云上 OLAP 引擎查詢性能評估框架:設計與實現

背景
公有云是一種為用戶提供經濟方便的計算資源的平臺。隨著云計算技術的快速發展,以及大數據查詢需求的日益增加,很多公有云的云計算應用市場中,出現了越來越多云上 OLAP 引擎服務。為了能夠根據自己的業務需求選擇合適的 OLAP 引擎,并通過合適的配置使引擎在最佳狀態運行,用戶需要對當前使用的查詢引擎性能進行評估。
當前 OLAP 引擎性能評估框架在云上部署使用時面臨三個主要挑戰:
- 對云環境適應能力弱。傳統性能評估框架誕生時,尚未具備云上特有的 PaaS、IaaS、SaaS 特性,也不具備對存算分離的適配支持。使用云上 OLAP 時,需要充分利用云計算特性分析 OLAP 引擎性能。
- 不具備復雜工作負載的復現能力。工作負載由數據集、查詢集、查詢序列組成。傳統的性能評估框架通常采用固定的數據集和查詢級,查詢序列也主要以線性序列為主。現代 OLAP 查詢場景的復雜化,對特定場景下的數據集和查詢集的特征刻畫、高并發復雜場景支持等,提出了更高的要求。
- 難以全面評估查詢性能與上云成本。傳統評估體系(如 TPC-H、TPC-DS)不體現成本因素,而在云上資源近乎無限的大環境里,不考慮成本的評估會造成很大的偏見,甚至得出錯誤的結論。云計算具備自定義租用服務器規模的特性,因此云上成本是可變、可設置的,其單價也隨時間波動。用戶既希望 OLAP 查詢能以最快的速度被執行,又希望能盡可能節省成本,因此需要性能評估框架全面評估查詢性能與上云成本,根據用戶需求提供最具性價比的云服務器與 OLAP 引擎搭配方式。
針對上述問題,南京大學顧榮老師、吳侗雨博士等人與 Apache Kylin 社區團隊聯合研究,設計開發一套云上 OLAP 引擎查詢性能評估框架,名為 Raven。
Raven 被設計來幫助用戶回答一些 OLAP 引擎上云面臨的實際而又重要的問題:
- 對于一份真實生產數據中的真實工作負載(數據載入 + 查詢),哪個 OLAP 引擎在云上運行的 IT 成本更低?
- 給定一個查詢速度的目標,在能達成的速度目標的前提下,哪個 OLAP 引擎在云上能給出更低的 IT 成本?
- 再加上考慮數據載入速度的因素,情況又會如何?
本文將介紹本團隊在設計與實現 Raven 時遇到的問題、對應的解決方案、以及當前的初步研究成果。
適應云架構的性能評估框架設計
OLAP 引擎查詢性能評估框架適配云架構時,實際上是在適配云上的 PaaS、IaaS、SaaS 特性。具體而言,云服務器的很多功能都以服務的方式呈現給用戶,用戶只需要調用對應服務的接口,即可實現不同的目的,如云服務器創建、文件操作、性能指標獲取、應用程序執行等。在文件操作中,由于云服務器采用計算存儲分離的架構,一些數據可能需要通過服務從遠程的云存儲服務上拉取。
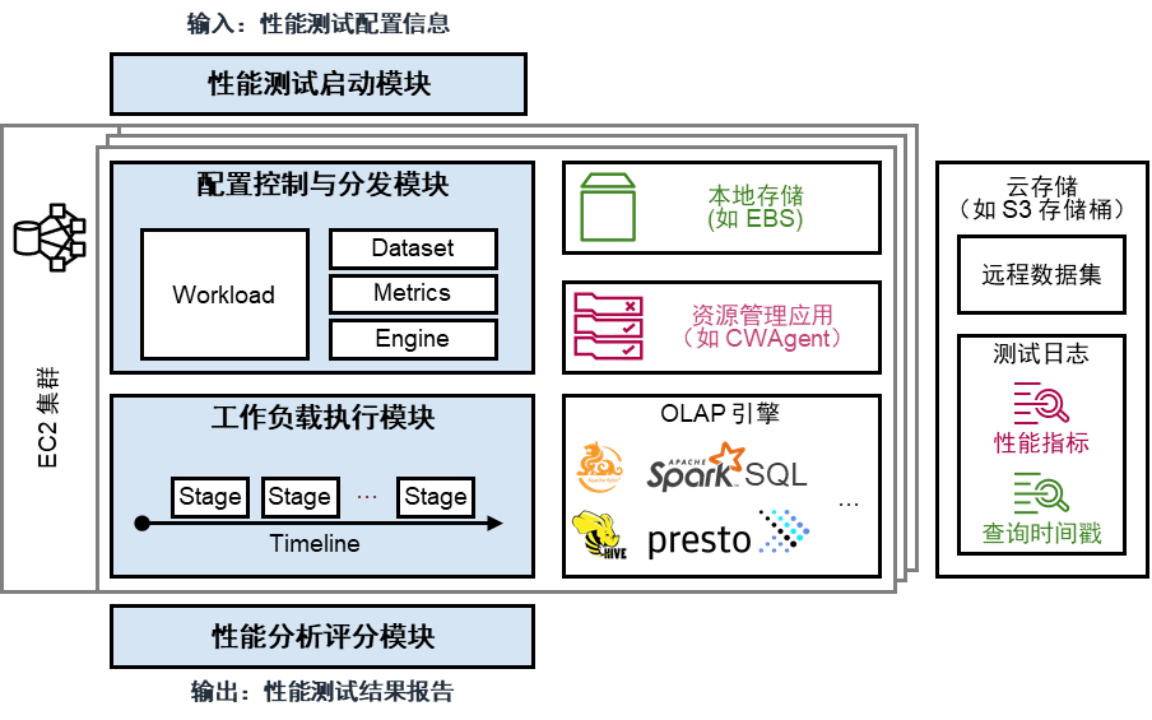
圖 1:基于公有云平臺的 Raven 性能評估框架
結合上述需求,Raven 的框架如圖 1 所示。其執行步驟如下:
- 用戶輸入性能測試配置信息,觸發性能測試啟動模塊,該模塊負責根據用戶配置創建啟動云上 OLAP 性能測試所需的云服務器和計算環境。
- 性能測試啟動模塊將工作負載、數據集、性能指標、引擎參數等信息傳遞給配置控制與分發模塊,該模塊負責將上述信息分發到對應的服務接口或模塊上。
- 配置控制與分發模塊觸發工作負載執行模塊,工作負載執行模塊啟動配置好的 OLAP 引擎,并根據工作負載設置隨時間向 OLAP 引擎發送查詢請求。
- OLAP 引擎向本地存儲或云存儲拉取數據集,執行查詢。查詢執行過程中,工作負載執行模塊記錄查詢開始和結束的時間戳,并啟動資源管理服務,監控 OLAP 引擎查詢期間的性能指標。查詢結束時,工作負載執行模塊將時間戳和性能指標信息輸出到云存儲中。
- 啟動性能分析評分模塊,從遠程云存儲中拉取時間戳和性能指標信息,導入用戶自定義的評分模型,得到最終的性能評估結果。
上述設計的優點在于:
- 充分利用可自定義的云服務器數量和配置,允許用戶自定義其希望創建的集群環境。
- 支持向遠程的云存儲服務讀寫數據,適應云環境的存算分離架構。
- 使用云服務提供商的資源管理服務,得以獲取大量系統資源使用狀況的信息。
- 支持可插拔的引擎接口,用戶可任意指定其所需測試的 OLAP 引擎及其配置。
實際使用時,用戶的輸入以一個.yaml 文件呈現,可仿照如下格式:
- engine: kylin
- workload: tpc-h
- test_plan: one-pass
- metrics: all
用戶需要的云服務器數量、每臺機器的配置、不同的引擎等,均可通過 JSON 文件配置。
基于事件和時間戳的工作負載設計
傳統的 OLAP 查詢引擎通常采用固定的數據集和查詢集,并執行一系列的查詢,查看 OLAP 引擎的查詢性能。然而,當前很多行業的工作負載正更加復雜。
- 越來越多的企業意識到自身數據及業務具有鮮明特征,希望能夠在給定的數據特征下獲得最佳的 OLAP 查詢方案。
- 除了傳統的 OLAP 查詢外,越來越多的預計算技術,如 ETL、索引、Kylin 的 Cube 等,亟待納入到 OLAP 引擎性能的考察中。
- 數據量的快速增長使得高并發查詢、QPS 可變查詢的場景越來越多,傳統的線性查詢方法很難上述新場景進行準確評估。
Raven 使用了一種基于時間線的事件機制描述復雜的 OLAP 工作場景。該機制下,一個工作負載由多個階段構成,一個階段由多個事件構成。在時間線上,一個工作負載被描述為若干個階段的順序執行。每個階段分為線上階段和線下階段兩種:線上階段執行實際的查詢請求,線下階段執行預計算等操作。事件是對工作負載中每一個原子執行單元的抽象,可以是查詢請求、shell 命令,或用 Python 等編程語言編寫的腳本。
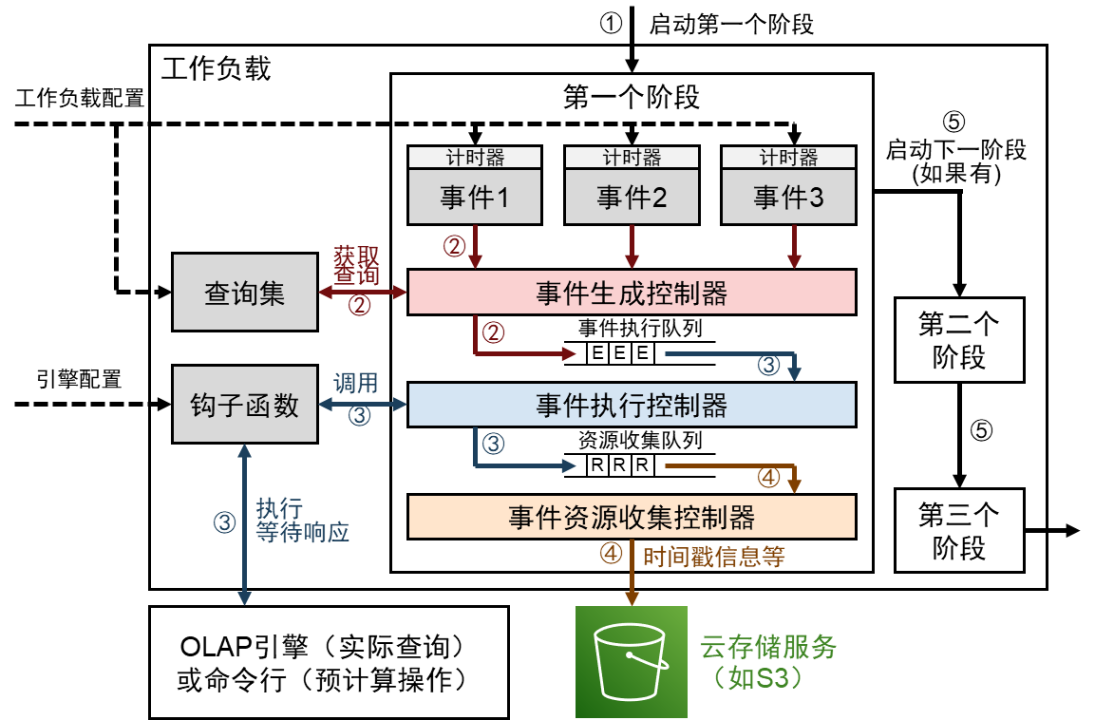
圖 2:Raven 工作負載的執行過程
Raven 的工作負載如圖 2 所示。其執行步驟如下:
- 啟動第一個階段,加載工作負載配置、引擎配置等;
- 當事件的計時器被觸發時,將時間事件生成控制器,讀取該事件對應的查詢語句或腳本內容,進入事件執行隊列,等待執行。
- 出事件執行隊列后,進入事件執行控制器,開啟線程執行鉤子函數,與 OLAP 引擎或命令行執行交互操作,并等待響應,得到響應后將事件插入到資源收集隊列中。
- 出資源收集隊列后,進入事件資源收集控制器,將操作的時間戳信息輸出到云存儲服務上。
- 當該階段內所有時間完成后,啟動下一個階段,然后按順序執行每個階段,直到整個工作負載結束。
上述設計的優點在于:
- 支持自定義數據集和查詢集,允許用戶充分利用其業務特點進行性能評估。
- 支持預計算,允許用戶評估預計算和實際查詢的整體性能。
- 帶時間戳的執行方法和線程管理策略,支持高并發查詢,允許模擬 QPS 隨時間波動的工作負載。
舉個例子,可以使用如下的 .yaml 配置文件,在 AWS 上啟動一主四從的 EC2 集群,并部署 Presto 引擎,指定數據集為 SSB(SF=100)且工作負載滿足泊松分布(λ=3.0),工作負載持續時間為 600 秒:
Cloud:
- Name: AWS
- Description: Amazon Web Service.
Properties:
- Region: ap-southeast-1
- Ec2KeyName: key_raven
- MasterInstaceCount: 1
- MasterInstanceType: m5.xlarge
- CoreInstanceCount: 4
- CoreInstanceType: m5.4xlarge
Engine:
- Name: presto
- Description: Presto.
- Properties:
- host: localhost
- port: 8080
- user: hive
- catalog: hive
- concurrency: 1
Testplan:
- Name: Timeline template.
Properties:
- Type: Timeline
- Path: config/testplan/template/timeline_template.yaml
Workload:
- Name: SSB
- Type: QPS
Parameters:
- database: ssb_100
- distribution: poisson
- duration: 600
- lam: 3.0
Raven 預置了一些常見工作負載供用戶使用,如均勻分布、突發高并發分布等。
基于自定義多元函數的性能評估模型
在性能評估方面,云上機器的一個特點是大小、配置可自定義調節。因此,如果只考慮查詢性能,理論上可以通過租用大量的高性能設備提升性能。但是,這樣也會造成云上計算成本飆升。因此,需要一套機制實現性能和成本的平衡和綜合考慮。
Raven 的性能評估方法是高度自定義的,允許用戶根據可以獲取的參數指標,使用函數表達式組合起來,得到一個評估分數。
Raven 中可獲取的參數指標主要有以下幾類:
- 查詢質量指標:包括所有查詢的總查詢時間、平均查詢時間、查詢時間 95% 分位數、最大查詢時間;
- 資源使用效率:內存和 CPU 的平均使用率、負載均衡、資源占用率超過 90% 的時間占總時間的比例;
- 云上金錢成本:可直接通過云服務商提供的應用服務獲取,主要包含四個部分的開銷:存儲、計算、服務調用、網絡傳輸。
Raven 給出的評分是相對的,只能在相同模型的評分之間進行比較。性能評估得分是云上成本和云上開銷的乘積,評分越低,OLAP 引擎的性能越好。云上開銷可使用線性模型,對上述參數賦予權重計算;也可使用非線性模型,將上述參數代入到一個函數表達式中。
Raven 也為用戶提供了一系列模板函數:
- 綜合模型:PTO=10×ln(PoC×(ravg+qavg))PTO=10×ln?(PoC×(ravg+qavg)).
- 速度優先模型:PTO=10×ln(ravg+qavg)PTO=10×ln?(ravg+qavg)
- 預算優先模型:PTO=11+e8(b?PoC)×(ravg+qavg)PTO=11+e8(b?PoC)×(ravg+qavg)
- 查詢效率模型:PTO=PoC×qmax+5q95%+94qavg100PTO=PoC×qmax+5q95%+94qavg100
- 查詢阻塞模型:PTO=PoC×ln(rmax )PTO=PoC×ln?(rmax )
其中,PTO 表示性能評分,PoC 表示云上成本,ravgravg、qavgqavg 分別表示平均響應時間和平均執行時間,rmaxrmax、qmaxqmax 分別表示最大響應時間和最大執行時間,b 表示預算金額,q95%q95% 表示查詢時間 95% 分位數。這里我們結合回顧下前文提出用戶需要關注的幾個際問題,不難看出,預算優先模型主要用于評估和回答:哪個 OLAP 引擎在云上運行的 IT 成本更低?速度優先模型、查詢效率模型、查詢阻塞模型主要用于評估和回答:在滿足不同查詢響應等約束的情況下,哪個 OLAP 引擎的云上運行成本更低?綜合模型則是通過設置不同權重來綜合考慮成本預算和查詢響應效率的評估 OLAP 引擎的云上性能模型。
實現與效果驗證
我們在亞馬遜 AWS 上實現了 Raven 的上述設計,并使用該性能評估框架執行 OLAP 引擎,查看不同引擎的查詢效果。
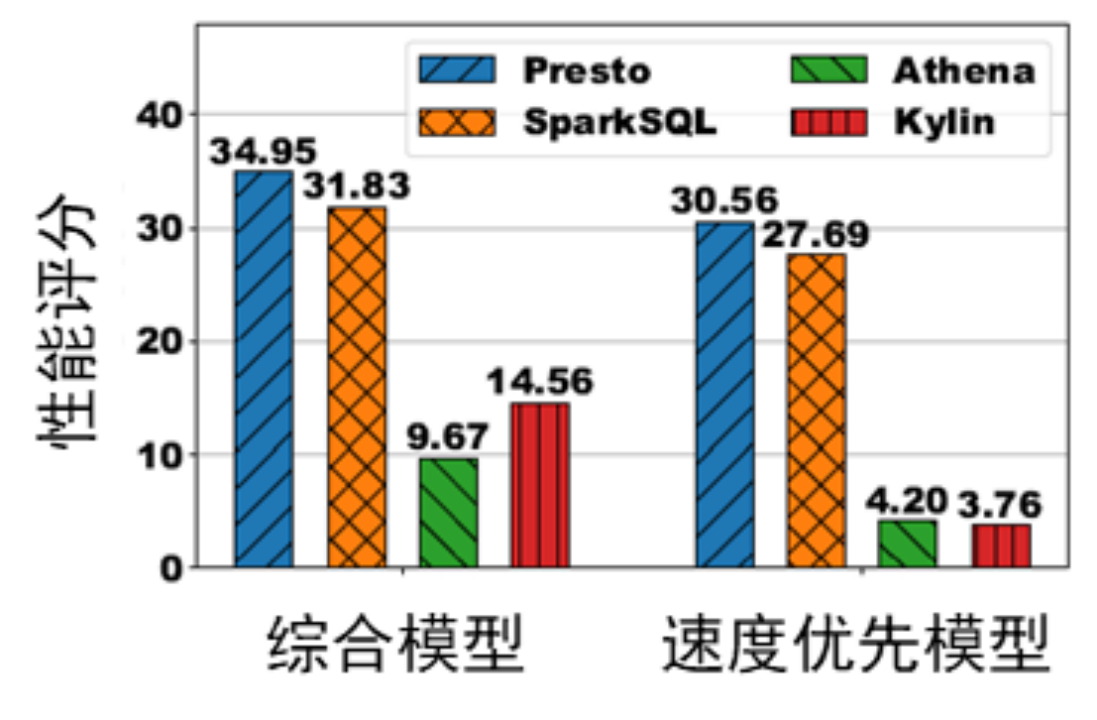
圖 3:不同引擎在不同評分模型下,運行均勻查詢 10 分鐘的性能評分
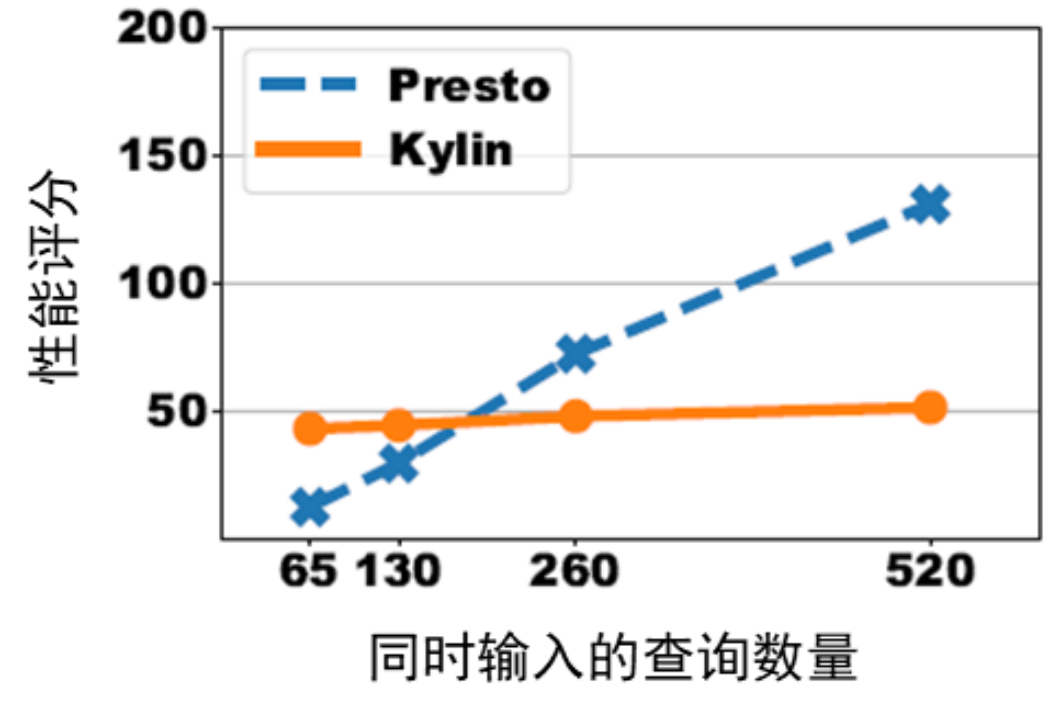
圖 4:在 Presto 和 Kylin 上運行突發高并發分布的性能評分
從圖 3 中可以看出,運行均勻查詢時,Athena 和 Kylin 是較好的解決方案。但是,使用不同模型會得到不同的評估結論。當綜合考慮查詢速度的云上成本時,由于 Athena 直接通過調用服務執行查詢,因此云上成本較低,評分也更低。但是,當優先考慮速度時,由于 Kylin 使用預計算技術實現了高速查詢,因此使用速度優先模型時,Kylin 的評分更低。
從圖 4 可以看出,運行突發高并發分布時,若采用查詢阻塞模型,隨著同時輸入的查詢數量增加,Presto 的性能評分隨查詢數量增加線性增長;但是,Kylin 并未受到查詢數量增加的影響,性能評分保持穩定。這是因為 Kylin 的預計算技術提升了計算效率,當查詢大量涌入時,Kylin 能以更高的效率處理這些查詢,減少查詢在隊列中的阻塞,使性能評分更為出色。當然,如果用戶集中的查詢數量不大,Presto 的性能評分更有優勢,因為其沒有預計算的相關開銷。
未來展望
未來的研究主要考慮以下方面:
- 應用實現更多引擎,嘗試兼容云原生引擎,以進行性能評估。
- 優化工作負載的表達形式,使用戶可以根據自己的業務需求,更容易地開發出多樣化、具代表性的工作負載。
- 形成更多標準化的評分模型,供不同工作負載之間的橫向對比。
- 結合當前評分結果,進一步分析不同 OLAP 引擎的性能優劣。