ProGAN、StyleGAN、Diffusion GAN…你都掌握了嗎?一文總結圖像生成必備經典模型
生成模型是一種訓練模型進行無監督學習的模型,即,給模型一組數據,希望從數據中學習到信息后的模型能夠生成一組和訓練集盡可能相近的數據。圖像生成(Image generation,IG)則是指從現有數據集生成新的圖像的任務。圖像生成模型包括無條件生成和條件性生成兩類,其中,無條件生成是指從數據集中無條件地生成樣本,即p(y);條件性圖像生成是指根據標簽有條件地從數據集中生成樣本,即p(y|x)。
圖像生成也是深度學習模型應用比較廣泛、研究程度比較深的一個主題,大量的圖像庫也為SOTA模型的訓練和公布奠定了良好的基礎。在幾個著名的圖像生成庫中,例如CIFAR-10、ImageNet64、ImageNet32、STL-10、CelebA 256、CelebA64等等,目前公布出的最好的無條件生成模型有StyleGAN-XL、Diffusion ProjectedGAN;在ImageNet128、TinyImageNet、CIFAR10、CIFAR100等庫中,效果最好的條件性生成模型則是LOGAN、ADC-GAN、StyleGAN2等。

我們在這篇文章中介紹圖像生成必備的TOP模型,從無條件生成模型和條件性生成模型兩個類別分別介紹。圖像生成模型的發展非常快,所以與其它幾個topic不同,圖像生成中必備的TOP模型介紹主要以近兩年的SOTA模型為主。
一、無條件生成模型
1.1 ProGAN
生成性對抗網絡(GAN)是機器學習中一個相對較新的概念,于2014年首次引入。GAN的目標是合成與真實圖像無法區分的人工樣本,如圖像。GAN的基本組成部分是兩個神經網絡:一個新樣本的生成器(G),一個從訓練數據和生成器輸出中提取樣本并預測它們是“真”還是“假”的鑒別器(D)。生成器的輸入是一個隨機向量(噪聲),因此其初始輸出也是噪聲。隨著訓練的進行,當它收到鑒別器的反饋時,會學習合成更“真實”的圖像。鑒別器還通過將生成的樣本與真實樣本進行比較,隨著訓練的進行不斷改進,使得生成器更難欺騙它。
ProGAN是NVIDIA投稿ICLR 2018的一篇文章,ProGAN關鍵創新在于漸進式訓練,它在經典GAN的基礎上首先通過學習在低分辨率圖像中也可以顯示的基本特征,來創建圖像的基本部分,并且隨著分辨率的提高和時間的推移,學習越來越多的細節。低分辨率圖像的訓練不僅簡單、快速,而且有助于更高級別的訓練,因此,整體的訓練也就更快。ProGAN被認為是后來大熱的StyleGAN的前身。

圖1 ProGAN架構
ProGAN的訓練部分,從低分辨率的圖像開始,通過向網絡添加層來逐步提高分辨率,如圖2所示。這種遞增的性質允許訓練首先發現圖像分布的大規模結構,然后將注意力轉移到越來越精細的細節上,而不是同時學習所有的尺度。使用生成器和鑒別器網絡,它們是彼此的鏡像,并且總是同步增長。在整個訓練過程中,兩個網絡中的所有現有層都是可訓練的。當新的層被添加到網絡中時,平穩地將它們淡化,如圖3所示。這就避免了對已經訓練好的小分辨率層的突然沖擊。

圖2 訓練開始時,生成器(G)和鑒別器(D)的空間分辨率都很低,只有4×4像素。隨著訓練的進行,逐步增加G和D的層數,從而提高生成圖像的空間分辨率

圖3 當生成器(G)和鑒別器(D)的分辨率翻倍時,順利地淡化新層。這個例子說明了從16×16圖像(a)到32×32圖像(c)的過渡。在過渡期間(b),把在更高的分辨率上操作的層當作一個殘差塊,其權重α從0到1線性增加
GAN還有一個問題是只捕捉訓練數據中發現的變化的一個子集,mini-batch就是為了解決這個問題提出的,它是通過在鑒別器的末尾添加一個minibatch層來實現的,該層學習一個大的張量,將輸入激活投射到一個統計數組。mini-batch中的每個樣本都會產生一組單獨的統計數據,并將其串聯到該層的輸出中,這樣鑒別器就可以在內部使用這些統計數據。
ProGAN的簡化方案既沒有可學習的參數,也沒有新的超參數,而是引入了特征的標準差作為衡量標準。首先計算每個特征在每個空間位置上的標準偏差。然后,在所有特征和空間位置上平均這些估計值,得到一個單一的值。復制這個值并將其連接到所有的空間位置和minibatch上,產生一個額外的(恒定)特征圖。這一層可以插入鑒別器的任何地方,將其在最后插入效果最好。這個特征圖中包含了不同樣本之間的差異性信息,送入鑒別器后,經過訓練,生成樣本的差異性也會與訓練樣本的相似。
此外,ProGAN還對生成器和鑒別器進行了歸一化處理,歸一化主要是用來控制信號幅度,從而減少G與D之間的不正常競爭,沿channel維度對每個像素的特征長度歸一化。minibatch statistic layer沿著batch維度求標準差,而它沿著channel維度求norm。
當前 SOTA!平臺收錄ProGAN共 1 個模型實現資源。

項目 | SOTA!平臺項目詳情頁 |
ProGAN | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/0190e1fa-5643-4043-8b75-9b863a6d20db |
1.2 StyleGAN
StyleGAN是一種開創性的工作,不僅可以生成高質量和逼真的圖像,還可以對生成的圖像進行更好的控制和理解,從而比以前更容易生成可信的假圖像。StyleGAN是ProGAN圖像生成器的升級版本,重點關注生成器網絡(G)。
StyleGAN的重點就是“Style”,在提出StyleGAN的論文中具體是指人臉的風格,包括人臉表情、人臉朝向、發型等等,還包括紋理細節上的人臉膚色、人臉光照等。進一步對這些Style進行細分為:1)粗-分辨率高達8*8-影響姿勢、一般發型、人臉形狀等;2)中等-分辨率16*16到32*32-影響更精細的人臉特征、發型、睜眼/閉眼等;3)精細-分辨率為64*64到1024*1024-影響配色方案(眼睛、頭發和皮膚)和微觀特征。

圖4 StyleGAN結構
StyleGAN 的網絡結構包含兩個部分,第一個是Mapping network,即圖 4(b)的左部分,由潛在變量 z 生成中間潛在變量 w的過程,w用來控制生成圖像的style。第二個是Synthesis network,它的作用是生成圖像,創新之處在于給每一層子網絡都輸入A 和 B,A 是由 w 轉換得到的仿射變換,用于控制生成圖像的style,B 是轉換后的隨機噪聲,用于豐富生成圖像的細節,即每個卷積層都能根據輸入的A來調整"style"。整個網絡結構還是保持了 ProGAN 的結構。經典GAN的隨機變量或者潛在變量 z是通過輸入層,即前饋網絡的第一層提供給生成器的(圖4a)。而StyleGAN完全省略了輸入層,直接從一個學習的常數開始(圖4b,右),即將 z 單獨用 mapping網絡變換成w,再將w輸入給 Synthesis network的每一層。
Mapping network 要做的事就是對潛在空間(latent space)進行解耦,Mapping network由8個全連接層組成,其輸出與輸入層的大小相同。通過一系列仿射變換,由 z 得到 w,這個 w 轉換成風格y=(ys,yb) ,結合 AdaIN (adaptive instance normalization) 風格變換方法:

使用輸入向量控制視覺特征的能力是有限的,因為它必須遵循訓練數據的概率密度。例如,如果黑發人的圖像在數據集中更常見,則更多輸入值將映射到該特征。因此,該模型無法將部分輸入(向量中的元素)映射到特征,這種現象稱為特征糾纏。然而,Mapping network通過使用另一個神經網絡,可以生成一個不必遵循訓練數據分布的向量,并且可以減少特征之間的相關性。
具體到AdaIN(也稱為Style模塊),該模塊被添加到生成網絡的每個分辨率級別,并定義該級別中特征的視覺表達:首先對卷積層輸出的每個通道進行正則歸一化,以確保縮放和移位達到預期效果;然后,使用另一個全連接層轉換為每個通道的比例和偏差;最后,將尺度變化和偏置移動作用于卷積輸出的每個通道,從而定義卷積中每個濾波器的重要性。利用AdaIN實現了將信息從潛在變量轉化為一種視覺表現。在StyleGAN中,可以省略初始隨機噪聲輸入,用常量值替換。這種操作減少了特征糾纏,因為網絡不再依賴于互相糾纏的輸入向量。AdaIN 層的含義同BN層類似,其目的是對網絡中間層的輸出結果進行scale和shift,以增加網絡的學習效果,避免梯度消失。相對于BN是學習當前batch數據的mean和variance,Instance Norm則是采用了單張圖片。AdaIN則是使用learnable的scale和shift參數去對齊特征圖中的不同位置。
具體到人臉圖像生成任務,人臉有很多的特征都很小且可以看作是隨機的,例如雀斑、頭發的精確位置、皺紋等,這些可以使圖像更逼真,并增加輸出的多樣性。將這些小特征插入GAN圖像的常用方法是向輸入向量添加隨機噪聲。然而,在許多情況下,由于上述特征糾纏現象,很難控制噪聲效果,這會導致圖像的其他特征受到影響。StyleGAN中的噪聲以與AdaIN機制類似的方式添加,即在AdaIN模塊之前向每個通道添加控制縮放的噪聲,并稍微改變其操作分辨率級別特征的視覺表達。
為了進一步定位Style,引入混合正則化的處理方式,即在訓練過程中,一定比例的圖像是使用兩個隨機潛在變量而不是一個潛在變量生成的。在生成這樣的圖像時,只需在生成網絡中隨機選擇一個點,從一個潛在變量切換到另一個潛在變量即Style mix。具體的,通過mapping network運行兩個潛在變量z1、z2,并讓相應的w1、w2控制style,使w1在crossover point之前適用,w2在crossover point之后適用。這種正則化技術可以防止網絡假設相鄰的風格是相關的。
最后,針對特征解糾纏(disentanglement)問題,對于disentanglement各種定義的共同的目標是由線性子空間組成的隱藏空間,每個子空間控制一個變化因素。然而,Z中每個因素組合的采樣概率需要與訓練數據中的相應密度相匹配。如圖5所示,因素無法與典型的數據集和輸入的潛在分布完全分離。

圖5. 有兩個變化因素(圖像特征,如男性化和頭發長度)的說明性示例。(a) 一個樣本訓練集,其中一些組合(如長發男性)是缺失的。(b) 這迫使從Z到圖像特征的映射變得彎曲,以便被禁止的組合在Z中消失,以防止無效組合的采樣。(c) 從Z到W的學習映射能夠 "撤銷 "大部分的彎曲
為了量化特征分離的表現,本文提出了量化兩種特征分離的新方法:
1)感知路徑長度:在兩個隨機輸入之間插值時,測量連續圖像之間的差異。劇烈的變化意味著多個功能一起發生了變化,它們可能會相互糾纏。
2)線性可分性:將輸入分類為二元類的能力,如男性和女性。分類越好,特征越可分離。
當前 SOTA!平臺收錄StyleGAN共 75 個模型實現資源。

項目 | SOTA!平臺項目詳情頁 |
StyleGAN | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/e072cfc0-26c3-40e7-a979-60df61170c7a |
1.3 StyleGAN2
StyleGAN2是為了應對StyleGAN的問題而提出的:少量生成的圖片有明顯的水珠(water-droplet artifacts),這個水珠也存在于feature map上。導致水珠的原因是 AdaIN,AdaIN對每個feature map進行歸一化,因此有可能會破壞掉feature之間的信息。作者認為出現droplet artifact的原因是生成器有意將信號強度信息隱藏再實例歸一化后的結果中:通過創建一個強大的、局部的尖峰來控制統計數據,生成器可以有效地縮放信號。

圖6 StyleGAN存在的水珠問題

圖7 重新設計StyleGAN synthesis network 。(a) StyleGAN,A表征生成style的學習映射變換,B為噪聲廣播操作;(b) StyleGAN的詳細表述,其中,將AdaIN拆分以更加明確歸一化操作,兩者均基于每個特征圖的平均值和標準偏差;(c)StyleGAN2架構,在開始時刪除了一些冗余操作,將b和B的添加移動到style的活動區域之外,并僅調整每個特征映射的標準偏差;(d) 將實例歸一化替換為“demodulation”操作,將其應用于與每個卷積層相關聯的權重
修改StyleGAN的生成器。首先,StyleGAN2將AdaIN重構為Weight Demodulation。如圖7(d)所示,modulation根據傳入的style對卷積的每個輸入特征圖進行縮放,也可以通過縮放卷積權重來實現:

其中,w和w’分別表征原始的和modulated的權重,s_i為對應第i個輸入特征圖的尺度,j和k分別表示生成輸出特征圖和卷積的空間分布圖。接著對卷積層的權重進行demod:

從而得到新的卷積層權重為:

加一個小的?是為了避免分母為0,保證數值穩定性。盡管這種方式與Instance Norm并非在數學上完全等價,但是weight demodulation同其它normalization 方法一樣,使得輸出特征圖有著standard的unit和deviation。此外,將scaling參數挪為卷積層的權重使得計算路徑可以更好的并行化。這種方式使得訓練加速了約40%。
第二,雖然諸如FID或精確率和召回率(Precision and Recall,P&R)等GAN指標成功地捕獲了生成器的許多方面,但它們在圖像質量方面仍然有一些盲點。感知圖像質量和感知路徑長度(perceptual path length,PPL)之間的相關性指標最初是用來量化從潛在空間到輸出圖像的映射的平滑度,通過測量潛在空間的小擾動下生成的圖像之間的平均LPIPS距離來實現。更小的PPL(更平滑的發生器映射)似乎與更高的整體圖像質量相關,而其他指標則對此并不敏感。為什么低PPL會與圖像質量相關,這一點尚不明確。作者假設,在訓練過程中,由于鑒別器對broken image進行懲罰,則改進生成器的最直接方式是有效地拉伸能夠產生良好圖像的潛在空間區域。
作者通過引入regularization的方式實現上述目標。StyleGAN2使用lazy regularization的策略,即對數據分布開始跑偏的時候才使用R1 regularization,其它時候不使用。Path Length Regularization的意義是使得latent space的插值變得更加平滑和線性。簡單來說,當在latent space中對latent vector進行插值操作時,我們希望對latent vector的等比例的變化直接反映到圖像中去。即:“在latent space和image space應該有同樣的變化幅度(線性的latent space)”(比如說,當你對某一組latent vector進行了5個degree的偏移,那么反映在最后的生成圖像中,應該是同樣的效果)。
最后,與StyleGAN第一代使用progressive growing的策略不同,StyleGAN2開始尋求其它的設計以便于讓網絡更深,并有著更好的訓練穩定性。progressive growing的關鍵問題是,逐漸演進的生成器會對細節有著強烈的位置偏好;當像牙齒或眼睛這樣的特征應該在圖像上平滑移動時,它們反而可能在跳到下一個首選位置之前停留在原地。如圖8所示。

圖8. progressive growing會導致 "相位 "偽影。在這個例子中,牙齒沒有跟隨姿勢,而是與相機保持一致,如藍線所示
為此,作者重新評估了StyleGAN的網絡設計,并尋找一種能生成高質量圖像而又不會逐漸增長的架構。如圖9所示,作者對比了MSG-GAN、對不同分辨率的RGB輸出的貢獻進行上采樣和求和、殘差連接。StyleGAN2采用了類似ResNet的殘差連接結構(residual block),使用雙線性濾波對前一層進行上/下采樣,并嘗試學習下一層的殘差值(residual value)。通過一個resnet風格的skip connection在低分辨率的特征映射到最終生成的圖像(圖9(c)的綠色block)。

圖9. 三個生成器(虛線以上)和鑒別器的結構。上面和下面分別表示雙線性上采樣和下采樣。在殘差網絡中,這些還包括一個1×1的卷積,以調整特征圖的數量
當前 SOTA!平臺收錄 StyleGAN2 共 1 個模型實現資源。

項目 | SOTA!平臺項目詳情頁 |
StyleGAN2 | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/a07f5a80-bf97-4a33-a2a8-4ff938b1b82f |
1.4 StyleGAN3
對于StyleGAN系列來說,生成網絡是整體訓練的,深層網絡特征的空間位置并不是由淺層網絡特征很強的控制,而是還受到監督信息(如對抗損失、重構損失等)的決定性的影響,粗糙特征(GAN的淺層網絡的輸出特征)主要控制了精細特征(GAN的深層網絡的輸出特征)的存在與否,沒有嚴格控制他們出現的精確位置。按照作者所說:“畫面上的細節似乎被粘在了圖像坐標上,而不是被描述的物體表面。”。作者認為,其根本原因是信號處理導致了生成網絡的aliasing。StyleGAN3主要是為了解決這一問題提出的,即實現高質量的 Equivariance(等變性)。所以,StyleGAN3的標題為 Alias-Free GAN。
StyleGAN2生成器由兩部分組成。首先,一個映射網絡將初始的、正常分布的latent轉換為 intermediate latent code w~W。然后,一個synthesis網絡G從學習的4×4×512常數Z0開始,應用N層處理—包括卷積、非線性、上采樣和per-pixel噪聲—以生成輸出圖像Z_N=G(Z0;w)。intermediate latent code w控制G中卷積核的調制。各層遵循嚴格的2×上采樣,在每個分辨率下執行兩個層,每次上采樣后特征圖的數量減半。此外,StyleGAN2采用了skip connection、 mixing regularization和 path length regularization 。StyleGAN3目標是使G的每一層對連續信號都是Equivariance的,這樣所有較細的細節就會與局部鄰域的較粗的特征一起轉化。如果這成功了,整個網絡也會變得類似于Equivariance。換句話說,目標是使synthesis網絡的連續操作g對應用于連續輸入z0的變換t(平移和旋轉)具有Equivariance:

其中 t 是一種變換(平移或旋轉),上式表明生成器對特征信號的連續運算應該對于平移和旋轉操作是等變的。改進后的生成器網絡結構圖見圖10。

圖10 (a) 2×上采樣濾波器的一維例子,n = 6, s = 2, fc = 1, fh = 0.4(藍色)。設置fh=0.6使得過渡帶更寬(綠色),這減少了不需要的阻帶紋波,從而導致更強的衰減。(b) alias-free生成器,對應于配置T和R。主要的數據路徑包括傅里葉特征和歸一化,調制卷積和過濾非線性。(c) Flexible layer specification(配置T),N=14,sN=1024。截止點fc(藍色)和最小可接受的阻帶頻率ft(橙色)服從各層的幾何級數;采樣率s(紅色)和實際阻帶fc+fh(綠色)是根據設計約束計算出來的
首先是將StyleGAN2的生成器的常數輸入替換為Fourier特征,刪除噪聲輸入,降低映射網絡深度并禁用 mixing regularization 和 path length regularization, 在每次卷積前使用簡單的歸一化。(B,C,D改進步驟)。
通過在目標空間周圍保持一個固定大小的邊界來進行近似,在每一層之后都要crop到這個擴展的空間上。用理想低通濾波器的一個更好的近似來代替雙線性上采樣:帶有較大Kaiser窗口(n=6)的 sinc 濾波器,Kaiser窗口的好處是提供了對過渡帶和衰減的明確控制。改進的邊界和上采樣得到了更好的平移Equivariance,但是FID變差了。(E改進步驟)。
由于信號是有帶限的,所以可以切換上采樣和卷積的順序,允許將常規的2×上采樣和隨后與非線性相關的m×上采樣融合到一個2m×上采樣中,并將整個upsample-LReLU-downsample過程寫到一個自定義的CUDA內核中。(F改進步驟)。
為了抑制aliasing,可以簡單地將截止頻率降低到fc = s/2 - fh,這樣可以確保所有的alias頻率(高于s/2)都在阻帶中。作者又額外加了一些trick使得FID低于了StyleGAN2。(G改進步驟)。
引入一個學習型仿射層,為輸入的傅里葉特征輸出全局平移和旋轉參數。該層被初始化為 identity transformation 。但隨著時間的推移,在有利的情況下會學習使用該機制。(H改進步驟)。
作者還設計了新的層規范化操作再次提高平移的Equivariance,目的是增強衰減來完全消除alias。(T改進步驟)。
生成一個有兩個變體的rotated equivalence網絡。首先,將所有層的3×3卷積改為1×1,并通過將特征圖的數量增加一倍來彌補容量的減少。在這個配置中,只有上采樣和下采樣操作在像素之間傳播信息。其次,用一個徑向對稱的jinc-based的濾波器取代sinc-based的下采樣濾波器,用同樣的Kaiser方案來構建這個濾波器。對所有的層都是這樣做的,除了兩個關鍵的采樣層。這兩個采樣層最重要的是要與訓練數據的potential non-radiometric spectrum相匹配。(R改進步驟)。
當前 SOTA!平臺收錄 StyleGAN3 共 2 個模型實現資源。

項目 | SOTA!平臺項目詳情頁 |
StyleGAN3 | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/6f7d3d51-762a-4d23-a572-3ea79ab49b4f |
1.5 VDVAE
VDVAE是一個層次化的VAE,它能快速生成樣本,并在所有自然圖像基準上的 log-likelihood 方面優于PixelCNN。文章論證了增加 VAE 的層數能夠在保證生成速度的情況下,實現超過自回歸模型 (AR) 的 NLL (negative log-likelihood)。VDVAE的基本假設就是:我們可以通過增加 VAE 的層數獲得更好的 VAE。首先,本文采用類似 LVAE 的并行化生成,示意圖如下:

圖11 在VAE中可能學到的不同生成模型。左圖:一個層次化的VAE可以通過使用確定性的identity functions作為編碼器來學習自回歸模型,并在先驗中學習自回歸。右圖:學習編碼器可以導致潛在變量的有效分層(黑色)。如果最下面的三組潛在變量是有條件地獨立于第一組潛在變量的,那么它們可以在一個單層內平行生成,可能會導致更快的采樣
當然了,只是單純的增加VAE的層數并不可行,作者對VAE進行了一些改進,包括減少 residual block 的維度,將殘差乘以一個常數,去掉 weight normalization, 使用 nearest-neighbour upsampling, skip 較大的 gradient 等。如圖12所示。它類似于ResNet VAE,但有bottleneck ResNet塊。對于每個隨機層,先驗和后驗是對角線高斯分布。作為權重歸一化和依賴數據的初始化的替代方案,采用默認的PyTorch權重歸一化。唯一的例外是對每個剩余bottleneck ResNet塊中的最后一個卷積層,將其按1/sqrt(N)進行擴展,其中N是深度。此外,對 "unpool "層使用了最近鄰的上采樣,當與ResNet架構配對時,可以完全消除相關工作中出現的 "free bits "和KL "warming up "。當上采樣通過轉置卷積層進行時,網絡可能會忽略低分辨率的層(例如,1x1或4x4層)。

圖12. 自上而下的VAE架構的圖示。殘差塊類似于bottleneck ResNet塊。q_φ(.)和p_θ(.)是對角線高斯分布。使用平均池化和最近鄰上采樣來進行池化和非池化層的處理
當前 SOTA!平臺收錄 VDVAE 共1個模型實現資源。

項目 | SOTA!平臺項目詳情頁 |
VDVAE | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/0ed2229c-722b-47fb-b6aa-d22dedf87f1b |
1.6 NCP-VAE
VAE是強大的基于似然的生成模型之一,在許多領域的應用都取得了很好的效果。然而,它們很難生成高質量的圖像,特別是當從先驗中獲得的樣本沒有任何調節時。對VAEs生成質量差的一個解釋是 prior hole 問題:先驗分布不能與總的近似后驗相匹配。由于這種不匹配,潛在空間中存在著在先驗下具有高密度的區域,而這些區域并不對應于任何編碼的圖像。來自這些區域的樣本被解碼為損壞的圖像。為了解決這個問題,作者提出了一個基于能量的先驗,其定義是基數先驗分布與reweighting factor的乘積,目的是使基數更接近總后驗。通過噪聲對比估計來訓練reweighting factor,并將其推廣到具有許多潛在變量組的分層VAEs。
這項工作的關鍵點在于,作為訓練VAE的結果,可訓練的先驗被盡可能地接近 aggregate posterior。先驗和 aggregate posterior 之間的不匹配可以通過重新加權來減少,在與 aggregate posterior 不匹配的地方重新調整其可能性。為了表示這種加權機制,使用EBM( Energy-based Models )來確定先驗,EBM是由一個 reweighting factor 和一個基礎可訓練先驗的乘積來定義的,如圖13所示。用神經網絡表示 reweighting factor ,用正態分布表示基本先驗。

圖13 提出了一種EBM先驗,使用基礎先驗p(z)和 reweighting factor r(z)的乘積,旨在使p(z)更接近aggregate posterior q(z)
基于EBM,引入NCP( the noise contrastive prior )計算基礎先驗:


使用兩階段訓練方法訓練NCP,如圖14。在第一階段,使用原始VAE目標訓練VAE。在第二階段,使用噪聲對比估計(noise contrast estimation,NCE)來訓練重新加權因子r(z)。NCE訓練一個分類器來區分來自先驗的樣本和來自aggregate posterior的樣本。NCP是由基礎先驗和reweighting factor的乘積構建的,通過分類器形成。在測試時,使用采樣-重要性-采樣( sampling-importance-resampling ,SIR)或LD(Langevin dynamics )從NCP中采樣。然后,這些樣本被傳遞給解碼器以產生輸出樣本。

圖14. NCP-VAE的訓練分為兩個階段
最后,作者還將NCP-VAE擴展到了Hierarchical VAEs

其中,每個因子都是EBM。pNCP(z)類似于具有自回歸結構的組間EBM。在第一階段,以先驗的方式訓練HVAE:

在第二階段,我們使用K個二進制分類器,每個分類器用于一個分層組。通過以下方式訓練每個分類器


模型 | SOTA!平臺模型詳情頁 |
NCP-VAE | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/74d15cbe-7f75-434a-a1cf-a69ae303eec6 |
1.7 StyleGAN-xl
StyleGAN-XL 是第一個在 ImageNet-scale 上演示 1024^2 分辨率圖像合成的模型。實驗表明,即使是最新的 StyleGAN3 也不能很好地擴展到 ImageNet 上,特別是在高分辨率時,訓練會變得不穩定。StyleGAN為關于圖像質量和可控性的生成建模設定了一種標桿方法。但StyleGAN在 ImageNet 等大型非結構化數據集上表現不好,它更適合人臉數據方面的生成。
研究者首先修改了StyleGAN的生成器及其正則化損失,調整了潛在空間以適應 Projected GAN (Config-B) 和類條件設置 (Config-C);然后重新討論了漸進式增長,以提高訓練速度和性能 (Config-D);接下來研究了用于 Projected GAN 訓練的特征網絡,以找到一個非常適合的配置 (Config-E);最后,提出了分類器引導,以便 GAN 通過一個預訓練的分類器 (Config-F) 提供類別信息。這樣一來,就能夠訓練一個比以前大得多的模型,同時需要比現有技術更少的計算量。StyleGAN-XL 在深度和參數計數方面比標準的 StyleGAN3 大三倍。

圖15. StyleGAN-XL訓練。將潛在編碼z和類別標簽c送入預訓練的嵌入和映射網絡G??,以生成 style code w,這些code調制synthesis網絡G??的卷積。在訓練過程中,逐漸增加層數,使漸進式增長的每個階段的輸出分辨率增加一倍。只訓練最新的層,而保持其他層的固定。G??只在最初的162階段進行訓練,在更高的分辨率階段保持固定。合成的圖像在小于2242時被放大,并通過一個CNN和一個ViT( Vision Transformer)以及各自的特征混合塊(CCM+CSM)。在更高的分辨率下,CNN接收未經修改的圖像,而ViT接收降頻輸入,以保持低內存要求,但仍利用其全局反饋。最后,在得到的多尺度特征圖上應用八個獨立的鑒別器。圖像也被送入分類器CLF,用于分類器指導
此外,還可以進一步細化所得到的重構結果,StyleGAN-xl可以在肖像或特定對象類的應用領域完成逆映射、編輯等擴展任務,將 PTI 和 StyleGAN-XL 相結合,幾乎可以精確地反演域內 (ImageNet 驗證集) 和域外圖像。同時生成器的輸出保持平滑。
當前 SOTA!平臺收錄 StyleGAN-XL 共 1 個模型實現資源。

項目 | SOTA!平臺項目詳情頁 |
StyleGAN-XL | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/01d16b00-e79f-4527-a7e3-08354b5d9b47 |
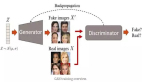
1.8 Diffusion GAN
Diffusion-GAN主要關注的是 stabilize GAN training 的問題。為了實現GAN的穩定訓練,將實例噪聲注入鑒別器的輸入理論上可行但缺少實踐的驗證。本文介紹了Diffusion-GAN,它采用了高斯混合分布,在前向擴散鏈條中的所有擴散步驟中引入實例噪聲。將觀察到的或生成的數據中擴散出的混合物的隨機樣本作為輸入送入鑒別器。生成器通過前向擴散鏈反向傳播其梯度進行更新,其長度是自適應調整的,以控制每個訓練步驟中允許的最大噪聲與數據比率。

圖16. Diffusion-GAN的流程圖。上排圖像代表真實圖像的前向擴散過程,而下排圖像代表生成的假圖像的前向擴散過程。鑒別器學會在所有擴散步驟中區分擴散的真圖像和擴散的假圖像
Diffusion-GAN的對應目標是vanilla GAN的最小-最大目標,定義為

鑒別器D學習區分擴散的生成樣本y_g和擴散的真實觀測值y,時間為?t∈{1, . . . , T},具體的優先級由π_t的值決定。生成器G學習將潛在變量z映射到它的輸出x_g=G_θ(z),它可以在擴散鏈的任何一步騙過鑒別器。y_g~q(y | G_θ(z), t)可以被重新參數化為

梯度可以直接反向傳播到生成器。隨著t的增加,y和y_g中的噪聲與數據之比也在增加,從而使鑒別器D的任務越來越難。作者設計了一個擴散強度的自適應控制,以便更好地訓練鑒別器。作者通過適應性地修改T來實現這一目標。我們為T設計了一個基于度量r_d的 self-paced schedule,這個schedule評估了鑒別器的過擬合度

為了更好地防止鑒別器過擬合,定義t作為一個不對稱的離散分布,鼓勵鑒別器在T增加時觀察新增加的擴散樣本。

當T開始增加時,鑒別器對所看到的樣本已經很有信心,所以我們希望它探索更多的新樣本,以抵消鑒別器的過度擬合。
當前 SOTA!平臺收錄 Diffusion-GAN 共 1 個模型實現資源。

模型 | SOTA!平臺模型詳情頁 |
Diffusion-GAN | 前往SOTA!模型平臺獲取實現資源:https://sota.jiqizhixin.com/project/9aa9b499-adec-46a3-aef9-4cd73e1c13ec |