













讓我來告訴你列存數據倉庫怎樣更高效
很多數據倉庫產品都采用了列式存儲。如果數據表的總列數很多而計算涉及的列很少,采用列存就只讀取需要的列即可,能夠減少硬盤訪問量,提高性能。特別是數據量非常大時,硬盤掃描和讀取的時間占比很大,這時候列存的優勢會很明顯。
那么,是不是只要用了列存就一定能做到性能最佳呢?我們來看看,列式存儲在哪些方面還可以做的更高效。
壓縮
結構化數據的編碼方式一般都不會非常緊湊,常常還有一定的可壓縮余地。數據倉庫通常會在列存的基礎上對數據進行壓縮,在物理上減少數據存儲量,從而減少讀取時間,提高性能。數據表相同字段的數據類型一般都是一樣的,甚至有些情況取值都很接近,這樣的一批數據通常會有較好的壓縮率。列存是將相同字段值存儲在一起的,所以比行存更有利于數據壓縮。
但是,通用的壓縮算法不能假定數據有某種特征,只能將數據當作隨意的字節流去編碼,有時并不能獲得最好的壓縮率。而且,高壓縮率的算法壓縮出來的數據,解壓縮時常常會增加CPU的運算量,消耗更多的時間。這部分多消耗的時間,甚至會大于壓縮節省的硬盤讀取時間,得不償失。
如果我們先對數據做一些處理,人為地制造某些數據特征來利用,再配合壓縮算法,就可以實現較高的壓縮率,同時保持較低的CPU消耗。
將數據排序后存儲就是一個有效的處理方法。數據表中常常有許多維度字段,比如地區、日期等。這些維度的取值基本都在一個小集合范圍內,數據量大時會有很多重復取值。如果數據是按這些列排序的,則相鄰記錄之間取值相同的情況就很常見。這時,使用很輕量級的壓縮算法也能獲得很好的壓縮率。簡單來講,可以直接存儲列值及其重復次數,而不必把同樣的值存儲多遍,少占用的空間是相當可觀的。
排序的次序也有講究。要盡量把字段值較長的列放在前面排序。比如有地區和性別兩個列,地區的值(“北京”、“上海”等)字符數要大于性別(“男”、“女”),則先地區、后性別排序的效果就要好于反過來的情況。
我們還可以進行數據類型的優化,比如將字符串、日期等轉換為適當的數值編碼。如果把地區、性別字段都轉換為小整數編號,字段值的長度就一樣了。這時,可以選擇重復情況更多的字段排到前面。例如性別只有兩個枚舉值,而地區則相對較多。所以各條記錄中,性別重復的會更多,先性別、后地區排序所占用空間通常會更小。
開源數據計算引擎SPL提供的列存方案,就實現了這種壓縮算法。把有序數據追加進SPL的組表時,默認會自動執行上述方法,只記錄一次值和重復計數。
SPL建立有序列存組表,并完成遍歷計算的寫法,大致是這樣:
示例代碼1:有序壓縮列存和遍歷計算
A | |
1 | =file("T_ordinary.ctx").open().cursor(f1,f2,f3,f4,…).sortx(f1,f2,f3) |
2 | >file("T.ctx").create(#f1,#f2,#f3,f4,…).append@i(A1) |
3 | =file("T.ctx").open().cursor().groups(…;sum(amt1),avg(amt2),max(amt3+amt4),…) |
A1:建立原數據的游標,并按照f1,f2,f3三個字段排序。
A2:建立新的組表,指定f1,f2,f3三個字段有序。將已經排好序的數據寫入組表。
A3:打開已經建好的新組表,做分組匯總。
在下面這個測試中,SPL采用數據類型優化和有序壓縮列存后,數據存儲量減少了31%,而計算性能提高了9倍多。測試結果見下圖:
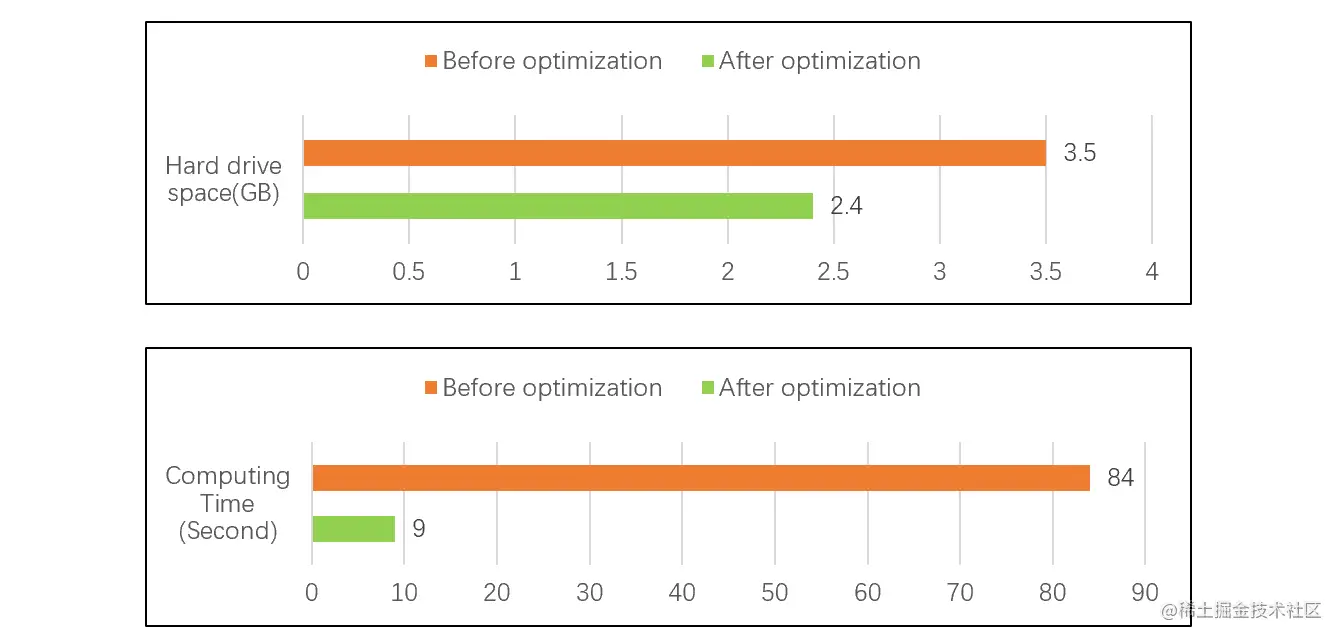
這個測試更詳細的信息請參考: 多維分析后臺實踐 3:維度排序壓縮
并行
多線程并行可以充分利用多CPU計算能力,是重要的提速手段。而要并行就需要先把數據分段。行存分段比較簡單,按數據量大體平均分段,再找記錄結束標記確定分段點位置即可。但列存不能采用同樣的辦法。由于列存的不同列是分別存儲的,也必須分別分段。又因為不定長字段和壓縮數據的存在,各個列相同的分段點位置不一定會落在同一條記錄上,會導致讀取錯誤。
業界普遍采用分塊方案解決列存分段同步性問題:塊內數據用列式存儲,分段必須以塊為單位,在塊內不再分段并行。實施這種方法,要先確定每一塊的數據量大小。如果數據表總數據量固定,以后也不再追加數據,則很容易計算出一個合適的塊大小。但數據表一般都會有新增數據不斷追加進來,這就會出現塊大小如何確定的矛盾。假如塊較大,在初期總數據量較小時,分塊數會比較少,無法做到靈活分段。而均勻、靈活的分段是決定并行計算性能的關鍵。假如塊較小,在數據量增長后分塊數會變得很多,列數據在物理上將被拆成很多不連續的小塊,會多讀入分塊之間的少量無用數據。考慮硬盤的尋道時間,分塊數越多這個問題越嚴重。很多數據倉庫或大數據平臺都無法解決這個分塊大小和分塊數的矛盾,所以很難充分利用并行計算提升性能。
SPL提供了倍增分段方式,將固定(物理)分塊改為動態(邏輯)分塊,可以很好的解決這個矛盾。具體做法是:為每列數據建立固定大小(例如 1024 個索引位)的索引區,每個索引位存儲一條記錄的起始位置,相當于一條記錄為一塊。追加記錄到索引位填滿后,重寫索引區,丟棄偶數索引位,奇數位向前移動,空出索引區后一半位置。相當于將分塊數縮減為 512 個,兩條記錄為一塊。依次類推,重復追加數據、填滿、重寫索引區的過程。隨著數據量的增加,塊的大小(塊內記錄數)不斷翻倍。所有列的索引區要同步填充,且填滿后同步重寫,始終保持一致。這種辦法實質上是以記錄數作為分段依據的,而不是字節數,所以可以保證各個列即使分別分段也是同步的,不會出現錯位的情況。
以動態塊為單位分段時,塊個數保持在 512 到 1024 之間(記錄數小于 512 除外),可以滿足分段靈活的要求。各列的動態塊對應記錄數完全相同,也可以滿足分段均勻的要求。數據量無論大小,都可以獲得良好的分段效果。倍增分段原理的詳細介紹參見這里:SPL 的倍增分段。
示例代碼1中生成的組表T,缺省采用了倍增分段方案。要用T做并行計算,只要將A3代碼做簡單修改:
cursor函數加上@m選項,就可以做并行計算了。
后續再追加數據時,不需要重新生成一遍組表。打開組表直接追加即可,代碼大致是這樣的:
這里要保證游標cs中的待追加數據,按照f1,f2,f3三個字段繼續有序。實際應用中,待追加數據不一定滿足這個條件。對于這種情況,SPL也給出了高性能的解決方案,具體方法請參考:SPL 的有序存儲。
查找
列存比較適合遍歷計算,比如分組匯總等。對于大多數查找任務來講,列存卻會導致更差的性能。在不用索引的時候,通常的列存即使已經有序存儲,也無法使用二分法查找。這個原因,和上面并行分段介紹的一樣,還是因為列存不能保證各列的同步性,可能會出現錯位,導致讀取錯誤。這時列存數據只能用遍歷法來查找了,性能會很差。
列存數據表上也可以建立索引來避免遍歷,但非常麻煩。理論上講,要在索引中把各個字段的物理位置都記錄下來,索引容量就會比行存時的索引大很多,甚至可能和原數據表一樣大(因為每個字段都有個物理位置,索引中的數據量和原數據相同,僅是數據類型簡單)。而且,讀取時也要分別到各個字段的數據區去讀,而硬盤有個最小讀取單位,這會導致各列的總讀取量遠遠超過行存,表現出來就是查找性能差很多。
SPL采用倍增分段機制后,可以較迅速按記錄序號在列存格式中找到各字段值,就可以執行二分法了。同時,索引中記錄整條記錄的序號即可,容量就能小得多,和行存時差不多。不過,使用二分法或索引查找的時候,仍然需要到各個字段的數據塊分別讀取,性能還是趕不上行存。所以,如果要追求極致的查找性能,還是要采用行存。實際應用中,最好是讓程序員根據計算的需要來選擇是否列存。但是,有些數據倉庫做成了透明機制,不允許用戶自由選擇行存和列存,就很難達到最佳效果了。
SPL則將這個自由度留給了開發人員,可以根據實際需要來決定是否采用列存、哪些數據采用列存,從而獲得極致性能。
在前面的介紹中,組表缺省使用列存,但也提供行存模式,可以在創建時用選項 @r 指明。
示例代碼1中的A2可以改為:
這樣生成的就是行存組表。有了列存和行存兩個組表,程序員即可根據需要自由選擇使用。
對遍歷和查找性能要求都很高的場景,就只能用存儲空間來換計算時間。也就是將數據冗余存儲兩遍,列存用于遍歷,行存用于查找。不過,這種共存方案的數據要冗余兩遍,且行存還要再建立索引,所以整體占用的硬盤空間會比較大。
SPL 還提供了一種帶值索引,在建立索引時把其它字段值一起復制過來。原組表繼續采用列存用于遍歷,而索引本身已經保存了字段值并使用行存,在查找時一般不再訪問原表,能獲得更好的性能。帶值索引和行列共存方案一樣,都能兼顧遍歷、查找的性能。而且,帶值索引相當于行存加上索引,比行列共存方案占用的空間更小。
示例代碼2:帶值索引
A | |
1 | =file("T.ctx").open() |
2 | =A1.index(IDS;f1;f4,amt1,amt2) |
3 | =A1.icursor(f1,f4;f1==123456).fetch() |
4 | =A1.icursor(f4,amt2;f1>=123456 && f2<=654321) |
A2 建立索引IDS時,把要引用的字段f4,amt1,amt2抄在參數中,就可以在索引中復制這些字段值。以后取出目標值時,只要涉及字段在這部分內,就不必再讀取原表。
回顧與總結
采用列存可以只讀取需要的列,在總列數較多、計算涉及的列較少時,能減少硬盤訪問量,提高性能。但僅此還不夠,列存數據倉庫還要在數據壓縮、多線程并行和查找計算等方面做優化以將列存的效果做到最佳。
開源數據計算引擎SPL充分利用數據有序存儲的特征,在保持低 CPU 消耗的前提下,實現了較高壓縮率的壓縮算法,大幅減少了物理存儲量,進一步提高了性能。SPL還提供倍增分段機制,解決了列存分段難題,讓列存數據也能充分利用并行計算來提高效率。并且,SPL能夠自由建立行存、列存數據表,允許開發者自主選擇使用,且提供了帶值索引機制,可以同時實現高性能遍歷和查找計算。
SPL資料
SPL下載
SPL源代碼





















