MySQL主從復制引發的這個問題,99%的人都不知道
一、背景
電商業務場景,隨著平臺訂單規模的日益增長,訂單現有的存儲已經沒辦法支撐后面業務的發展。在得物五彩石項目的時候就對訂單進行了分庫分表的拆分,為了解決分庫分表后賣家維度的查詢問題,單獨創建了一個賣家維度的訂單庫。
目前訂單分為買家和賣家兩個庫,賣家庫的數據是通過監聽買家庫binlog異構出來的一個庫。現在訂單主要有兩張表,分別是訂單的主表和子表。
在異構的邏輯中,我們會對這兩張表的binlog消息進行處理,異構成我們的賣家訂單表。在監聽到插入的消息時,只會處理子表的插入消息,其余需要補充的主訂單表數據直接查詢主表。

查詢訂單主表的時候如果為空就會拋一個異常,依賴MQ的重試功能進行下一次重試,這是目前的邏輯。正常情況下訂單主表是不可能會出現查不到的情況,在19號凌晨的時候,有一大批訂單主表查不到的告警,于是通過關鍵字去日志平臺搜索,如下圖所示:

二、分析
2.1 業務影響
通過對報錯的消息進行排查,消息在二次重新投遞的時候,數據成功的保存到了數據庫里面,對業務無影響,只是會有異常告警。
2.2 主從延遲
目前的現象是第一次處理的時候,查詢主表為空,異常重試后就能查詢到數據。給我們的直覺就是數據庫的主從延遲產生的問題。
根據這個想法,去排查對應的代碼,發現從代碼層面是走的主庫查詢。這里順帶介紹下主從路由是如何實現的,項目中依賴了數據庫代理中間件彩虹橋的jar包,支持通過配置(bifrost.read-write-separate-model=SQL_READ_DEFAULT_MASTER)指定默認的讀寫分離模式。我們的模式默認是路由到主庫,如果有需要走從庫查詢的場景會在對應的dao方法上加一個注解進行標記。
然后會通過Mybatis的攔截器,對SQL進行處理,通過hint的方式將路由方式帶給彩虹橋,彩虹橋內部根據指定的方式進行路由。
2.3 創單數據一致性
主從延遲的排除后,懷疑點在另一個方面。會不會創單的時候數據保存沒有在同一個事務里面,比如說子單先保存,然后再保存主單,此時子單的binlog肯定會早于主單,也就會存在查詢主單為空的情況。
這個也很快被否決了,如果是這個情況,那肯定是100%必現的場景,不是存在偶現的情況。其次,創單的代碼中對于數據存儲那塊是在一個事務內,所以不存在分批保存的情況。
2.4 數據庫內部問題
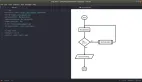
排除了外部相關的問題,那么只剩下數據庫內部的問題。接下來從binlog的寫入流程來看下是否存在有問題的地方,首先我們看下整體的流程,如下圖:

這里比較懷疑的點就在于redo log 二階段提交時,這個時候會把redo日志刷數據盤,也就是MySQL的存儲數據真正落庫。正常情況下,這個速度很快,當數據庫的IO很高的時候,刷盤的性能也會有所影響。所以在刷盤時稍微延遲了X毫秒的話,binlog已經被應用給消費了,然后查詢不到。
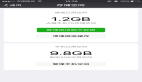
根據告警的時間點,去看了從節點數據庫的監控,那段時間確實IO較高,如下圖所示:

上面只是猜測,我們如何去驗證這個猜測是對的呢?
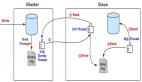
目前用的數據庫是主從模式,那么必然涉及到數據的復制,先簡單介紹下復制的幾種模式:
- 強同步
應用發起數據插入/更新/刪除操作在主實例執行完成后,會將日志同步傳輸到所有備實例,至少1個備實例收到并存儲日志后,事務才完成提交。
- 半同步
應用發起數據插入/更新/刪除操作在主實例執行完成后,會將日志同步傳輸到1個備實例,備實例收到日志,事務就算完成了提交,不需要等待備實例執行日志內容。
- 異步
應用發起數據插入/更新/刪除請求,主實例完成操作后會立即響應應用,同時主實例向備實例異步復制數據。
目前我們數據庫用的是半同步的方式,在半同步里面支持兩種模式,分別是AFTER_COMMIT(5.6版本默認)和AFTER_SYNC(5.7版本才有,默認)。
1)AFTER_COMMIT
master將每個事務寫入binlog,傳遞到slave刷新到磁盤,同時master提交事務。master等待slave反饋收到relay log,只有收到ACK后master才將commit OK結果反饋給客戶端。
AFTER_COMMIT意味在master上,剛剛提交的事務對數據庫的修改,對其他事務是可見的。因此,如果在等待Slave ACK的時候crash了,那么會對其他事務出現幻讀,數據丟失的問題。
2)AFTER_SYNC
master將每個事務寫入binlog , 傳遞到slave刷新到磁盤。master等待slave反饋接收到relay log的ACK之后,再提交事務并且返回commit OK結果給客戶端。即使master crash,所有在master上已經提交的事務都能保證已經同步到slave的relay log中。
AFTER_SYNC在寫完binlog后,就開始傳輸,但此時還沒有提交事務,意味著當前這個事務對數據庫的修改,其他事務也是不可見的。所以不會出現幻讀,數據丟失風險。
我們目前是用的AFTER_SYNC模式,也就是說binlog寫入后,master會等待slave的反饋結果,然后才會commit,這里也就能正常解釋我們這個查詢不到的問題是什么原因了。原因就是master寫完binlog后在等待中,slave收到binlog后,由于IO高,寫入relay log比較慢,此時我們的訂閱平臺也相當于是一個從節點,同樣也收到了binlog,然后投遞給應用,應用這個時候去數據庫查詢,因為master還沒commit,自然就查不到。

三、解決方案
針對這個問題,解決方案有很多,梳理后發現這個場景其實不影響業務,將告警信息調整下,并不需要改造業務,如果想改也有一些可以解決的方案。
3.1 重試機制
對于這類場景,可以利用重試機制來解決。而目前的binlog監聽也是利用MQ來投遞消息給業務方使用,可以直接依賴MQ的重試即可。
這個業務場景本身就是一個異步的過程,對實時性要求沒有那么高,其次對業務也不會有影響。第一次消息過來的時候沒有查到,終止流程,然后等到MQ重試,就可以查到數據,完成整個流程。
3.2 延時消息
可以對訂閱平臺進行改造,在配置訂閱任務的時候可以指定監聽到binlog后延遲多久發送給業務應用,這個延遲的處理直接用MQ的延時消息,這樣就可以將消息晚幾秒送到業務應用,也能解決問題。
延時消息也不能保證一定解決,重點在于延時的時間怎么設置比較合理。因為我們也不能保證數據庫從節點收到binlog后ack的時間有多長。還有就是如果配置的很長,要對現有場景的業務進行評估,是否能夠接受數據的延遲。
3.3 不依賴binlog
不依賴binlog指的是將消息改成業務動作觸發后發出的消息,比如創建訂單后,在代碼中通過MQ發出一條訂單創建的消息,里面包含了訂單的數據。這樣業務應用就可以不直接依賴binlog的消息,監聽到業務消息的時候,事務必定已經提交了,業務應用進行反查的時候數據已經有了。
四、總結
數據庫可以說是作為研發同學必須要掌握的一個技能,但在日常工作中我們只需要掌握一些基本的語法就可以滿足開發需求,于是會忽略很多底層的原理。通過本文這個案例你會發現整個數據庫體系還有很多內容值得去學習,試想一下,如果平時對主從復制的原理比較熟的話,問題排查起來也會簡單很多。
其次作為研發,對于每一個問題都要有認真的態度,不能草草了事。從一個小問題,如果采取忽略的方式,就會失去求真的動力,從而失去很多可以學習的點。這個問題也是一樣,通過一步步排查,又積累了新的經驗。