七個有用的Pandas顯示選項
Pandas是一個在數據科學中常用的功能強大的Python庫。它可以從各種來源加載和操作數據集。當使用Pandas時,默認選項就已經適合大多數人了。但是在某些情況下,我們可能希望更改所顯示內容的格式。所以就需要使用Pandas的一些定制功能來幫助我們自定義內容的顯示方式。

1、控制顯示的行數
在查看數據時,我們希望看到比默認行數更多或更少的行數(默認行數為10)。
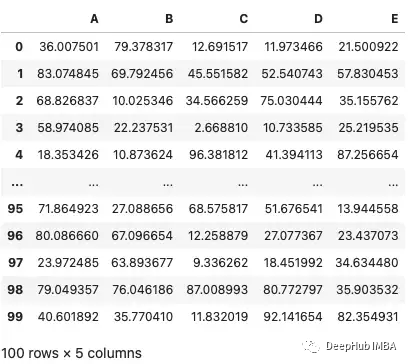
可以看到,默認包括數據幀的前5行和后5行。因為這樣可以防止pandas在調用數據框架時顯示大量的數據,從而降低計算機的速度。
這里有兩個選項可用于控制顯示的行數。
首先是display.max_rows,它控制在截斷之前顯示的最大行數。如果數據中的行數超過此值,則顯示將被截斷。默認設置為60。
如果希望顯示所有行,則需要將display.max_rows設置為None。如果數據非常大,這可能會占用很多資源并且降低計算速度。
這樣就可以看到df中的所有行。

如果數據的行數多于 max_rows 設置的行數,則必須將 display.min_rows 參數更改為要顯示的值。還需要確保 max_rows 參數大于 min_rows。
如果將min_rows設置為20,那么當查看時,將看到頂部有10行,底部有10行。
2、控制顯示的列數
當處理包含大量列的數據集時,pandas將截斷顯示,默認顯示20列。下圖第9列和第15列之間的三個點(省略號)表示已經被截斷了
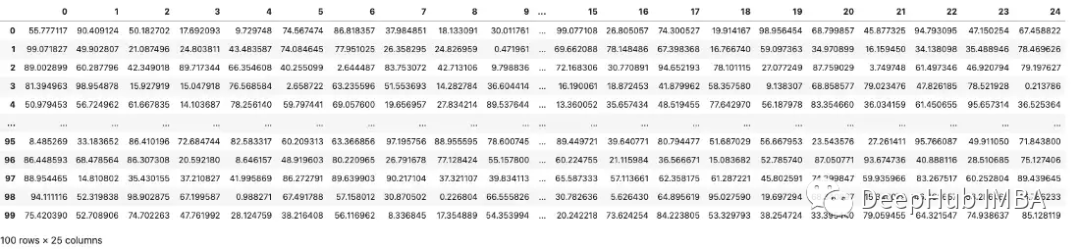
上述數據,是使用以下代碼顯示的:
要查看顯示上的更多列,可以更改display.max_columns參數
這樣做最多將顯示30列。但是這可能會導致其他問題,例如當有圖片時這會變得很難看。

3、禁止科學記數法
通常在處理科學數據時,你會遇到非常大的數字。一旦這些數字達到數百萬,Pandas就會將它們重新格式化為科學符號,這可能很有幫助,但并不總是如此。
要生成具有非常大值的數據,可以使用以下代碼。
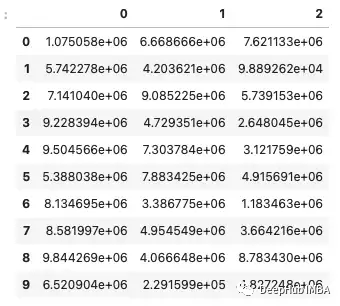
如果想要顯示這些數字的完整形式而不使用科學符號。這可以通過更改float_format顯示選項并傳入一個lambda函數來實現。這將重新格式化顯示,使其具有不帶科學記數法的值和最多保留小數點后3位。
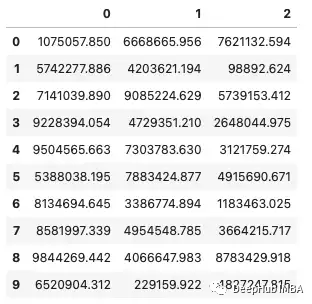
如果你想讓它看起來更好看,你可以在千位之間添加逗號分隔符。
下面的代碼可能看起來與上面的相同,但是如果您仔細查看該代碼的f'{x:部分后面有一個逗號。

4、更改數據的浮點精度
在某些情況下,數據可能在小數點后有太多的值,這樣看起來很亂。默認情況下,Pandas將在小數點后顯示6個位。

為了使它更容易閱讀,可以通過調用display.precision來減少顯示的值的數量。
數值列的浮點精度已降低到2。

此設置只更改數據的顯示方式。它不更改底層數據值。
5、控制Float格式
在某些情況下,數字可以代表百分比或貨幣價值。如果是這種情況,用正確的單位來格式化它們是很方便的。
若要在列后面添加百分比符號,可以調用display.float_format選項,并使用f-string傳入想要顯示的格式:

要以美元符號開始,可以這樣更改代碼:

6、更改默認的Pandas繪圖庫
在進行探索性數據分析時,通常需要快速生成數據圖。可以使用matplotlib來構建一個plot,但是在Pandas中可以使用.plot()方法使用幾行代碼來完成它。
Pandas為我們提供了一系列可以使用的繪圖庫:
- matplotlib
- hvplot >= 0.5.1
- holoviews
- pandas_bokeh
- plotly >= 4.8
- altair
要更改當前的默認繪圖庫,需要更改plotting.backend選項。
這樣就使用.plot方法創建plot時就會調用設置的庫

7、重置顯示選項
如果希望將特定選項的參數設置回默認值,可以調用reset_option方法并傳入想要重置的選項。
或者可以通過all作為參數將它們全部更改回默認值。
如果想一次設置多個選項可以這樣做。
這樣做可以幫助節省時間,減少編寫的代碼數量,提高可讀性。
總結
Pandas是一個功能強大的庫,但是默認選項可能不適合特定的需要。本文介紹了一些常用選項,可以改進查看數據的方式。