當我們說大數據Hadoop,究竟在說什么?
?前言
提到大數據,大抵逃不過兩個問題,一個是海量的數據該如何存儲,另外一個就是那么多數據該如何進行查詢計算呢。好在這些問題前人都有了解決方案,而Hadoop就是其中的佼佼者,是目前市面上最流行的一個大數據軟件,那它包括哪些內容呢?有什么特點呢?
Hadoop介紹
提到Hadoop,大家的理解是什么?
狹義上理解,Hadoop指的是Apache軟件基金會的一款用java語言實現,開源的軟件,允許用戶使用簡單的編程模型實現跨機器集群對海量數據進行分布式計算處理。
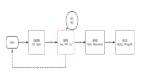
廣義上,Hadoop指的是圍繞Hadoop打造的大數據生態圈,如下圖所示, 其中Hadoop是整個生態圈的底座、地基,構建出整個大數據的生態系統。

Hadoop怎么來的?
Hadoop之父:Doug Cutting
《The Google file system》:谷歌分布式文件系統GFS
《MapReduce: Simplified Data Processing on Large Clusters》:谷歌分布式計算框架MapReduce
《Bigtable: A Distributed Storage System for Structured Data》:谷歌結構化數據存儲系統
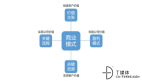
Hadoop三大核心組件
hadoop主要由3大部分組成,俗稱Hadoop三劍客:
Hadoop HDFS(分布式文件存儲系統)
全稱分布式文件系統,本質是一個文件系統,由于數據量很大,總不能將將所有數據存儲到一臺"電腦"上,哪有那么大磁盤的電腦,那么是不是可以存儲到多個不同的"電腦"上,也就是分布式的,把文件存儲在不同的節點中,主要是為了解決海量數據存儲的問題,它處在生態圈的底層與核心地位。
Hadoop MapReduce(分布式計算框架)
MapReduce作為大數據生態圈第一代分布式計算框架,主要是解決了海量數據的計算問題。
傳統的計算方式一般都是將數據從各個節點上加載過來,然后統一計算。這樣有個最大的弊端就是計算十分慢,只有一個節點工作。而MapReduce計算框架可以分布在各個節點上并行計算,最后進行歸并。
注意,MapReduce只是一個計算框架,或者說編程模型,不是一個軟件,無需部署。
Hadoop YARN(集群資源管理和任務調度平臺)
YARN是分布式通用的集群資源管理系統和任務調度平臺,怎么理解呢?
大數據的很多計算任務,比如MapReduce任務、或者其他的Spark任務等等,他們在計算的時候需要CPU、內存、磁盤等資源,那么多個任務進行運算的時候需要有個管理者去給他們進行資源分配、調度等,這個管理員就是YARN。
Hadoop優點
Hadoop為什么這么流行,這和它的眾多優點分不開。
擴容能力
Hadoop是在可用的計算機集群間分配數據并完成計算任務的,這些集群可方便靈活的方式擴展到數以千計的節點。
成本低
Hadoop集群允許通過部署普通廉價的機器組成集群來處理大數據,以至于成本很低。看重的是集群整體能力。
效率高
通過并發數據,Hadoop可以在節點之間動態并行的移動數據,使得速度非常快。
可靠性
能自動維護數據的多份復制,并且在任務失敗后能自動地重新部署(redeploy)計算任務。所以Hadoop的按位存儲和處理數據的能力值得人們信賴。
開源
由于Hadoop開源,所以整個社區活躍度很高,很多企業都是基于Hadoop構建他們的大數據平臺。
Hadoop架構變遷
Hadoop也一直在迭代升級,如今已經到了3.0時代了,那么每個大版本有什么差別呢?
1.Hadoop 1.0時代

Hadoop1.0時代只有HDFS?(分布式文件存儲)和MapReduce(資源管理和分布式數據處理)兩部分。
2.Hadoop 2.0時代

Hadoop2.0時代引入了YARN作為統一的集群資源管理和任務調度平臺,它不僅可以提交自己的任務,還可以提交其他的一些任務,是一個很大的變革,也是保證Hadoop的統治地位的一大原因。
3.Hadoop 3.0時代
Hadoop 3.0架構組件和Hadoop 2.0類似, 但是3.0著重于性能優化。
Hadoop初體驗
好了,上面基本講清楚Hadoop的基本內容,那Hadoop究竟長啥樣呢?至于安裝這邊就不介紹了。
Hadoop分布式文件系統
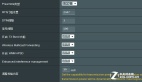
我們可以在web上看到hadoop的文件系統,其實和我們的目錄沒啥差別。

YARN集群資源管理和任務調度平臺
我們也可以在瀏覽器輸入指定的地址看到之前都提交過上面樣的計算任務。

至于MapReduce是看不到的,它只是一個計算框架,提交到這個Yarn上。
總結
本文講解了大數據開發中最流行的軟件Hadoop, 它主要分為3部分,管理文件存儲的hdfs, 統一管理資源和任務的調度平臺Yarn,以及提供了一種計算引擎MapReduce, 基于這三個"磐石",可以構建出整個大數據生態。