













Diffusion 和Stable Diffusion的數學和工作原理詳細解釋
擴散模型的興起可以被視為人工智能生成藝術領域最近取得突破的主要因素。而穩定擴散模型的發展使得我們可以通過一個文本提示輕松地創建美妙的藝術插圖。所以在本文中,我將解釋它們是如何工作的。

擴散模型 Diffusion
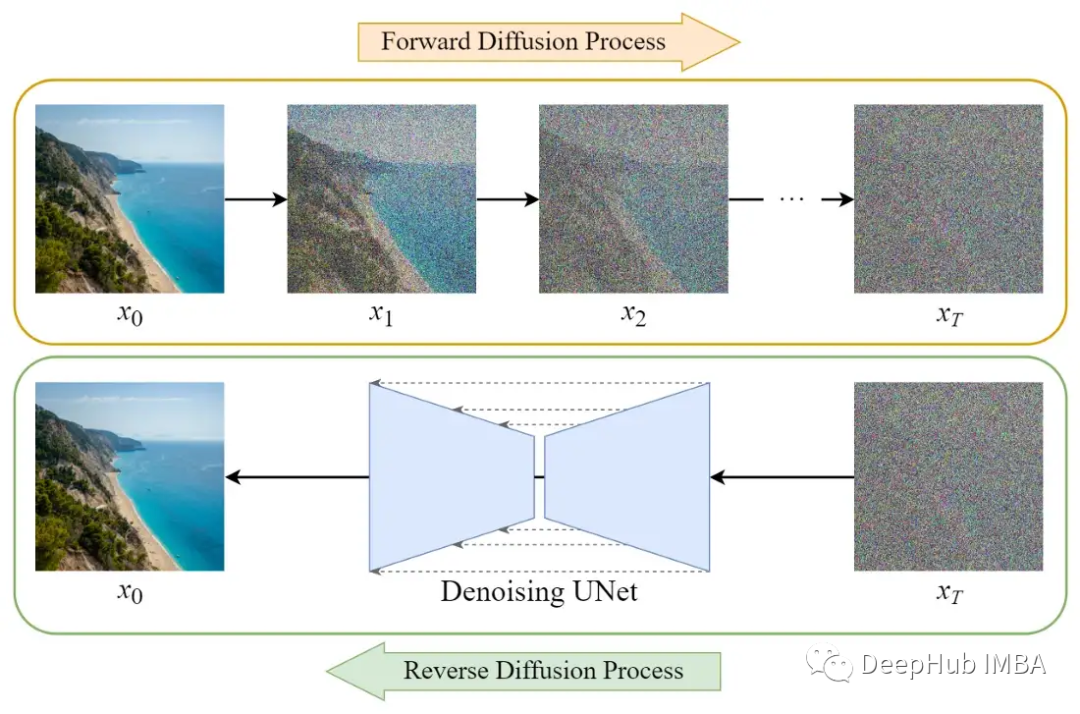
擴散模型的訓練可以分為兩部分:
- 正向擴散→在圖像中添加噪聲。
- 反向擴散過程→去除圖像中的噪聲。
正向擴散過程

正向擴散過程逐步對輸入圖像 x? 加入高斯噪聲,一共有 T 步。該過程將產生一系列噪聲圖像樣本 x?, …, x_T。
當 T → ∞ 時,最終的結果將變成一張完包含噪聲的圖像,就像從各向同性高斯分布中采樣一樣。
但是我們可以使用一個封閉形式的公式在特定的時間步長 t 直接對有噪聲的圖像進行采樣,而不是設計一種算法來迭代地向圖像添加噪聲。
封閉公式
封閉形式的抽樣公式可以通過重新參數化技巧得到。
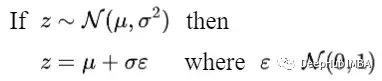
通過這個技巧,我們可以將采樣圖像x?表示為:
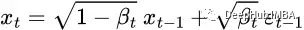
然后我們可以遞歸展開它,最終得到閉式公式:

這里的ε 是 i.i.d. (獨立同分布)標準正態隨機變量。使用不同的符號和下標區分它們很重要,因為它們是獨立的并且它們的值在采樣后可能不同。
但是,上面公式是如何從第4行跳到第5行呢?
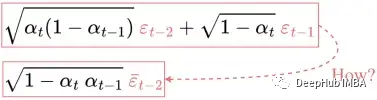
有些人覺得這一步很難理解。下面我詳細介紹如何工作的:

讓我們用 X 和 Y 來表示這兩項。它們可以被視為來自兩個不同正態分布的樣本。即 X ~ N(0, α?(1-α???)I) 和 Y ~ N(0, (1-α?)I)。
兩個正態分布(獨立)隨機變量的總和也是正態分布的。即如果 Z = X + Y,則 Z ~ N(0, σ2?+σ2?)。因此我們可以將它們合并在一起并以重新以參數化的形式表示合并后的正態分布。
重復這些步驟將為得到只與輸入圖像 x? 相關的公式:
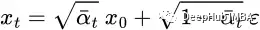
現在我們可以使用這個公式在任何時間步驟直接對x?進行采樣,這使得向前的過程更快。
反向擴散過程
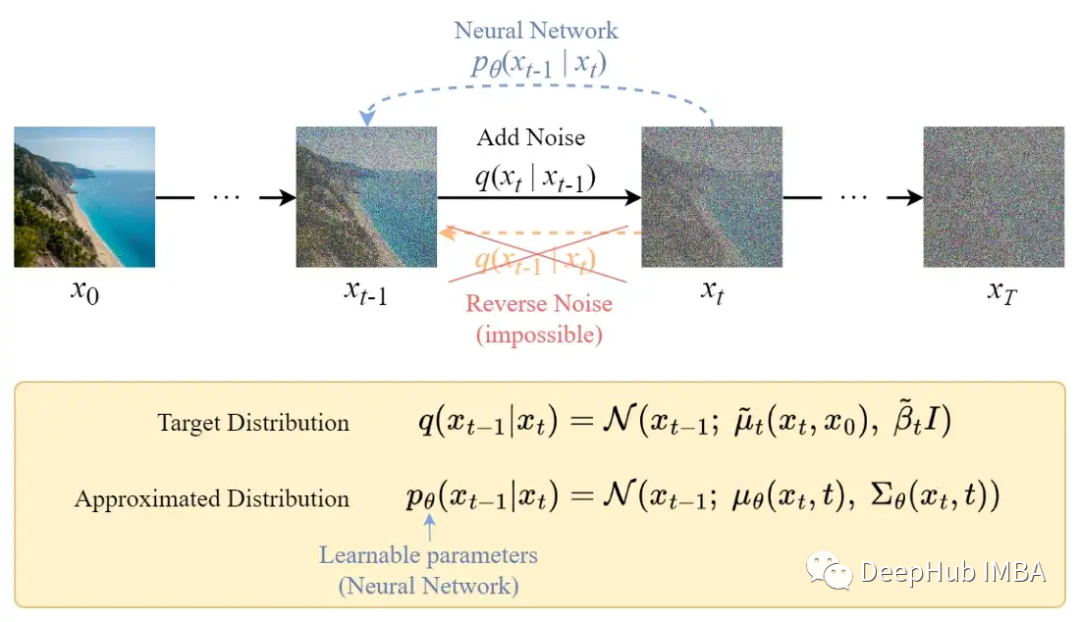
與正向過程不同,不能使用q(x???|x?)來反轉噪聲,因為它是難以處理的(無法計算)。所以我們需要訓練神經網絡pθ(x???|x?)來近似q(x???|x?)。近似pθ(x???|x?)服從正態分布,其均值和方差設置如下:
損失函數
損失定義為負對數似然:
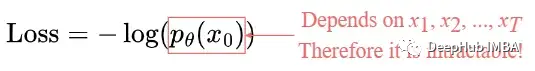
這個設置與VAE中的設置非常相似。我們可以優化變分的下界,而不是優化損失函數本身。
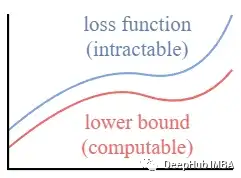
通過優化一個可計算的下界,我們可以間接優化不可處理的損失函數。

通過展開,我們發現它可以用以下三項表示:
1、L_T:常數項
由于 q 沒有可學習的參數,p 只是一個高斯噪聲概率,因此這一項在訓練期間將是一個常數,因此可以忽略。
2、L???:逐步去噪項
這一項是比較目標去噪步驟 q 和近似去噪步驟 pθ。通過以 x? 為條件,q(x???|x?, x?) 變得易于處理。

經過一系列推導,上圖為q(x???|x?,x?)的平均值μ′?。為了近似目標去噪步驟q,我們只需要使用神經網絡近似其均值。所以我們將近似均值 μθ 設置為與目標均值 μ?? 相同的形式(使用可學習的神經網絡 εθ):

目標均值和近似值之間的比較可以使用均方誤差(MSE)進行:

經過實驗,通過忽略加權項并簡單地將目標噪聲和預測噪聲與 MSE 進行比較,可以獲得更好的結果。所以為了逼近所需的去噪步驟 q,我們只需要使用神經網絡 εθ 來逼近噪聲 ε?。
3、L?:重構項
這是最后一步去噪的重建損失,在訓練過程中可以忽略,因為:
- 可以使用 L??? 中的相同神經網絡對其進行近似。
- 忽略它會使樣本質量更好,并更易于實施。
所以最終簡化的訓練目標如下:
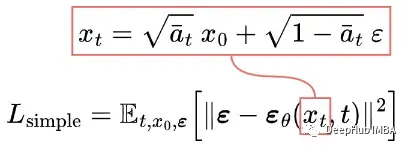
我們發現在真實變分界上訓練我們的模型比在簡化目標上訓練產生更好的碼長,正如預期的那樣,但后者產生了最好的樣本質量。[2]
通過測試在變分邊界上訓練模型比在簡化目標上訓練會減少代碼的長度,但后者產生最好的樣本質量。[2]
U-Net模型
在每一個訓練輪次
- 每個訓練樣本(圖像)隨機選擇一個時間步長t。
- 對每個圖像應用高斯噪聲(對應于t)。
- 將時間步長轉換為嵌入(向量)。
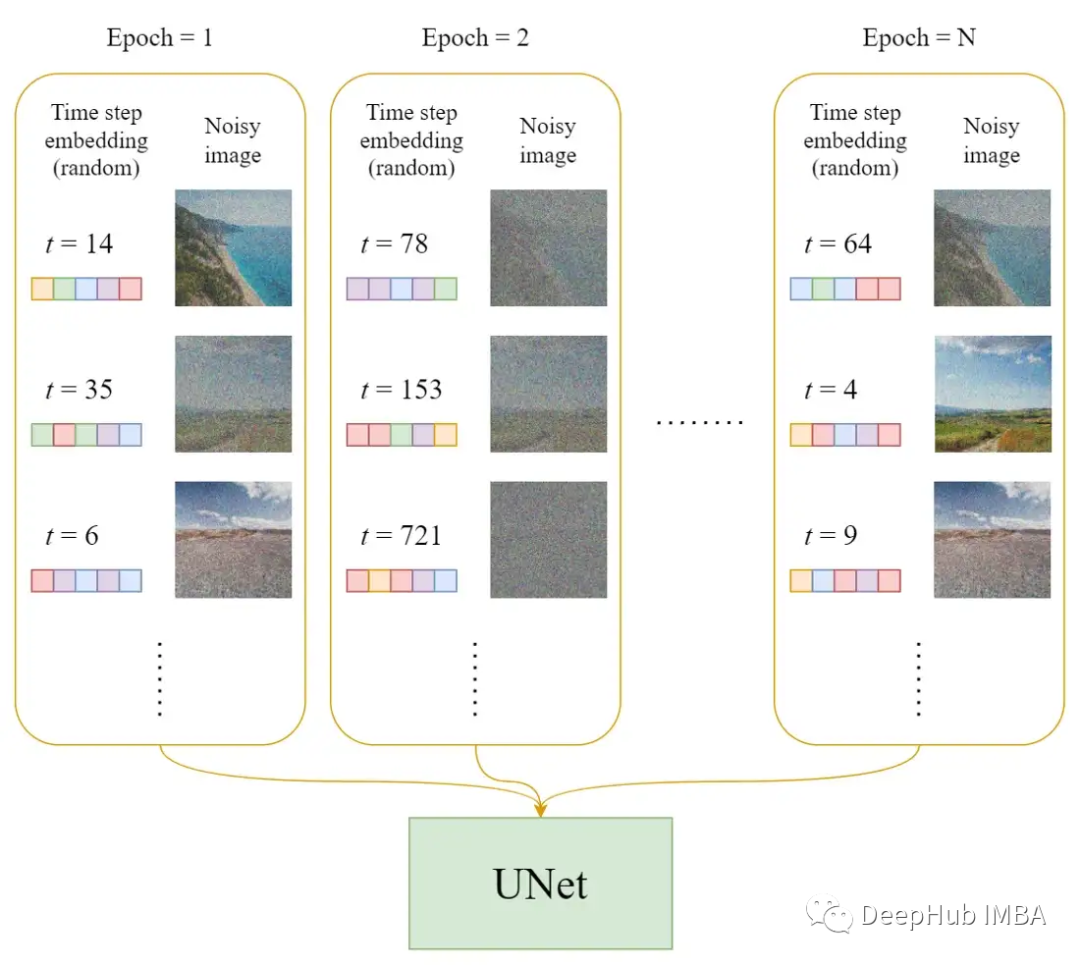
訓練過程的偽代碼

官方的訓練算法如上所示,下圖是訓練步驟如何工作的說明:

反向擴散

我們可以使用上述算法從噪聲中生成圖像。下面的圖表說明了這一點:
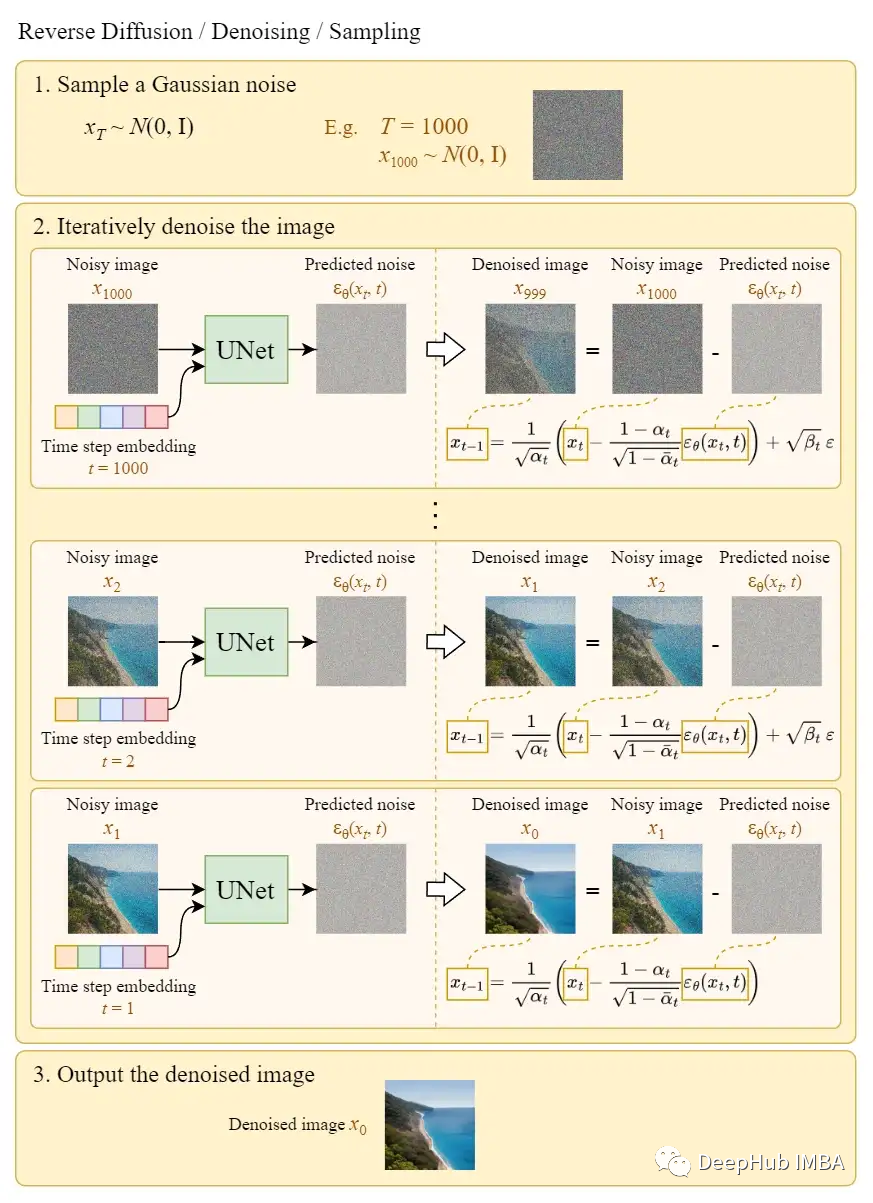
在最后一步中,只是輸出學習的平均值μθ(x?,1),而沒有添加噪聲。反向擴散就是我們說的采樣過程,也就是從高斯噪聲中繪制圖像的過程。
擴散模型的速度問題
擴散(采樣)過程會迭代地向U-Net提供完整尺寸的圖像獲得最終結果。這使得純擴散模型在總擴散步數T和圖像大小較大時極其緩慢。
穩定擴散就是為了解決這一問題而設計的。
穩定擴散 Stable Diffusion
穩定擴散模型的原名是潛擴散模型(Latent Diffusion Model, LDM)。正如它的名字所指出的那樣,擴散過程發生在潛在空間中。這就是為什么它比純擴散模型更快。
潛在空間

首先訓練一個自編碼器,學習將圖像數據壓縮為低維表示。
通過使用訓練過的編碼器E,可以將全尺寸圖像編碼為低維潛在數據(壓縮數據)。然后通過使用經過訓練的解碼器D,將潛在數據解碼回圖像。
潛在空間的擴散
將圖像編碼后,在潛在空間中進行正向擴散和反向擴散過程。
- 正向擴散過程→向潛在數據中添加噪聲
- 反向擴散過程→從潛在數據中去除噪聲
條件作用/調節

穩定擴散模型的真正強大之處在于它可以從文本提示生成圖像。這是通過修改內部擴散模型來接受條件輸入來完成的。

通過使用交叉注意機制增強其去噪 U-Net,將內部擴散模型轉變為條件圖像生成器。
上圖中的開關用于在不同類型的調節輸入之間進行控制:
- 對于文本輸入,首先使用語言模型 ??θ(例如 BERT、CLIP)將它們轉換為嵌入(向量),然后通過(多頭)Attention(Q, K, V) 映射到 U-Net 層。
- 對于其他空間對齊的輸入(例如語義映射、圖像、修復),可以使用連接來完成調節。
訓練

訓練目標(損失函數)與純擴散模型中的訓練目標非常相似。唯一的變化是:
- 輸入潛在數據z?而不是圖像x?。
- U-Net增加條件輸入??θ(y)。
采樣

由于潛在數據的大小比原始圖像小得多,所以去噪過程會快得多。
架構的比較
比較純擴散模型和穩定擴散模型(潛在擴散模型)的整體架構。
Diffusion Model

Stable Diffusion (Latent Diffusion Model)

快速總結一下:
- 擴散模型分為正向擴散和反向擴散兩部分。
- 正擴散可以用封閉形式的公式計算。
- 反向擴散可以用訓練好的神經網絡來完成。
- 為了近似所需的去噪步驟q,我們只需要使用神經網絡εθ近似噪聲ε?。
- 在簡化損失函數上進行訓練可以獲得更好的樣本質量。
- 穩定擴散(潛擴散模型)是在潛空間中進行擴散過程,因此比純擴散模型快得多。
- 純擴散模型被修改為接受條件輸入,如文本、圖像、語義等。






























