













機器學習中必學的四種交叉驗證技術
?介紹
考慮在數據集上創建模型,但它在看不見的數據上失敗。
我們不能簡單地將模型擬合到我們的訓練數據中,然后坐等它在真實的、看不見的數據上完美運行。
這是一個過度擬合的例子,我們的模型已經提取了訓練數據中的所有模式和噪聲。為了防止這種情況發生,我們需要一種方法來確保我們的模型已經捕獲了大多數模式并且不會拾取數據中的每一點噪聲(低偏差和低方差)。處理此問題的眾多技術之一是交叉驗證。
了解交叉驗證
假設在一個特定的數據集中,我們有 1000 條記錄,我們train_test_split()在上面執行。假設我們有 70% 的訓練數據和 30% 的測試數據random_state = 0,這些參數導致 85% 的準確度。現在,如果我們設置random_state = 50假設準確度提高到 87%。
這意味著如果我們繼續選擇不同random_state的精度值,就會發生波動。為了防止這種情況,一種稱為交叉驗證的技術開始發揮作用。
交叉驗證的類型
留一交叉驗證 (LOOCV)
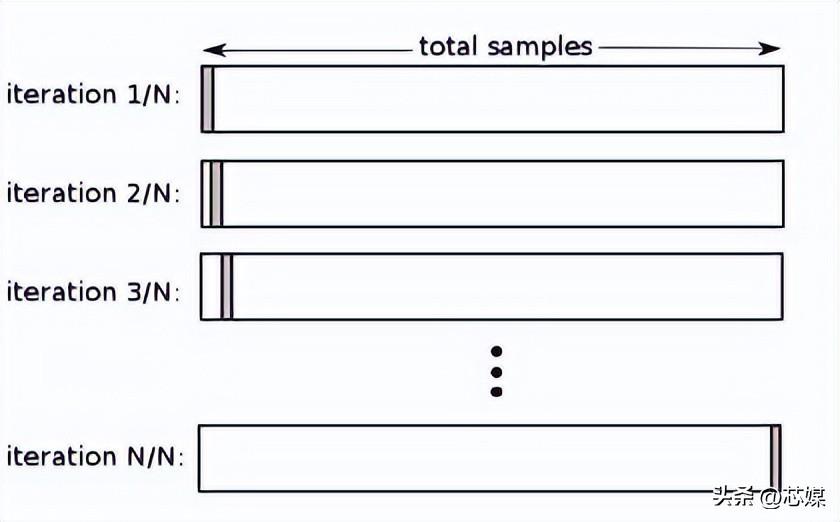
在LOOCV中,我們選擇 1 個數據點作為測試,剩下的所有數據都將是第一次迭代中的訓練數據。在下一次迭代中,我們將選擇下一個數據點作為測試,其余的作為訓練數據。我們將對整個數據集重復此操作,以便在最終迭代中選擇最后一個數據點作為測試。
通常,要計算迭代交叉驗證過程的交叉驗證 R2,您需要計算每次迭代的 R2 分數并取它們的平均值。
盡管它會導致對模型性能的可靠且無偏的估計,但它的執行計算成本很高。
2. K-fold 交叉驗證

在K-fold CV中,我們將數據集拆分為 k 個子集(稱為折疊),然后我們對所有子集進行訓練,但留下一個 (k-1) 個子集用于評估訓練后的模型。
假設我們有 1000 條記錄并且我們的 K=5。這個 K 值意味著我們有 5 次迭代。對于測試數據要考慮的第一次迭代的數據點數從一開始就是 1000/5=200。然后對于下一次迭代,隨后的 200 個數據點將被視為測試,依此類推。
為了計算整體準確度,我們計算每次迭代的準確度,然后取其平均值。
我們可以從這個過程中獲得的最小準確度將是所有迭代中產生的最低準確度,同樣,最大準確度將是所有迭代中產生的最高準確度。
3.分層交叉驗證
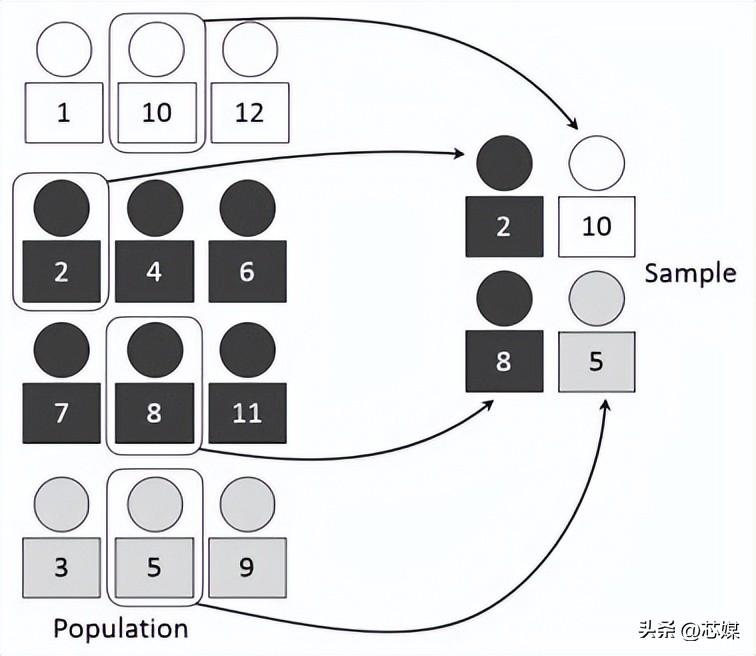
分層 CV是常規 k 折交叉驗證的擴展,但專門針對分類問題,其中的分割不是完全隨機的,目標類之間的比率在每個折中與在完整數據集中的比率相同。
假設我們有 1000 條記錄,其中包含 600 條是和 400 條否。因此,在每個實驗中,它都會確保填充到訓練和測試中的隨機樣本的方式是,每個類的至少一些實例將是存在于訓練和測試分裂中。
4.時間序列交叉驗證?
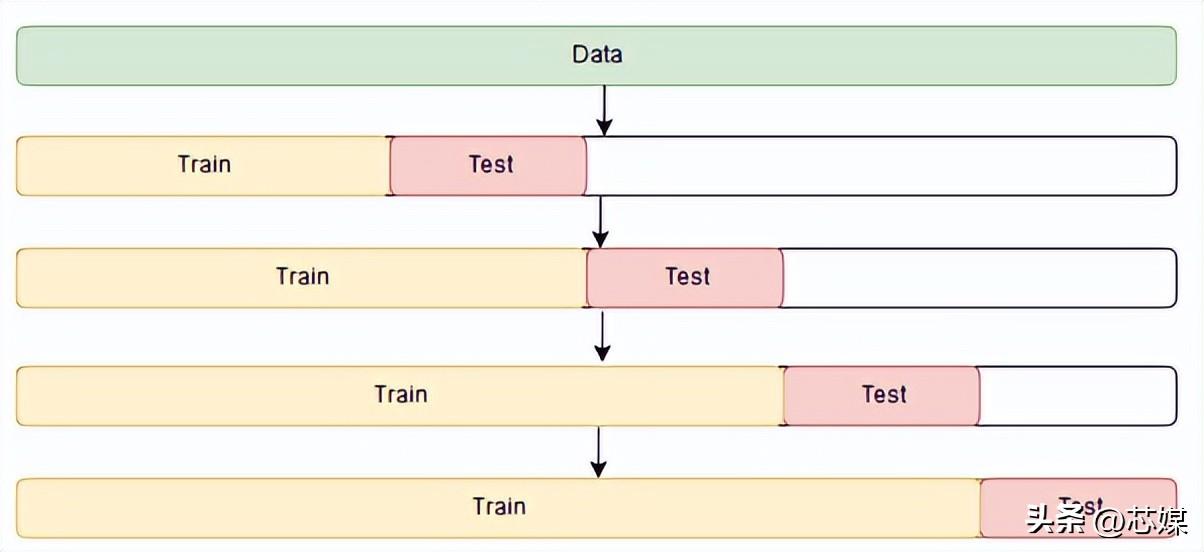
在時間序列 CV中有一系列測試集,每個測試集都包含一個觀察值。相應的訓練集僅包含在形成測試集的觀察之前發生的觀察。因此,未來的觀察不能用于構建預測。
預測精度是通過對測試集進行平均來計算的。此過程有時被稱為“對滾動預測原點的評估”,因為預測所基于的“原點”會及時前滾。
結論
在機器學習中,我們通常不想要在訓練集上表現最好的算法或模型。相反,我們需要一個在測試集上表現出色的模型,以及一個在給定新輸入數據時始終表現良好的模型。交叉驗證是確保我們能夠識別此類算法或模型的關鍵步驟。




















