













關于圖形數據庫的可擴展性,您應該了解什么?

在許多企業場景中,擁有一個分布式和可擴展的圖數據庫系統是非常受歡迎的。一方面,這很大程度上受到大數據處理框架的持續興起和流行的影響,包括但不限于Hadoop、Spark和NoSQL數據庫;另一方面,隨著越來越多的數據以相關和多維的方式進行分析,將所有數據打包到一個實例的一個圖中變得越來越困難,擁有一個真正分布式和水平可擴展的圖數據庫是必須的 -有。
不要被誤導
設計和實現可擴展的圖形數據庫系統從來都不是一項簡單的任務。有無數的企業,尤其是互聯網巨頭,已經探索了使圖形數據處理可擴展的方法。盡管如此,大多數解決方案要么僅限于其私有和狹窄的用例,要么通過硬件加速以垂直方式提供可擴展性,這再次證明大型機架構計算機在 90 年代被 PC 架構計算機確定性取代的原因主要是與水平可擴展性相比,垂直可擴展性通常被認為是劣質的且可擴展性較差。分布式數據庫通過添加廉價PC來實現可擴展性(存儲和計算),并試圖按需一勞永逸地存儲數據,這已成為一種常態。但是,如果不大量犧牲圖形系統上的查詢性能,這樣做就無法實現同等的可擴展性。
為什么圖形(數據庫)系統的可擴展性如此難以(獲得)?主要原因是圖系統是高維的;這與傳統的 SQL 或 NoSQL 系統形成鮮明對比,傳統的 SQL 或 NoSQL 系統主要以表為中心,本質上是列式和行式存儲(以及更簡單的 KV 存儲),并且已被證明通過水平可擴展設計相對容易實現。
一個看似簡單直觀的圖查詢可能會導致大量圖數據的深度遍歷和滲透,否則往往會導致典型的BSP(Bulky Synchronous Processing)系統在其眾多分布式實例之間進行大量交換,從而導致重大(和難以忍受的)延遲。
另一方面,大多數現有的圖形系統更愿意在提供可擴展性(存儲)的同時犧牲性能(計算)。這將使此類系統在處理許多現實世界的業務場景時變得不切實際和無用。描述此類系統的更準確的方法是,它們可能可以存儲大量數據(跨越許多實例),但不能提供足夠的圖形計算能力——換句話說,這些系統在被超出范圍的查詢時無法返回結果元數據(節點和邊)。
本文旨在揭開圖形數據庫的可擴展性挑戰的神秘面紗,同時重點關注性能問題。簡而言之,您將對任何圖形數據庫系統的可伸縮性和性能有更好、更通暢的理解,并在選擇您未來的圖形系統時更有信心。
市場上有很多關于圖數據庫可擴展性的聲音;一些供應商聲稱他們具有無限的可擴展性,而其他供應商則聲稱他們是第一個企業級可擴展圖形數據庫。你應該相信或跟隨誰?唯一的出路是讓自己對圖形數據庫系統的可擴展性有足夠的了解,這樣你就可以自己驗證它,而不必被所有那些營銷炒作所誤導。
誠然,圖數據庫可擴展性有很多術語;有些可能非常令人困惑,僅舉幾例:HA、RAFT 或分布式共識、HTAP、聯合、結構、分片、分區等。
你真的能分辨出所有這些術語的區別嗎?我們會解開它們。
3 分布式圖系統架構設計流派
首先,確保您了解從獨立(圖形數據庫)實例到完全分布式且可水平擴展的圖形數據庫實例集群的演進路徑。
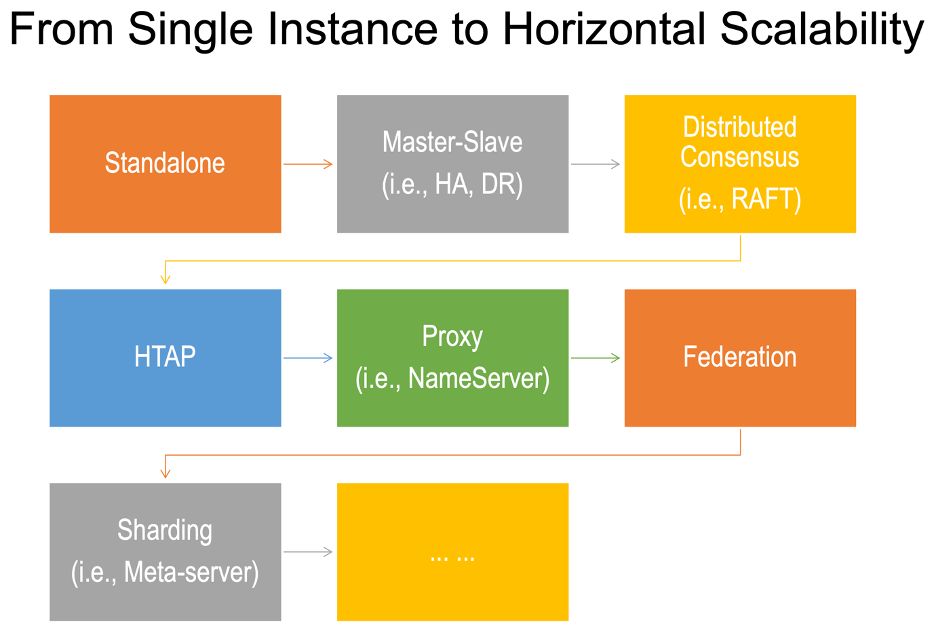
圖 1:分布式(圖)系統的演變。
分布式系統可能有多種形式,這種豐富的多樣化可能會導致混亂。一些供應商誤導性地(諷刺地)聲稱他們的數據庫系統均勻分布在單個基礎硬件實例上,而其他供應商則聲稱他們的分片圖形數據庫集群可以處理數以萬計的圖形數據集,而實際上,集群不能甚至可以處理反復遍歷整個數據集的典型多跳圖查詢或圖算法。
簡而言之,只有三種可擴展圖形數據庫架構設計流派,如表所示:
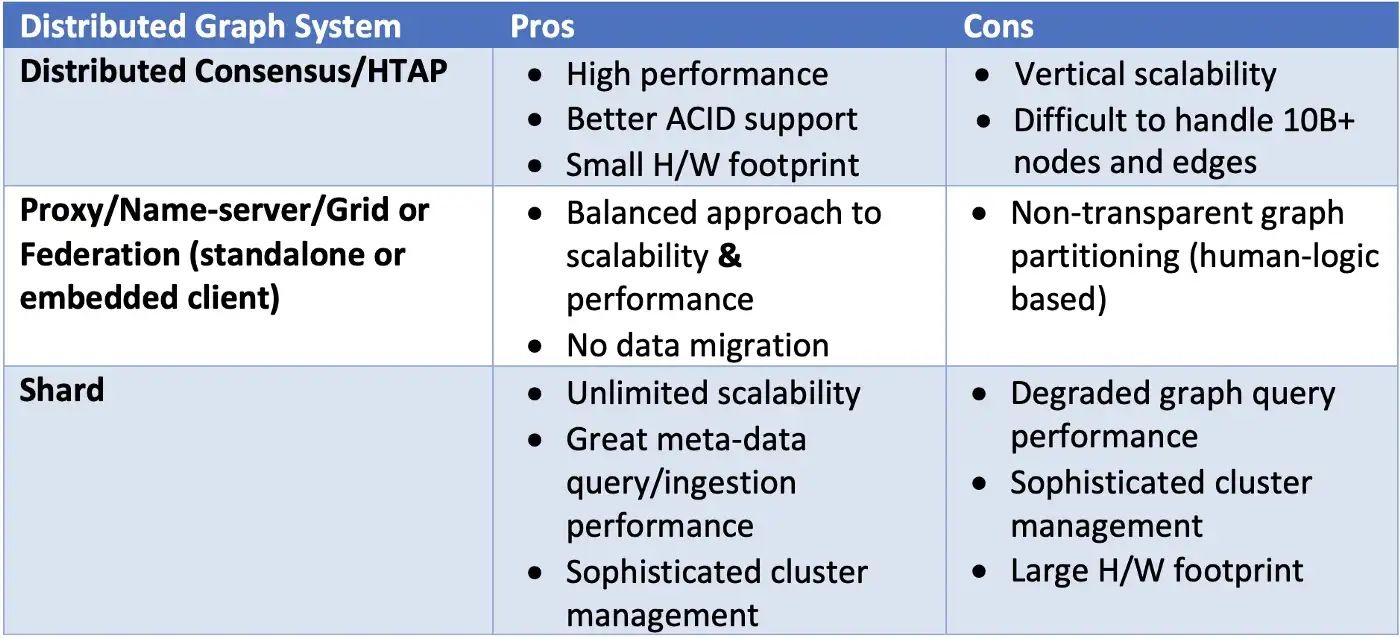
表 1:三種分布式圖譜系統流派的比較。
多環芳烴架構
第一種學派被認為是主從模型的自然擴展,我們稱之為分布式共識集群,通常三個實例組成一個圖數據庫集群。在同一集群中擁有三個或奇數個實例的唯一原因是更容易投票選出集群的領導者。
如您所見,這種集群設計模型可能有很多變化;例如,Neo4j 的企業版 v4.x 支持原始的 RAFT 協議,只有一個實例處理工作負載,而其他兩個實例被動地從主實例同步數據——當然,這是讓 RAFT 協議工作的一種天真方式. 一種更實用的處理工作負載的方法是擴充 RAFT 協議以允許所有實例以負載均衡的方式工作。例如,讓領導實例處理讀寫操作,而其他實例至少可以處理讀取類型的查詢,以確保整個集群的數據一致性。
在這種分布式圖形系統設計中,一種更復雜的方法是允許 HTAP(混合事務和分析處理),這意味著將在集群實例之間分配不同的角色;領導者將處理 TP 操作,而追隨者將處理 AP 操作,這些操作可以進一步細分為圖算法等角色。
利用分布式共識的圖系統的優缺點包括:
- 硬件占用空間小(更便宜)。
- 數據一致性好(更容易實現)。
- 復雜和深度查詢的最佳性能。
- 可擴展性有限(依賴垂直可擴展性)。
- 難以處理超過一百億個節點和邊的單個圖。
下面展示的是來自 Ultipa 的新型 HTAP 架構,其主要功能如下:
- 高密度并行圖計算。
- 多層存儲加速(存儲與計算非常接近)。
- 動態修剪(通過動態修剪機制加速圖形遍歷)。
- 超線性性能(即當CPU核數等計算資源增加一倍時,性能提升可達一倍以上)。
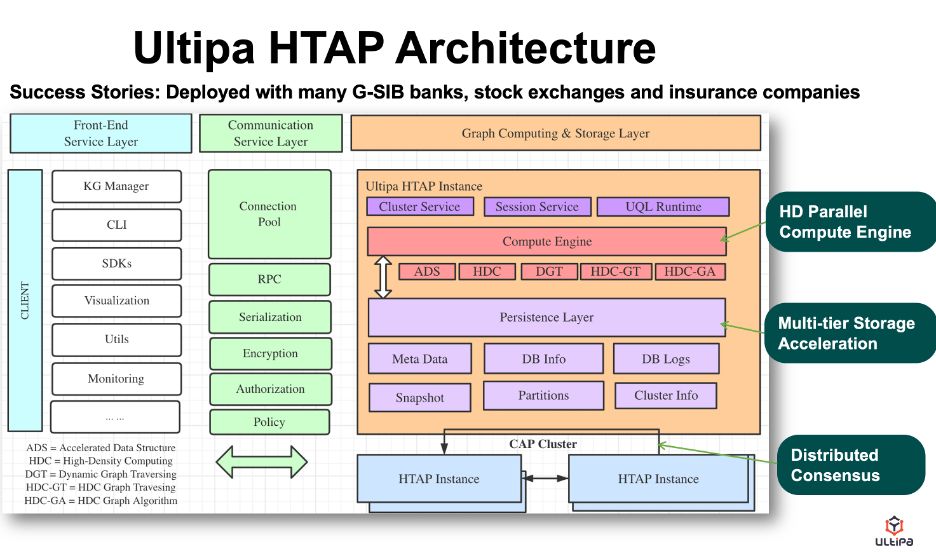
圖 2:Ultipa Graph 的 HTAP 架構圖。
請注意,這種 HTAP 架構在小于 10B 節點 + 邊的圖形數據大小上運行良好。因為很多計算加速都是通過內存計算來完成的,如果每十億個節點和邊消耗大約100GB的DRAM,那么單個實例可能需要1TB的DRAM來處理一個百億個節點和邊的圖。
這種設計的好處是該體系結構可以滿足大多數真實場景的要求。即使對于 G-SIB(全球系統重要性銀行),典型的欺詐檢測、資產負債管理或流動性風險管理用例也會消耗大約 10 億個數據;一個合理大小的虛擬機或 PC 服務器可以很好地容納這樣的數據規模,并且可以通過 HTAP 設置非常高效。
這種設計的缺點是缺乏水平(和無限)的可擴展性。而這一挑戰在分布式圖形系統設計的第二和第三流派中得到解決(見表 1)。
下面兩張圖展示了 HTAP 架構的性能優勢。有兩點需要注意:
- 線性性能增益:一個 3 實例 Ultipa HTAP 集群的吞吐量可以達到獨立實例的 ~300%。增益主要反映在 AP 類型的操作中,例如元數據查詢、路徑/k-hop 查詢和圖形算法,但不反映在 TP 操作中,例如元數據的插入或刪除,因為這些操作主要是在與輔助實例同步之前的主實例。
- 更好的性能 = 更低的延遲和更高的吞吐量(TPS 或 QPS)。
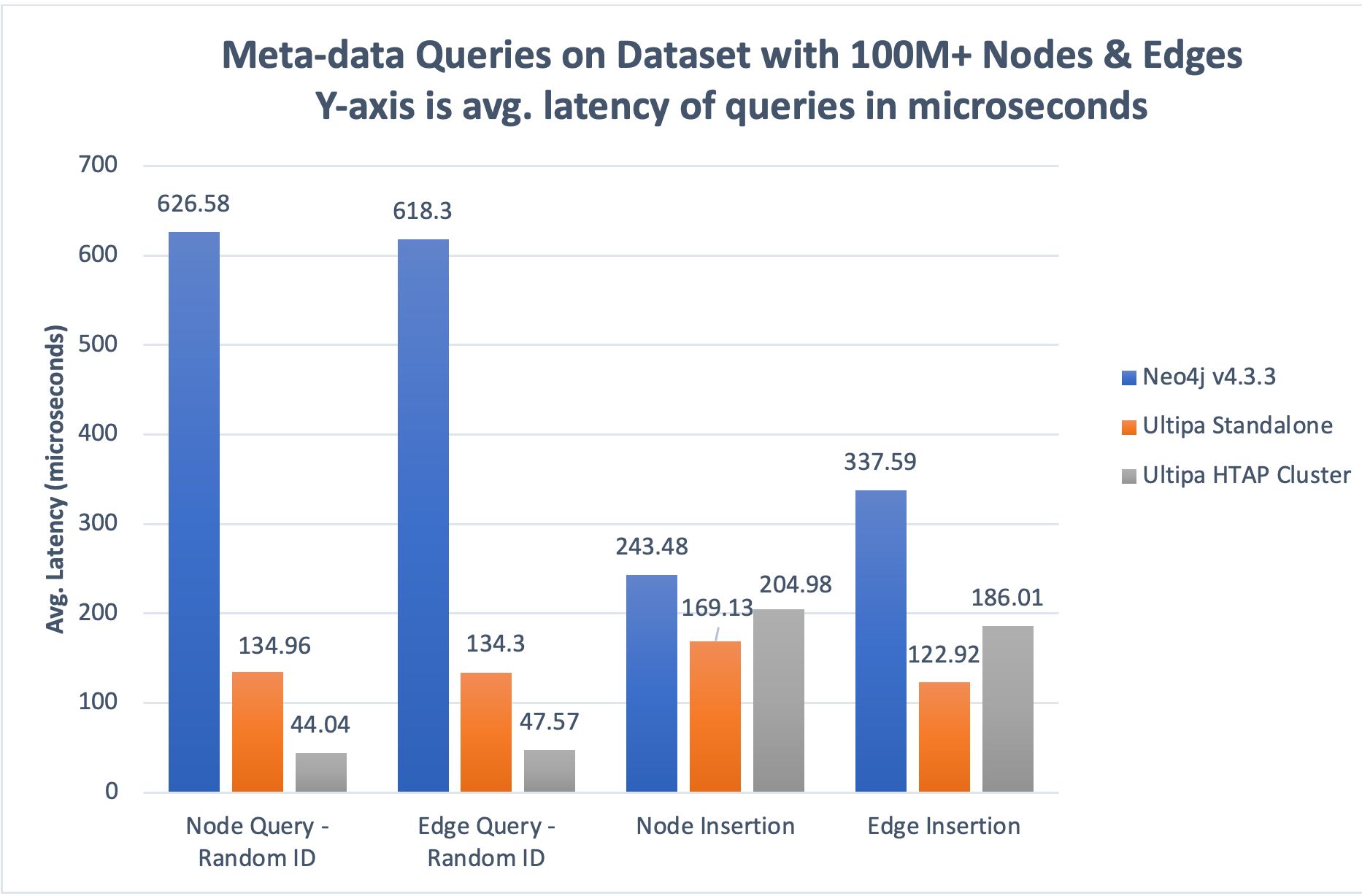
圖 3:HTAP 架構的性能優勢。
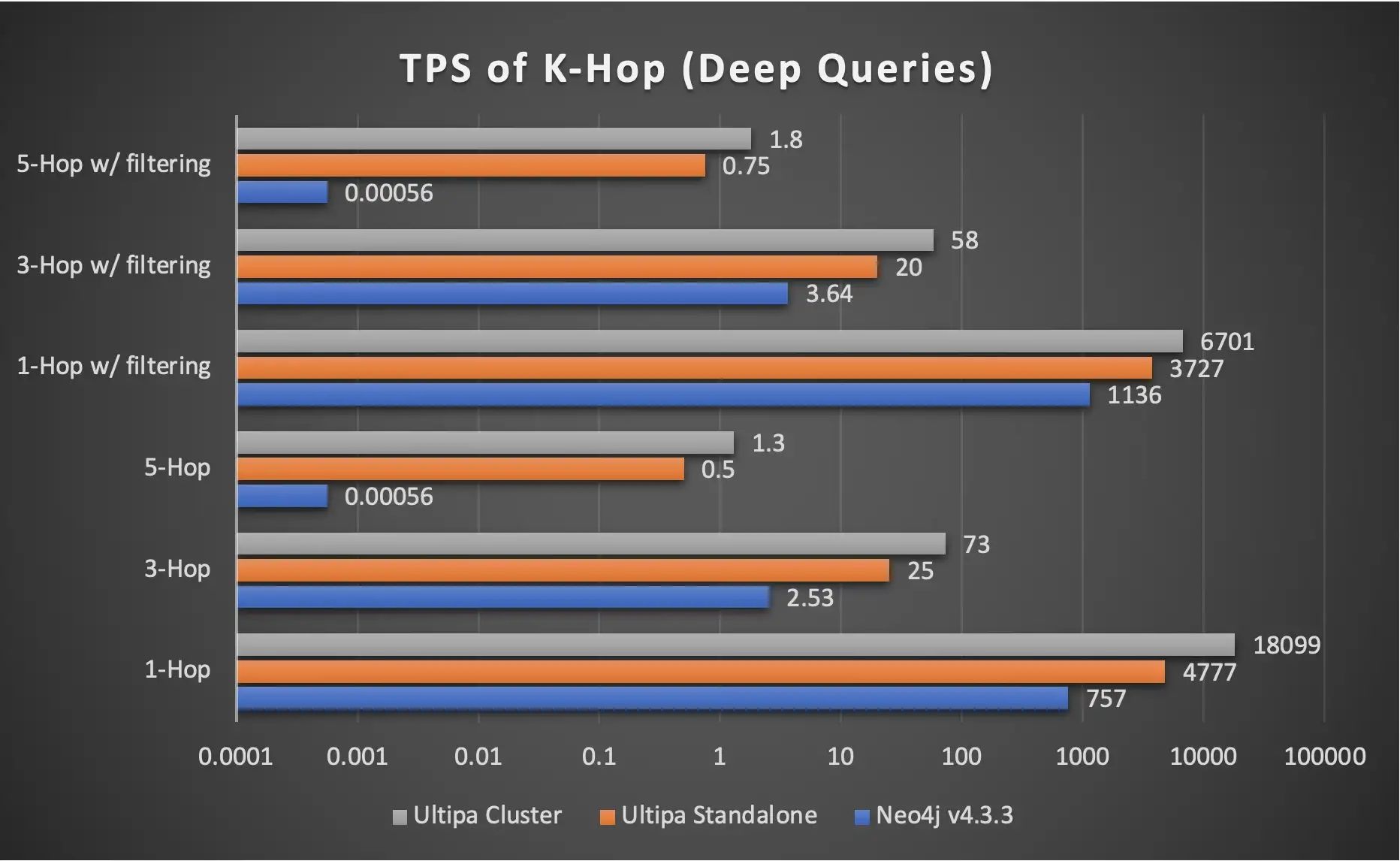
圖 4:Ultipa 和 Neo4j 的 TPS 比較。
網格架構
在第二流派中,這種類型的分布式和可擴展圖系統設計也有相當多的命名變體(有些是誤導性的)。僅舉幾例:代理、名稱服務器、MapReduce、網格或聯合。忽略命名差異;中學和第一學校之間的主要區別在于名稱服務器充當客戶端和服務器端之間的代理。
作為代理服務器時,名稱服務器僅用于路由查詢和轉發數據。最重要的是,除了運行圖算法外,名稱服務器還具有從基礎實例聚合數據的能力。此外,在聯合模式下,可以針對多個基礎實例運行查詢(查詢聯合);然而,對于圖算法,聯邦的性能很差(由于數據遷移,就像 map-reduce 的工作原理一樣)。請注意,第二所學校與第三所學校在一個方面有所不同:數據在功能上進行了分區,但在該設計學校中并未分片。
對于圖數據集,功能分區是圖數據的邏輯劃分,例如按時間序列(水平分區)或按業務邏輯(垂直分區)。
另一方面,分片旨在實現自動化,業務邏輯或時間序列無知。分片通常考慮基于網絡存儲的數據分區位置;它利用各種冗余數據和特殊的數據分布來提高性能,例如一方面對節點和邊緣進行切割,另一方面復制部分切割數據以獲得更好的訪問性能。事實上,sharding 非常復雜且難以理解。根據定義,自動分片旨在以最小到零的人為干預和業務邏輯無知來處理不可預測的數據分布,但是當面臨與特定數據分布糾纏在一起的業務挑戰時,這種無知可能會帶來很大問題。
讓我們用具體的例子來說明這一點。假設您有 12 個月的信用卡交易數據。在人工分區模式下,您自然地將數據網絡劃分為 12 個圖形集,一個圖形集在每個包含三個實例的集群上包含一個月的事務,并且此邏輯由數據庫管理員預定義。它強調通過數據庫的元數據來劃分數據,而忽略了不同圖集之間的連接性。它對業務友好,不會減慢數據遷移速度,并且具有良好的查詢性能。另一方面,在自動分片模式下,由圖系統決定如何劃分(切割)數據集,分片邏輯對數據庫管理員是透明的。但是開發人員很難立即弄清楚數據存儲在哪里,
僅僅因為自動分片涉及較少的人為干預就聲稱自動分片比功能分區更智能是不明智的。
你覺得這里有什么不對嗎?隨著人工智能的不斷興起,這正是我們正在經歷的,我們允許機器代表我們做出決定,而且它并不總是智能的!(在另一篇文章中,我們將討論從人工智能到增強智能的全球轉變的主題,以及為什么圖形技術在戰略上定位于推動這種轉變。)
在 Graph-5 中,展示了屬于第二設計學院的網格架構;在 Graph-2 的 HTAP 架構之上添加的兩個額外組件是名稱服務器和元服務器。基本上所有的查詢都是通過名稱服務器代理的,名稱服務器與元服務器共同工作以確保網格的彈性;服務器集群實例在很大程度上與原始 HTAP 實例相同(如圖 2 所示)。
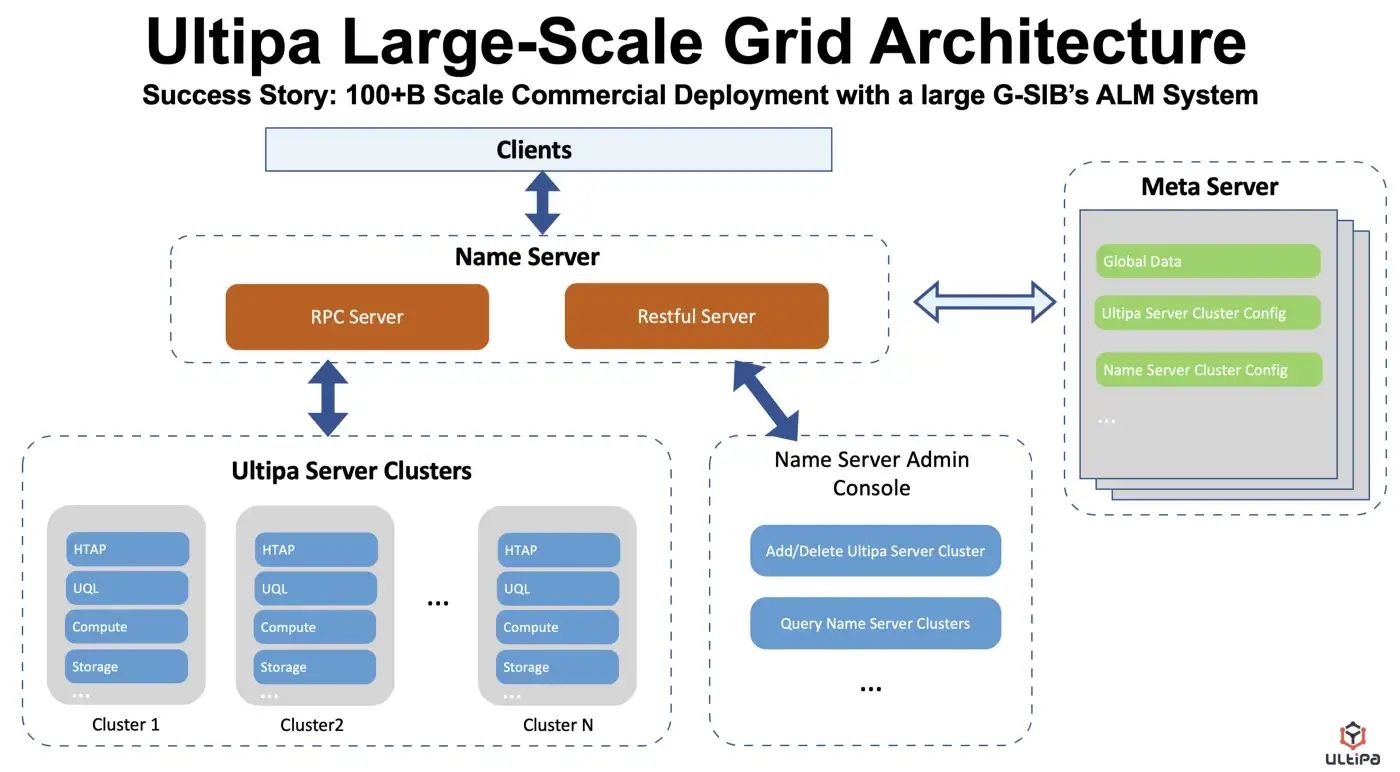
圖 5:帶有名稱服務器和元服務器的網格架構。
參考表1,網格架構設計的優缺點可以歸納如下:
- 保留了典型 HTAP 架構的所有優點/優點。
- 可擴展性是在性能不變的情況下實現的(與 HTAP 架構相比)。
- 可擴展性受限——服務器集群在 DBA/管理員干預下進行分區。
- 引入名稱服務器/元服務器,使集群管理更加復雜。
- 名稱服務器在確保業務邏輯在服務器集群上分布式執行并在返回給客戶端之前在其上具有簡單的合并和聚合功能方面至關重要且復雜。
- 可能需要業務邏輯配合分區和查詢。
分片架構
現在,我們可以迎來具有無限可擴展性的分布式圖系統設計的第三個流派——分片(shard)(見表1)。
從表面上看,分片系統的水平可擴展性也像第二種設計一樣利用名稱服務器和元服務器,但主要區別在于:
- 分片服務器是真正共享的。
- 名稱服務器不直接了解業務邏輯(如第二所學校)。間接地,它可以通過自動統計來粗略判斷業務邏輯的類別。這個解耦很重要,在二流不可能優雅的實現。
分片架構有一些變化;有的叫fabric(其實更像中學的grid architecture),有的叫map-reduce,但還是要深入核心的數據處理邏輯來揭開謎底。
分片架構中只有兩類數據處理邏輯:
- 類型 1:數據主要在名稱服務器(或代理服務器)上處理
- 類型 2:數據在分片或分區服務器以及名稱服務器上處理。
類型 1 是典型的,正如您在大多數 map-reduce 系統(例如 Hadoop)中看到的那樣;數據分散在高度分布式的實例中。然而,在它們在那里被處理之前,它們需要被提升并轉移到名稱服務器。
類型 2 的不同之處在于,分片服務器有能力在數據被聚合并在名稱服務器上進行二次處理之前在本地處理數據(這稱為:在存儲附近計算或與存儲或以數據為中心的計算并置)。
正如您所想象的那樣,類型1更容易實現,因為它是許多大數據框架的成熟設計方案;但是,類型 2 通過更復雜的集群設計和查詢優化提供更好的性能。type-2 中的分片服務器提供計算能力,而 type-1 沒有這種能力。
下圖顯示了 type-2 分片設計:
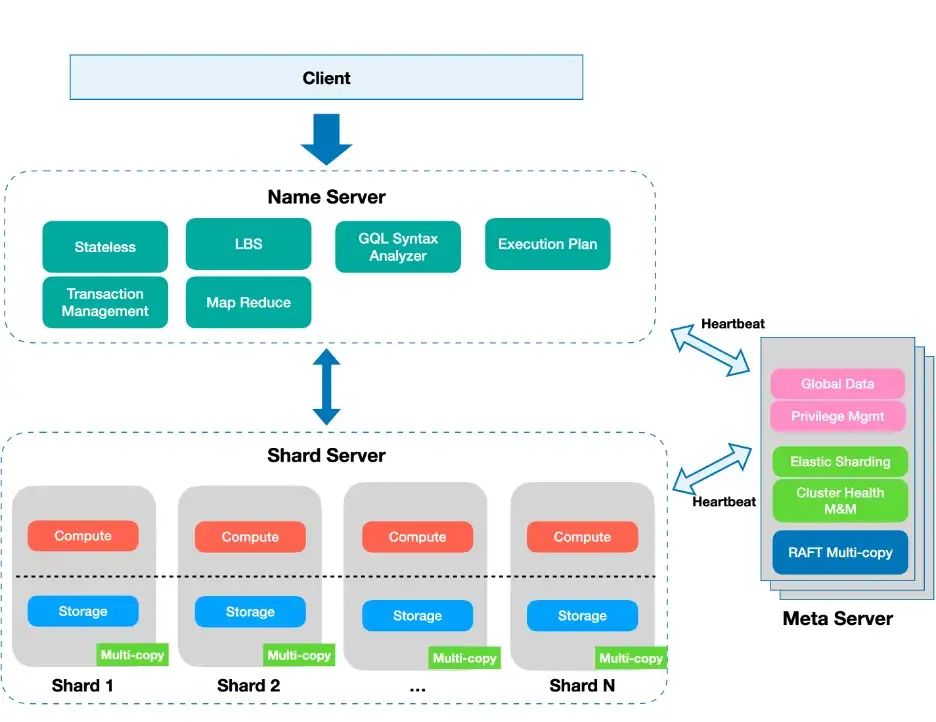
圖 6:帶有名稱服務器和元服務器的分片架構。
從傳統 SQL 或 NoSQL 大數據框架設計的角度來看,分片并不是什么新鮮事。然而,圖數據的分片可能是潘多拉魔盒,原因如下:
- 多個分片將提高 I/O 性能,尤其是數據攝取速度。
- 但是多個分片將顯著增加任何跨越多個分片的圖查詢的周轉時間,例如路徑查詢、k-hop 查詢和大多數圖算法(延遲增加可能是指數級的!)。
- 圖查詢計劃和優化可能非常復雜,如今大多數供應商在這方面做得很淺,并且有大量的機會可以即時深化查詢優化:
- 級聯(啟發式與成本)
- 分區修剪(實際上是碎片修剪)
- 索引選擇
- 統計(智能估計)
- 下推(使計算盡可能靠近存儲)等等。
在 Graph-7 中,我們捕獲了一些關于 Ultipa HTAP 集群和 Ultipa Shard 集群的初步發現;如您所見,數據攝取速度提高了四倍(超線性),但其他一切往往會慢五倍或更多(PageRank 慢 10 倍,LPA 慢 16 倍,等等)
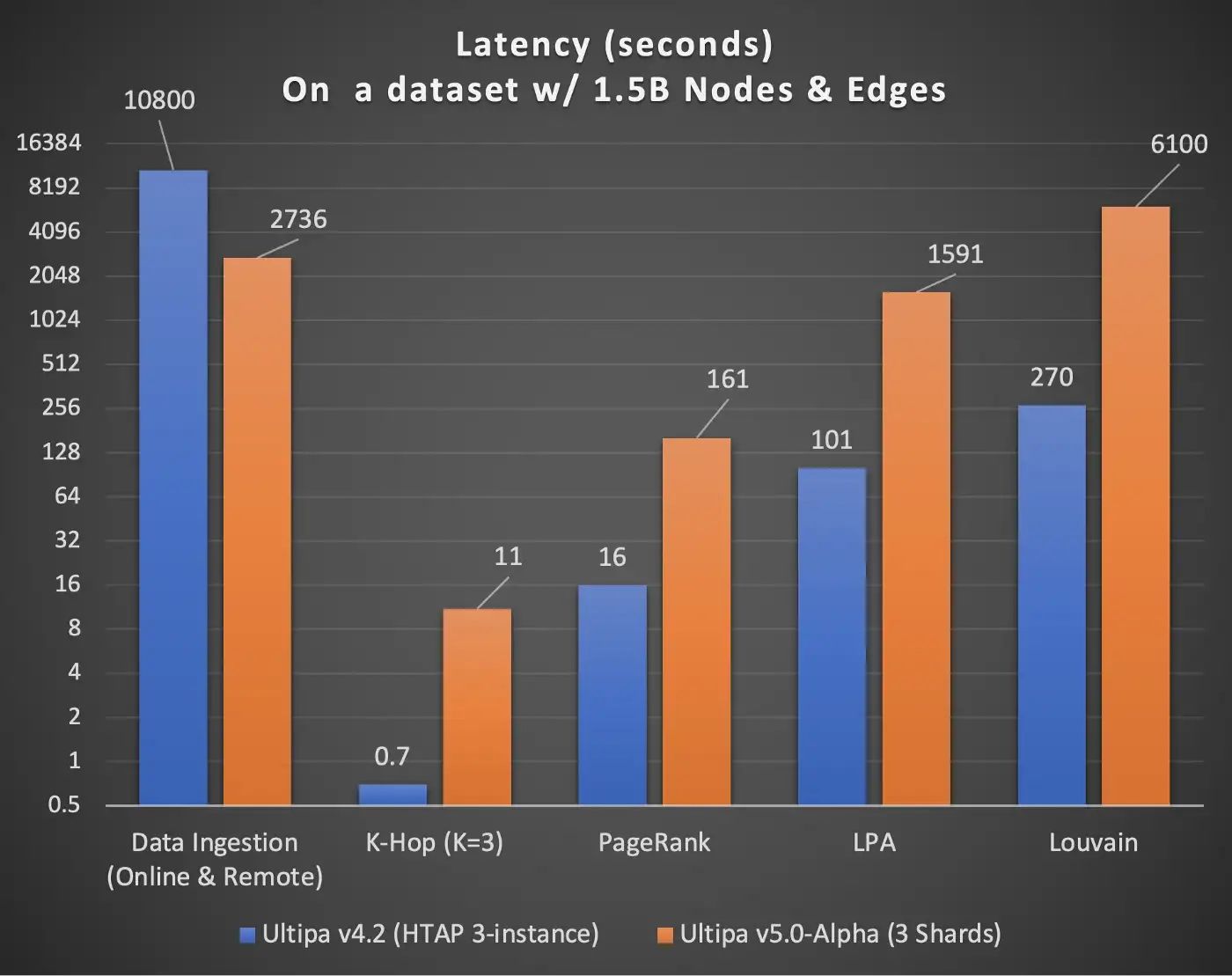
圖 7:HTAP 和分片架構之間性能差異的初步發現。
敬請關注
有很多機會可以不斷提高分片架構的性能。Ultipa 的團隊已經意識到,在水平可擴展系統上擁有真正先進的集群管理機制和更深入的查詢優化是實現無限可擴展性和令人滿意的性能的關鍵。
最后,分布式圖系統體系結構的第三流派說明了設計復雜且有能力的圖系統時所涉及的多樣性和復雜性。當然,鑒于成本、主觀偏好、設計理念、業務邏輯、復雜性容忍度、可服務性和許多其他因素,很難說一種架構絕對優于另一種架構——明智的做法是得出架構演進的方向從長遠來看,顯然是從第一所學校到第二所學校,最后到第三所學校。然而,大多數客戶場景可以滿足前兩種流派,人類智能(DBA 干預)在幫助實現性能和可擴展性的平衡方面仍然具有關鍵意義,特別是在第二和第三種設計流派中。
國王公式:
圖增強智能=人類智能+機器圖算力
















