高并發+海量數據下如何實現系統解耦?「下」

一、前情提示
上一篇文章《?高并發+海量數據下如何實現系統解耦?【中】?》分析了一下如何利用消息中間件對系統進行解耦處理。
同時,我們也提到了使用消息中間件還有利于一份數據被多個系統同時訂閱,供多個系統來使用于不同的目的。
目前的一個架構如下圖所示。
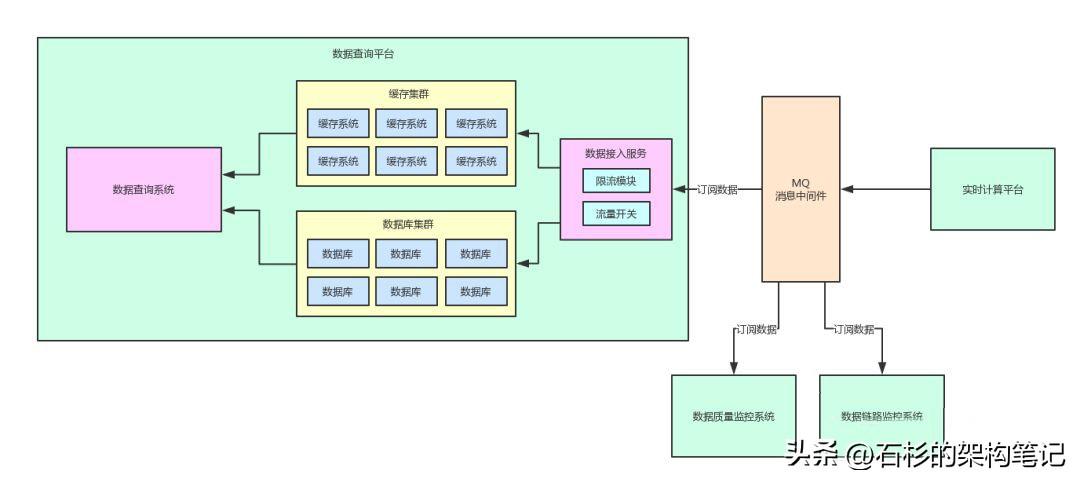
在這個圖里,我們可以清晰的看到,實時計算平臺發布的一份數據到消息中間件里,接著,會進行如下步驟:
- 數據查詢平臺,會訂閱這份數據,并落入自己本地的數據庫集群和緩存集群里,接著對外提供數據查詢的服務
- 數據質量監控系統,會對計算結果按照一定的業務規則進行監控,如果發現有數據計算錯誤,則會立馬進行報警
- 數據鏈路追蹤系統,會采集計算結果作為一個鏈路節點,同時對一條數據的整個完整計算鏈路都進行采集并組裝出來一系列的數據計算鏈路落地存儲,最后如果某個數據計算錯誤了,就可以立馬通過計算鏈路進行回溯排查問題
因此上述場景中,使用消息中間件一來可以解耦,二來還可以實現消息“Pub/Sub”模型,實現消息的發布與訂閱。
這篇文章,咱們就來看看,假如說基于RabbitMQ作為消息中間件,如何實現一份數據被多個系統同時訂閱的“Pub/Sub”模型。
二、基于消息中間件的隊列消費模型
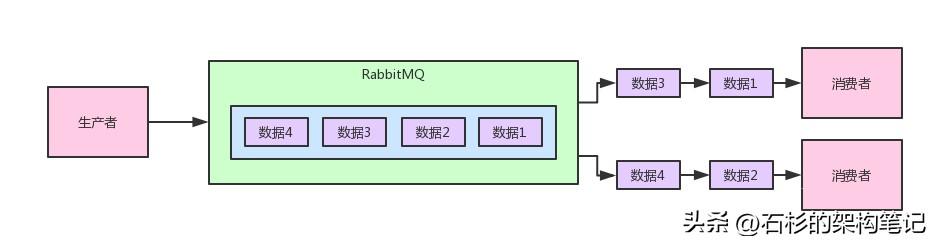
上面那個圖,其實就是采用的RabbitMQ最基本的隊列消費模型的支持。
也就是說,你可以理解為RabbitMQ內部有一個隊列,生產者不斷的發送數據到隊列里,消息按照先后順序進入隊列中排隊。
接著,假設隊列里有4條數據,然后我們有2個消費者一起消費這個隊列的數據。
此時每個消費者會均勻的被分配到2條數據,也就是說4條數據會均勻的分配給各個消費者,每個消費者只不過是處理一部分數據罷了,這個就是典型的隊列消費模型。
三、基于消息中間件的“Pub/Sub”模型
但是消息中間件還可以實現一種“Pub/Sub”模型,也就是“發布/訂閱”模型,Pub就是Publish,Sub就是Subscribe。
這種模型是可以支持多個系統同時消費一份數據的。也就是說,你發布出去的每條數據,都會廣播給每個系統。
給大家來一張圖,一起來感受一下。
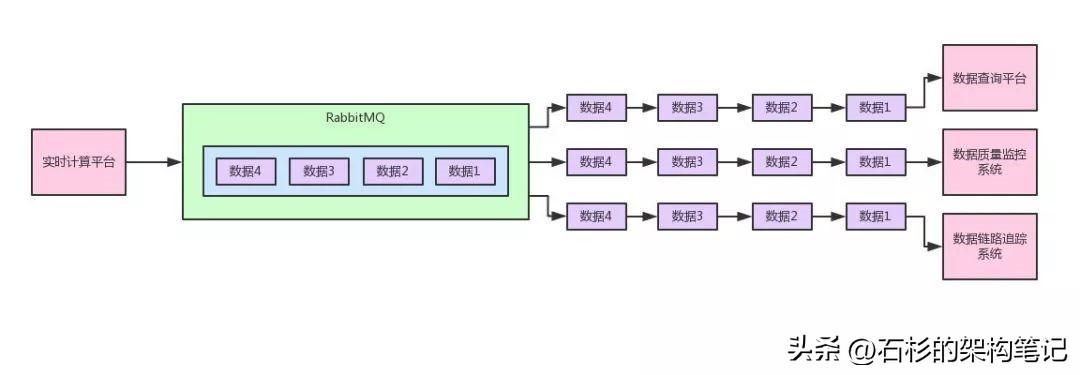
如上圖所示。也就是說,我們想要實現的上圖的效果,實時計算平臺發布一系列的數據到消息中間件里。
然后數據查詢平臺、數據質量監控系統、數據鏈路追蹤系統,都會訂閱數據,都會消費到同一份完整的數據,每個系統都可以根據自己的需要使用數據。
這,就是所謂的“Pub/Sub”模型,一個系統發布一份數據出去,多個系統訂閱和消費到一模一樣的一份數據。
那如果要實現上述的效果,基于RabbitMQ應該怎么來處理呢?
四、RabbitMQ中的exchange到底是個什么東西?
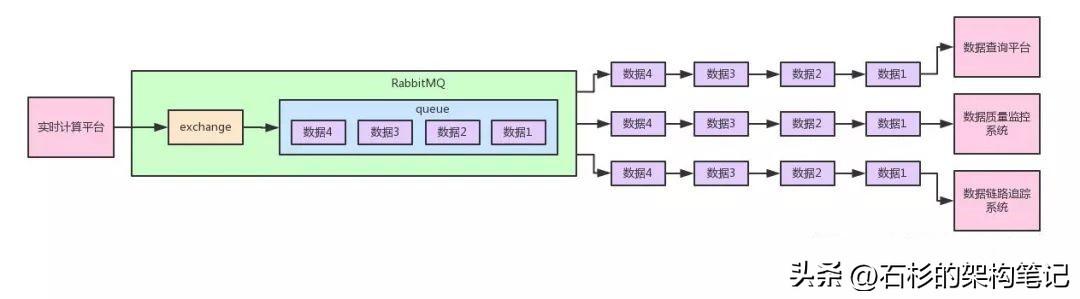
實際上來說,在RabbitMQ里面是不允許生產者直接投遞消息到某個queue(隊列)里的,而是只能讓生產者投遞消息給RabbitMQ內部的一個特殊組件,叫做“exchange”。
關于這個exchange,大概你可以把這個組件理解為一種消息路由的組件。
也就是說,實時計算平臺發送出去的message到RabbitMQ中都是由一個exchange來接收的。
然后這個exchange會根據一定的規則決定要將這個message路由轉發到哪個queue里去,這個實際上就是RabbitMQ中的一個核心的消息模型。
大家看下面的圖,一起來理解一下。
五、默認的exchange
在之前的文章里,我們投遞消息到RabbitMQ的時候,也沒有用什么exchange,但是為什么就還是把消息投遞到了queue里去呢?
那是因為我們用了默認的exchange,他會直接把消息路由到你指定的那個queue里去,所以如果簡單用隊列消費模型,不就省去了exchange的概念了嗎。
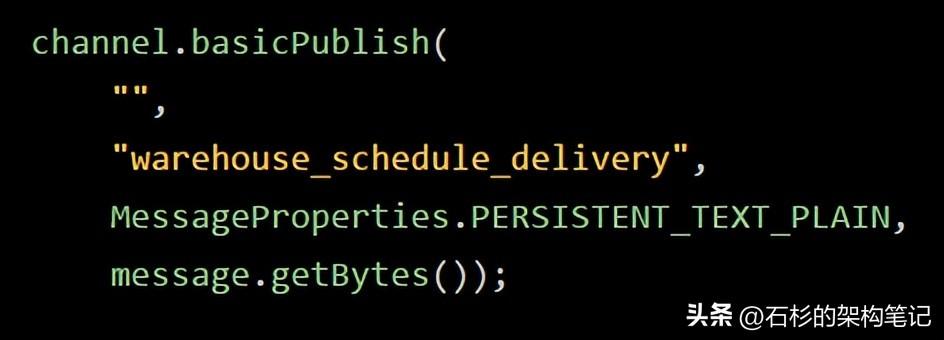
上面這段就是之前我們給大家展示的,讓消息持久化的一種投遞消息的方式。
大家注意里面的第一個參數,是一個空的字符串,這個空字符串的意思,就是說投遞消息到默認的exchange里去,然后他就會路由消息到我們指定的queue里去。
六、將消息投遞到fanout exchange
?在RabbitMQ里,exchange這種組件有很多種類型,比如說:direct、topic、headers以及fanout。這里咱們就來看看最后一種,fanout這種類型的exchange組件。
這種exchange組件其實非常的簡單,你可以創建一個fanout類型的exchange,然后給這個exchange綁定多個queue。
接著只要你投遞一條消息到這個exchange,他就會把消息路由給他綁定的所有queue。
使用下面的代碼就可以創建一個exchange,比如說在實時計算平臺(生產者)的代碼里,可以加入下面的一段,創建一個fanout類型的exchange。
第一個參數我們叫做“rt_compute_data”,這個就是exchange的名字,rt就是“RealTime”的縮寫,意思就是實時計算系統的計算結果數據。
第二個參數就是定義了這個exchange的類型是“fanout”。?
channel.exchangeDeclare(
"rt_compute_data",
"fanout");
接著我們就采用下面的代碼來投遞消息到我們創建好的exchange組件里去:
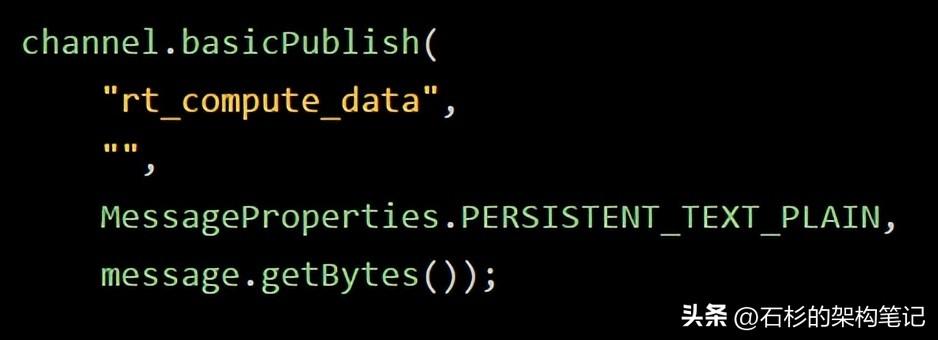
大家會注意到,此時消息就是投遞到指定的exchange里去了,但是路由到哪個queue里去呢?此時我們暫時還沒確定,要讓消費者自己來把自己的queue綁定到這個exchange上去才可以。
七、綁定自己的隊列到exchange上去消費
我們對消費者的代碼也進行修改,之前我們在這里關閉了autoAck機制,然后每次都是自己手動ack。
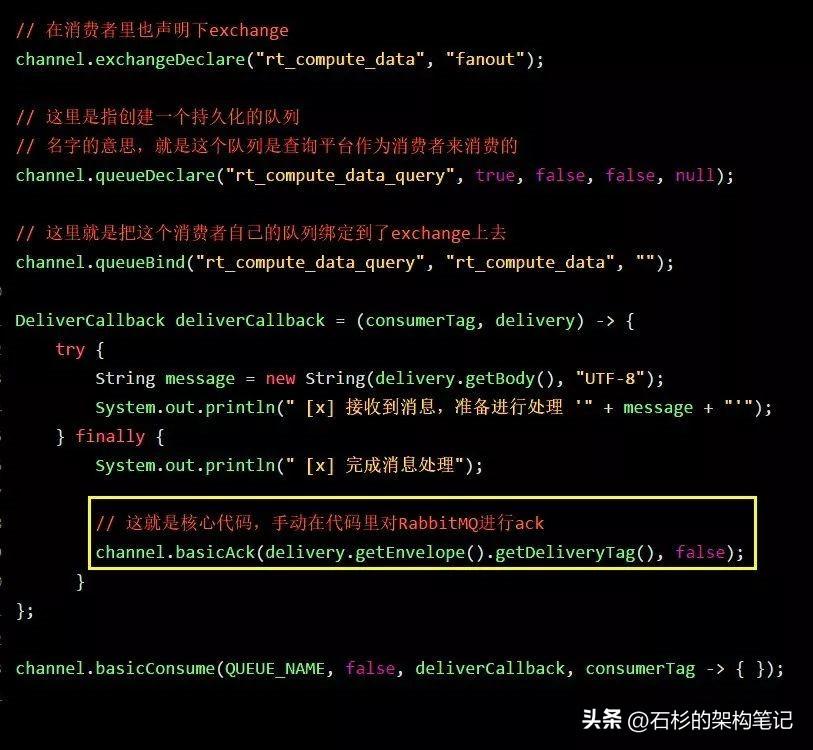
上面的代碼里,每個消費者系統,都會有一些不一樣,就是每個消費者都需要定義自己的隊列,然后綁定到exchange上去。比如:
- 數據查詢平臺的隊列是“rt_compute_data_query”。
- 數據質量監控平臺的隊列是“rt_compute_data_monitor”。
- 數據鏈路追蹤系統的隊列是“rt_compute_data_link”。
這樣,每個訂閱這份數據的系統其實都有一個屬于自己的隊列,然后隊列里被會被exchange路由進去實時計算平臺生產的所有數據。
而且因為是多個隊列的模式,每個系統都可以部署消費者集群來進行數據的消費和處理,非常的方便。
八、整體架構圖
最后,給大家來一張大圖,我們再跟著圖,來捋一捋整個流程。
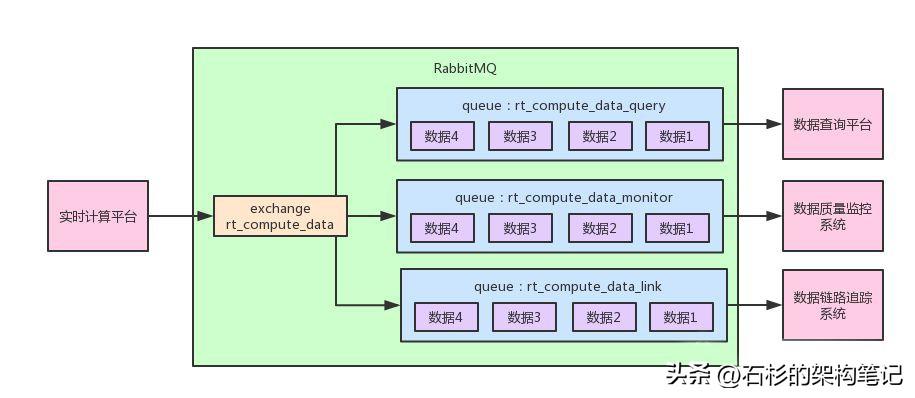
如上圖所示,首先,實時計算平臺會投遞消息到“rt_compute_data”這個“exchange”里去,但是他沒指定這個exchange要路由消息到哪個隊列,因為這個他本身是不知道的。
接著數據查詢平臺、數據質量監控系統、數據鏈路追蹤系統,就可以聲明自己的隊列,都綁定到exchange上去。
因為queue和exchange的綁定,在這里是要由訂閱數據的平臺自己指定的。而且因為這個exchange是fanout類型的,他只要接收到了數據,就會路由數據到所有綁定到他的隊列里去,這樣每個隊列里都有同樣的一份數據,供對應的平臺來消費。
而且針對每個平臺自己的隊列,自己還可以部署消費服務集群來消費自己的一個隊列,自己的隊列里的數據還是會均勻分發給各個消費服務實例來?處理,每個消費服務實例會獲取到一部分的數據。
大家思考一下,這樣是不是就實現了不同的系統訂閱一份數據的“Pub/Sub”的模型?
當然,其實RabbitMQ還支持各種不同類型的exchange,可以實現各種復雜的功能。?