我們為什么需要「云原生大數據」?
「云原生大數據 」已經是現在科技領域的熱詞了,尤其是對于大中型企業的可擴展性和敏捷性開發需求而言。什么是「云原生大數據」呢?首先大數據是我們很熟悉的詞匯了,主要講的是儲存、使用、挖掘海量的數據。而因為數據量過大,因此無法在本地單機上運行,而必須在云上進行管理。云原生指的是進一步提升云服務的可擴展性(scalability)和敏捷性(agility),前者指的是處理數據的數量,后者指的是開發的便捷性。因此簡單來說, 云原生大數據就是「為了在更大的數據上做更快的開發」的這一類技術與平臺 。
很多企業都有這樣的需求。以微信為例,它有超過3000個(微)服務,而每天可能要更新部署超過一千次。流服務媒體奈飛(Netflix)有超過600個(微)服務,每天也需要部署高達100多次 [1]。而云原生的重要性就在于把原本只有在本地上才可行的敏捷開發拓展到云上,從而支持海量運算的快速開發,這樣也才能保證數據量巨大的應用(比如微信)不需要離線測試和更新。
云原生有很多優點。首先它繼承了傳統云服務的優點,著重于向外擴展而不是增大資源投放 。舉個簡單的例子,傳統的開發會找一個機器,然后讓它專門負責一個任務,而隨著任務的拓展給它補充更多的資源(scale up)。但壞處很明顯,就是當這個機器出了問題以后整個任務就會下線。而云原生走的是向外擴展的思路(scale out),也就是說它虛擬出多個機器來共同完成任務,而任意一臺機器的鼓掌不影響整體的運營。因此它可以很輕易的提升服務的擴展性,比如一個APP從服務1000人到2000人可能只需要加一個虛擬機即可,不容易遇到上限。
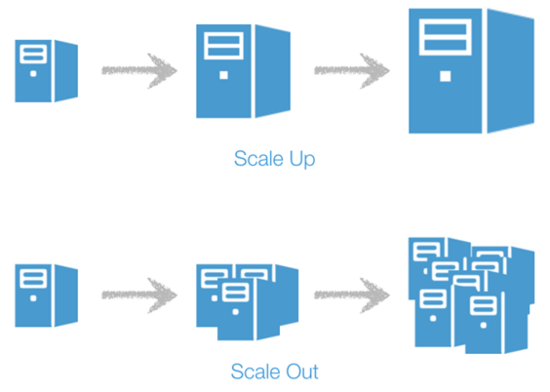
上圖:資源擴展(scale up); 下圖:云原生所采取的向外擴展(scale out)
其次云原生的另一個特點是著重微服務(microservice)和容器(container)來提高開發便捷性 。簡單來說,一個負責的系統可以被拆解為多個獨立但可以被組合的模塊(微服務),那么開發新的功能就只需要增加新的小模塊并與現有的組合。當我們部署這樣的新功能時,可以把打包好的功能放到統一的容器里。在這種情況下,我們無需每次重新處理所有的微服務,而可以敏捷的進行替換和升級,簡單理解就像是充電電池。我們可以給每個電池單獨充電(類比微服務升級),充好電之后(微服務升級好了),即插即用替換現有的微服務即可。比如一款社交軟件如何給用戶推送內容,可能就是一個微服務,它改變推送策略一般是把這個部分拿出來做升級與AB測試,再逐步在云上替換掉所有用戶的推薦系統。因為云原生采用的是向外擴展,這樣可以對用戶進行獨立或者有對比的升級,不會造成任何服務的中斷。
而在這些抽象的概念以外,其實原生云大數據從2013年被首次提出已經逐步的被應用到了越來越多的商業案例里 。國外的微軟在這個上面做的一直很好,而國內的話騰訊云發起了首個原生大數據的生態,也有很多用原生云大數據賦能產品的案例。
以微信來說,它們正在使用騰訊云的原生云設計來進行數據挖掘和分析。其實不難想象微信的數據量有多大,畢竟月活超過十億。因此在這樣的海量用戶場景下,很容易產生龐大的數據量進行分析,尤其是在整合多種用戶信息時需要大量時間,往往準備數據就需要數個小時甚至以天來計算,以前的AB 測試的滯后性比較明顯。而近水樓臺先得月,微信現在用騰訊云的云數據倉庫來處理這樣的數據,最大的優勢就是把數據量的吞吐、儲存和挖掘問題轉移到了騰訊云,每秒可以吞吐10億+的數據。而微信的工程師只需要通過業務需求進行具體的分析和開發,避免了把大量的時間放在等待上的問題。所以原生云大數據平臺的核心目的就是把儲存和開發中因為數據量造成的問題解決,而只把開發和分析問題留給使用者。
作為一套系統完整的解決方案,云原生大數據的重要組件有「大數據的基礎引擎」,用來保存、倉儲和調用數據,而在數據之上更重要的是「數據開發與治理」,即怎么從數據中挖掘有用的信息。當然再上層還可以集成各種商業可視化面板,從而更簡單的進行分析。而在這些系統的統籌下,原生云平臺可以支持各種重要的場景和應用。
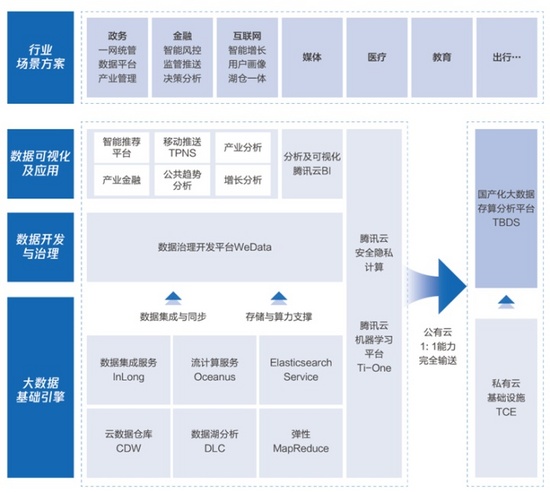
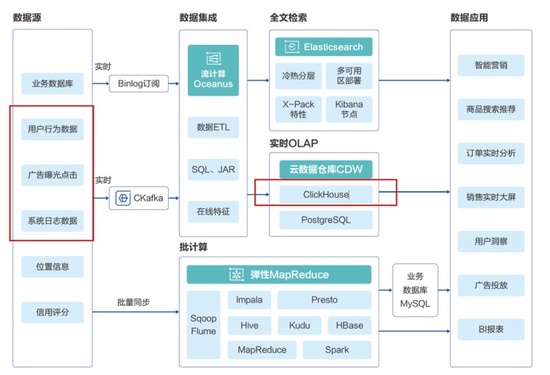
騰訊云大數據架構
我個人認為在這一整套架構中,最重要的部分就是底層的「大數據引擎」和中層的「數據開發與治理」, 非常考察技術。而更難的是怎么有機的把這些技術模塊結合起來。
在騰訊云的大數據引擎里,我個人覺得最有意思的是數據湖分析(DLC)和云數據倉庫(CDW)。先說數據湖分析DLC。和傳統的數據庫不同,數據湖(data lake)可以支持更大的數據存儲,它不僅可以支持保存關系數據庫(relational database),還可以保存半結構化的數據,比如CSV,JSON和XML等,甚至包括非結構性的數據,像是PDF、文檔、圖片,音視頻等。數據湖的出現讓我們有了一個統一的地方來儲存數據。 簡單來說,數據湖的出現避免了各個數據庫的孤立問題,為數據整合提供了一站式的地點 。騰訊云的DLC提供數據湖的數據分析因此也提供了:(1)從多個數據庫進行聯合查詢(2)serverless的架構使得使用者無需關注底層架構,可以直接用SQL語句進行處理。數據湖分析的場景非常適合游戲開發和迭代,比如可以進行網絡游戲的運營和應力分析,我們可以通過DLC把用戶的游戲日志和購買習慣等各種不同格式的數據拿到數據湖中,進行統一分析,從而最大化盈利。其中很有代表性的案例包括B站,可以通過游戲運營日志指標實時分析來為企業獲得更大的價值。
而云數據倉庫(CDW)的目標主要是整合大數據(尤其是寬表類數據),從而進行統一分析 。以騰訊的云數據倉庫ClickHouse為例,它的主要目的是在短時間內對于復雜的用戶特征進行分析,也就是我們常說的”大寬表”。即每個用戶可能在網絡上產生了個各種特征,比如購買習慣比如搜索習慣的,因此當我們把大量數據的行為整合起來,就會形成一個巨大的表格,不僅長度可能有上億行,寬度上可能也成千上萬(各種行為特征)。因此Clickhouse提供的就是一個開箱即用可擴展的數據整合工具。以下圖為例,大部分電商和營銷類企業都可以簡單的使用Clickhouse進行數據整合,從而篩選符合特征的用戶,并把數據喂到下一步的數據應用里進行實時訂單分析或者精準營銷。
以騰訊云的「數據開發與治理」平臺WeData為例 ,它的核心特色就在于云上的敏捷化開發和一體化操作。我們前面講了云原生大數據的一個重要就是需要敏捷化開發,可以根據數據的反饋即時進行修正和部署,從需求、開發和部署的過程需要非常快速,這也是現在新的概念叫做DataOps。而WeData的重要創新就是支持協同開發,這個可以通多IDE和內置的DAG實現,而多人協作時一個很有用的功能就是數據可視化,這樣避免代碼層面的沖突。WeData因此在打通下游大數據引擎的前提下,同時支持快速的開發、迭代與部署。
而在數據治理層面,另一個重點是安全性 。WeData在多人協作時可以精細化的控制每個人可以接觸到的數據,從而防止有數據泄露的安全問題。敏捷性不代表我們應該在開發中犧牲安全性。
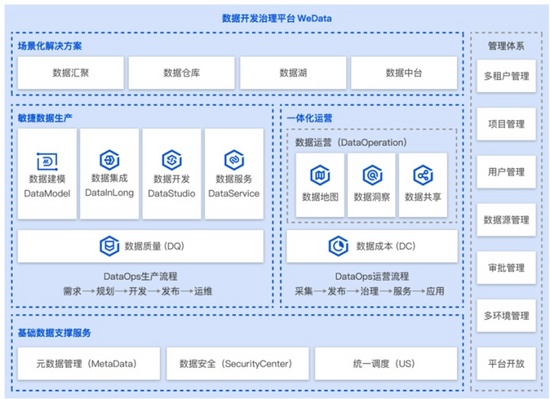
WeData數據開發治理平臺
而結合這些引擎和處理系統,云原生大數據確實已經被應用到了我們生活當中 。除了前文提到的知乎、微信、B站等,大部分我們熟悉的行業其實都已經用上了云原生的技術。比如金融行業包括證券和銀行,它們利用云服務,比如騰訊云,把多個渠道的用戶信息匯總,并在海量的數據里挖掘欺詐與洗錢,或是開設智能的風控與理賠。又或是教育行業,它們會利用原生云完成從個性化學習內容推薦,智能測評與批改,到實時對學員表現進行分析的全鏈條支持。雖然有些功能對于小企業在本地也可以完成,但云原生的特性就是可以隨著用戶數的上升彈性擴容,提供一樣便捷的數據儲存和分析。
因此云原生大數據確實是技術發展上不可阻擋的趨勢 。而隨著我們每天產生數據量的繼續的飛速增加,未來它的使用場景還會進一步拓展。人類現在每年產生的數據已經是前十幾年的總和,而隨著越來越多的數據產生,我們也會從中有更多對自己和社會的理解,而更好的云服務和技術將會是其中重要的一環。