













突破 etcd 限制!字節自研 K8s 存儲 KubeBrain

一. 背景
分布式應用編排調度系統 Kubernetes 已經成為云原生應用基座的事實標準,但是其官方的穩定運行規模僅僅局限在 5,000 節點。這對于大部分的應用場景已經足夠,但是對于百萬規模機器節點的超大規模應用場景, Kubernetes 難以提供穩定的支撐。
尤其隨著“數字化””云原生化”的發展,全球整體 IT 基礎設施規模仍在加速增長,對于分布式應用編排調度系統,有兩種方式來適應這種趨勢:
- 水平擴展 : 即構建管理多個集群的能力,在集群故障隔離、混合云等方面更具優勢,主要通過集群聯邦(Cluster Federation)來實現;
- 垂直擴展 : 即提高單個集群的規模,在降低集群運維管理成本、減少資源碎片、提高整體資源利用率方面更具優勢。
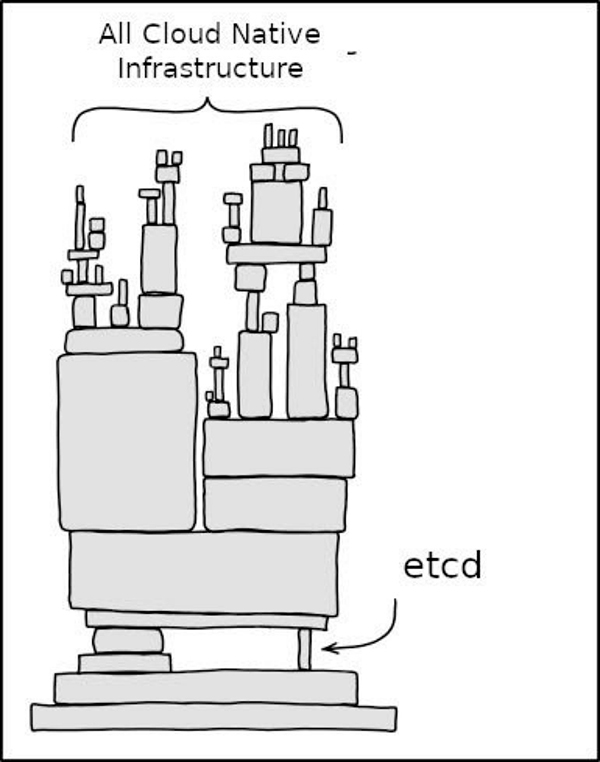
K8s 采用的是一種中心化的架構,所有組件都與 APIServer 交互,而 APIServer 則需要將集群元數據持久化到元信息存儲系統中。當前,etcd 是 APIServer 唯一支持的元信息存儲系統,隨著單個集群規模的逐漸增大,存儲系統的讀寫吞吐以及總數據量都會不斷攀升,etcd 不可避免地會成為整個分布式系統的瓶頸。
1.1 Kubernetes元信息存儲需求
APIServer 并不能直接使用一般的強一致 KV 數據庫作為元信息存儲系統,它與元信息存儲系統的交互主要包括數據全量和增量同步的 List/Watch,以及單個 KV 讀寫。更近一步來說,它主要包含以下方面:
- 在版本控制方面,存儲系統需要對 APIServer 暴露數據的版本信息,APIServer 側依賴于數據的版本生成對應的 ResourceVersion;
- 在寫操作方面,存儲系統需要支持 Create/Update/Delete 三種語義的操作,更為重要的是,存儲系統需要支持在寫入或者刪除數據時對數據的版本信息進行 CAS;
- 在讀操作方面,存儲系統需要支持指定版本進行快照 List 以此從存儲中獲取全量的數據,填充APIServer 中的 WatchCache 或供查詢使用,此外也需要支持讀取數據的同時獲取對應的數據版本信息;
- 在事件監聽方面,存儲系統需要支持獲取特定版本之后的有序變更,這樣 APIServer 通過 List 從元信息存儲中獲取了全量的數據之后,可以監聽快照版本之后的所有變更事件,進而以增量的方式來更新 Watch Cache 以及向其他組件進行變更的分發,進而保證 K8s 各個組件中數據的最終一致性。
1.2 etcd 的實現方式與瓶頸
etcd 本質上是一種主從架構的強一致、高可用分布式 KV 存儲系統:
- 節點之間,通過 Raft 協議進行選舉,將操作抽象為 log 基于 Raft 的日志同步機制在多個狀態機上同步;
- 單節點上,按順序將 log 應用到狀態機,基于 boltdb 進行狀態持久化 。
對于 APIServer 元信息存儲需求,etcd 大致通過以下方式來實現:
- 在版本控制方面,etcd 使用 Revision 作為邏輯時鐘,對每一個修改操作,會分配遞增的版本號Revision,以此進行版本控制,并且在內存中通過 TreeIndex 管理 Key 到 Revision 的索引;
- 在寫操作方面,etcd 以串行 Apply Raft Log 的方式實現,以 Revision 為鍵,Key/Value/Lease 等數據作為值存入 BoltDB 中,在此基礎上實現了支持對 Revision 進行 CAS 的寫事務;
- 在讀操作方面,etcd 則是通過管理 Key 到 Revision 的 TreeIndex 來查詢 Revision 進而查詢 Value,并在此基礎上實現快照讀;
- 在事件監聽方面,歷史事件可以從 BoltDB 中指定 Revision 獲取 KV 數據轉換得到,而新事件則由寫操作同步 Notify 得到。
etcd 并不是一個專門為 K8s 設計的元信息存儲系統,其提供的能力是 K8s 所需的能力的超集。在使用過程中,其暴露出來的主要問題有:
- etcd 的網絡接口層限流能力較弱,雪崩時自愈能力差;
- etcd 所采用的是單 raft group,存在單點瓶頸,單個 raft group 增加節點數只能提高容錯能力,并不能提高寫性能;
- etcd 的 ExpensiveRead 容易導致 OOM,如果采用分頁讀取的話,延遲相對會提高;
- boltdb 的串行寫入,限制了寫性能,高負載下寫延遲會顯著提高;
- 長期運行容易因為碎片問題導致寫性能發生一定劣化,線上集群定期通過 defrag 整理碎片,一方面會比較復雜,另一方面也可能會影響可用性。
二. 新的元數據存儲
過去面對生產環境中 etcd 的性能問題,只能通過按 Resource 拆分存儲、etcd 參數調優等手段來進行一定的緩解。但是面對 K8s 更大范圍的應用之后帶來的挑戰,我們迫切的需要一個更高性能的元數據存儲系統作為 etcd 的替代方案,從而能對上層業務有更有力的支撐。
在調研了 K8s 集群的需求以及相關開源項目之后,我們借鑒了 k3s 的開源項目 kine 的思想,設計并實現了基于分布式 KV 存儲引擎的高性能 K8s 元數據存儲項目—— KubeBrain 。
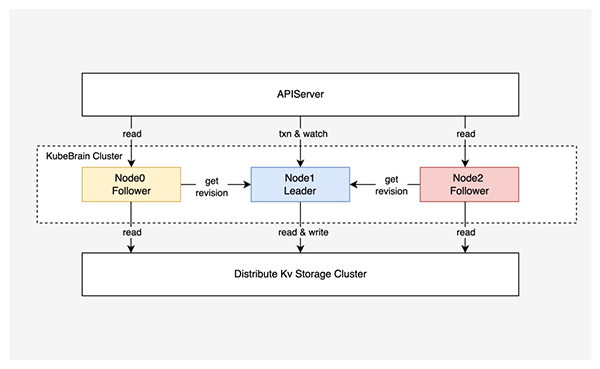
KubeBrain 系統實現了 APIServer 所使用的元信息存儲 API ,整體采用主從架構,主節點負責處理寫操作和事件分發,從節點負責處理讀操作,主節點和從節點之間共享一個分布式強一致 KV 存儲,在此基礎上進行數據讀寫。下面介紹 KubeBrain 的核心模塊。
2.1 存儲引擎
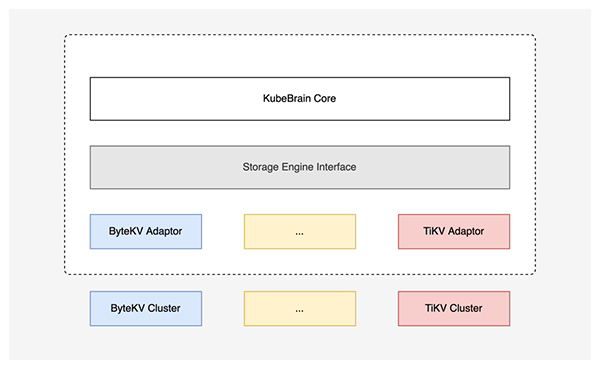
KubeBrain 統一抽象了邏輯層所使用的 KeyValue 存儲引擎接口,以此為基礎,項目實現了核心邏輯與底層存儲引擎的解耦:
- 邏輯層基于存儲引擎接口來操作底層數據,不關心底層實現;
- 對接新的存儲引擎只需要實現對應的適配層,以實現存儲接口。
目前項目已經實現了對 ByteKV 和 TiKV 的適配,此外還實現了用于測試的適配單機存儲 Badger 的版本。需要注意的是,并非所有 KV 存儲都能作為 KubeBrain 的存儲引擎。當前 KubeBrain 對于存儲引擎有著以下特性要求:
- 支持快照讀
- 支持雙向遍歷
- 支持讀寫事務或者帶有CAS功能的寫事務
- 對外暴露邏輯時鐘
此外,由于 KubeBrain 對于上層提供的一致性保證依賴于存儲引擎的一致性保證, KubeBrain 要求存儲引擎的事務需要達到以下級別(定義參考 HATs :??http://www.vldb.org/pvldb/vol7/p181-bailis.pdf):??
- Isolation Guarantee: Snapshot Isolation
- Session Guarantee: Linearizable
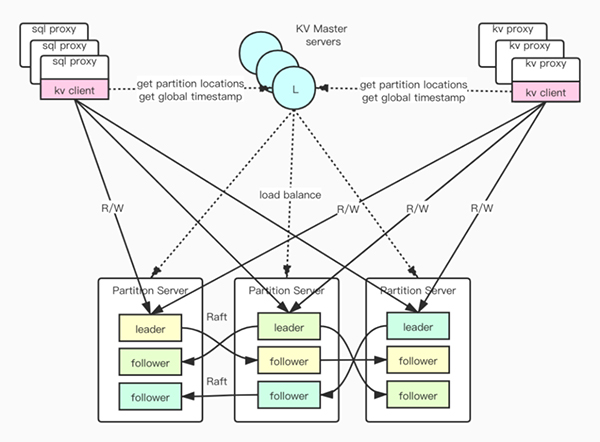
在內部生產環境中, KubeBrain 均以 ByteKV 為存儲引擎提供元信息存儲服務。ByteKV 是一種強一致的分布式 KV 存儲。在 ByteKV 中,數據按照 key 的字典序有序存儲。當單個 Partition 數據大小超過閾值時, Partition 自動地分裂,然后可以通過 multi-raft group 進行水平擴展,還支持配置分裂的閾值以及分裂邊界選擇的規則的定制。此外, ByteKV 還對外暴露了全局的時鐘,同時支持寫事務和快照讀,并且提供了極高的讀寫性能以及強一致的保證。
2.2 選主機制
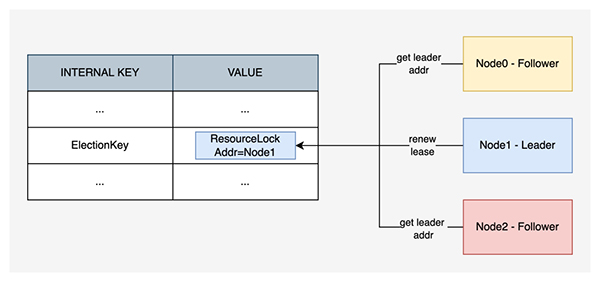
KubeBrain 基于底層強一致的分布式 KV 存儲引擎,封裝實現了一種 ResourceLock,在存儲引擎中指向一組特定的 KeyValue。ResourceLock 中包含主節點的地址以及租約的時長等信息。
KubeBrain 進程啟動后均以從節點的身份對自己進行初始化,并且會自動在后臺進行競選。競選時,首先嘗試讀取當前的 ResourceLock。如果發現當前 ResourceLock 為空,或者 ResourceLock 中的租約已經過期,節點會嘗試將自己的地址以及租約時長以 CAS 的方式寫入 ResourceLock,如果寫入成功,則晉升為主節點。
從節點可以通過 ResourceLock 讀取主節點的地址,從而和主節點建立連接,并進行必要的通信,但是主節點并不感知從節點的存在。即使沒有從節點,單個 KubeBrain 主節點也可以提供完成的 APIServer 所需的 API,但是主節點宕機后可用性會受損。
2.3 邏輯時鐘
KubeBrain 與 etcd 類似,都引入了 Revision 的概念進行版本控制。KubeBrain 集群的發號器僅在主節點上啟動。當從節點晉升為主節點時,會基于存儲引擎提供的邏輯時鐘接口來進行初始化,發號器的Revision 初始值會被賦值成存儲引擎中獲取到的邏輯時間戳。
單個 Leader 的任期內,發號器發出的整數號碼是單調連續遞增的。主節點發生故障時,從節點搶到主,就會再次重復一個初始化的流程。由于主節點的發號是連續遞增的,而存儲引擎的邏輯時間戳可能是非連續的,其增長速度是遠快于連續發號的發號器,因此能夠保證切主之后, Revision 依然是遞增的一個趨勢,舊主節點上發號器所分配的最大的 Revision 會小于新主節點上發號器所分配的最小的Revision。
KubeBrain 主節點上的發號是一個純內存操作,具備極高的性能。由于 KubeBrain 的寫操作在主節點上完成,為寫操作分配 Revision 時并不需要進行網絡傳輸,因此這種高性能的發號器對于優化寫操作性能也有很大的幫助。
2.4 數據模型
KubeBrain 對于 API Server 讀寫請求參數中的 Raw Key,會進行編碼出兩類 Internal Key寫入存儲引擎索引和數據。對于每個 Raw Key,索引 Revision Key 記錄只有一條,記錄當前 Raw Key 的最新版本號, Revision Key 同時也是一把鎖,每次對 Raw Key 的更新操作需要對索引進行 CAS。數據記錄Object Key 有一到多條,每條數據記錄了 Raw Key 的歷史版本與版本對應的 Value。Object Key 的編碼方式為magic+raw_key+split_key+revision,其中:
- magic為\x57\xfb\x80\x8b;
- raw_key為實際 API Server 輸入到存儲系統中的 Key ;
- split_key為$;
- revision為邏輯時鐘對寫操作分配的邏輯操作序號通過 BigEndian 編碼成的 Bytes 。
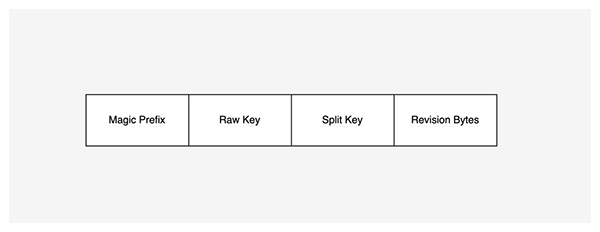
- 根據 Kubernetes 的校驗規則,raw_key 只能包含小寫字母、數字,以及'-' 和 '.',所以目前選擇 split_key 為 $ 符號。
特別的,Revision Key 的編碼方式和 Object Key 相同,revision取長度為 8 的空 Bytes 。這種編碼方案保證編碼前和編碼后的比較關系不變。
在存儲引擎中,同一個 Raw Key 生成的所有 Internal Key 落在一個連續區間內 。
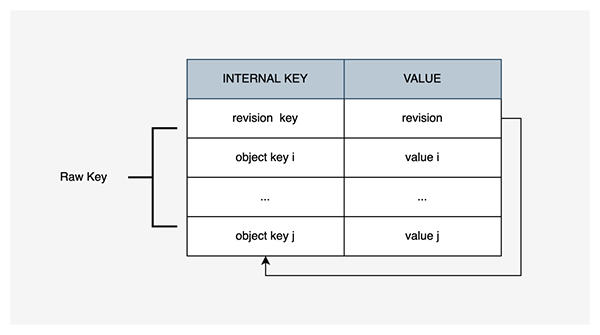
這種編碼方式有以下優點:
- 編碼可逆,即可以通過Encode(RawKey,Revision)得到InternalKey,相對應的可以通過Decode(InternalKey)得到Rawkey與Revision;
- 將 Kubernetes 的對象數據都轉換為存儲引擎內部的 Key-Value 數據,且每個對象數據都是有唯一的索引記錄最新的版本號,通過索引實現鎖操作;
- 可以很容易地構造出某行、某條索引所對應的 Key,或者是某一塊相鄰的行、相鄰的索引值所對應的 Key 范圍;
- 由于 Key 的格式非單調遞增,可以避免存儲引擎中的遞增 Key 帶來的熱點寫問題
2.5 數據寫入
每一個寫操作都會由發號器分配一個唯一的寫入 revision ,然后并發地對存儲引擎進行寫入。在 創建、更新 和 刪除 Kubernetes 對象數據的時候,需要同時操作對象對應的索引和數據。由于索引和數據在底層存儲引擎中是不同的 Key-Value 對,需要使用 寫事務 保證更新過程的 原子性,并且要求至少達到 Snapshot Isolation 。
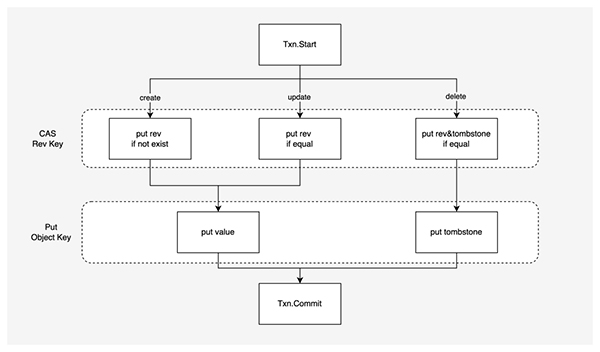
同時 KubeBrain 依賴索引實現了樂觀鎖進行并發控制。KubeBrain 寫入時,會先根據 APIServer 輸入的 RawKey 以及被發號器分配的 Revision 構造出實際需要到存儲引擎中的 Revision Key 和 Object Key,以及希望寫入到 Revision Key 中的 Revision Bytes。在寫事務過程中,先進行索引 Revision Key 的檢查,檢查成功后更新索引 Revision Key,在操作成功后進行數據 Object Key 的插入操作。
- 執行 Create 請求時,當 Revision Key 不存在時,才將 Revision Bytes 寫入 Revision Key 中,隨后將 API Server 寫入的 Value 寫到 Object Key 中;
- 執行 Update 請求時,當 Revision Key 中存放的舊 Revision Bytes 符合預期時,才將新 Revision Bytes 寫入,隨后將 API Server 寫入的 Value 寫到 Object Key 中;
- 執行 Delete 請求時,當 Revision Key 中存放的舊 Revision Bytes 符合預期時,才將新 Revision Bytes 附帶上刪除標記寫入,隨后將 tombstone 寫到 Object Key 中。
由于寫入數據時基于遞增的 Revision 不斷寫入新的 KeyValue , KubeBrain 會進行后臺的垃圾回收操作,將 Revision 過舊的數據進行刪除,避免數據量無限增長。
2.6 數據讀取
數據讀取分成點讀和范圍查詢查詢操作,分別對應 API Server 的 Get 和 List 操作。

Get 需要指定讀操作的ReadRevision,需要讀最新值時則將 ReadRevision 置為最大值MaxUint64, 構造 Iterator ,起始點為Encode(RawKey, ReadRevision),向Encode( RawKey, 0)遍歷,取第一個。
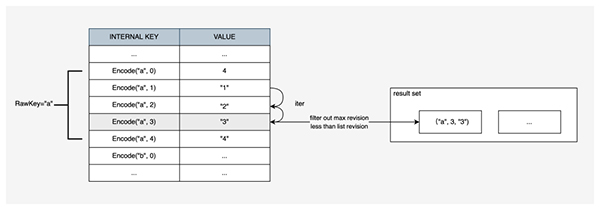
范圍查詢需要指定讀操作的ReadRevision 。對于范圍查找的 RawKey 邊界[RawKeyStart, RawKeyEnd)區間, KubeBrain 構造存儲引擎的 Iterator 快照讀,通過編碼將 RawKey 的區間映射到存儲引擎中 InternalKey 的數據區間
- InternalKey 上界InternalKeyStart為Encode(RawKeyStart, 0)
- InternalKey 的下界為InternalKeyEnd為Encode(RawKeyEnd, MaxRevision)
對于存儲引擎中[InternalKeyStart, InternalKeyEnd)內的所有數據按序遍歷,通過Decode(InternalKey)得到RawKey與Revision,對于一個RawKey 相同的所有ObjectKey,在滿足條件Revision<=ReadRevision的子集中取Revision最大的,對外返回。 2.7 事件機制
對于所有變更操作,會由 TSO 分配一個連續且唯一的 revision ,然后并發地寫入存儲引擎中。變更操作寫入存儲引擎之后,不論寫入成功或失敗,都會按照 revision 從小到大的順序,將變更結果提交到滑動窗口中,變更結果包括變更的類型、版本、鍵、值、寫入成功與否 。在記錄變更結果的滑動窗口中,從起點到終點,所有變更數據中的 revision 嚴格遞增,相鄰 revision 差為 1。
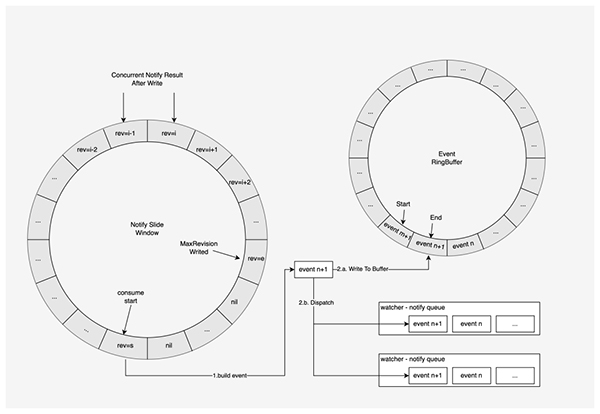
記錄變更結果的滑動窗口由事件生成器統一從起點開始消費,取出的變更結果后會根據變更的 revision更新發號器的 commit index ,如果變更執行成功,則還會構造出對應的修改事件,將并行地寫入事件緩存和分發到所有監聽所創建出的通知隊列。
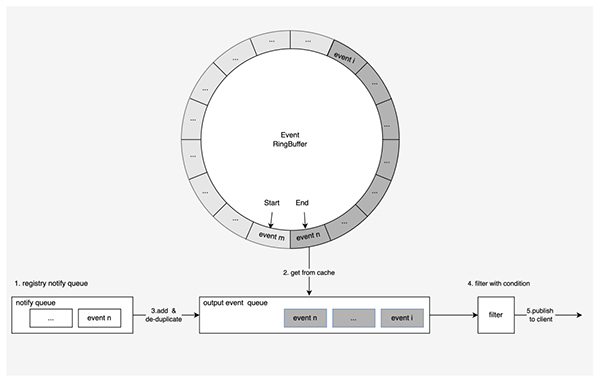
在元數據存儲系統中,需要監聽指定邏輯時鐘即指定 revision 之后發生的所有修改事件,用于下游的緩存更新等操作,從而保證分布式系統的數據最終一致性。注冊監聽時,需要傳入起始 revision 和過濾參數,過濾參數包括 key 前綴等等。
當客戶端發起監聽時,服務端在建立事件流之后的處理,分成以下幾個主要步驟:
- 處理監聽注冊請求時首先創建通知隊列,將通知隊列注冊到事件生成組件中,獲取下發的新增事件;
- 從事件緩存中拉取事件的 revision 大于等于給定要求 revision 所有事件到事件隊列中,并放到輸出隊列中,以此獲取歷史事件;
- 將通知隊列中的事件取出,添加到輸出隊列中, revision 去重之后添加到輸出隊列;
- 按照 revision 從小到大的順序,依次使用過濾器進行過濾;
- 將過濾后符合客戶端要求的事件,通過事件流推送到元數據存儲系統外部的客戶端。
三. 落地效果
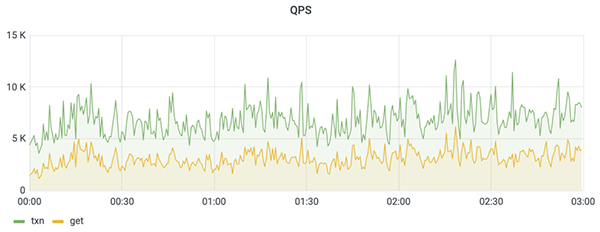
- 在 Benchmark 環境下,基于 ByteKV 的 KubeBrain 對比于 etcd 純寫場景吞吐提升 10 倍左右,延遲大幅度降低, PCT 50 降低至 1/6 ,PCT 90 降低至 1/20 ,PCT 99降低至 1/4 ;讀寫混合場景吞吐提升 4 倍左右;事件吞吐大約提升5倍;
- 在模擬 K8s Workload 的壓測環境中,配合 APIServer 側的優化和調優,支持 K8s 集群規模達到 5w Node 和 200w Pod;
- 在生產環境中,穩定上量至 2.1w Node ,高峰期寫入超過 1.2w QPS,讀寫負載合計超過 1.8w QPS。
四. 未來演進
項目未來的演進計劃主要包括四個方面的工作:
- 探索實現多點寫入的方案以支持水平擴展 現在 KubeBrain 本質上還是一個單主寫入的系統,KubeBrain 后續會在水平擴展方面做進一步的探索,后續也會在社區中討論;
- 提升切主的恢復速度 當前切主會觸發 API Server 側的 Re-list ,數據同步的開銷較大,我們會在這方面進一步做優化;
- 實現內置存儲引擎 實現兩層存儲融合,由于現在在存儲引擎、KubeBrain 中存在兩層 MVCC 設計,整體讀寫放大較多,實現融合有助于降低讀寫放大,更進一步提高性能;
- 完善周邊組件 包括數據遷移工具、備份工具等等,幫助用戶更好地使用 KubeBrain 。
五. 關于我們
字節基礎架構編排調度團隊,負責構建字節跳動內部的容器云平臺,為產品線提供運行基石;以超大容器集群規模整體支撐了字節內產品線,涵蓋今日頭條、抖音、西瓜視頻等。
團隊支持業務同時覆蓋在線、離線機器學習,推薦/廣告/搜索等多種應用場景;在持續多年的超高速增長中,積累了豐富的 Kubernetes/容器超大規模應用經驗,旨在打造覆蓋多場景,多地域的千萬級容器的大平臺。


























