HyperBDR是一款基于云原生理念的遷移和容災產品,核心的業務場景是將源端以塊級別差量方式同步至云原生存儲中,目前已經實現對塊存儲和對象存儲支持,最后再利用Boot-in-Cloud專利技術將業務系統一鍵式恢復至可用狀態,真正做到了對云原生編排能力的充分利用,滿足遷移和災備等業務場景的不同需求。
HyperBDR目前已經支持的源端操作系統大版本就將近10個(
Windows/CentOS/Redhat/Ubuntu/SUSE/國產化操作系統),小版本更是超過幾百個,而在目標目標云平臺也陸續支持了將近40個(公有云、專有云、私有云、超融合、虛擬化等),并且數量還在增加。假設我們將源端的操作系統到全部云平臺進行一次覆蓋性測試,組合的測試用例可能超過10000個。
這么大規模的情況下想做到測試覆蓋,單純依靠人力顯然不現實,必須引入自動化測試手段對核心業務場景進行測試,這樣不僅可以滿足自動化測試的需要,也可以在日常開發過程中及時讓開發人員在新開發功能中對核心流程的影響,進一步提升產品的穩定性和可靠性。
痛點分析
我們先來看一下手工測試情況下,HyperBDR產品測試的幾個痛點:
痛點一、測試用例多,人力資源不足
在上述源端和目標端的規模情況下,即使做一些基本冒煙,一次完整的測試的場景用例也依然有一百多種。例如:
- ? 源端(19種):CentOS(6/7/8)、Redhat(6/7/8)、SUSE(11/12)、Ubuntu(14.04/16.04/18.04/20.04)、Windows(2003/2008/2012/2016/2019)、Oracle Linux、國產化操作系統
- ? 目標端(9種):OpenStack、AWS、阿里云、騰訊云、華為云、移動云、ZStack、超融合產品、超融合產品
如此計算下來,一次測試的場景是171種。可能有的同學會說,這些用例也不是很多呀,跑一次也用不了多久,所以接下來讓我們看一下HyperBDR在測試過程中第二個痛點:測試周期問題。
痛點二、測試周期長
不同于業務測試,HyperBDR單一場景的測試是非常耗時的,我們先忽略前期資源準備時間和各種配置時間,單純就數據同步和啟動過程進行一下分析:
- ? 數據同步:簡單來說數據同步的過程就是將源端操作系統內的有效數據(不是分配容量),以塊級別方式讀出,寫入到目標的云原生存儲中。其中,第一次為全量,后續為永久增量。以Windows為例,假設有效數據為500G,如果按照千兆局域網帶寬80%利用率計算,傳輸速度大概在800 Mbps,大約為80 MB/s,耗時約為1小時8分鐘。
- ? 主機啟動:根據不同的云原生存儲類型,啟動時間有很大的差異性,例如華為云的塊存儲,由于快照機制以及可以支持交換系統盤,所以啟動時間與容量基本沒有關系,基本可以控制在5分鐘之內。但是對于國內的大多數云平臺來說,并沒有這樣的能力,像阿里云在有快照生成卷時,底層限速為40 MB/s,這樣一下子就拉長了恢復實踐。我們以對象存儲為例,假設我們從內網(Internal網絡)將對象存儲數據恢復至塊存儲,一個500G有效數據磁盤的恢復時間大約在40分鐘左右。
所以我們在處理單一主機的一次測試,耗時至少在2個小時之內。按照上面假設的場景,一天測試下來,可能連一朵云的完整測試都無法完成。可能這里又有同學說了,你為什么不并發呀?這又引出了我們第三個痛點問題:成本。
痛點三、測試成本
之所以無法完全采用并發的原因,是受限于網絡帶寬因素。在內部研發環境中,我們的外網帶寬只有40Mbps,在上述測試場景中,500G的數據在帶寬充分利用的前提下,全量數據傳輸的時間在35小時左右。這無疑進一步擴大了一次測試的周期。
另外一點,源端這么多環境,如果再加上不同場景,需要占用的源端的計算和存儲資源是海量的。隨著產品不停地迭代,資源占用會越來越多。所以為了解決這一問題,我們決定采用部分公有云環境,來解決本地資源不足的問題。根據資源使用的特點,主要采用按量計費方式,實現成本最優。在實際測試過程中,主要產生的云資源包括:計算、塊存儲、對象存儲、網絡等。在自動化測試中,盡可能縮短資源周期,避免浪費,及時清理資源。另外,還需要對資源賬單情況進行監控,避免資源殘留。
需求分析
基本原則:不要重復制造輪子
進行自動化測試開發工作,并沒有增加新的開發人員。開發工作主要由研發團隊負責,測試團隊作為使用方。但是由于開發團隊有自身產品研發任務,所以為了避免對產品研發造成影響,制定的第一個原則就是不要重復制造輪子,盡可能復用現有技術積累和第三方組件,靈活的實現自動化測試的目標。
需求一、源端自動化創建與銷毀
首先要解決的就是源端資源的靈活創建,而這方面最簡單的就是利用Terraform,結合不同的模板實現源端資源創建和銷毀能力。這樣,我們至少擁有了阿里云、華為云、AWS、OpenStack、VMware五大云作為源端的能力。
第二個要解決的是代理方式自動化注冊問題。源端主機需要進行Agent安裝和注冊后,才能被HyperBDR識別進行后續流程。根據操作系統不同,又分為Linux和Windows系統。Linux系統中,可以使用SSH登錄系統后執行安裝,而Windows則是利用WinRM方式進行Agent安裝。
第三,可擴展性滿足更多場景化需求。雖然Terraform本身提供了remote執行方式,但是為了后續的可擴展性,可以結合Ansible實現相關功能。未來的測試場景可能還包含對源端各種應用數據完整性的測試,此時在準備源端時還需要額外的準備應用和數據,使用Terraform結合Ansible,可以實現最大的靈活性。
需求二、測試場景與測試工具解耦,滿足擴展性需求
簡單來說,自動化測試程度越高,開發成本越高,后期維護的成本會更高。因此在規劃自動化測試時,要降低測試場景和測試工具之間的耦合性。這樣才能最大程度滿足測試場景的可擴展性。換言之,測試場景是由測試工具進行靈活組合實現的,而二者之間的差距是通過各種配置文件進行融會貫通。
具體到HyperBDR的自動化測試規劃中,我們將場景定義為:
- ? 為了驗證主線流程的穩定性,我們設計了這樣的場景:阿里云的一臺CentOS 7操作系統主機,容災到阿里云對象存儲中,利用該數據,主機可以正常啟動,系統啟動后,可以正常ping通IP地址,可以正常SSH到系統內部,寫入一個文件
- ? 為了驗證華為云驅動的穩定性,我們設計的場景如下:將阿里云的N臺主機(包含各個版本的操作系統),容災到華為云的對象存儲或塊存儲中,再將主機在華為云進行啟動,啟動后,利用ping通IP地址,可以正常登錄系統,寫入一個文件
- ? 為了驗證增量數據,我們設計的場景如下:將阿里云的N臺主機安裝數據庫,并且構建一定量數據進行記錄,容災到華為云對象存儲中,再將主機在華為云進行啟動,啟動后,除了常規驗證外,還要對數據庫是否可以訪問以及數據記錄條數進行比對
而測試工具提供的能力上,我們進行了這樣的定義:
- ? 源端創建/刪除資源:完全由Terraform實現,但是為了后續程序更好的銜接,在產生主機后,自動產生一個conf文件,作為后續命令的輸入,而主機內不同的應用則通過編寫Ansible模板實現
- ? 目標平臺配置/數據同步/啟動主機/清理資源:這幾部分主要通過調用HyperBDR SDK實現,而具體的配置則在配置文件中進行修改,如果是不同場景時,只需要不同的配置文件即可實現
以上全部的步驟,均是可以單獨執行的,而每一步完成后,寫入統一的CSV文件,這樣步驟在連接時可以通過該文件形成統一性。后續可以將該CSV文件直接推送到數據可視化工具中,形成趨勢展現的效果。
需求三、實現場景自動化,測試失敗及時通知
在實際應用中,幾乎從研發到交付的整個過程中都需要使用該工具。比如研發同學在提交代碼前,至少需要對基本流程進行一次測試;交付同事在搭建一些演示環境時,也可以利用該腳本提高效率;而測試同事更是對這個工具有強烈的需求。
那么真正的不同場景自動化工作,則是由Jenkins任務完成串聯,并且在測試失敗后,可以及時通知大家,盡快進行修改。例如:每個小時,做一次小的冒煙測試,確保主線流程是否穩定;每天凌晨,做一次基本冒煙,確保已經支持云平臺的穩定性;每周做一次大冒煙,確保主要的操作系統版本的穩定性。這樣不僅節約了人力資源,也能第一時間發現版本中的不穩定因素。
實現方式
整體架構
根據上面的需求,完整的工具包含兩部分:
- Terraform:主要包含了源端創建使用的模板以及ansible playbooks,Terraform在每次執行后,會自動產生源端主機列表,用于AutoTest工具的命令行輸入參數
- AutoTest工具:使用Python語言開發,主要通過對HyperBDR SDK調用控制HyperBDR實現自動化流程調度,各個階段都是通過獨立命令行進行控制,所有的可變部分在配置文件進行修改
- AutoTest配置文件包含以下三部分配置:
- 基本配置:HyperBDR SDK鑒權信息,以及平臺整體配置
- 目標云平臺配置:目標云平臺鑒權信息,配置參數等,根據不同的存儲類型分為塊存儲和對象存儲
- 容災/遷移配置:用于定義主機在目標端的啟動參數
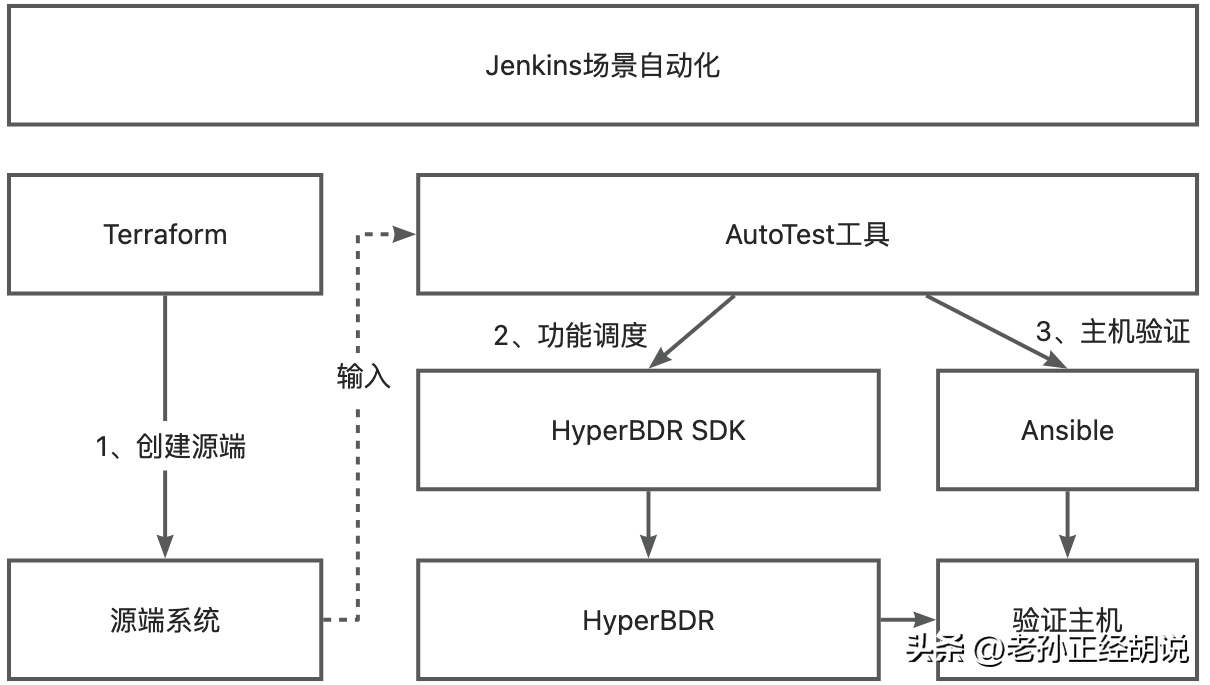
Terraform創建資源并遠程執行指令
Terraform的使用方面,有很多教程,這里不再贅述。這里主要說明一些Terraform使用的一些細節功能,滿足Terraform于AutoTest之間的腳本串聯。
內置方法remote-exec
Terraform創建資源后,會自動安裝Agent注冊到HyperBDR中,為了減少遠程主機操作復雜度,這里將Agent上傳至新創建的主機,再進行安裝實現自動注冊。
Terraform本身通過provisioner提供遠程連接、上傳并執行的方式,基本結構如下:
resource "null_resource" "ins_centos7_run_remote_command" {
# 定義了SSH連接方式,可以通過密碼或者密鑰方式
connection {
timeout = "5m"
type = "ssh"
user = "root"
password = "${random_password.password.result}"
host = "${openstack_compute_instance_v2.ins_centos7.network[0].fixed_ip_v4}"
}
# 將本地文件上傳至遠程資源的某個目錄中
provisioner "file" {
source = "../downloads/linux_agent.sh"
destination = "/tmp/script.sh"
}
# 通過remote-exec遠程執行腳本
provisioner "remote-exec" {
inline = [
"chmod +x /tmp/script.sh",
"sudo bash /tmp/script.sh",
]
}
depends_on = [openstack_compute_instance_v2.ins_centos7]
}如果是Windows,則連接方式為winrm方式,這里要注意的一點是,啟動的資源必須已經開啟了WinRM,否則無法使用該方式進行連接。一種開啟WinRM方式是利用user-data方式。這里看一下具體的示例
resource "null_resource" "run_windows_remote_command" {
# 注意此處的類型為winrm
connection {
timeout = "5m"
type = "winrm"
user = "Administrator"
password = "${random_password.password.result}"
host = "${openstack_compute_instance_v2.ins_windows.network[0].fixed_ip_v4}"
https = true
insecure = true
}
# 如果給定的是一個目錄,則會上傳整個目錄,但是要注意Windows目錄的斜線方向,盤符需要轉移C:\\
provisioner "file" {
source = "../downloads/Windows_server_64bit_beta"
destination = "C:\\Windows_server_64bit_beta"
}
# 遠程執行方式與Linux相同
provisioner "remote-exec" {
inline = [
"C:\\Windows_server_64bit_beta\\install-cli.bat",
"net start DiskSyncAgent",
]
}
depends_on = [openstack_compute_instance_v2.ins_windows]
}與Ansible結合
直接利用Terraform的遠程執行方式很簡便,但是對于更多的復雜場景在支持上,并不夠靈活,所以我們引入Ansible來加強我們對資源的控制。與remote-exec相對應的指令是local-exec,即通過執行本地的Ansible指令實現對遠程資源的控制。目錄結構如下:
.
├── main.tf
├── playbooks
│ └── apache-install.yml
我們將Ansible Playbooks存放在單獨的目錄中,Terraform中實現方式如下:
resource "null_resource" "run_ansible" {
connection {
timeout = "5m"
type = "ssh"
user = "root"
password = "${random_password.password.result}"
host = "${huaweicloud_vpc_eip.myeip.address}"
}
# 這里調用了local-exec本地執行Ansible命令
provisioner "local-exec" {
command = "ANSIBLE_HOST_KEY_CHECKING=False ansible-playbook -u root -i '${huaweicloud_vpc_eip.myeip.address},' --extra-vars 'ansible_ssh_pass=${random_password.password.result}' --ssh-common-args '-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null' playbooks/apache-install.yml"
}
depends_on = [huaweicloud_compute_eip_associate.associated]
}輸出
為了串接Terraform和AutoTest,我們需要Terraform每次執行后,輸出一個主機列表,包含了一些基本信息,當然這也可以作為Ansible Inventory文件使用。利用local_file resource,直接將我們想要寫入的內容定向輸出到文件中。具體實現如下:
resource "local_file" "inventory" {
filename = "./sources.conf"
content = <<-EOF
[${openstack_compute_instance_v2.ins_centos7.network[0].fixed_ip_v4}]
username = centos
password = ${nonsensitive(random_password.password.result)}
ipv4 = ${openstack_compute_instance_v2.ins_centos7.network[0].fixed_ip_v4}
mac = ${openstack_compute_instance_v2.ins_centos7.network[0].mac}
private_key = "${abspath(path.module)}/../keys/openstack_linux.pem"
os = CentOS7
EOF
}Terraform本地緩存
由于眾所周知的原因,Terraform在執行init命令的時候,會訪問github,這就造成安裝過程中有一定的失敗概率,為了減少失敗的風險,需要采用本地緩存的方式,避免訪問網絡造成的風險。先來看一下目錄結構:
.
├── install.sh
├── plugins-cache
│ └── registry.terraform.io
│ ├── hashicorp
│ │ ├── local
│ │ ├── null
│ │ ├── random
│ │ ├── template
│ │ └── tls
│ ├── huaweicloud
│ │ └── huaweicloud
│ └── terraform-provider-openstack
│ └── openstack
├── README.md
├── terraform_1.3.7_linux_amd64.zip
└── update_plugins_cache.sh
install.sh用于將下載好的terraform二進制包進行解壓縮安裝,同時會將plugins-cache拷貝至$HOME/.terraform.d目錄,最后生成.terraformrc文件。
plugin_cache_dir = "$HOME/.terraform.d/plugins-cache"
在實際執行時,通過指定參數實現從本地執行安裝,這種方式網上大部分文檔都沒有提及到:
terraform init -ignore-remote-version
在構建plugins-cache時,我們主要使用terraform providers mirror命令,例如:
terrform providers mirror /path/to/your/plugins-cache
為此我們在項目中增加了一個腳本,來自動化更新我們的緩存:
#!/bin/bash
#
# This script is used to install Terraform from local
#
set -e
CURRENT_PATH=$(cd `dirname $0`; pwd)
TERRAFORM_CLI="$HOME/bin/terraform"
PLUGINS_CACHE_PATH="${CURRENT_PATH}/plugins-cache"
SRC_ROOT_PATH="${CURRENT_PATH}/.."
# NOTE(Ray): Find all terraform directories and cache providers
for dir in $(find $SRC_ROOT_PATH -type d); do
for file in "$dir"/*tf; do
if [ -f "$file" ]; then
echo "Run terraform cache in $dir..."
$TERRAFORM_CLI providers mirror $PLUGINS_CACHE_PATH
break
fi
done
done
Taskflow串聯執行流程,實現擴展性
在AutoTest工具開發過程中,我們主要復用了OpenStack部分Python模塊簡化開發,主要使用的模塊為stevedore和taskflow,另外為了簡化CSV文件操作,使用了pandas庫來進行操作。
利用驅動方式擴展命令行
在setup.cfg中,我們定義了下面的驅動,每一個指令對應一個Taskflow的執行流程。
tasks =
cloud_config_oss = autotest.tasks.cloud_config:CloudConfigOss
cloud_config_block = autotest.tasks.cloud_config:CloudConfigBlock
cloud_config_clean = autotest.tasks.cloud_config:CloudConfigClean
data_sync_oss = autotest.tasks.data_sync:DataSyncOss
data_sync_block = autotest.tasks.data_sync:DataSyncBlock
host_boot = autotest.tasks.host_boot:HostBoot
host_clean = autotest.tasks.host_clean:HostClean
report = autotest.tasks.report:Report
在代碼加載時,通過輸入而不同參數,動態加載相應的流水線:
def run_tasks(args, hosts_conf, hyperbdr_conf):
"""Load each tasks as a driver"""
# We use a csv as a data table
data_table = DataTable(hosts_conf, args.work_path)
data_table.init()
status_file = StatusFile(args.work_path)
status_file.init()
driver_name = args.which.replace("-", "_")
logging.info("Loading task driver for %s..." % driver_name)
# 根據不同的命令行名稱,加載相關的驅動
driver_manager = driver.DriverManager(
namespace="tasks",
name=driver_name,
invoke_on_load=False)
task_driver = driver_manager.driver(hyperbdr_conf, data_table, status_file)
task_driver.run()
利用Taskflow串接流程
Taskflow是OpenStack中非常優秀的庫,對Task執行過程進行了抽象后,方便上層上時序業務場景使用。所以在應用中為了簡化開發過程,在Taskflow之上做了適當的抽象,將執行過程和執行內容進行分離,即基類中進行執行,而子類中只需要定義相關具體的任務即可。
基類代碼示例如下:
import taskflow.engines
from taskflow.patterns import linear_flow as lf
class BaseTask(object):
# 此處有代碼省略
def run(self, tasks=[], *args, **kwargs):
# 子類只需要在繼承類中定義好自己的tasks即可
if not tasks:
raise NotImplementedError("run() method "
"is not implemented")
# .......
flow_name = self.__class__.__name__
flow_api = lf.Flow(flow_name)
for task in tasks:
flow_api.add(task)
try:
taskflow.engines.run(flow_api,
engine_conf={"engine": "serial"},
store={
# 參數傳遞
})
except Exception as e:
raise e
finally:
# 任務失敗后的處理,比如記錄數據
一個具體的子類實現如下:
from taskflow import task
from autotest.tasks.base import BaseTask
class CloudConfigOss(BaseTask):
def run(self, *args, **kwargs):
steps = [
AddCloudAccount(),
WaitCloudAccount(),
AddOss(),
]
super().run(steps)
class AddCloudAccount(task.Task):
# TODO
class WaitCloudAccount(task.Task):
# TODO
class AddOss(task.Task):
# TODO
通過上述抽象,可以很快速的利用HyperBDR SDK實現各種應用場景,最大程度滿足后續可擴展性的需求。
Jenkins串聯自動化測試流程
工具實現后,不僅可以滿足手工分步執行的需要,也可以利用Jenkins串接流程,滿足場景自動化測試的需求。
場景自動化
我們在git中新建一個項目,名稱為autotest-cases,用于自動化場景測試。示例結構如下:
.
├── Jenkinsfile
├── openstack_oss_qa_tiny_smoke
│ ├── hyperbdr.conf
│ └── terraform_templates
我們以場景名稱命名目錄,每一個目錄下均有單獨一套的terraform模板和hyperbdr配置文件。這樣定義Jenkins任務時,就可以把測試場景作為一個目錄,靈活的進行加載。
其中Jenkinsifle的基本結構為:
pipeline {
// 省略部分代碼
parameters {
string(
name: 'TEST_CASE',
defaultValue: 'openstack_oss_qa_tiny_smoke',
description: '測試任務執行的目錄,對應autotest-cases的目錄'
)
string(
name: 'HYPERBDR_URL',
defaultValue: 'https://xxxx',
description: 'HyperBDR地址,需要配合鑒權信息使用'
)
// 省略部分代碼
}
stages {
stage('Clone Repository') {
// 省略部分代碼
} // end stage
stage('更新HyperBDR環境') {
// 省略部分代碼
} // end stage
stage('下載Agent代理') {
// 省略部分代碼
} // end stage
// 鑒權信息固定寫在Terraform tfvars文件時,使用時通過Jenkins中的Credentials進行替換
stage('創建源端') {
steps {
// 對每個目錄下auth文件進行替換后,source聲明環境變量
withCredentials([usernamePassword(credentialsId: "${CLOUD_CREDENTIALS_ID}", usernameVariable: 'USERNAME', passwordVariable: 'PASSWORD')]) {
sh """
sed -i "s/JENKINS_CLOUD_USERNAME/${USERNAME}/g" "${terraformVars}"
sed -i "s/JENKINS_CLOUD_PASSWORD/${PASSWORD}/g" "${terraformVars}"
"""
}
dir("${terraformTemplatePath}") {
sh """
${terraformPath} init -ignore-remote-version -plugin-dir ~/.terraform.d/plugins-cache
${terraformPath} apply -auto-approve -var-file="${terraformVars}"
"""
}
} // end steps
} // end stage
stage('目標平臺配置') {
// 省略部分代碼
} // end stage
stage('數據同步') {
// 省略部分代碼
} // end stage
stage('啟動主機') {
// 省略部分代碼
} // end stage
stage('清理資源') {
// 省略部分代碼
} // end stage
stage('清理環境') {
steps {
dir("${terraformTemplatePath}") {
sh """
${terraformPath} destroy -auto-approve -var-file="${terraformVars}"
"""
}
} // end steps
} // end stage
stage('發送報告') {
// 將Markdown格式報告發送至釘釘,包含執行結果和執行時間
} // end stage
} // end stages
} // end pipeline通過對每一階段的定義,能夠清晰的了解每一階段執行的結果以及失敗的原因,最終將結果發送至釘釘中,及時了解當前代碼的穩定性。
異常處理
在整個自動化測試流程中,如果在中間任何一個步驟失敗,都需要對資源進行及時清理,避免對下一次測試的影響。所以定義一個全局的失敗,進行強制資源清理。
post {
failure {
// TODO(Ray): 目前暫未加入清理目標端資源的邏輯
// 全局異常處理,保證源端和目標端不殘留資源
dir("${terraformTemplatePath}") {
sh """
${terraformPath} destroy -auto-approve -var-file="${terraformVars}"
"""
}
} // end failure
} // end post總結
目前,在HyperBDR的日常開發中,我們還在不斷完善自動化測試的場景,但是經過這一輪的實現,讓我對自動化測試有了全新的認知。
自動化測試能否實現全面覆蓋呢?至少在HyperBDR中不行,因為HyperBDR的源端和目標端造成了測試場景的不可預期性,很難完全通過自動化腳本來模擬出復雜場景,特別是異常場景。例如:對源端主機內部的破壞性測試,對數據傳輸鏈路的一些攻擊場景,需要配合監控才能發現是否滿足預期。這些場景,利用自動化測試模擬開發代價太大,而且可能發生的場景還在不斷變化,根本無法滿足版本快速迭代的需求。當然你如果有一個幾百人的研發團隊,專門做這件事情,那另當別論,不過這樣的投入產出比是否合理,值得探討。
自動化測試中,哪些該”自動“,哪些該”手動“?在實現自動化測試過程中,不要盲目的追求”自動“。自動程度越高,開發成本越高,靈活性大打折扣,導致可利用的場景較少,這反而與預期相違背。以HyperBDR場景為例,倒不如將每個流程進行切分,實現局部自動化,實現多個工具形成工具集,再用流程串聯方式構建場景化。
后續的計劃有哪些?隨著產品不停的迭代,自動化測試還將不斷的擴展,除了支持代理方式,還會增加對無代理方式、塊存儲方式自動化的支持,但是這些的開發模式全部以上述框架為前提。上述測試主要還是針對接口的測試,對于前端的測試還將引入Selenium實現,實現的范圍仍然以主線流程為主。最后,逐步豐富數據測試場景,增加對數據完整性的測試。
隨著DevOps理念逐步改變傳統研發流程,自動化測試作為其中的一環也是必不可少的,也是未來開發人員必備的技能之一。但是自動化測試不同于產品研發,要學會”斷“的思想,理解測試的需求和場景,才能做出適配性最好的自動化測試工具。