如何使用Python遍歷HTML表和抓取表格數據
譯文譯者 | 李睿
審校 | 孫淑娟
表格數據是網絡上最好的數據來源之一。它們可以存儲大量有用的信息,同時又不丟失易于閱讀的格式,使其成為數據相關項目的金礦。
無論是抓取足球賽事數據還是提取股票市場數據,都可以使用Python從HTML表中快速訪問、解析和提取數據,而這需要感謝Requests和Beautiful Soup。
理解HTML表的結構
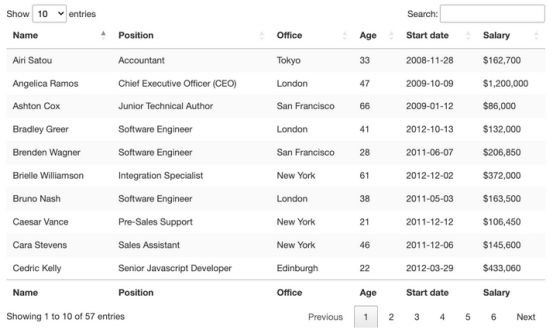
從視覺上看,HTML表是一組以表格格式顯示信息的行和列。本文主要介紹如何抓取表格數據:
為了能夠抓取該表中包含的數據,需要更深入地研究它的編碼。
一般來說,HTML表實際上是使用以下HTML標記構建的:
- <table>:標志著HTML表的開始
- <th> 或 <thead>:定義行作為HTML表的標題
- <tbody>:表示數據所在的部分
- <tr>:表示表中的一行
- <td>:在表中定義單元格
??然而,正如人們在實際場景中看到的,并不是所有開發人員在構建表時都遵循這些約定,這使得一些項目比其他項目更難。不過,了解它們的工作原理對于找到正確的方法至關重要。
在瀏覽器中輸入表的??URL??,并檢查頁面,看看在底層發生了什么。
這就是這個頁面非常適合練習用Python抓取表格數據的原因。有一個明確的<table>標簽對打開和關閉表,所有相關數據都在<tbody>標簽中。它只顯示與前端所選條目數量匹配的10行。
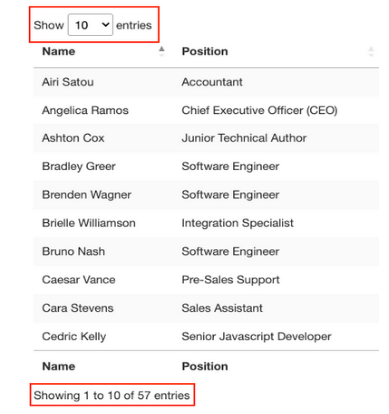
關于這個表還有一些需要了解的事情,即想要抓取的條目共有57個,并且似乎有兩種訪問數據的解決方案。第一種是點擊下拉菜單,選擇“100”,顯示所有條目:
或者單擊“下一步”按鈕以瀏覽分頁。

那么哪一種方案會更好?這兩種解決方案都會給腳本增加額外的復雜性,因此,先檢查從哪里提取數據。
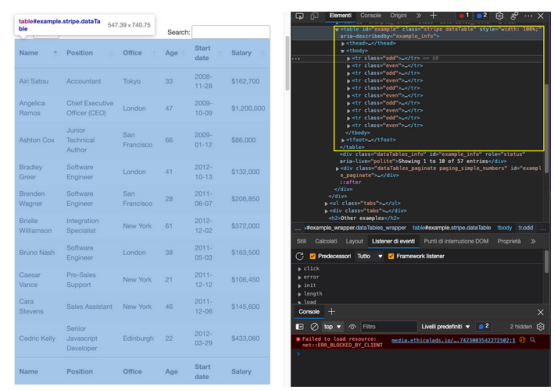
當然,因為這是一個HTML表,因此所有數據都應該在HTML文件本身上,而不需要AJAX注入。要驗證這一點,需要右擊>查看頁面來源。接下來,復制一些單元格并在源代碼中搜索它們。
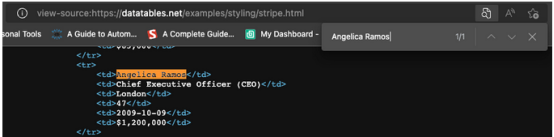
對來自不同分頁單元格的多個條目執行了相同的操作,盡管前端沒有顯示,但似乎所有目標數據都在其中。
有了這些信息,就可以開始編寫代碼了。
使用Python的Beautiful Soup刪除HTML表
因為要獲取的所有員工數據都在HTML文件中,所以可以使用Requests庫發送HTTP請求,并使用Beautiful Soup解析響應。
注:對于網頁抓取的新手,本文作者在Python教程中為初學者創建了一個網絡抓取教程。盡管新手沒有經驗也可以學習,但從基礎開始總是一個好主意。
1.發送主請求
在這個項目中創建一個名為python-html-table的新目錄,然后創建一個名為bs4-table-scraper的新文件夾,最后創建一個新的python_table_scraper.py文件。
從終端pip3安裝請求beautifulsoup4,并將它們導入到項目中,如下所示:
要用requests發送HTTP請求,所需要做的就是設置一個URL并通過request.get()傳遞它,將返回的HTML存儲在響應變量中并輸出response.status_code。
注:如果完全不熟悉Python,可以使用命令python3python_table_scraper.py從終端運行代碼。
如果它有效,將會返回一個200狀態碼。任何其他情況都意味著IP正在被網站設置的反抓取系統拒絕。一個潛在的解決方案是在腳本中添加自定義標題,使腳本看起來更加人性化,但這可能還不夠。另一個解決方案是使用Web抓取API處理所有這些復雜的問題。
2.使用Beautiful Soup構建解析器
在提取數據之前,需要將原始HTML轉換為格式化或解析的數據。將這個解析后的HTML存儲到一個soup對象中,如下所示:
從這里開始,可以使用HTML標記及其屬性遍歷解析樹。
如果返回到頁面上的表,已經看到該表用類stripe dataTable封裝在<table>標記之間,可以使用它來選擇該表。
注:在測試之后,添加第二個類(dataTable)并沒有返回元素。實際上,在return元素中,表的類只是stripe。還可以使用id='example'。
以下是它返回的結果:
既然已經獲取了表,就可以遍歷行并獲取所需的數據。
3.遍歷HTML表
回想一下HTML表的結構,每一行都由<tr>元素表示,其中有包含數據的<td>元素,所有這些都包裝在<tbody>標簽對之間。
為了提取數據,將創建兩個for looks,一個用于抓取表的<tbody>部分(所有行所在的位置),另一個用于將所有行存儲到可以使用的變量中:
在行中,將存儲表正文部分中找到的所有<tr>元素。如果遵循這個邏輯,下一步就是將每一行存儲到單個對象中,并循環遍歷它們以查找所需的數據。
首先,嘗試使用.querySelectorAll()方法在瀏覽器控制臺上選擇第一個員工的名字。這個方法的一個真正有用的特性是,可以越來越深入地實現大于(>)符號的層次結構,以定義父元素(在左側)和要獲取的子元素(在右側)。
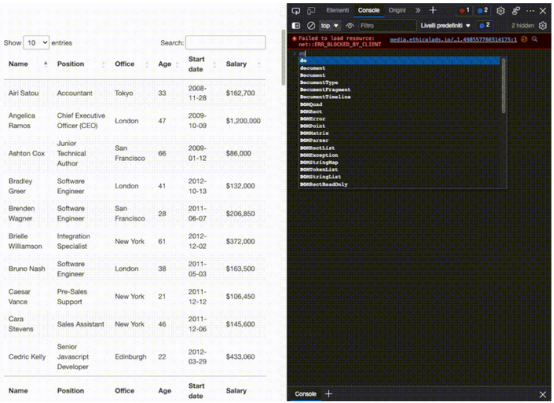
如上所見,一旦抓取所有<td>元素,這些元素就會成為節點列表。因為不能依賴類來獲取每個單元格,所以只需要知道它們在索引中的位置,而第一個name是0。
從那里,可以像這樣編寫代碼:
簡單地說,逐個獲取每一行,并找到其中的所有單元格,一旦有了列表,只獲取索引中的第一個單元格(position 0),然后使用.text方法只獲取元素的文本,忽略不需要的HTML數據。
這是一個包含所有員工姓名的列表! 對于其余部分,只需要遵循同樣的邏輯:
然而,將所有這些數據輸出在控制臺上并沒有太大幫助。與其相反,可以將這些數據存儲為一種、更有用的新格式。
4.將表格數據存儲到JSON文件中
雖然可以輕松地創建一個CSV文件并將數據發送到那里,但如果可以使用抓取的數據創建一些新內容,那么這將不是最容易管理的格式。
盡管如此,以前做的一個項目解釋了如何創建一個CSV文件來存儲抓取的數據。
好消息是,Python有自己的JSON模塊來處理JSON對象,所以不需要安裝任何程序,只需要導入它。
但是,在繼續并創建JSON文件之前,需要將所有這些抓取的數據轉換為一個列表。為此,將在循環外部創建一個空數組。
然后向它追加數據,每個循環向數組追加一個新對象。
如果print(employee_list),其結果如下:
還是有點混亂,但已經有了一組準備轉換為JSON的對象。
注:作為測試,輸出employee_list的長度,它返回57,這是抓取的正確行數(行現在是數組中的對象)。
將列表導入到JSON只需要兩行代碼:
- 首先,打開一個新文件,傳入想要的文件名稱(json_data)和'w',因為想要寫入數據。
- 接下來,使用.dump()函數從數組(employee_list)和indent=2中轉儲數據,這樣每個對象都有自己的行,而不是所有內容都在一個不可讀的行中。
5.運行腳本和完整代碼
如果一直按照下面的方法做,那么代碼庫應該是這樣的:
注:在這里為場景添加了一些注釋。
以下是JSON文件中的前三個對象:
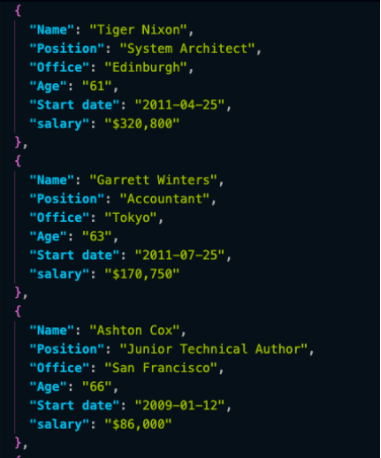
以JSON格式存儲抓取數據允將信息用于新的應用程序
使用Pandas抓取HTML表
在離開頁面之前,希望探索第二種抓取HTML表的方法。只需幾行代碼,就可以從HTML文檔中抓取所有表格數據,并使用Pandas將其存儲到數據框架中。
在項目的目錄中創建一個新文件夾(將其命名為panda-html-table-scraper),并創建一個新文件名pandas_table_scraper.py。
打開一個新的終端,導航到剛剛創建的文件夾(cdpanda-html-table-scraper),并從那里安裝pandas:
在文件的頂部導入它。
Pandas有一個名為read_html()的函數,它主要抓取目標URL,并返回所有HTML表作為DataFrame對象的列表。
要實現這一點,HTML表至少需要結構化,因為該函數將查找<table>之類的元素來標識文件中的表。
為了使用這個函數,需要創建一個新變量,并將之前使用的URL傳遞給它:
當輸出它時,它將返回頁面內的HTML表列表。
如果比較DataFrame中的前三行,它們與采用BeautifulSoup抓取的結果完全匹配。
為了處理JSON,Pandas可以有一個內置的.to_json()函數。它將把DataFrame對象列表轉換為JSON字符串。
而所需要做的就是調用DataFrame上的方法,并傳入路徑、格式(split,data,records,index等),并添加縮進以使其更具可讀性:
如果現在運行代碼,其結果文件如下:
注意,需要從索引([0])中選擇表,因為.read_html()返回一個列表,而不是單個對象。
以下是完整的代碼以供參考
有了這些新知識,就可以開始抓取網絡上幾乎所有的HTML表了。只要記住,如果理解了網站的結構和背后的邏輯,就沒有什么是不能抓取的。
也就是說,只要數據在HTML文件中,這些方法就有效。如果遇到動態生成的表,則需要找到一種新的方法。
原文標題:??How to Use Python to Loop Through HTML Tables and Scrape Tabular Data??,作者:Zoltan Bettenbuk?