面試記錄:HashMap核心知識,擾動函數(shù)、負(fù)載因子、擴(kuò)容鏈表拆分
一、前言
得益于Doug Lea老爺子的操刀,讓HashMap成為使用和面試最頻繁的API,沒辦法設(shè)計(jì)的太優(yōu)秀了!
HashMap 最早出現(xiàn)在 JDK 1.2中,底層基于散列算法實(shí)現(xiàn)。HashMap 允許 null 鍵和 null 值,在計(jì)算哈鍵的哈希值時(shí),null 鍵哈希值為 0。HashMap 并不保證鍵值對的順序,這意味著在進(jìn)行某些操作后,鍵值對的順序可能會發(fā)生變化。另外,需要注意的是,HashMap 是非線程安全類,在多線程環(huán)境下可能會存在問題。
HashMap 最早在JDK 1.2中就出現(xiàn)了,底層是基于散列算法實(shí)現(xiàn),隨著幾代的優(yōu)化更新到目前為止它的源碼部分已經(jīng)比較復(fù)雜,涉及的知識點(diǎn)也非常多,在JDK 1.8中包括;1、散列表實(shí)現(xiàn)、2、擾動函數(shù)、3、初始化容量、4、負(fù)載因子、5、擴(kuò)容元素拆分、6、鏈表樹化、7、紅黑樹、8、插入、9、查找、10、刪除、11、遍歷、12、分段鎖等等,因涉及的知識點(diǎn)較多所以需要分開講解,本章節(jié)我們會先把目光放在前五項(xiàng)上,也就是關(guān)于數(shù)據(jù)結(jié)構(gòu)的使用上。
數(shù)據(jù)結(jié)構(gòu)相關(guān)往往與數(shù)學(xué)離不開,學(xué)習(xí)過程中建議下載相應(yīng)源碼進(jìn)行實(shí)驗(yàn)驗(yàn)證,可能這個(gè)過程有點(diǎn)燒腦,但學(xué)會后不用死記硬背就可以理解這部分知識。
二、資源下載
本章節(jié)涉及的源碼和資源在工程,interview-04中,包括;
10萬單詞測試數(shù)據(jù),在doc文件夾
擾動函數(shù)excel展現(xiàn),在doc文件夾
測試源碼部分在interview-04工程中
可以通過關(guān)注公眾號:bugstack蟲洞棧,回復(fù)下載進(jìn)行獲取{回復(fù)下載后打開獲得的鏈接,找到編號ID:19}
三、源碼分析
1. 寫一個(gè)最簡單的HashMap
學(xué)習(xí)HashMap前,最好的方式是先了解這是一種怎么樣的數(shù)據(jù)結(jié)構(gòu)來存放數(shù)據(jù)。而HashMap經(jīng)過多個(gè)版本的迭代后,乍一看代碼還是很復(fù)雜的。就像你原來只穿個(gè)褲衩,現(xiàn)在還有秋褲和風(fēng)衣。所以我們先來看看最根本的HashMap是什么樣,也就是只穿褲衩是什么效果,之后再去分析它的源碼。
問題: 假設(shè)我們有一組7個(gè)字符串,需要存放到數(shù)組中,但要求在獲取每個(gè)元素的時(shí)候時(shí)間復(fù)雜度是O(1)。也就是說你不能通過循環(huán)遍歷的方式進(jìn)行獲取,而是要定位到數(shù)組ID直接獲取相應(yīng)的元素。
方案: 如果說我們需要通過ID從數(shù)組中獲取元素,那么就需要把每個(gè)字符串都計(jì)算出一個(gè)在數(shù)組中的位置ID。字符串獲取ID你能想到什么方式? 一個(gè)字符串最直接的獲取跟數(shù)字相關(guān)的信息就是HashCode,可HashCode的取值范圍太大了[-2147483648, 2147483647],不可能直接使用。那么就需要使用HashCode與數(shù)組長度做與運(yùn)算,得到一個(gè)可以在數(shù)組中出現(xiàn)的位置。如果說有兩個(gè)元素得到同樣的ID,那么這個(gè)數(shù)組ID下就存放兩個(gè)字符串。
以上呢其實(shí)就是我們要把字符串散列到數(shù)組中的一個(gè)基本思路,接下來我們就把這個(gè)思路用代碼實(shí)現(xiàn)出來。
1.1 代碼實(shí)現(xiàn)
這段代碼整體看起來也是非常簡單,并沒有什么復(fù)雜度,主要包括以下內(nèi)容;
- 初始化一組字符串集合,這里初始化了7個(gè)。
- 定義一個(gè)數(shù)組用于存放字符串,注意這里的長度是8,也就是2的3次冪。這樣的數(shù)組長度才會出現(xiàn)一個(gè) 0111除高位以外都是1的特征,也是為了散列。
- 接下來就是循環(huán)存放數(shù)據(jù),計(jì)算出每個(gè)字符串在數(shù)組中的位置。key.hashCode() & (tab.length - 1)。
- 在字符串存放到數(shù)組的過程,如果遇到相同的元素,進(jìn)行連接操作模擬鏈表的過程。
- 最后輸出存放結(jié)果。
測試結(jié)果
- 在測試結(jié)果首先是計(jì)算出每個(gè)元素在數(shù)組的Idx,也有出現(xiàn)重復(fù)的位置。
- 最后是測試結(jié)果的輸出,1、3、6,位置是空的,2、5,位置有兩個(gè)元素被鏈接起來e4we->plop。
- 這就達(dá)到了我們一個(gè)最基本的要求,將串元素散列存放到數(shù)組中,最后通過字符串元素的索引ID進(jìn)行獲取對應(yīng)字符串。這樣是HashMap的一個(gè)最基本原理,有了這個(gè)基礎(chǔ)后面就會更容易理解HashMap的源碼實(shí)現(xiàn)。
1.2 Hash散列示意圖
如果上面的測試結(jié)果不能在你的頭腦中很好地建立出一個(gè)數(shù)據(jù)結(jié)構(gòu),那么可以看以下這張散列示意圖,方便理解;
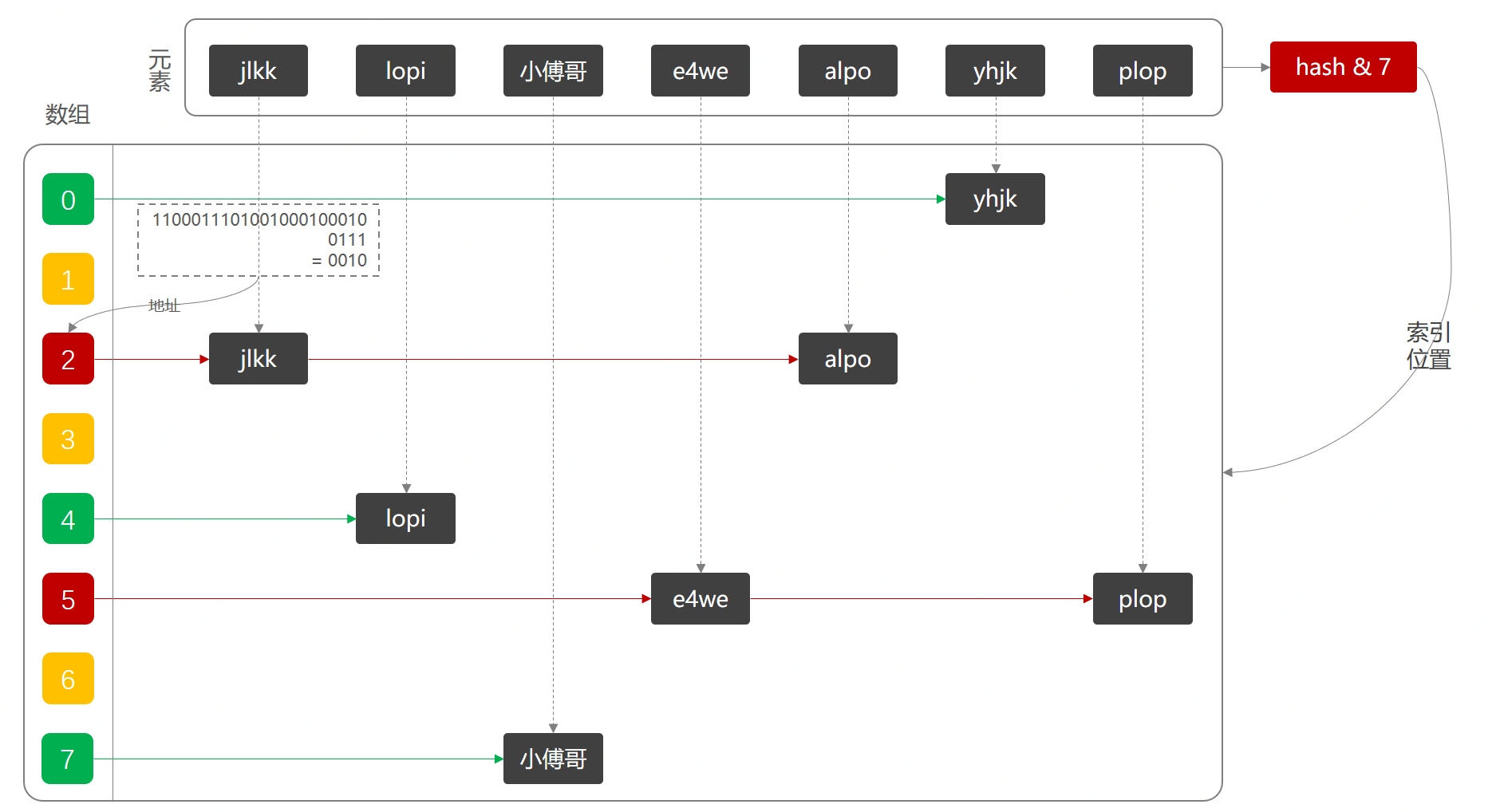
bugstack.cn Hash散列示意圖
- 這張圖就是上面代碼實(shí)現(xiàn)的全過程,將每一個(gè)字符串元素通過Hash計(jì)算索引位置,存放到數(shù)組中。
- 黃色的索引ID是沒有元素存放、綠色的索引ID存放了一個(gè)元素、紅色的索引ID存放了兩個(gè)元素。
1.3 這個(gè)簡單的HashMap有哪些問題
以上我們實(shí)現(xiàn)了一個(gè)簡單的HashMap,或者說還算不上HashMap,只能算做一個(gè)散列數(shù)據(jù)存放的雛形。但這樣的一個(gè)數(shù)據(jù)結(jié)構(gòu)放在實(shí)際使用中,會有哪些問題呢?
- 這里所有的元素存放都需要獲取一個(gè)索引位置,而如果元素的位置不夠散列碰撞嚴(yán)重,那么就失去了散列表存放的意義,沒有達(dá)到預(yù)期的性能。
- 在獲取索引ID的計(jì)算公式中,需要數(shù)組長度是2的冪次方,那么怎么進(jìn)行初始化這個(gè)數(shù)組大小。
- 數(shù)組越小碰撞的越大,數(shù)組越大碰撞的越小,時(shí)間與空間如何取舍。
- 目前存放7個(gè)元素,已經(jīng)有兩個(gè)位置都存放了2個(gè)字符串,那么鏈表越來越長怎么優(yōu)化。
- 隨著元素的不斷添加,數(shù)組長度不足擴(kuò)容時(shí),怎么把原有的元素,拆分到新的位置上去。
以上這些問題可以歸納為;擾動函數(shù)、初始化容量、負(fù)載因子、擴(kuò)容方法以及鏈表和紅黑樹轉(zhuǎn)換的使用等。接下來我們會逐個(gè)問題進(jìn)行分析。
2. 擾動函數(shù)
在HashMap存放元素時(shí)候有這樣一段代碼來處理哈希值,這是java 8的散列值擾動函數(shù),用于優(yōu)化散列效果;
2.1 為什么使用擾動函數(shù)
理論上來說字符串的hashCode是一個(gè)int類型值,那可以直接作為數(shù)組下標(biāo)了,且不會出現(xiàn)碰撞。但是這個(gè)hashCode的取值范圍是[-2147483648, 2147483647],有將近40億的長度,誰也不能把數(shù)組初始化得這么大,內(nèi)存也是放不下的。
我們默認(rèn)初始化的Map大小是16個(gè)長度 DEFAULT_INITIAL_CAPACITY = 1 << 4,所以獲取的Hash值并不能直接作為下標(biāo)使用,需要與數(shù)組長度進(jìn)行取模運(yùn)算得到一個(gè)下標(biāo)值,也就是我們上面做的散列列子。
那么,hashMap源碼這里不只是直接獲取哈希值,還進(jìn)行了一次擾動計(jì)算,(h = key.hashCode()) ^ (h >>> 16)。把哈希值右移16位,也就正好是自己長度的一半,之后與原哈希值做異或運(yùn)算,這樣就混合了原哈希值中的高位和低位,增大了隨機(jī)性。計(jì)算方式如下圖;

bugstack.cn 擾動函數(shù)
- 說白了,使用擾動函數(shù)就是為了增加隨機(jī)性,讓數(shù)據(jù)元素更加均衡的散列,減少碰撞。
2.2 實(shí)驗(yàn)驗(yàn)證擾動函數(shù)
從上面的分析可以看出,擾動函數(shù)使用了哈希值的高半?yún)^(qū)和低半?yún)^(qū)做異或,混合原始哈希碼的高位和低位,以此來加大低位區(qū)的隨機(jī)性。
但看不到實(shí)驗(yàn)數(shù)據(jù)的話,這終究是一段理論,具體這段哈希值真的被增加了隨機(jī)性沒有,并不知道。所以這里我們要做一個(gè)實(shí)驗(yàn),這個(gè)實(shí)驗(yàn)是這樣做;
- 選取10萬個(gè)單詞詞庫
- 定義128位長度的數(shù)組格子
- 分別計(jì)算在擾動和不擾動下,10萬單詞的下標(biāo)分配到128個(gè)格子的數(shù)量
- 統(tǒng)計(jì)各個(gè)格子數(shù)量,生成波動曲線。如果擾動函數(shù)下的波動曲線相對更平穩(wěn),那么證明擾動函數(shù)有效果。
擾動函數(shù)對比方法
- disturbHashIdx擾動函數(shù)下,下標(biāo)值計(jì)算
- hashIdx非擾動函數(shù)下,下標(biāo)值計(jì)算
單元測試
以上分別統(tǒng)計(jì)兩種函數(shù)下的下標(biāo)值分配,最終將統(tǒng)計(jì)結(jié)果放到excel中生成圖表。
以上的兩張圖,分別是沒有使用擾動函數(shù)和使用擾動函數(shù)的,下標(biāo)分配。實(shí)驗(yàn)數(shù)據(jù);
- 10萬個(gè)不重復(fù)的單詞
- 128個(gè)格子,相當(dāng)于128長度的數(shù)組
未使用擾動函數(shù)

bugstack.cn 未使用擾動函數(shù)
使用擾動函數(shù)

bugstack.cn 使用擾動函數(shù)
- 從這兩種的對比圖可以看出來,在使用了擾動函數(shù)后,數(shù)據(jù)分配的更加均勻了。
- 數(shù)據(jù)分配均勻,也就是散列的效果更好,減少了hash的碰撞,讓數(shù)據(jù)存放和獲取的效率更佳。
3. 初始化容量和負(fù)載因子
接下來我們討論下一個(gè)問題,從我們模仿HashMap的例子中以及HashMap默認(rèn)的初始化大小里,都可以知道,散列數(shù)組需要一個(gè)2的冪次方的長度,因?yàn)橹挥?的冪次方在減1的時(shí)候,才會出現(xiàn)01111這樣的值。
那么這里就有一個(gè)問題,我們在初始化HashMap的時(shí)候,如果傳一個(gè)17個(gè)的值new HashMap<>(17);,它會怎么處理呢?
3.1 尋找2的冪次方最小值
在HashMap的初始化中,有這樣一段方法;
- 閾值threshold,通過方法tableSizeFor進(jìn)行計(jì)算,是根據(jù)初始化來計(jì)算的。
- 這個(gè)方法也就是要尋找比初始值大的,最小的那個(gè)2進(jìn)制數(shù)值。比如傳了17,我應(yīng)該找到的是32(2的4次冪是16<17,所以找到2的5次冪32)。
計(jì)算閾值大小的方法;
- MAXIMUM_CAPACITY = 1 << 30,這個(gè)是臨界范圍,也就是最大的Map集合。
- 乍一看可能有點(diǎn)暈怎么都在向右移位1、2、4、8、16,這主要是為了把二進(jìn)制的各個(gè)位置都填上1,當(dāng)二進(jìn)制的各個(gè)位置都是1以后,就是一個(gè)標(biāo)準(zhǔn)的2的冪次方減1了,最后把結(jié)果加1再返回即可。
那這里我們把17這樣一個(gè)初始化計(jì)算閾值的過程,用圖展示出來,方便理解;
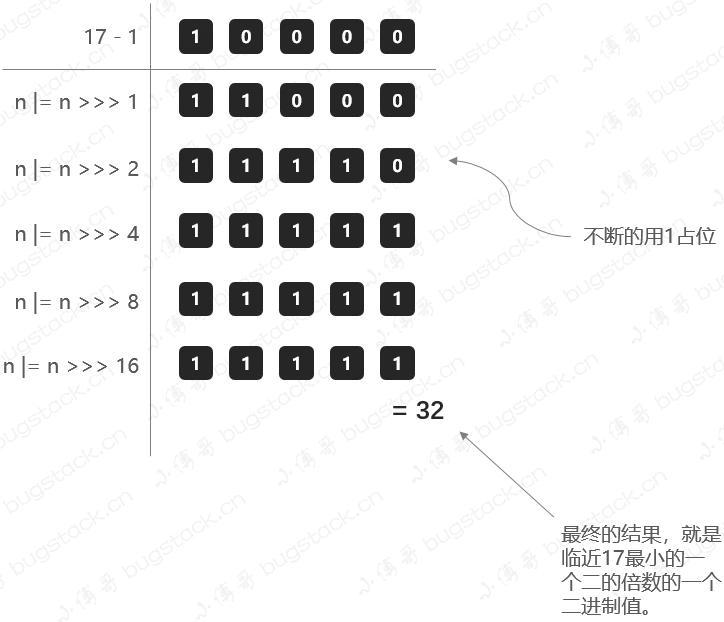
bugstack.cn 計(jì)算閾值
3.2 負(fù)載因子
負(fù)載因子是做什么的?
負(fù)載因子,可以理解成一輛車可承重重量超過某個(gè)閾值時(shí),把貨放到新的車上。
那么在HashMap中,負(fù)載因子決定了數(shù)據(jù)量多少了以后進(jìn)行擴(kuò)容。這里要提到上面做的HashMap例子,我們準(zhǔn)備了7個(gè)元素,但是最后還有3個(gè)位置空余,2個(gè)位置存放了2個(gè)元素。 所以可能即使你數(shù)據(jù)比數(shù)組容量大時(shí)也是不一定能正正好好的把數(shù)組占滿的,而是在某些小標(biāo)位置出現(xiàn)了大量的碰撞,只能在同一個(gè)位置用鏈表存放,那么這樣就失去了Map數(shù)組的性能。
所以,要選擇一個(gè)合理的大小下進(jìn)行擴(kuò)容,默認(rèn)值0.75就是說當(dāng)閾值容量占了3/4時(shí)趕緊擴(kuò)容,減少Hash碰撞。
同時(shí)0.75是一個(gè)默認(rèn)構(gòu)造值,在創(chuàng)建HashMap也可以調(diào)整,比如你希望用更多的空間換取時(shí)間,可以把負(fù)載因子調(diào)的更小一些,減少碰撞。
4. 擴(kuò)容元素拆分
為什么擴(kuò)容,因?yàn)閿?shù)組長度不足了。那擴(kuò)容最直接的問題,就是需要把元素拆分到新的數(shù)組中。拆分元素的過程中,原jdk1.7中會需要重新計(jì)算哈希值,但是到j(luò)dk1.8中已經(jīng)進(jìn)行優(yōu)化,不再需要重新計(jì)算,提升了拆分的性能,設(shè)計(jì)的還是非常巧妙的。
4.1 測試數(shù)據(jù)
測試結(jié)果
- 這里我們隨機(jī)使用一些字符串計(jì)算他們分別在16位長度和32位長度數(shù)組下的索引分配情況,看哪些數(shù)據(jù)被重新路由到了新的地址。
- 同時(shí),這里還可以觀察出一個(gè)非常重要的信息,原哈希值與擴(kuò)容新增出來的長度16,進(jìn)行&運(yùn)算,如果值等于0,則下標(biāo)位置不變。如果不為0,那么新的位置則是原來位置上加16。{這個(gè)地方需要好好理解下,并看實(shí)驗(yàn)數(shù)據(jù)}
- 這樣一來,就不需要在重新計(jì)算每一個(gè)數(shù)組中元素的哈希值了。
4.2 數(shù)據(jù)遷移
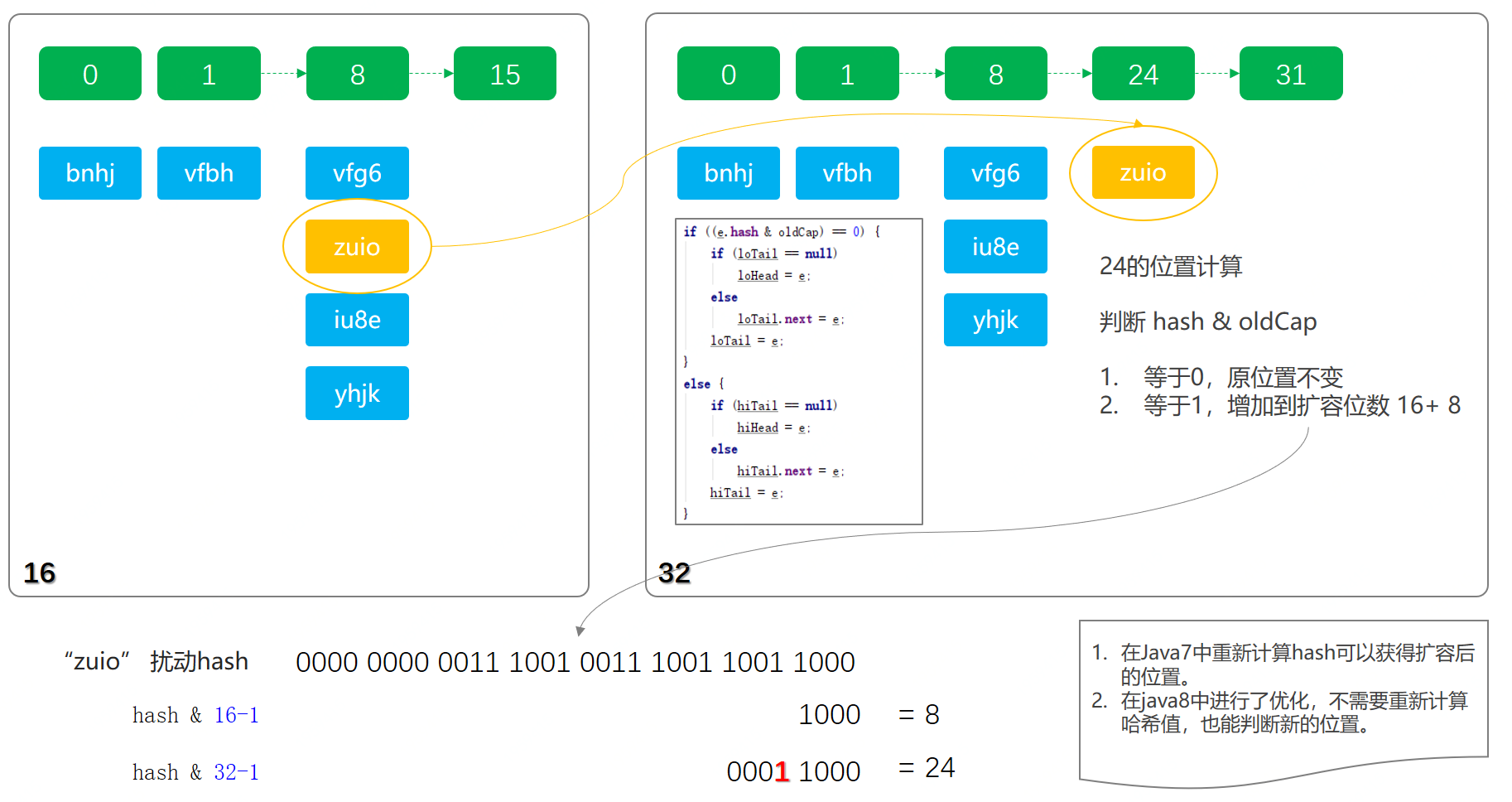
bugstack.cn 數(shù)據(jù)遷移
- 這張圖就是原16位長度數(shù)組元素,向32位擴(kuò)容后數(shù)組轉(zhuǎn)移的過程。
- 對31取模保留低5位,對15取模保留低4位,兩者的差異就在于第5位是否為1,是的話則需要加上增量,為0的話則不需要改變
- 其中黃色區(qū)域元素zuio因計(jì)算結(jié)果hash & oldCap低位第5位為1,則被遷移到下標(biāo)位置24。
- 同時(shí)還是用重新計(jì)算哈希值的方式驗(yàn)證了,確實(shí)分配到24的位置,因?yàn)檫@是在二進(jìn)制計(jì)算中補(bǔ)1的過程,所以可以通過上面簡化的方式確定哈希值的位置。
那么為什么 e.hash & oldCap == 0 為什么可以判斷當(dāng)前節(jié)點(diǎn)是否需要移位, 而不是再次計(jì)算hash;
仍然是原始長度為16舉例:
從上面的示例可以很輕易的看出, 兩次indexFor()的差別只是第二次參與位于比第一次左邊有一位從0變?yōu)?, 而這個(gè)變化的1剛好是oldCap, 那么只需要判斷原key的hash這個(gè)位上是否為1: 若是1, 則需要移動至oldCap + i的槽位, 若為0, 則不需要移動;
這也是HashMap的長度必須保證是2的冪次方的原因, 正因?yàn)檫@種環(huán)環(huán)相扣的設(shè)計(jì), HashMap.loadFactor的選值是3/4就能理解了, table.length * 3/4可以被優(yōu)化為((table.length >> 2) << 2) - (table.length >> 2) == table.length - (table.length >> 2), JAVA的位運(yùn)算比乘除的效率更高, 所以取3/4在保證hash沖突小的情況下兼顧了效率;
四、總結(jié)
- 如果你能堅(jiān)持看完這部分內(nèi)容,并按照文中的例子進(jìn)行相應(yīng)的實(shí)驗(yàn)驗(yàn)證,那么一定可以學(xué)會本章節(jié)涉及這五項(xiàng)知識點(diǎn);1、散列表實(shí)現(xiàn)、2、擾動函數(shù)、3、初始化容量、4、負(fù)載因子、5、擴(kuò)容元素拆分。
- 對我個(gè)人來說以前也知道這部分知識,但是沒有驗(yàn)證過,只知道概念如此,正好借著寫面試手冊專欄,加深學(xué)習(xí),用數(shù)據(jù)驗(yàn)證理論,讓知識點(diǎn)可以更加深入的理解。
- 這一章節(jié)完事,下一章節(jié)繼續(xù)進(jìn)行HashMap的其他知識點(diǎn)挖掘,讓懂了就是真的懂了。好了,寫到這里了,感謝大家的閱讀。如果某處沒有描述清楚,或者有不理解的點(diǎn),歡迎與我討論交流。?