













原來用戶隱私是這樣被泄露:超八成搜索網站將信息出售
互聯網時代給用戶帶來了極大地便利,但也讓個人隱私信息無處躲藏。打開電商購物平臺,APP的精準推薦總是讓人感到不安;打開搜索平臺,跳出的智能搜索記錄著瀏覽行為;打開娛樂軟件,推薦算法讓用戶逐漸沉迷其中......

雖然“隱私”在數字化的世界已經無處安放,但我們卻很少去認真思考,隱私究竟是怎樣被泄露的?
近日,諾頓LifeLock實驗室研究后發現,超過8成帶有搜索欄的網站會將訪問者的搜索字詞泄露給谷歌等在線廣告商。
很明顯這是在赤裸裸地侵犯用戶隱私,并公然將敏感信息泄露給龐大的第三方服務商,借助這些信息,谷歌等在線廣告商可以提供有針對性的廣告或跟蹤用戶的網絡行為。這些數據甚至有可能在這些服務商之間共享,又或者是多次轉手出售給更多的企業,由此帶來的惡果是,用戶的隱私信息將會一直存在互聯網上,一直被曝光。
雖然一些網站可能會在其用戶政策中聲明這種做法,但訪問者通常不會閱讀這些內容,并認為他們在嵌入式搜索字段中輸入的信息是與大數據代理隔離的。
用爬蟲發現信息泄露
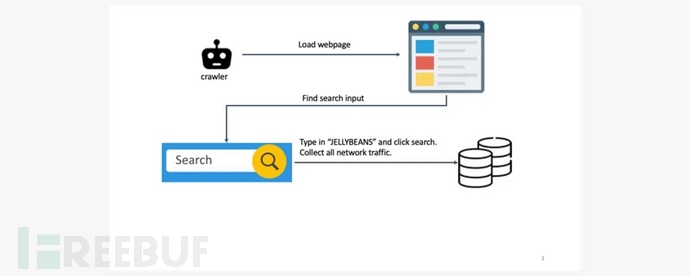
為了研究用戶隱私信息泄露的普遍程度,諾頓LifeLock實驗室開發了一個基于Chrome 瀏覽器的網絡爬蟲。該爬蟲可以使用前100萬個網站內部的搜索功能并執行搜索,最后搜索后捕獲所有網絡流量,以此查看用戶的搜索詞會流轉到哪里。
為了區別于其他的普通搜索,實驗室使用了一個特定的搜索詞“jellybeans”,以確保可以在網絡流量中輕松找到測試的搜索詞。
眾所周知,一個典型的 HTTP 網絡請求由三部分組成:URL、Request Header 和 payload。HTTP 請求標頭是瀏覽器自動發送的元數據(見下文),有效負載是腳本或表單請求的附加數據,可能包括更詳細的跟蹤信息,例如瀏覽器指紋或點擊流數據。
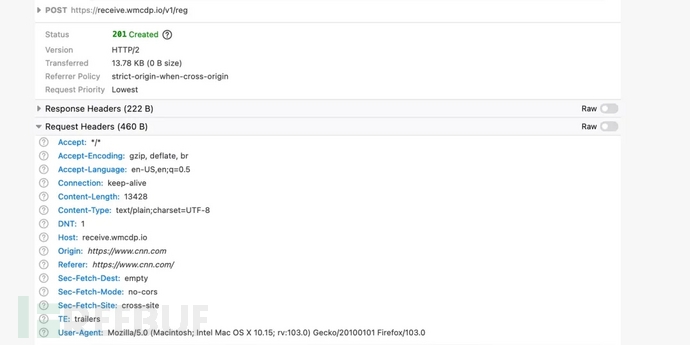
CNN 加載的廣告的 HTTP 網絡請求
在實際研究中,安全研究人員在網絡請求的Referer 請求標頭、URL 和有效負載中尋找關鍵詞“jellybeans”。
結果令人感到非常驚訝。在具有內部站點搜索功能的頂級網站中,安全研究人員發現,81.3%的網站都在以某種形式向第三方泄露搜索字詞:75.8% 的網站通過Referer標頭,71% 的網站通過URL,21.2%的網站通過有效載荷。這也就意味著網站通常會以多個向量泄露關鍵詞。
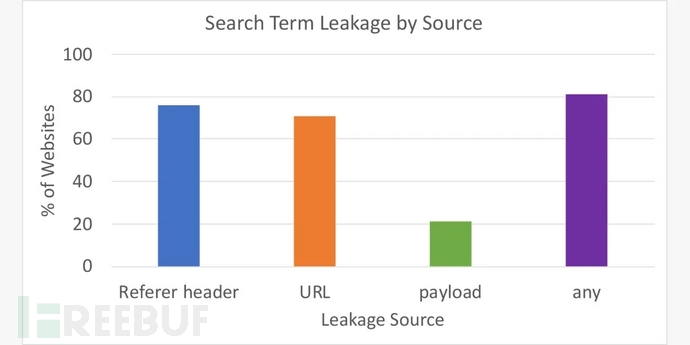
研究人員強調,八成只是最低的數字,因為他們僅在三個特定位置查找“jellybeans”搜索字符串,還有不少有效載荷被混淆以避免被工具檢查,因此有效載荷的實際數量將會更高。
鑒于如此嚴峻的結果,安全研究人員很好奇這些網站是否都告知用戶,其搜索關鍵詞將會被發給第三方服務商。事實上,自歐洲通用數據保護條例 (GDPR) 和加利福尼亞州消費者隱私法 (CCPA) 通過以來,許多網站都更新了各自的隱私政策,那么又有多少網站明確告知了這些內容?
為此安全研究人員再次使用爬蟲爬取了隱私政策,并建立了一個人工智能邏輯來閱讀隱私政策,結果發現只有13% 的隱私政策明確提到了用戶搜索詞的處理,如此之低的比例再次讓安全研究人員感到震驚。這不僅侵犯了用戶隱私,而且還侵犯了用戶的知情同意權。
參考來源:https://www.nortonlifelock.com/blogs/norton-labs/search-privacy-research













