深入理解kubernetes監控原理

前言
?承接上文?,我們在基于Ubuntu 2204使用kubeadm部署了k8s集群,且基于helm部署了metrics-server.
然后我們可以很歡快的使用kubectl top命令查看node、pod的實時資源使用情況:如CPU、內存。
本文將介紹其數據鏈路和實現原理,同時會闡述k8s中的監控體系。
kubectl top
kubectl top是我們經常使用的基礎命令,但是必須需要部署metrics-server組件,才能獲取到監控值。
- 在kubernetes 1.8版本之前,則需要部署heapter, 現已被廢棄。
- 在kubernetes1.8以及以上,則需要部署metrics-server。
我們所使用的版本是1.24.3的最新版本,所以一定要部署metrics-server。
查看node的資源使用情況。
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-unode1 158m 7% 1814Mi 47%
k8s-unode2 50m 2% 874Mi 23%
k8s-unode3 51m 2% 943Mi 24%
k8s-unode4 45m 2% 905Mi 23%
$ kubectl top node k8s-unode1
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-unode1 160m 8% 1811Mi 47%
查看pod的資源使用情況,--containers可以顯示pod內所有的container。
$ kubectl top pod -n metrics-server
NAME CPU(cores) MEMORY(bytes)
metrics-server-56c6866684-w6n9b 5m 17Mi
$ kubectl top pod --containers -n metrics-server
POD NAME CPU(cores) MEMORY(bytes)
metrics-server-56c6866684-w6n9b metrics-server 5m 17Mi
指標的具體含義:
- 這里CPU 的m 和 memory 的 mi 與k8s中 request、limit是一致的,cpu單位的100m=0.1 內存單位 1MI=1204Ki。
- pod的內存值是其內存的實際使用量,也是做limit限制時判斷oom的依據。pod的使用量等于其所有業務容器的綜合,但是不包含pause容器。與Cadvisr中的container_memory_working_set_bytes 指標值相等。
- node的值并不等于該node上所有pod值的總和,也不等于直接在機器上執行top或free所得到的值。
kubectl top pod 內存計算
每次啟動 pod,都會有一個 pause 容器,既然是容器就一定有資源消耗(一般在 2-3M 的內存),cgroup 文件中,業務容器和 pause 容器都在同一個 pod的文件夾下。
但 cadvisor 在查詢 pod 的內存使用量時,是先獲取了 pod 下的container列表,再逐個獲取container的內存占用,不過這里的 container 列表并沒有包含 pause,因此最終 top pod 的結果也不包含 pause 容器。
pod 的內存使用量計算
kubectl top pod 得到的內存使用量,并不是cadvisor 中的container_memory_usage_bytes,而是container_memory_working_set_bytes,計算方式為:
- container_memory_usage_bytes == container_memory_rss + container_memory_cache + kernel memory。
- container_memory_working_set_bytes = container_memory_usage_bytes – total_inactive_file(未激活的匿名緩存頁)。
container_memory_working_set_bytes是容器真實使用的內存量,也是limit限制時的 oom 判斷依據。
kubectl top命令和 top 的差異和上邊 一致,無法直接對比,同時,就算你對 pod 做了limit 限制,pod 內的 top 看到的內存和 cpu總量仍然是機器總量,并不是pod 可分配量。
- 進程的RSS為進程使用的所有物理內存(file_rss+anon_rss),即Anonymous pages+Mapped apges(包含共享內存)。
- cgroup RSS為(anonymous and swap cache memory),不包含共享內存。兩者都不包含file cache。
實現原理
數據鏈路
k8s dashboard、kubectl top等都是通過apiserver獲取監控數據,數據鏈路如下:

- 使用 heapster 時:apiserver 會直接將metric請求通過 proxy 的方式轉發給集群內的 hepaster 服務。
- 使用 metrics-server 時:apiserver是通過/apis/metrics.k8s.io/的地址訪問metric。
監控體系
在提出 metric api 的概念時,官方頁提出了新的監控體系,監控資源被分為了2種:
- Core metrics(核心指標):從 Kubelet、cAdvisor 等獲取度量數據,再由metrics-server提供給 Dashboard、HPA 控制器等使用。
- Custom Metrics(自定義指標):由Prometheus Adapter提供API custom.metrics.k8s.io,由此可支持任意Prometheus采集到的指標。
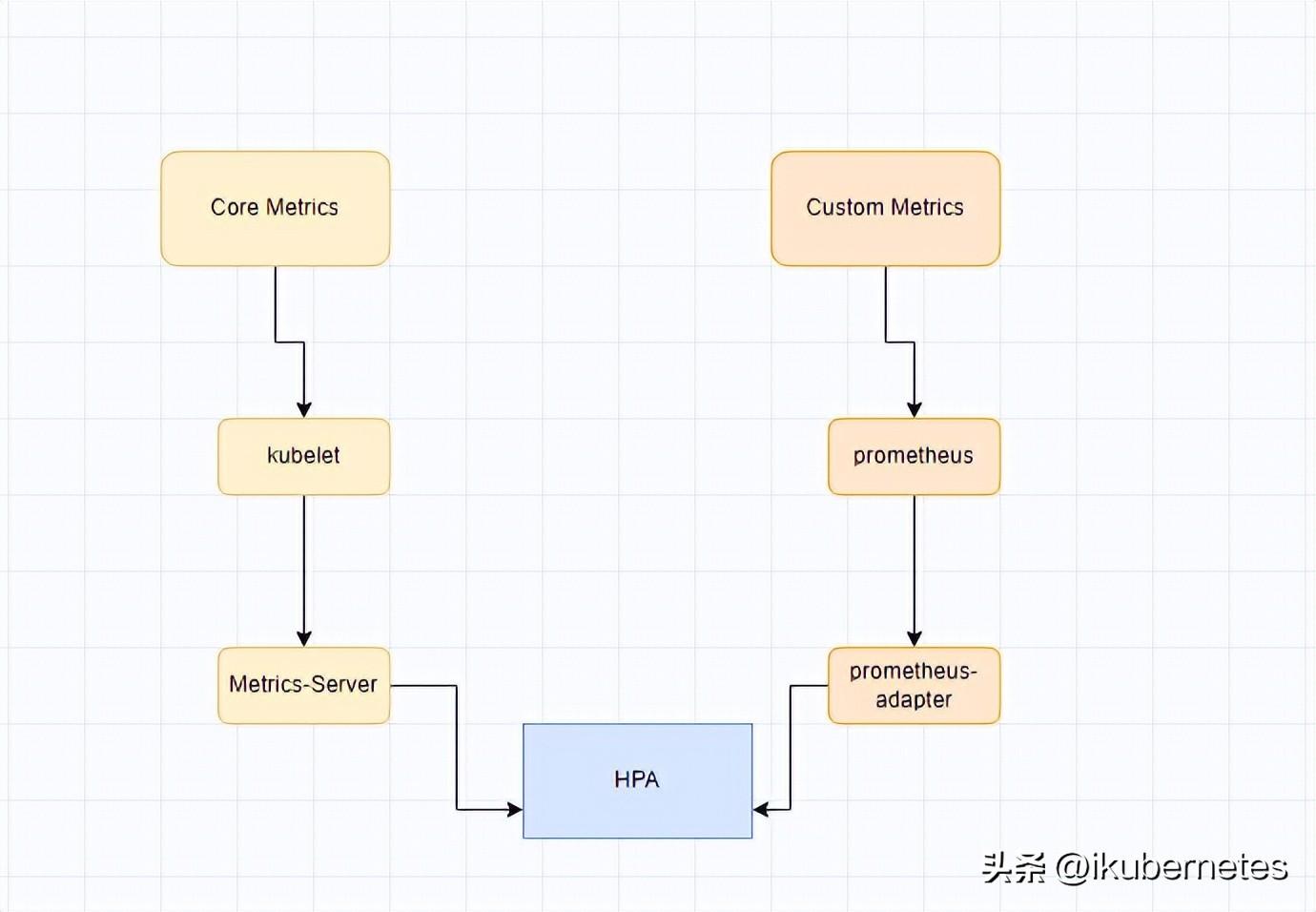
- 核心指標只包含node和pod的cpu、內存等,一般來說,核心指標作HPA已經足夠,但如果想根據自定義指標:如請求qps/5xx錯誤數來實現HPA,就需要使用自定義指標了。
- 目前Kubernetes中自定義指標一般由Prometheus來提供,再利用k8s-prometheus-adpater聚合到apiserver,實現和核心指標(metric-server)同樣的效果。
kubelet
無論是廢棄的heapster還是metric-server,都只是數據的中轉和聚合;兩者都是調用的kubelet的api接口獲取的數據。kubelet代碼中實際集成了采集指標的cAdvisor模塊,可以通過kubelet暴露的10250端口獲取監控數據。
- Kubelet Summary metrics: 127.0.0.1:10250/metrics,暴露 node、pod 匯總數據。
- Cadvisor metrics: 127.0.0.1:10250/metrics/cadvisor,暴露 container 維度數據。
kubelet雖然提供了 metric 接口,但實際監控邏輯由內置的cAdvisor模塊負責。
cAdvisor
cAdvisor由谷歌開源,使用go語言開發。項目地址:https://github.com/google/cadvisor。
cadvisor不僅可以搜集一臺機器上所有運行的容器信息,包括CPU使用情況、內存使用情況、網絡吞吐量及文件系統使用情況,還提供基礎查詢界面和http接口,方便其他組件進行數據抓取。在K8S中集成在Kubelet里作為默認啟動項,k8s官方標配。
cadvisor獲取指標時實際調用的是 runc/libcontainer庫,而libcontainer是對 cgroup文件 的封裝,即 cadvsior也只是個轉發者,它的數據來自于cgroup文件。
cgroup
cgroup文件中的值是監控數據的最終來源,如:
- mem usage的值,來自于/sys/fs/cgroup/memory/docker/[containerId]/memory.usage_in_bytes。
- 如果沒限制內存,Limit = machine_mem,否則來自于 /sys/fs/cgroup/memory/docker/[id]/memory.limit_in_bytes。
- 內存使用率 = memory.usage_in_bytes/memory.limit_in_bytes。
一般情況下,cgroup文件夾下的內容包括CPU、內存、磁盤、網絡等信息。

device:設備控制權限
cpuset:分配指定的CPU和內存節點
cpu:控制CPU占用率
cpuacct:統計CPU使用情況
memory:限制內存的使用上限
freezer:凍結Cgroup中的進程
net_cls:配合(traffic controller)限制網絡帶寬
net_prio:設置進程的網絡流量優先級
huge_tlb:限制HugeTLB的使用
pref_event:允許perf工具基于cgrgoup分組做性能監測
memory下的幾個常用的指標含義:

memory.usage_in_bytes: 已使用的內存量(包含cache和buffer)字節,相當于linux的userd_mem
memory.limit_in_bytes: 限制的內存總量(字節),相當于linux的total_mem
memory.failcnt: 申請內存失敗次數計數
memory.stat: 內存相關狀態
memory.memsw.usage_in_bytes: 已使用內存和swap
memory.memsw.limit_in_bytes: 限制的內存和swap
memory.memsw.failcnt: 申請內存和swap失敗次數計數