不超過百行的SQL文件提取器
數據的獲取以及對數據的處理非常重要。
數據是互聯網的靈魂、沒有數據互聯網就是一個無用的空殼子,像人工智能、大數據、智能算法等。都是需要基礎數據來驗證模型是否是可用的,來進行調參矯正算法的可用性、幫助算法的落地,對算法起到最關鍵的作用。所以數據的獲取以及對數據的處理就是非常重要的。
通常的數據格式是txt、sql、excel以及word,其中最重要的還是SQL中的數據、SQL數據包括MySQL、SQLServer、SQLite、Oracle等,導出的數據格式。 常用的數據處理語言是Python、因為Python是個膠水語言,沒有Python搞不定的事。 Python比較適合做些快速、時間緊、參與人員較少,切性能要求不高的項目,而且Python成熟的庫很多、這也是它 被稱為 膠水語言的原因 。
技術要求需要懂得python3的基礎語法以及對正則表達式有基礎了解。
實現步驟
1.讀取SQL文件中的數據、去除多余的內容并提取需要的數據、追加到集合中;
# -*- coding: utf-8 -*-
# !/usr/bin/python3
# desc by: 兩行代碼實現SQL文件中數據提取,后期可以結合geogle瀏覽器插件應用
# author by : rainNight
# weChatPublicNumber: 雨夜的博客
import re
import json
"""
第一步:讀取area.sql文件,去除多余內容提取需要添加的數據
第二步:定義轉換后的文件地址,寫入文件
"""
opens = open("./data/area.sql", encoding="utf-8")
codeline = opens.readlines() # 一行一行的讀取
jsonList = []
for line in codeline:
if re.match("INSERT", line):
jsonList.append(re.findall(re.compile(r'[(](.*?)[)]', re.S), line))
2.將集合中的數據轉成json格式;
3.定義轉換后的文件地址并寫入文件中
jsonArray = json.dumps(jsonList)
jsonOpen = open("./data/areaToJson.txt", "w")
jsonOpen.writelines(str(jsonArray))
opens.close()
jsonOpen.close()
所有代碼:
# -*- coding: utf-8 -*-
# !/usr/bin/python3
# desc by: 兩行代碼實現SQL文件中數據提取,后期可以結合geogle瀏覽器插件應用
# author by : rainNight
# weChatPublicNumber: 雨夜的博客
import re
import json
"""
第一步:讀取area.sql文件,去除多余內容提取需要添加的數據
第二步:定義轉換后的文件地址,寫入文件
"""
opens = open("./data/area.sql", encoding="utf-8")
codeline = opens.readlines() # 一行一行的讀取
jsonList = []
for line in codeline:
if re.match("INSERT", line):
jsonList.append(re.findall(re.compile(r'[(](.*?)[)]', re.S), line))
jsonArray = json.dumps(jsonList)
jsonOpen = open("./data/areaToJson.txt", "w")
jsonOpen.writelines(str(jsonArray))
opens.close()
jsonOpen.close()
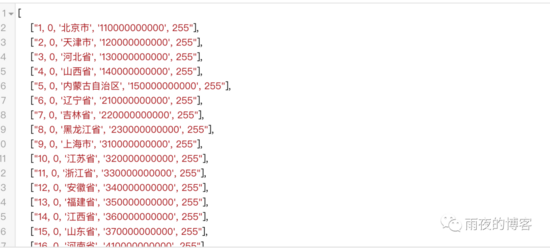
實現的結果:
細微思路的發現、并將該思維實現產品中逐漸放大化,最終實現體系走向產品運營。
責任編輯:張燕妮
來源:
雨夜的博客