













測試技能提升篇—k8s的網絡核心概念

絕大多數剛剛接觸k8s的同學都會被其中的網絡相關知識點搞得暈頭轉向!各種IP,包括:Node IP,ClusterIP,Node IP糾結是啥東東?internet是怎樣訪問k8s的?k8s內部各個pod之間又是如何通信的?本文就為大家來解決上述問題。
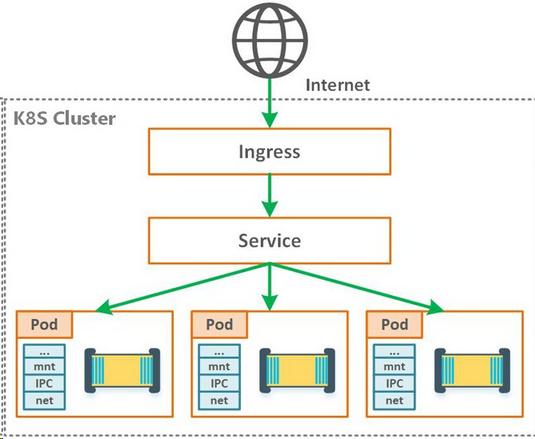
K8s中網絡核心概念介紹
Node IP
Node節點的IP地址,即物理網卡的IP地址。
NodePort可以是物理機的IP(也可能是虛擬機IP)。每個Service都會在Node節點上開通一個端口,外部可以通過NodeIP:NodePort即可訪問Service里的Pod,和我們訪問服務器部署的項目一樣,IP:端口/項目名。
Cluster IP
Service的IP地址,此為虛擬IP地址。外部網絡無法ping通,只有k8s集群內部訪問使用。Cluster IP是一個虛擬的IP,但更像是一個偽造的IP網絡,原因有以下幾點:
1.Cluster IP僅僅作用于k8s Service這個對象,并由k8s管理和分配P地址。
2.Cluster IP無法被ping,他沒有一個“實體網絡對象”來響應。
3.Cluster IP只能結合Service Port組成一個具體的通信端口,單獨的Cluster IP不具備通信的基礎,并且他們屬于k8s集群這樣一個封閉的空間。
4.在不同Service下的pod節點在集群間相互訪問可以通過Cluster IP。
Pod IP
Pod IP是每個Pod的IP地址,他是Docker Engine根據docker網橋的IP地址段進行分配的,通常是一個虛擬的二層網絡
- 同Service下的pod可以直接根據Pod IP相互通信。
- 不同Service下的pod在集群間pod通信要借助于 cluster IP。
- pod和集群外通信,要借助于node IP。
簡單地總結:外部訪問時,先到Node節點網絡,再轉到service網絡,最后代理給pod網絡。
K8s如何實現網絡通信
三條核心原則
- 默認情況下,Linux 將所有的進程都分配到 root network namespace,以使得進程可以訪問外部網絡。
- K8s為每一個 Pod 都創建了一個 network namespace。
- 在 K8s中,Pod 是一組 docker 容器的集合,這一組 docker 容器將共享一個 network namespace。Pod 中所有的容器都使用該 network namespace 提供的同一個 IP 地址以及同一個端口空間。所有的容器都可以通過 localhost 直接與同一個 Pod 中的另一個容器通信。
容器與容器之間網絡通信
pod中每個docker容器和pod在一個網絡命名空間內,所以ip和端口等等網絡配置,都和pod一樣,主要通過一種機制就是,docker的一種網絡模式,container,新創建的Docker容器不會創建自己的網卡,配置自己的 IP,而是和一個指定的容器共享 IP、端口范圍等
pod與pod之間網絡通信
從 Pod 的視角來看,Pod 是在其自身所在的 network namespace 與同節點上另外一個 network namespace 進程通信。在Linux上,不同的 network namespace 可以通過 Virtual Ethernet Device (opens new window) 或 veth pair (兩塊跨多個名稱空間的虛擬網卡)進行通信。為連接 pod 的 network namespace,可以將 veth pair 的一段指定到 root network namespace,另一端指定到 Pod 的 network namespace。每一組 veth pair 類似于一條網線,連接兩端,并可以使流量通過。節點上有多少個 Pod,就會設置多少組 veth pair。下圖展示了 veth pair 連接 Pod 到 root namespace 的情況:
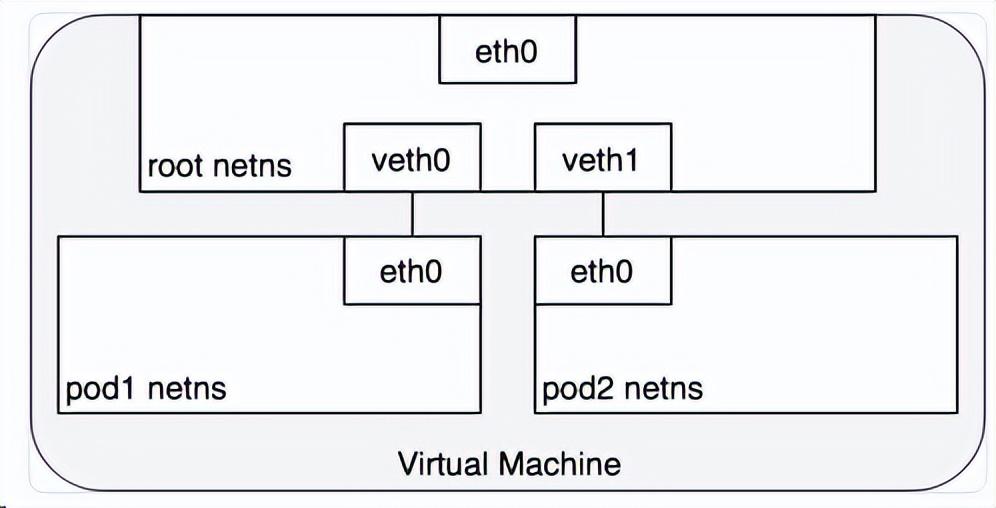
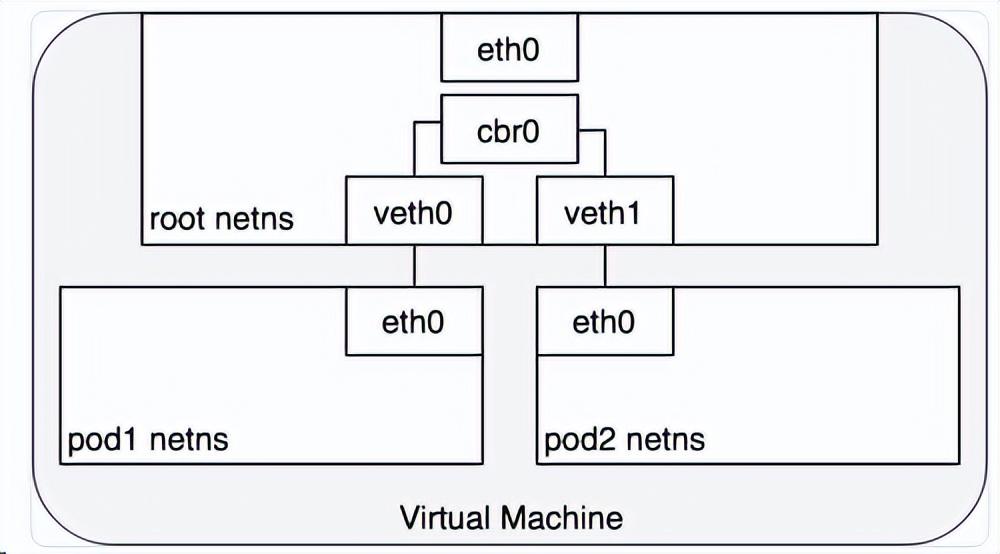
為了讓 Pod 可以互相通過 root network namespace 通信,我們將使用 network bridge(網橋)。Linux Ethernet bridge 是一個虛擬的 Layer 2 網絡設備,可用來連接兩個或多個網段。網橋的工作原理是,在源于目標之間維護一個轉發表,通過檢查通過網橋的數據包的目標地址和該轉發表來決定是否將數據包轉發到與網橋相連的另一個網段。橋接代碼通過網絡中具備唯一性的網卡MAC地址來判斷是否橋接或丟棄數據。網橋實現了ARP協議來發現鏈路層與 IP 地址綁定的 MAC 地址。當網橋收到數據幀時,網橋將該數據幀廣播到所有連接的設備上(除了發送者以外),對該數據幀做出相應的設備被記錄到一個查找表中。后續網橋再收到發向同一個 IP 地址的流量時,將使用查找表來找到對應的 MAC 地址,并轉發數據包。下圖中cbr0就是網橋。
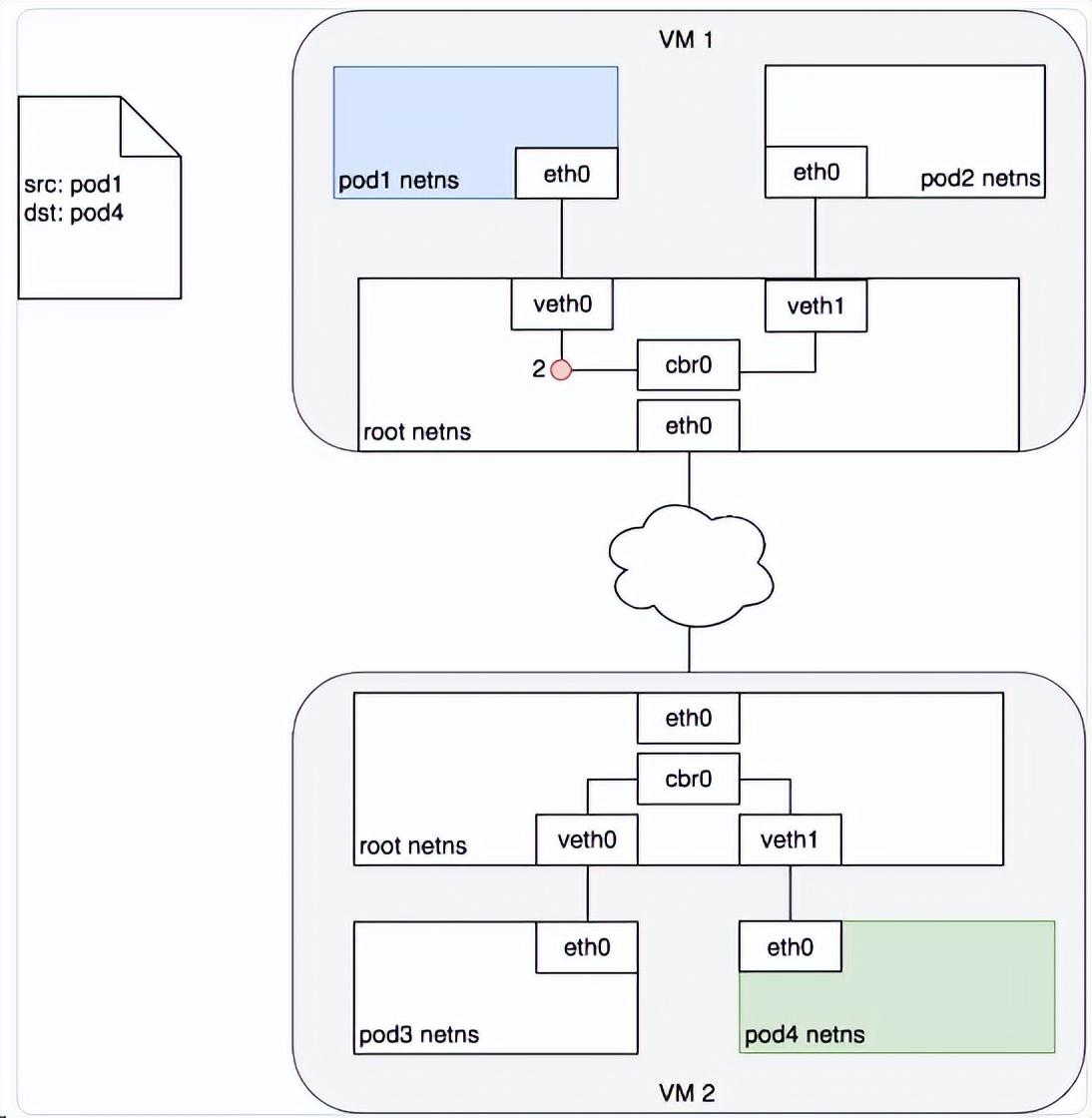
不同Node間通信原理
通常,集群中每個節點都被分配了一個 CIDR 網段(簡單的理解CIDR可以把幾個標準網絡合成一個大的網絡),指定了該節點上的 Pod 可用的 IP 地址段。一旦發送到該 CIDR 網段的流量到達節點,就由節點負責將流量繼續轉發給對應的 Pod。下圖展示了兩個節點之間的數據報文傳遞過程。
pod與service之間網絡通信
Pod 的 IP 地址并非是固定不變的,隨著 Pod 的重新調度(例如水平伸縮、應用程序崩潰、節點重啟等),Pod 的 IP 地址將會出現又消失。此時,Pod 的客戶端無法得知該訪問哪個 IP 地址。k8s中,Service 的概念用于解決此問題。Service管理了多個Pods,每個Service有一個虛擬的ip,要訪問service管理的Pod上的服務只需要訪問你這個虛擬ip就可以了,這個虛擬ip是固定的,當service下的pod規模改變、故障重啟、node重啟時候,對使用service的用戶來說是無感知的,因為他們使用的service的ip沒有變。當數據包到達Service虛擬ip后,數據包會被通過k8s給該servcie自動創建的負載均衡器路由到背后的pod容器。
我們知道Service 是 k8s中的一種服務發現機制,總結核心功能如下:
- 通常通過service來關聯pod并提供對外訪問接口。
- Service 實現負載均衡,可將請求均衡分發到選定這一組 Pod 中。
- Service 通過 label selector 選定一組 Pod。
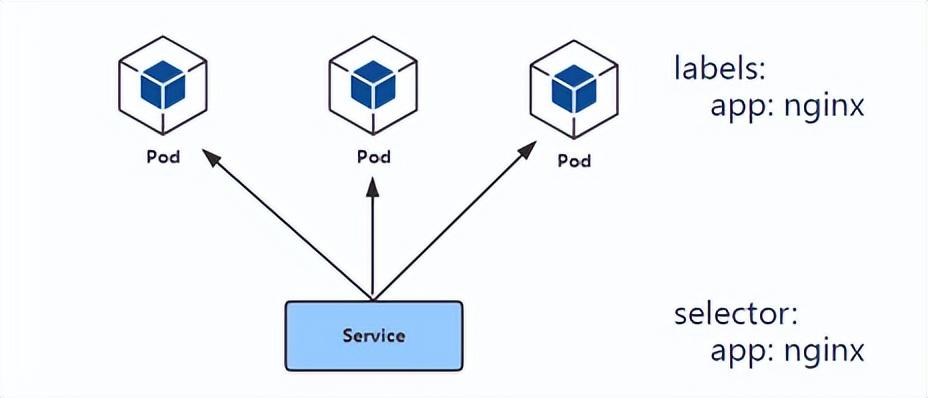
Service的ip分配策略
k8s的一個設計哲學是:盡量避免非人為錯誤產生的可能性。就設計 Service 而言,k8s應該將您選擇的端口號與其他人選擇的端口號隔離開。為此,k8s為每一個 Service 分配一個該 Service 專屬的 IP 地址。為了確保每個 Service 都有一個唯一的 IP 地址,k8s在創建 Service 之前,先更新 etcd 中的一個全局分配表,如果更新失敗(例如 IP 地址已被其他 Service 占用),則 Service 不能成功創建。k8s使用一個后臺控制器檢查該全局分配表中的 IP 地址的分配是否仍然有效,并且自動清理不再被 Service 使用的 IP 地址。
Service的dns解析
k8s集群中運行了一組 DNS Pod,配置了對應的 Service,并由 k8s將 DNS Service 的 IP 地址配置到節點上的容器中以便解析 DNS names。集群中的每一個 Service(包括 DNS 服務本身)都將被分配一個 DNS name。默認情況下,客戶端 Pod 的 DNS 搜索列表包括 Pod 所在的名稱空間以及集群的默認域。例如:
假設名稱空間 A中有一個 Service 名為 foo:
- 名稱空間 A中的 Pod 可以通過 nslookup foo 查找到該 Service。
- 名稱空間 B中的 Pod 可以通過 nslookup foo.A 查找到該 Service。
Internet與k8s的網絡通信
讓Internet流量進入k8s集群,這特定于配置的網絡,可以在網絡堆棧的不同層來實現:
- NodePort
NodePort 服務是引導外部流量到你的服務的最原始方式。NodePort,正如這個名字所示,在所有節點(虛擬機)上開放一個特定端口,任何發送到該端口的流量都被轉發到對應服務。
- Service LoadBalancer
如果你想要直接暴露服務,這就是默認方式。所有通往你指定的端口的流量都會被轉發到對應的服務。它設有過濾條件,路由等功能。值得一提的是,如果是在本地開發測試環境里頭搭建的K8s,一般不支持Load Balancer也沒必要,因為通過NodePort做測試訪問就夠了。但是在生產環境或者公有云上的K8s,基本都支持自動創建Load Balancer。
- Ingress控制器
它處于多個服務的前端,扮演著“智能路由”或者集群入口的角色。它的本質上就是K8s集群中的一個比較特殊的Service(發布Kind: Ingress)。這個Service提供的功能主要就是7層反向代理(也可以提供安全認證,監控,限流和SSL證書等高級功能),功能類似Nginx。Ingress對外暴露出去是通過HostPort(80/443),可以和上面LoadBalancer對接起來。有了這個Ingress Service,我們可以做到只需購買一個LB+IP,就可以通過Ingress將內部多個(甚至全部)服務暴露出去,Ingress會幫忙做代理轉發。


























