至物理機(jī)水平。
7.總結(jié)與展望
本文從實(shí)際業(yè)務(wù)痛點(diǎn)出發(fā),首先簡(jiǎn)單介紹了騰訊星辰算力的業(yè)務(wù)場(chǎng)景與精細(xì)化調(diào)度相關(guān)的各類背景知識(shí),然后充分調(diào)研國內(nèi)外研究現(xiàn)狀,發(fā)現(xiàn)目前已有的各種解決方案都存在局限性。最后通過痛點(diǎn)問題分析后給出了相應(yīng)的解決方案。經(jīng)過優(yōu)化后,資源得到更合理地利用,原有測(cè)試任務(wù)的訓(xùn)練速度能提升至原來的 3 倍,CPU 搶占的驅(qū)逐率大大降低至物理機(jī)水平。
未來,精細(xì)化調(diào)度將會(huì)覆蓋更多的場(chǎng)景,包括在 GPU 虛擬化技術(shù)下對(duì) GPU 整卡、碎卡的調(diào)度,支持高性能網(wǎng)絡(luò)架構(gòu)的調(diào)度,電力資源的調(diào)度,支持超售場(chǎng)景,配合內(nèi)核調(diào)度共同完成等等。