













數(shù)據(jù)庫管理是后端開發(fā)最重要的方面之一。適當優(yōu)化的數(shù)據(jù)庫可以幫助減少響應時間,從而帶來更好的用戶體驗。在本文中,我們將討論在 Django 應用程序中優(yōu)化數(shù)據(jù)庫以提高速度的方法。

了解 Django 中的查詢集是優(yōu)化的關鍵,因此,請記住以下幾點:
- 查詢集是惰性的,這意味著在你對查詢集執(zhí)行某些操作(例如對其進行迭代)之前,不會發(fā)出相應的數(shù)據(jù)庫請求。
- 始終通過指定要返回的值的數(shù)量來限制數(shù)據(jù)庫查詢的結果。
- 在 Django 中,查詢集可以通過迭代、切片、緩存和 python 方法(例如len()等)進行評估count()。確保充分利用它們。
- Django 查詢集被緩存,因此如果你重復使用相同的查詢集,將不會發(fā)出多個數(shù)據(jù)庫請求,從而最大限度地減少數(shù)據(jù)庫訪問。
- 一次檢索你需要的所有內(nèi)容,但請確保你只檢索你需要的內(nèi)容。
Django中的查詢優(yōu)化
數(shù)據(jù)庫索引
數(shù)據(jù)庫索引是一種在從數(shù)據(jù)庫中檢索記錄時加快查詢速度的技術。隨著應用程序大小的增加,它可能會變慢,并且用戶會注意到,因為獲取所需數(shù)據(jù)需要更長的時間。因此,在處理生成大量數(shù)據(jù)的大型數(shù)據(jù)庫時,索引是一項不可協(xié)商的操作。
索引是一種基于各個字段對大量數(shù)據(jù)進行排序的方法。當你在數(shù)據(jù)庫中的字段上創(chuàng)建索引時,你將創(chuàng)建另一個數(shù)據(jù)結構,其中包含字段值以及指向與其相關的記錄的指針。然后對該索引結構進行排序,使二進制搜索成為可能。
例如,這是一個名為 Sale 的 Django 模型:
# models.py
from django.db import models
class Sale(models.Model):
sold_at = models.DateTimeField(
auto_now_add=True,
)
charged_amount = models.PositiveIntegerField()
在定義 Django 模型時,可以將數(shù)據(jù)庫索引添加到特定字段,如下所示:
# models.py
from django.db import models
class Sale(models.Model):
sold_at = models.DateTimeField(
auto_now_add=True,
db_index=True, #DB Indexing
)
charged_amount = models.PositiveIntegerField()
如果你為此模型運行遷移,Django 將在表 Sales 上創(chuàng)建一個數(shù)據(jù)庫索引,并且它將被鎖定直到索引完成。在本地開發(fā)設置中,數(shù)據(jù)量很少,連接很少,這種遷移可能感覺是瞬間的,但是當我們談論生產(chǎn)環(huán)境時,有很多并發(fā)連接的大型數(shù)據(jù)集可能會導致停機,如獲取鎖和創(chuàng)建數(shù)據(jù)庫索引可能需要很長時間。
你還可以為兩個字段創(chuàng)建單個索引,如下所示:
# models.py
from django.db import models
class Sale(models.Model):
sold_at = models.DateTimeField(
auto_now_add=True,
db_index=True, #DB Indexing
)
charged_amount = models.PositiveIntegerField()
class Meta:
indexes = [
["sold_at", "charged_amount"]]
數(shù)據(jù)庫緩存
數(shù)據(jù)庫緩存是從數(shù)據(jù)庫獲得快速響應的最佳方法之一。它確保對數(shù)據(jù)庫的調(diào)用更少,從而防止過載。標準緩存操作遵循以下結構:
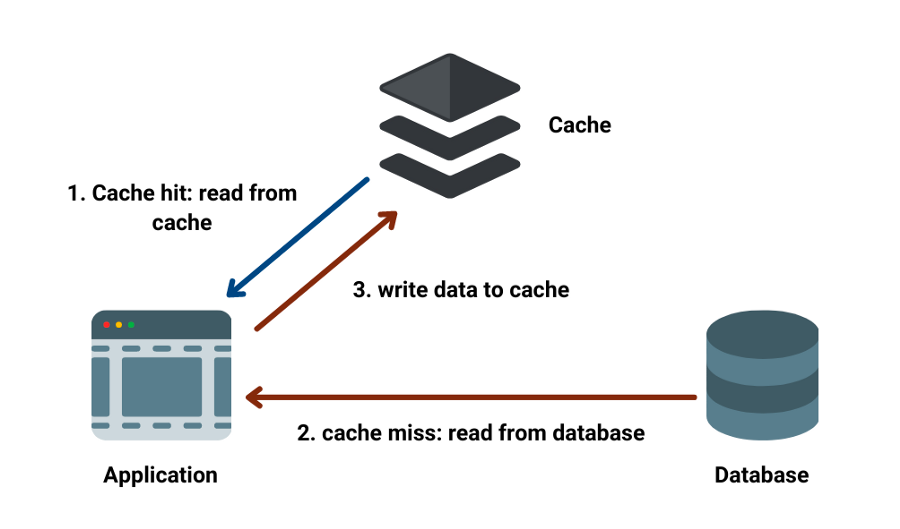
Django 提供了一種緩存機制,可以使用不同的緩存后端,如 Memcached 和 Redis,讓你避免多次運行相同的查詢。
Memcached 是一個開源的內(nèi)存系統(tǒng),可保證在不到一毫秒的時間內(nèi)提供緩存結果。它易于設置和擴展。另一方面,Redis 是一種開源緩存解決方案,具有與 Memcached 相似的特性。大多數(shù)離線應用程序使用以前緩存的數(shù)據(jù),這意味著大多數(shù)查詢永遠不會到達數(shù)據(jù)庫。
用戶會話應該保存在 Django 應用程序的緩存中,并且因為 Redis 在磁盤上維護數(shù)據(jù),所以登錄用戶的所有會話都來自緩存而不是數(shù)據(jù)庫。
要在 Django 中使用 Memcache,我們需要定義以下內(nèi)容:
- BACKEND:定義要使用的緩存后端。
- LOCATION:ip:port 值 where ip 是 Memcached 守護程序的 IP 地址, port 是運行 Memcached 的端口,或者是指向你的 Redis 實例的 URL,使用適當?shù)姆桨浮?/li>
要使用 Memcached 啟用數(shù)據(jù)庫緩存,請pymemcache使用以下命令使用 pip 進行安裝:
pip install pymemcache
然后,你可以settings.py按如下方式配置緩存設置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyMemcacheCache',
'LOCATION': '127.0.0.1:11211',
}
}
在上面的示例中,Memcached 使用以下 pymemcache 綁定在 localhost (127.0.0.1) 端口 11211 上運行:
同樣,要使用 Redis 啟用數(shù)據(jù)庫緩存,請使用以下命令使用 pip 安裝 Redis:
pip install redis
tings.py然后通過添加以下代碼來配置你的緩存設置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.redis.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379',
}
}
Memcached 和 Redis 也可用于存儲用戶身份驗證令牌。因為每個登錄的人都必須提供一個令牌,所以所有這些過程都會導致大量的數(shù)據(jù)庫開銷。使用緩存的令牌將大大加快數(shù)據(jù)庫訪問速度。
盡可能使用迭代器
Django 中的查詢集通常會在評估發(fā)生時緩存其結果,對于該查詢集的任何進一步操作,它首先檢查是否有緩存的結果。但是,當你使用 時iterator(),它不會檢查緩存并直接從數(shù)據(jù)庫中讀取結果,也不會將結果保存到查詢集。
現(xiàn)在,你一定想知道這有什么幫助。考慮一個查詢集,它返回大量具有大量內(nèi)存的對象進行緩存,但只能使用一次,在這種情況下,你應該使用iterator()。
例如,在下面的代碼中,所有記錄將從數(shù)據(jù)庫中獲取,然后加載到內(nèi)存中,然后我們將遍歷每條記錄:
queryset = Product.objects.all()
for each in queryset:
do_something(each)
而如果我們使用iterator(),Django 將保持 SQL 連接打開并讀取每條記錄,并 do_something() 在讀取下一條記錄之前調(diào)用:
queryset = Product.objects.all().iterator()
for each in queryset:
do_something(each)
使用持久性數(shù)據(jù)庫連接
Django 為每個請求創(chuàng)建一個新的數(shù)據(jù)庫連接,并在請求完成后關閉它。這種行為是由 引起的CONN_MAX_AGE,它的默認值為 0。但是應該設置多長時間呢?這取決于你網(wǎng)站上的流量;音量越高,維持連接所需的秒數(shù)就越多。通常建議從較低的數(shù)字開始,例如 60。
你需要將額外的選項包裝在 中 OPTIONS,如留檔中詳細說明:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'dashboard',
'USER': 'root',
'PASSWORD': 'root',
'HOST': '127.0.0.1',
'PORT': '3306',
'OPTIONS': {
'CONN_MAX_AGE': '60',
}
}
}
使用查詢表達式
查詢表達式定義了可以在更新、創(chuàng)建、過濾、排序、注釋或聚合操作中使用的值或計算。Django 中常用的內(nèi)置查詢表達式是 F 表達式。讓我們看看它是如何工作的并且很有用。
在 Django Queryset API 中,F(xiàn)()表達式用于直接引用模型字段值。它允許你引用模型字段值并對它們執(zhí)行數(shù)據(jù)庫操作,而無需從數(shù)據(jù)庫中獲取它們并進入 Python 內(nèi)存。相反,Django 使用該F()對象來生成定義所需數(shù)據(jù)庫活動的 SQL 短語。
例如,假設我們想將所有產(chǎn)品的價格提高 20%,那么代碼將如下所示:
products = Product.objects.all()
for product in products:
product.price *= 1.2
product.save()
但是,如果我們使用F(),我們可以在單個查詢中執(zhí)行此操作,如下所示:
from django.db.models import F
Product.objects.update(price=F('price') * 1.2)
使用 select_related() 和 prefetch_related()
Django 通過最小化數(shù)據(jù)庫請求的數(shù)量來提供優(yōu)化查詢集select_related()的prefetch_related()參數(shù)。
根據(jù)官方 Django 文檔:
select_related() “遵循”外鍵關系,在執(zhí)行查詢時選擇其他相關對象數(shù)據(jù)。
prefetch_related() 對每個關系進行單獨的查找,并在 Python 中進行“加入”。
select_related()
我們select_related()在要選擇的項目是單個對象時使用,這意味著 forward ForeignKey、OneToOne和 backOneToOne字段。
你可以使用select_related()創(chuàng)建單個查詢,該查詢返回單個實例的所有相關對象,用于一對多和一對一連接。執(zhí)行查詢時,select_related()從外鍵關系中檢索任何額外的相關對象數(shù)據(jù)。
select_related()通過生成 SQL 連接并在SELECT表達式中包含相關對象的列來工作。因此,select_related()在同一數(shù)據(jù)庫查詢中返回相關項目。
雖然select_related()會產(chǎn)生更復雜的查詢,但獲取的數(shù)據(jù)會被緩存,因此處理獲取的數(shù)據(jù)不需要任何額外的數(shù)據(jù)庫請求。
語法看起來像這樣:
queryset = Tweet.objects.select_related('owner').all()
prefetch_related()
相反,prefetch_related()用于多對多和多對一連接。它生成一個查詢,其中包括查詢中給出的所有模型和過濾器。
語法看起來像這樣:
Book.objects.prefetch_related('author').get(id=1).author.first_name
使用bulk_create()和bulk_update()
bulk_create() 是一種通過一次查詢將提供的對象列表創(chuàng)建到數(shù)據(jù)庫中的方法。類似地,bulk_update() 是一種使用一個查詢更新提供的模型實例上的給定字段的方法。
例如,如果我們有一個如下所示的帖子模型:
class Post(models.Model):
title = models.CharField(max_length=300, unique=True)
time = models.DateTimeField(auto_now_add=True)
def __str__(self):
return self.title
現(xiàn)在,假設我們要在這個模型中添加多條數(shù)據(jù)記錄,那么我們可以bulk_create()這樣使用:
#articles
articles = [Post(title="Hello python"), Post(title="Hello django"), Post(title="Hello bulk")]
#insert data
Post.objects.bulk_create(articles)
輸出如下所示:
>>> Post.objects.all()
<QuerySet [<Post: Hello python>, <Post: Hello django>, <Post: Hello bulk>]>
如果我們想更新數(shù)據(jù),那么我們可以bulk_update()這樣使用:
update_queries = []
a = Post.objects.get(id=14)
b = Post.objects.get(id=15)
c = Post.objects.get(id=16)
#set update value
a.title="Hello python updated"
b.title="Hello django updated"
c.title="Hello bulk updated"
#append
update_queries.extend((a, b, c))
Post.objects.bulk_update(update_queries, ['title'])
輸出如下所示:
>>> Post.objects.all()
<QuerySet [<Post: Hello python updated>, <Post: Hello django updated>, <Post: Hello bulk updated>]>
結語
在本文中,我們介紹了在 Django 應用程序中優(yōu)化數(shù)據(jù)庫性能、減少瓶頸和節(jié)省資源的技巧。
原文標題:??7 Database Optimization Best Practices for Django Developers??

















