HashMap采用Node<K,V> 數組來存儲key-value對,每一個鍵值對組成了一個Node實體,Node類實際上是一個單向的鏈表結 構,它具有Next指針,可以連接下一個Node實體。
HashMap在JDK1.8之前和之后的區別
JDK1.8 之前,數組 + 鏈表 存儲結構
缺點就是哈希函數很難使元素百分百的均勻分布,這會產生一種極端的可能,就是大量的元素存在一個桶里
JDK1.8 之后:數組 + 鏈表 + 紅黑樹
- 添加元素時:鏈表長度 大于8的時候,轉換為紅黑樹
- 刪除元素、擴容時,同上,數量大于8時,也是采用紅黑樹形式存儲,但是在數量較少時,即數量小于6時,會將紅黑樹轉換回鏈表
- 遍歷、查找時,使用紅黑樹,他的時間復雜度O(log n),便于性能的提高。
數據結構
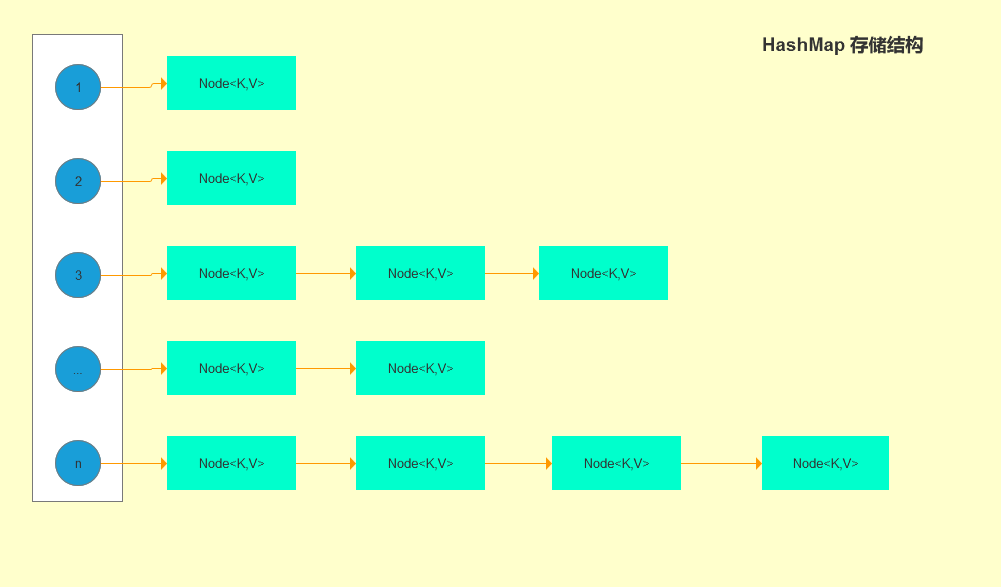
存儲結構
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey(){ return key; }
public final V getValue(){ return value; }
public final String toString(){ return key + "=" + value; }
public final int hashCode(){
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue){
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o){
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
// Node<K,V> 數組
transient Node<K,V>[] table;
//加載因子
final float loadFactor;
//默認加載因子 ,容量達到這個比例時自動擴容
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 數量大于8時,鏈表轉換為紅黑樹形式存儲
static final int TREEIFY_THRESHOLD = 8;
//即數量小于6時,會將紅黑樹轉換回鏈表,刪除元素時remove
static final int UNTREEIFY_THRESHOLD = 6;
//PUT 時每次都做hash
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//put 函數核心算法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 這里的n 表示數組的長度。
// hash
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 空實現
return oldValue;
}
}
++modCount; // modCount 是java集合中Fail-Fast的底層實現原理
if (++size > threshold) //擴容
resize();
afterNodeInsertion(evict);// 空實現
return null;
}
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
思考
java集合中的快速失敗:modCount
//?快速失敗是Java集合的一種錯誤檢測機制,當多個線程對集合進行結構上的改變的操作時,有可能會產生fail-fast。
//舉個例子:假設存在兩個線程(線程1、線程2),線程1通過Iterator在遍歷集合A中的元素,在某個時候線程2修改了集合A的結構(是結構上面的修改,而不是簡單的修改集合元素的內容),那么這個時候程序就可能會拋出
ConcurrentModificationException異常,從而產生fast-fail快速失敗。
HashMap中遍歷算法如下:
final class KeySet extends AbstractSet<K> {
public final int size(){ return size; }
public final void clear(){ HashMap.this.clear(); }
public final Iterator<K> iterator(){ return new KeyIterator(); }
public final boolean contains(Object o){ return containsKey(o); }
public final boolean remove(Object key){
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator(){
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action){
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
//拋出異常,Fail-Fast
throw new ConcurrentModificationException();
}
}
}優化hash 算法
JDK1.8中,是通過hashCode()的高16位異或低16位實現的:(h=k.hashCode())^(h>>>16),主要是從速度,功效和質量來考慮的,減少系統的開銷,也不會造成因為高位沒有參與下標的計算,從而引起的碰撞。
//擾動函數:促使元素位置分布均勻,減少碰撞幾率
static final int hash(Object key){
int h;
// 如果key == null 返回的值是 0
// 如果key !=null
// 首先計算 key 的 hashcode 值賦值給 h ,
// 然后與h 無符號右移16位后的二進制按位異或預算得到最后hash值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
hash具體實現過程如下圖所示:
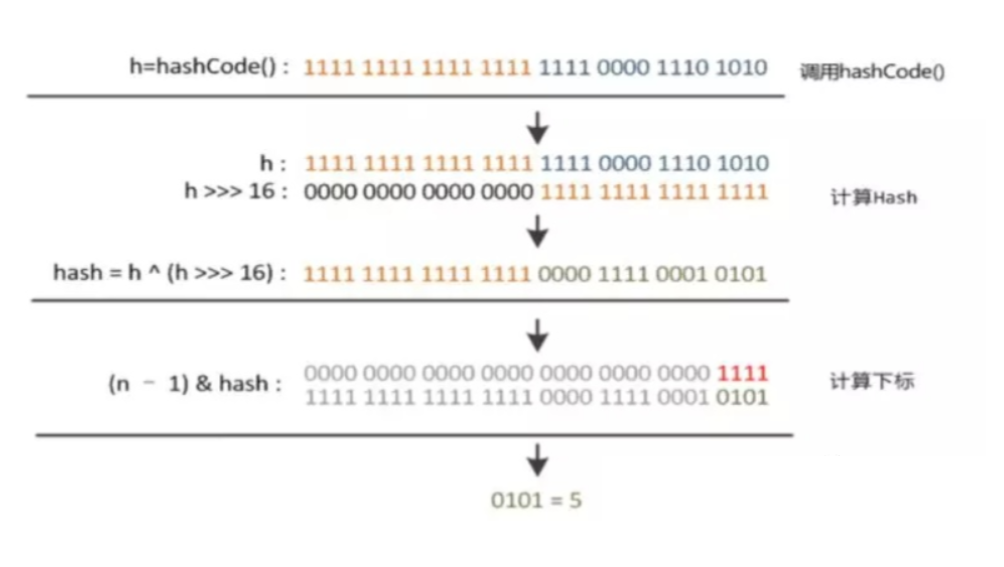
hash 計算過程與putval函數的應用
- key.hashCode();返回散列值也就是hashcode,假設隨便生成的一個值。
- n表示數組初始化的長度是16。
- &(按位與運算):運算規則:相同的二進制數位上,都是1的時候,結果為1,否則為零。
- ^(按位異或運算):運算規則:相同的二進制數位上,數字相同,結果為0,不同為1。
高16bit不變,低16bit和高16bit做了一個異或(得到的hashCode轉化為32位二進制,前16位和后16位低16bit和高16bit做了一個異或)
為什么這樣實現呢?
如果當n即數組長度很小,假設是16的話,那么n - 1即為1111 ,這樣的值和hashCode直接做按位與操作,實際上只使用了哈希值的后4位。如果當哈希值的高位變化很大,低位變化很小,這樣就很容易造成哈希沖突了,所以這里把高低位都利用起來,從而解決了這個問題。降低了Hash沖突的概率
為什么要用異或運算符
保證了對象的hashCode的32位值只要有一位發生改變,整個hash()返回值就會改變。盡可能的減少碰撞。
工作原理
存儲對象時,將K/V鍵值傳給put()方法:
- 調用hash(K)方法計算K的hash值,然后結合數組長度,計算得數組下標;
- 調整數組大小(當容器中的元素個數大于capacity*loadfactor時,容器會進行擴容resize為2n);
- hash碰撞
i.如果K的hash值在HashMap中不存在,則執行插入,若存在,則發生碰撞;
ii.如果K的hash值在HashMap中存在,且它們兩者equals返回true,則更新鍵值對;
iii.如果K的hash值在HashMap中存在,且它們兩者equals返回false,則插入鏈表的尾部(尾插法)或者紅黑樹中(樹的添加方式)。(JDK1.7之前使用頭插法、JDK1.8使用尾插法)
//get 實現
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
問題思考?
Q:默認初始化大小是多少?為啥是這么多?為啥大小都是2的冪?
A:hash運算的過程其實就是對目標元素的Key進行hashcode,再對Map的容量進行取模,而JDK 的工程師為了提升取模的效率,使用位運算代替了取模運算,這就要求Map的容量一定得是2的冪。HashMap的容量為什么是2的n次冪,和這個putval方法中(n - 1) & hash的計算方法有著千絲萬縷的關系,符號&是按位與的計算,這是位運算,計算機能直接運算,特別高效,按位與&的計算方法是,只有當對應位置的數據都為1時,運算結果也為1,當HashMap的容量是2的n次冪時,(n-1)的2進制也就是1111111***111這樣形式的,這樣與添加元素的hash值進行位運算時,能夠(充分的散列),使得添加的元素均勻分布在HashMap的每個位置上,減少hash碰撞。
Q:HashMap如何有效減少碰撞?
A: 擾動函數:促使元素位置分布均勻,減少碰撞幾率 、使用final對象,并采用合適的equals()和hashCode()方法