太強了!這么設計中間件完美解決了百萬并發的問題!
這篇文章,給大家聊聊一個百萬級并發的中間件系統的內核代碼里的鎖性能優化。
很多同學都對Java并發編程很感興趣,學習了很多相關的技術和知識。比如volatile、Atomic、synchronized底層、讀寫鎖、AQS、并發包下的集合類、線程池,等等。
一、對Java并發仍停留在理論階段
很多同學對Java并發編程的知識,可能看了很多的書,也通過不少視頻課程進行了學習。
但是,大部分人可能還是停留在理論的底層,主要是了解理論,基本對并發相關的技術很少實踐和使用,更很少做過復雜的中間件系統。
實際上,真正把這些技術落地到中間件系統開發中去實踐的時候,是會遇到大量的問題,需要對并發相關技術的底層有深入的理解和掌握。
然后,結合自己實際的業務場景來進行對應的技術優化、機制優化,才能實現最好的效果。
因此,本文將從筆者曾經帶過的一個高并發中間件項目的內核機制出發,來看看一個實際的場景中遇到的并發相關的問題。
同時,我們也將一步步通過對應的偽代碼演進,來分析其背后涉及到的并發的性能優化思想和實踐,最后來看看優化之后的效果。
二、中間件系統的內核機制:雙緩沖機制
這個中間件項目整體就不做闡述了,因為涉及核心項目問題。我們僅僅拿其中涉及到的一個內核機制以及對應的場景來給大家做一下說明。
其實這個例子是大量的開源中間件系統、大數據系統中都有涉及到的一個場景,就是:核心數據寫磁盤文件。
比如,大數據領域里的hadoop、hbase、elasitcsearch,Java中間件領域里的redis、mq,這些都會涉及到核心數據寫磁盤文件的問題。
而很多大型互聯網公司自研的中年間系統,同樣也會有這個場景。只不過不同的中間件系統,他的作用和目標是不一樣的,所以在核心數據寫磁盤文件的機制設計上,是有一些區別的。
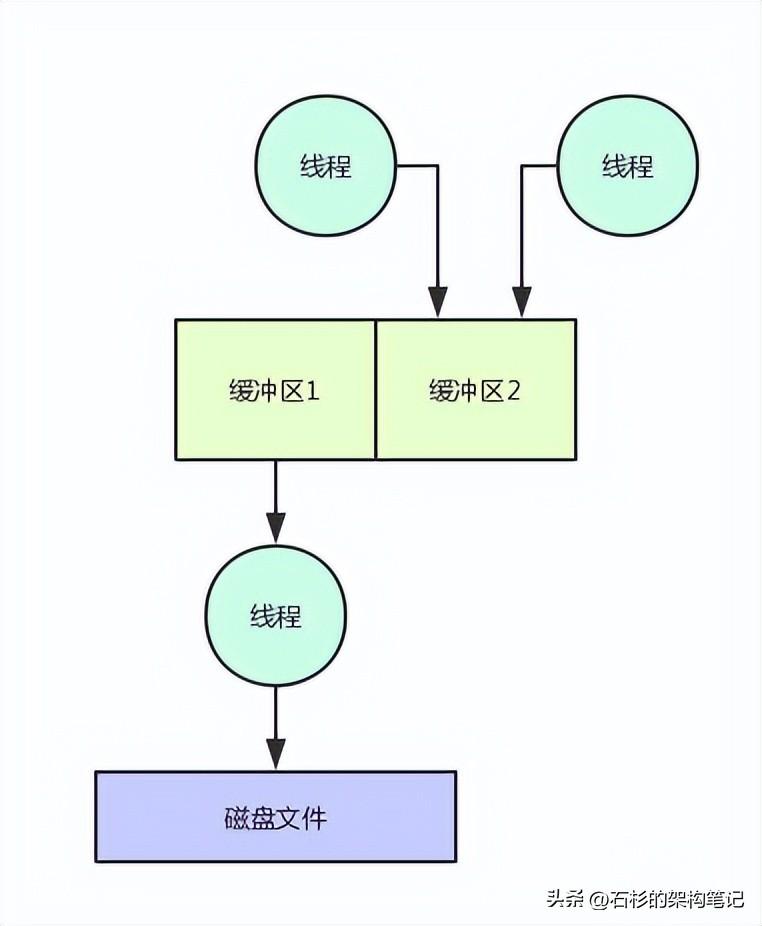
那么我們公司自研的中間件項目,簡單來說,需要實現的一個效果是:開辟兩塊內存空間,也就是經典的內存雙緩沖機制。
然后核心數據進來全部寫第一塊緩沖區,寫滿了之后,由一個線程進行那塊緩沖區的數據批量刷到磁盤文件的工作,其他線程同時可以繼續寫另外一塊緩沖區。
我們想要實現的就是這樣的一個效果。這樣的話,一塊緩沖區刷磁盤的同時,另外一塊緩沖區可以接受其他線程的寫入,兩不耽誤。核心數據寫入是不會斷的,可以持續不斷的寫入這個中間件系統中。
我們來看看下面的那張圖,也來了解一下這個場景。
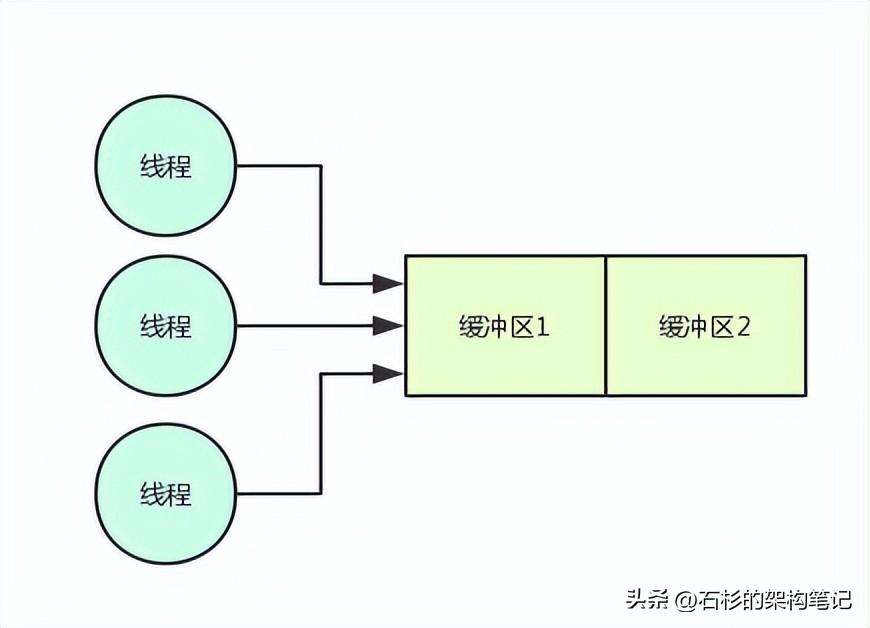
如上圖,首先是很多線程需要寫緩沖區1,然后是緩沖區1寫滿之后,就會由寫滿的那個線程把緩沖區1的數據刷入磁盤文件,其他線程繼續寫緩沖區2。
這樣,數據批量刷磁盤和持續寫內存緩沖,兩個事兒就不會耽誤了,這是中間件系統設計中極為常用的一個機制,大家看下面的圖。
三、百萬并發的技術挑戰
先給大家說一下這個中間件系統的背景:這是一個服務某個特殊場景下的中間件系統,整體是集群部署。
然后每個實例部署的都是高配置機器,定位是單機承載并發達到萬級甚至十萬級,整體集群足以支撐百萬級并發,因此對單機的寫入性能和吞吐要求極為高。
在超高并發的要求之下,上圖中的那個內核機制的設計就顯得尤為重要了。弄的不好,就容易導致寫入并發性能過差,達不到上述的要求。
此外在這里多提一句,類似的這種機制在很多其他的系統里都有涉及。
只不過不同的是,那篇文章是用這個機制來做MQ集群整體故障時的容災降級機制,跟本文的高并發中間件系統還有點不太一樣,所以在設計上考慮的一些細節也是不同的。
而且,之前那篇文章的主題是講這種內存雙緩沖機制的一個線上問題:瞬時超高并發下的系統卡死問題。
四、內存數據寫入的鎖機制以及串行化問題
首先我們先考慮第一個問題,你多個線程會并發寫同一塊內存緩沖,這個肯定有問題啊!
因為內存共享數據并發寫入的時候,必須是要加鎖的,否則必然會有并發安全問題,導致內存數據錯亂。
所以在這里,我們寫了下面的偽代碼,先考慮一下線程如何寫入內存緩沖。
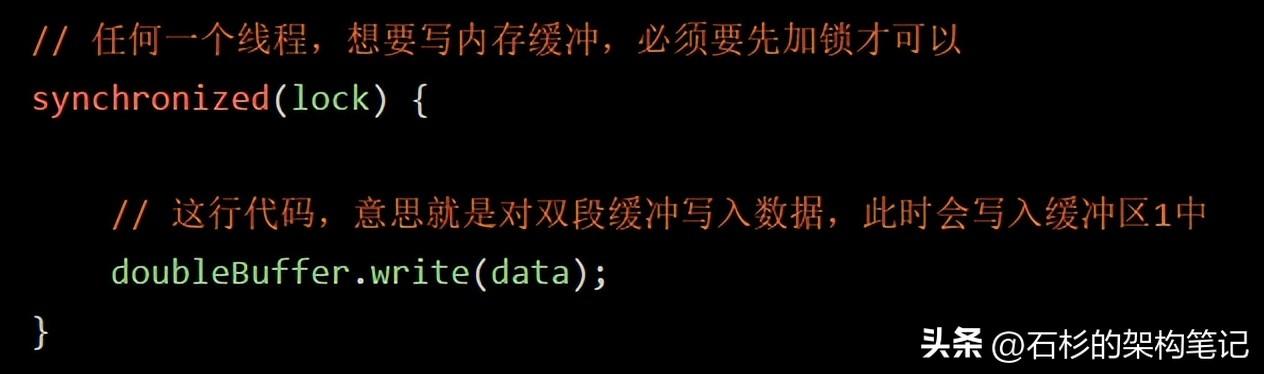
好了,這行代碼弄好之后,對應著下面的這幅圖,大家看一下。
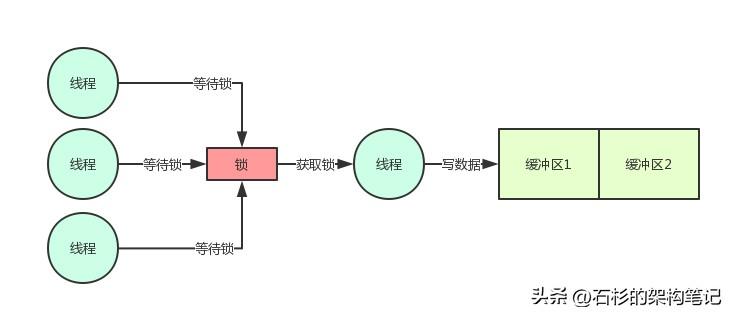
看到這里,就遇到了Java并發的第一個性能問題了,你要知道高并發場景下,大量線程會并發寫內存的,你要是直接這樣加一個鎖,必然會導致所有線程都是串行化。
即一個線程加鎖,寫數據,然后釋放鎖。接著下一個線程干同樣的事情。這種串行化必然導致系統整體的并發性能和吞吐量會大幅度降低的。
五、內存緩沖分片機制+分段枷鎖機制
因此在這里必須要對內存雙緩沖機制引入分段加鎖機制,也就是將內存緩沖切分為多個分片,每個內存緩沖分片就對應一個鎖。
這樣的話,你完全可以根據自己的系統壓測結果,調整內存分片數量,提升鎖的數量,進而允許大量線程高并發寫入內存。
我們看下面的偽代碼,對這塊就實現了內存緩沖分片機制:

好!我們再來看看,目前為止的圖是什么樣子的:
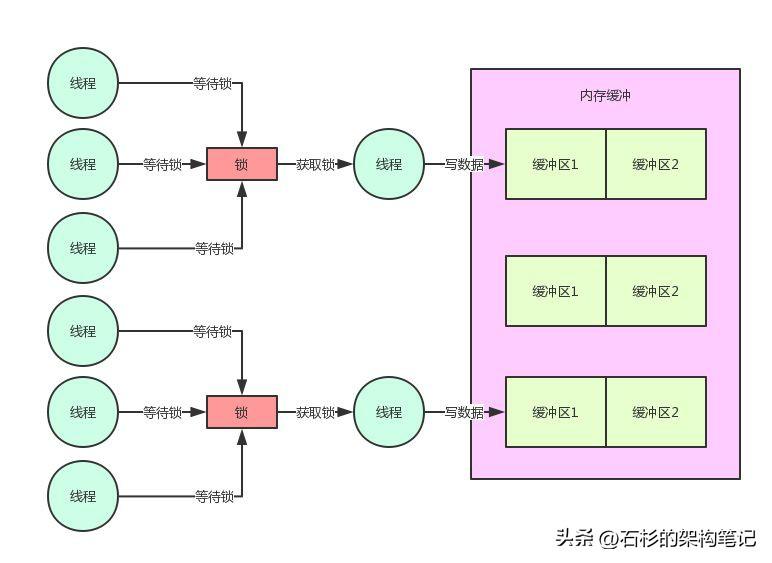
這里因為每個線程僅僅就是加鎖,寫內存,然后釋放鎖。
所以,每個線程持有鎖的時間是很短很短的,單個內存分片的并發寫入經過壓測,達到每秒幾百甚至上千是沒問題的,因此線上系統我們是單機開辟幾十個到上百個內存緩沖分片的。
經過壓測,這足以支撐每秒數萬的并發寫入,如果將機器資源使用的極限,每秒十萬并發也是可以支持的。
六、緩沖區寫滿時的雙緩沖交換
那么當一塊緩沖區寫滿的時候,是不是就必須要交換兩塊緩沖區?接著需要有一個線程來將寫滿的緩沖區數據刷寫到磁盤文件中?
此時的偽代碼,大家考慮一下,是不是如下所示:

同樣,我們通過下面的圖來看看這個機制的實現:
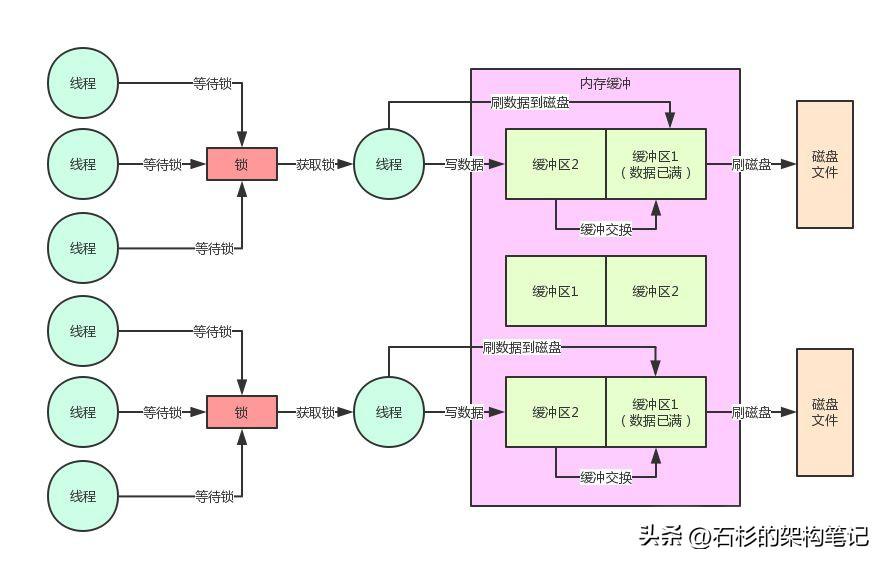
七、且慢!刷寫磁盤不是會導致鎖持有時間過長嗎?
且慢,各位同學,如果按照上面的偽代碼思路,一定會有一個問題:要是一個線程,他獲取了鎖,開始寫內存數據。
然后,發現內存滿了,接著直接在持有鎖的過程中,還去執行數據刷磁盤的操作,這樣是有問題的。
要知道,數據刷磁盤是很慢的,根據數據的多少,搞不好要幾十毫秒,甚至幾百毫秒。
這樣的話,豈不是一個線程會持有鎖長達幾十毫秒,甚至幾百毫秒?
這當然不行了,后面的線程此時都在等待獲取鎖然后寫緩沖區2,你怎么能一直占有鎖呢?
一旦你按照這個思路來寫代碼,必然導致高并發場景下,一個線程持有鎖上百毫秒。刷數據到磁盤的時候,后續上百個工作線程全部卡在等待鎖的那個環節,啥都干不了,嚴重的情況下,甚至又會導致系統整體呈現卡死的狀態。
八、內存 + 磁盤并行寫機制
所以此時正確的并發優化代碼,應該是發現內存緩沖區1滿了,然后就交換兩個緩沖區。
接著直接就釋放鎖,釋放鎖了之后再由這個線程將數據刷入磁盤中,刷磁盤的過程是不會占用鎖的,然后后續的線程都可以繼續獲取鎖,快速寫入內存,接著釋放鎖。
大家先看看下面的偽代碼的優化:
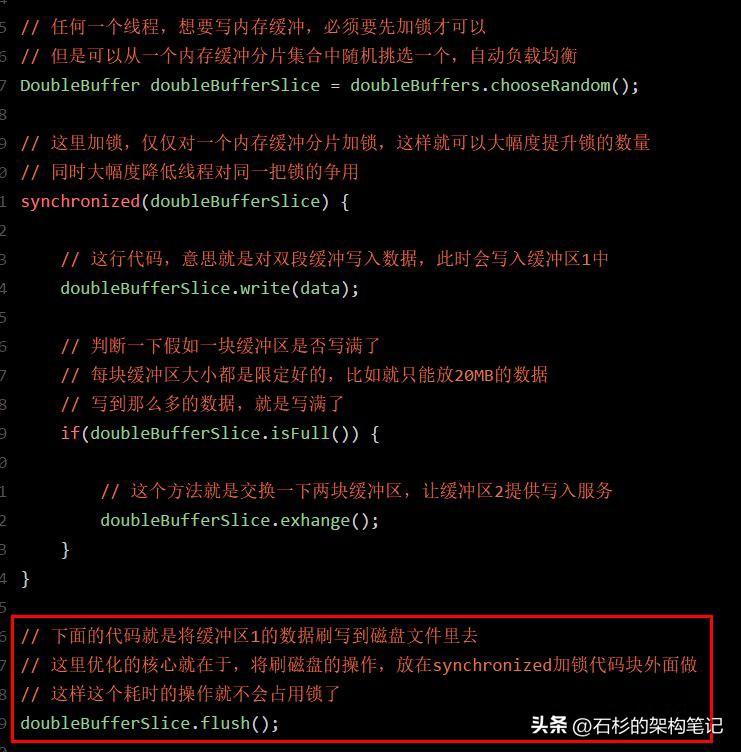
按照上面的偽代碼的優化,此時磁盤的刷寫和內存的寫入,完全可以并行同時進行。
因為這里核心的要點就在于大幅度降低了鎖占用的時間,這是java并發鎖優化的一個非常核心的思路。
大家看下面的圖,一起來感受一下:
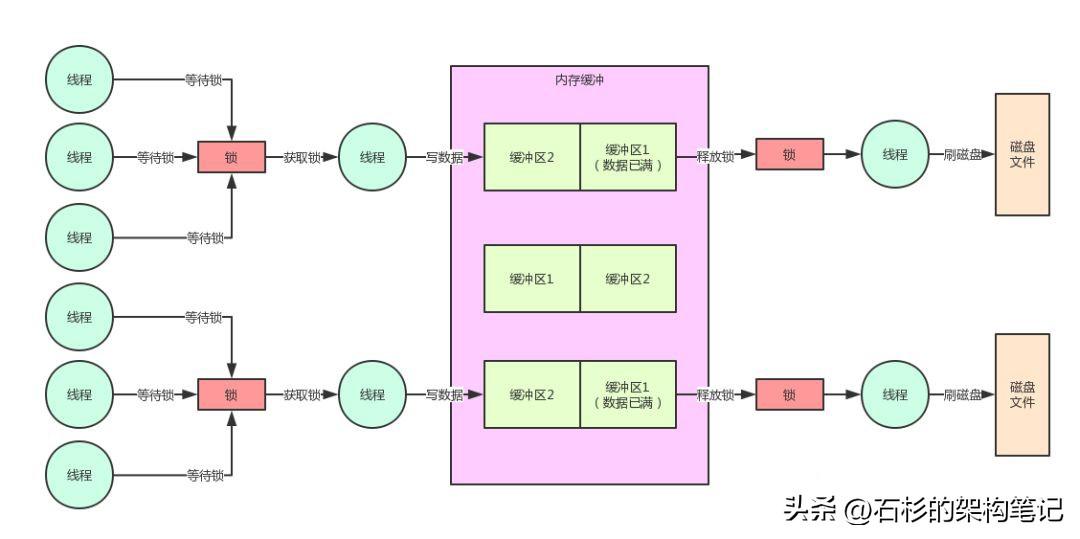
九、為什么必須要用雙緩沖機制?
其實看到這里,大家可能或多或少都體會到了一些雙緩沖機制的設計思想了,如果只用單塊內存緩沖的話,那么從里面讀數據刷入磁盤的過程,也需要占用鎖,而此時想要獲取鎖寫入內存緩沖的線程是獲取不到鎖的。
所以假只用單塊緩沖,必然導致讀內存數據,刷入磁盤的過程,長時間占用鎖。進而導致大量線程卡在鎖的獲取上,無法獲取到鎖,然后無法將數據寫入內存。這就是必須要在這里使用雙緩沖機制的核心原因。
十、總結
最后做一下總結,本文從筆者團隊自研的百萬并發量級中間件系統的內核機制出發,給大家展示了Java并發中加鎖的時候:
- 如何利用雙緩沖機制
- 內存緩沖分片機制
- 分段加鎖機制
- 磁盤 + 內存并行寫入機制
- 高并發場景下大幅度優化多線程對鎖的串行化爭用問題
- 長時間占用鎖的問題
其實在很多開源的優秀中間件系統中,都有很多類似的Java并發優化的機制,主要就是應對高并發的場景下大幅度的提升系統的并發性能以及吞吐量。大家如果感興趣,也可以去了解閱讀一下相關的底層源碼。