十個實用的數據可視化的圖表總結
可視化是一種方便的觀察數據的方式,可以一目了然地了解數據塊。我們經常使用柱狀圖、直方圖、餅圖、箱圖、熱圖、散點圖、線狀圖等。這些典型的圖對于數據可視化是必不可少的。除了這些被廣泛使用的圖表外,還有許多很好的卻很少被使用的可視化方法,這些圖有助于完成我們的工作,下面我們看看有那些圖可以進行。

1、平行坐標圖(Parallel Coordinate)
我們最多可以可視化 3 維數據。但是我們有時需要可視化超過 3 維的數據才能獲得更多的信息。我們經常使用 PCA 或 t-SNE 來降維并繪制它。在降維的情況下,可能會丟失大量信息。在某些情況下,我們需要考慮所有特征, 平行坐標圖有助于做到這一點。
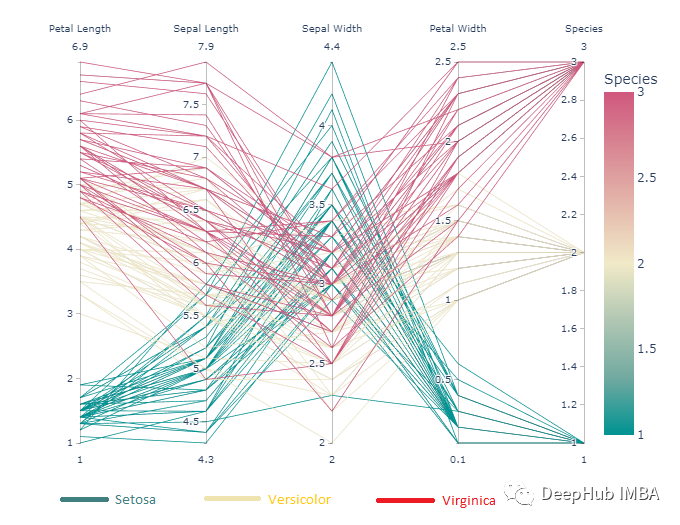
上面的圖片。橫線(平行軸)表示鳶尾花的特征(花瓣長、萼片長、萼片寬、花瓣寬)。分類是Setosa, Versicolor和Virginica。上圖將該物種編碼為Setosa→1,Versicolor→2,Virginica→3。每個平行軸包含最小值到最大值(例如,花瓣長度從1到6.9,萼片長度從4.3到7.9,等等)。例如,考慮花瓣長度軸。這表明與其他兩種植物相比,瀨蝶屬植物的花瓣長度較小,其中維珍屬植物的花瓣長度最高。
有了這個圖,我們可以很容易地獲得數據集的總體信息。數據集是什么樣子的?讓我們來看看。
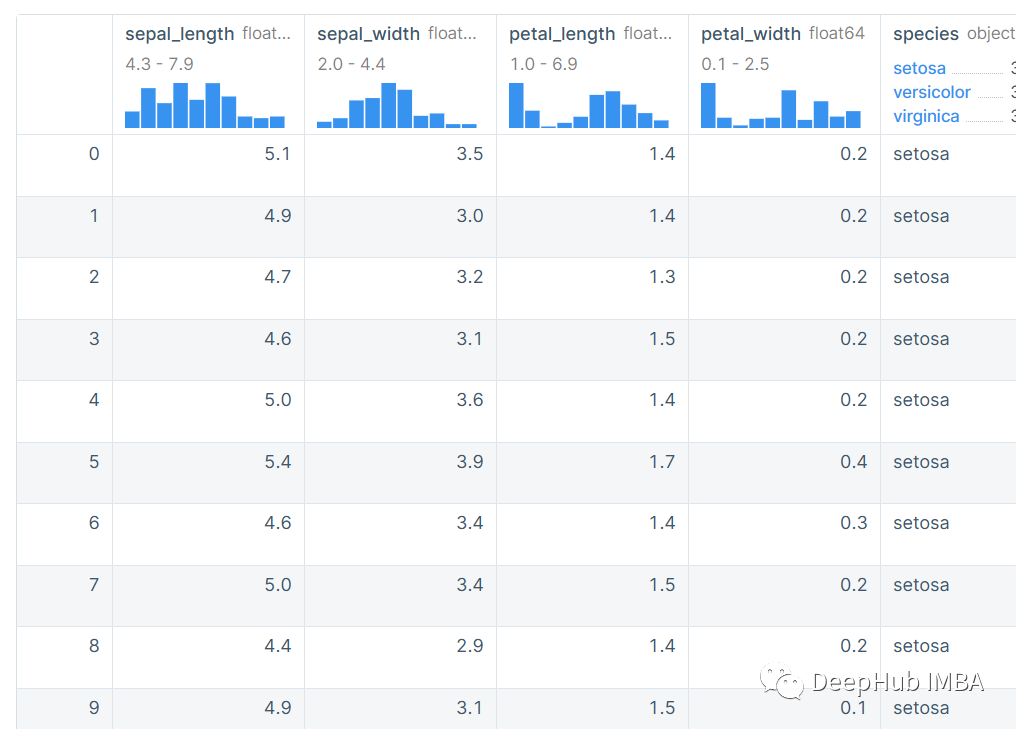
讓我們用Plotly Express庫[1]可視化數據。Plotly庫提供了一個交互式繪圖工具。

除了上圖以外我們還可以使用其他庫,如pandas、scikit-learn和matplotlib來繪制并行坐標。
2、六邊形分箱圖 (Hexagonal Binning)
六邊形分箱圖是一種用六邊形直觀表示二維數值數據點密度的方法。
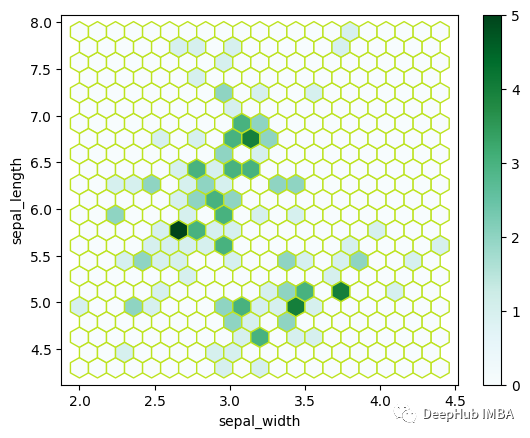
我考慮了上一節的數據集來繪制上面的六邊形分箱圖。Pandas 允許我們繪制六邊形 binning [2]。我已經展示了用于查找 sepal_width 和 sepal_length 列的密度的圖。
如果仔細觀察圖表,我們會發現總面積被分成了無數個六邊形。每個六邊形覆蓋特定區域。我們注意到六邊形有顏色變化。六邊形有的沒有顏色,有的是淡綠色,有的顏色很深。根據圖右側顯示的色標,顏色密度隨密度變化。比例表示具有顏色變化的數據點的數量。六邊形沒有填充顏色,這意味著該區域沒有數據點。
其他庫,如 matplotlib、seaborn、bokeh(交互式繪圖)也可用于繪制它。
3、等高線密度圖(Contour )
二維等高線密度圖是可視化特定區域內數據點密度的另一種方法。這是為了找到兩個數值變量的密度。例如,下面的圖顯示了在每個陰影區域有多少數據點。
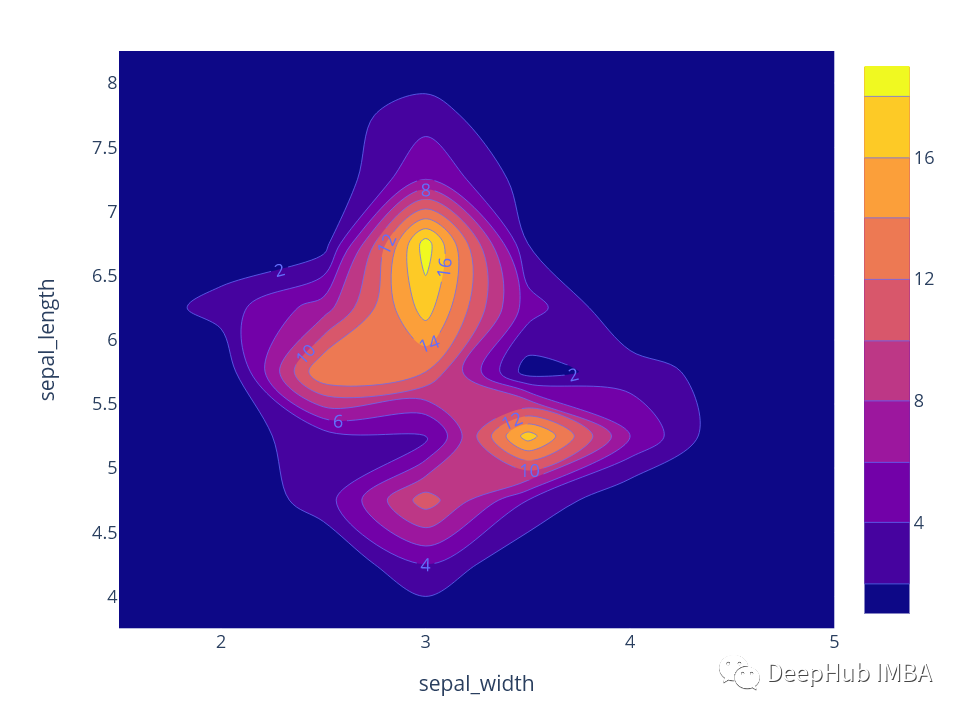
為了生成上面的圖表,我這里使用了plotly庫,因為它可以方便地繪制交互式的圖表。我們這里繪制了兩個變量 sepal_width 和 sepal_length 的密度。
當然,也可以使用其他庫,如seaborn、matplotlib等。
4、QQ-plot
QQ plot是另一個有趣的圖。QQ是Quantile - Quantile plot的縮寫(Quantile/percentile是一個范圍,在這個范圍內數據下降了指定百分比。例如,第10個quantile/percentile表示在該范圍下,找到了10%的數據,90% 超出范圍)。這是一種直觀地檢查數值變量是否服從正態分布的方法。讓我解釋一下它是如何工作的。

圖(a)是樣本分布;(b) 是標準正態分布。對于樣本分布,數據范圍從 10 到 100(100% 數據在 10 到 100 之間)。但對于標準正態分布,100% 的數據在 -3 到 3(z 分數)的范圍內。在 QQ 圖中,兩個 x 軸值均分為 100 個相等的部分(稱為分位數)。如果我們針對 x 和 y 軸繪制這兩個值,我們將得到一個散點圖。

散點圖位于對角線上。這意味著樣本分布是正態分布。如果散點圖位于左邊或右邊而不是對角線,這意味著樣本不是正態分布的。
導入必要的庫
生成正態分布數據。
繪制數據點的分布。
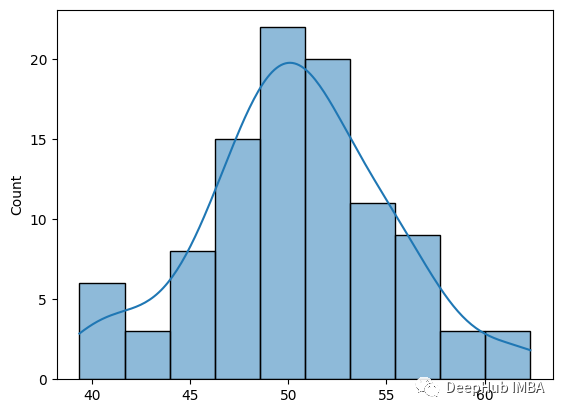
該圖顯示數據是正態分布的。我們用數據點做qq-plot來檢驗它是否正態分布。
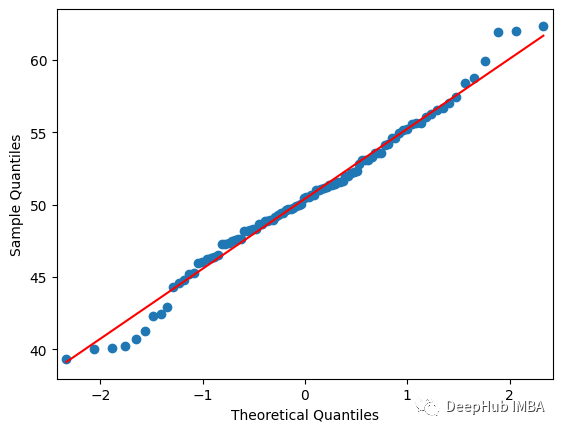
該圖顯示散點位于對角線上。所以它是正態分布的。
5、小提琴圖(Violin Plot)
小提琴圖與箱線圖相關。我們能從小提琴圖中獲得的另一個信息是密度分布。簡單來說就是一個結合了密度分布的箱線圖。我們將其與箱線圖進行比較。
在小提琴圖中,小提琴中間的白點表示中點。實心框表示四分位數間距 (IQR)。上下相鄰值是異常值的圍欄。超出范圍,一切都是異常值。下圖顯示了比較。

讓我們看看小提琴圖的可視化

我們還可以通過傳遞名稱來繪制不同物種的小提琴圖。
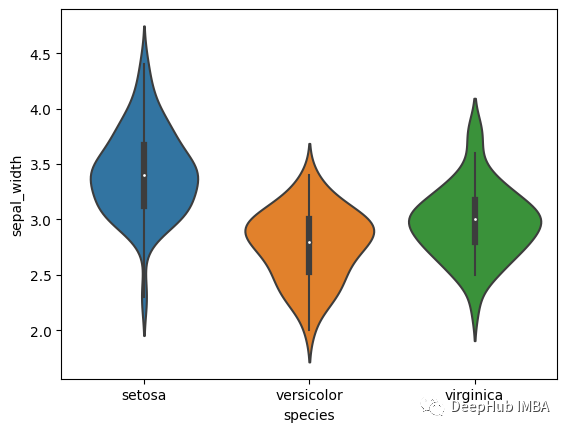
還可以使用其他庫,如plotly、matplotlib等來繪制小提琴圖。
6、箱線圖的改進版(Boxen plot)
Boxenplot 是 seaborn 庫引入的一種新型箱線圖。對于箱線圖,框是在四分位數上創建的。但在 Boxenplot 中,數據被分成更多的分位數。它提供了對數據的更多內存。
鳶尾花數據集的 Boxenplot 顯示了 sepal_width 的數據分布。

上圖顯示了比箱線圖更多的盒。這是因為每個框代表一個特定的分位數。
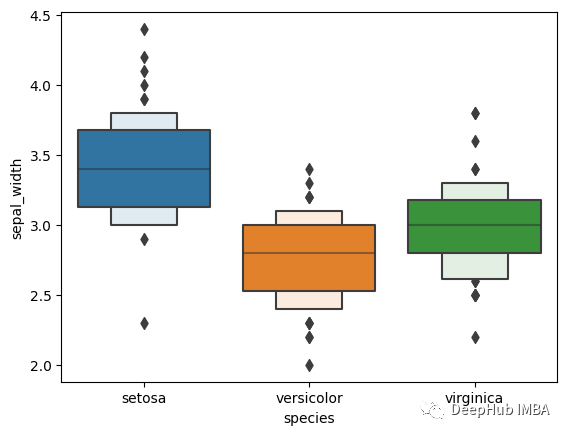
不同物種sepal_width的Boxenplot圖。
7、點圖
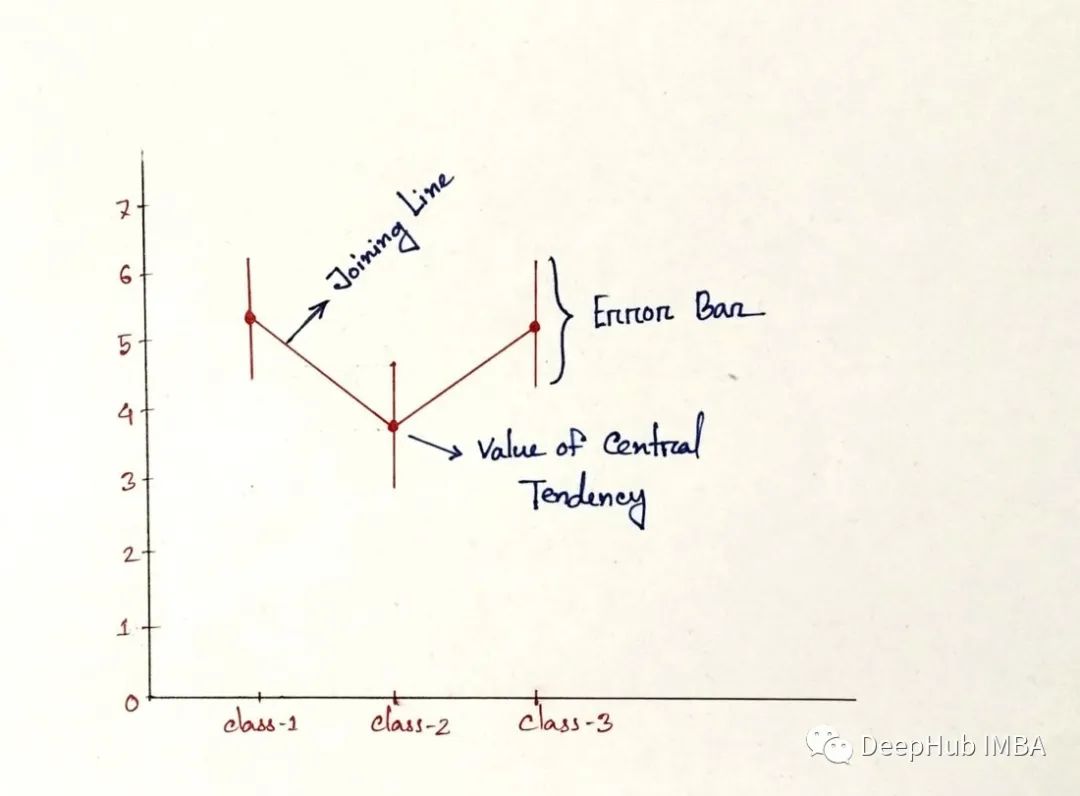
下圖中有一些名為誤差線的垂直線和其他一些連接這些垂直線的線。讓我們看看它的確切含義。
點圖是一種通過上圖中顯示的點的位置來表示數值變量集中趨勢的方法,誤差條表示變量的不確定性(置信區間)[4]。繪制線圖是為了比較不同分類值的數值變量的變異性 [4]。
讓我們舉一個實際的例子——
我們繼續使用 seaborn 庫和 iris 數據集(在平行坐標部分中提到)。
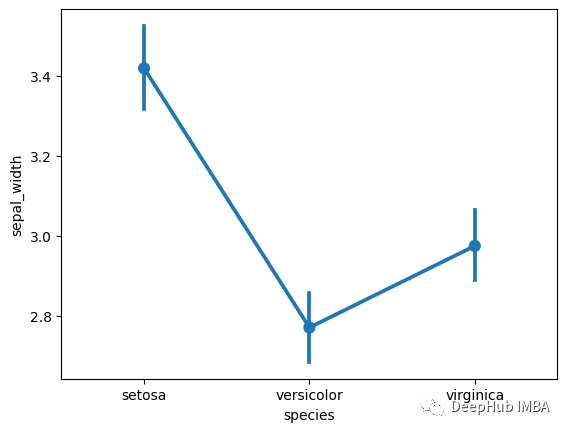
該圖表顯示了不同花的萼片寬度的變異性。我們還可以繪制多個點圖。
8、分簇散點圖(Swarm plot)
Swarm plot 是另一個受“beeswarm”啟發的有趣圖表。通過此圖我們可以輕松了解不同的分類值如何沿數值軸分布 [5]。它在不重疊數據點的情況下繪制數據。但它不適用于大型數據集。

9、旭日圖(Sunburst Chart)
它是圓環圖或餅圖的定制版本,將一些額外的層次信息集成到圖中 [7]。

整個圖表被分成幾個環(從內到外)。它保存層次結構信息,其中內環位于層次結構的頂部,外環位于較低的[7]階。


繪制旭日圖

sunburst類的path屬性提供了層次結構,其中性別位于層次結構的頂部,然后是日期和時間。
10、詞云(Word Cloud)
詞云圖的想法非常簡單。假設我們有一組文本文檔。單詞有很多,有些是經常出現的,有些是很少出現的。在詞云圖中,所有單詞都被繪制在特定的區域中,頻繁出現的單詞被高亮顯示(用較大的字體顯示)。有了這個詞云,我們可以很容易地找到重要的客戶反饋,熱門的政治議程話題等。

我們統計每個類別的數據數量

我們進行可視化。

該圖表顯示了頻率最高的所有類別。我們也可以用這個圖從文本中找到經常出現的單詞。
總結
數據可視化是數據科學中不可缺少的一部分。在數據科學中,我們與數據打交道。手工分析少量數據是可以的,但當我們處理數千個數據時它就變得非常麻煩。如果我們不能發現數據集的趨勢和洞察力,我們可能無法使用這些數據。希望上面介紹的的圖可以幫助你深入了解數據。