如何解決混合精度訓(xùn)練大模型的局限性問(wèn)題
混合精度已經(jīng)成為訓(xùn)練大型深度學(xué)習(xí)模型的必要條件,但也帶來(lái)了許多挑戰(zhàn)。將模型參數(shù)和梯度轉(zhuǎn)換為較低精度數(shù)據(jù)類型(如FP16)可以加快訓(xùn)練速度,但也會(huì)帶來(lái)數(shù)值穩(wěn)定性的問(wèn)題。使用進(jìn)行FP16 訓(xùn)練梯度更容易溢出或不足,導(dǎo)致優(yōu)化器計(jì)算不精確,以及產(chǎn)生累加器超出數(shù)據(jù)類型范圍的等問(wèn)題。

在這篇文章中,我們將討論混合精確訓(xùn)練的數(shù)值穩(wěn)定性問(wèn)題。為了處理數(shù)值上的不穩(wěn)定性,大型訓(xùn)練工作經(jīng)常會(huì)被擱置數(shù)天,會(huì)導(dǎo)致項(xiàng)目的延期。所以我們可以引入Tensor Collection Hook來(lái)監(jiān)控訓(xùn)練期間的梯度條件,這樣可以更好地理解模型的內(nèi)部狀態(tài),更快地識(shí)別數(shù)值不穩(wěn)定性。
在早期訓(xùn)練階段了解模型的內(nèi)部狀態(tài)可以判斷模型在后期訓(xùn)練中是否容易出現(xiàn)不穩(wěn)定是非常好的辦法,如果能夠在訓(xùn)練的頭幾個(gè)小時(shí)就能識(shí)別出梯度不穩(wěn)定性,可以幫助我們提升很大的效率。所以本文提供了一系列值得關(guān)注的警告,以及數(shù)值不穩(wěn)定性的補(bǔ)救措施。
混合精度訓(xùn)練
隨著深度學(xué)習(xí)繼續(xù)向更大的基礎(chǔ)模型發(fā)展。像GPT和T5這樣的大型語(yǔ)言模型現(xiàn)在主導(dǎo)著NLP,在CV中對(duì)比模型(如CLIP)的泛化效果優(yōu)于傳統(tǒng)的監(jiān)督模型。特別是CLIP的學(xué)習(xí)文本嵌入意味著它可以執(zhí)行超過(guò)過(guò)去CV模型能力的零樣本和少樣本推理,訓(xùn)練這些模型都是一個(gè)挑戰(zhàn)。
這些大型的模型通常涉及深度transformers網(wǎng)絡(luò),包括視覺(jué)和文本,并且包含數(shù)十億個(gè)參數(shù)。GPT3有1750億個(gè)參數(shù),CLIP則是在數(shù)百tb的圖像上進(jìn)行訓(xùn)練的。模型和數(shù)據(jù)的大小意味著模型需要在大型GPU集群上進(jìn)行數(shù)周甚至數(shù)月的訓(xùn)練。為了加速訓(xùn)練減少所需gpu的數(shù)量,模型通常以混合精度進(jìn)行訓(xùn)練。
混合精確訓(xùn)練將一些訓(xùn)練操作放在FP16中,而不是FP32。在FP16中進(jìn)行的操作需要更少的內(nèi)存,并且在現(xiàn)代gpu上可以比FP32的處理速度快8倍。盡管在FP16中訓(xùn)練的大多數(shù)模型精度較低,但由于過(guò)度的參數(shù)化它們沒(méi)有顯示出任何的性能下降。
隨著英偉達(dá)在Volta架構(gòu)中引入Tensor Cores,低精度浮點(diǎn)加速訓(xùn)練更加快速。因?yàn)樯疃葘W(xué)習(xí)模型有很多參數(shù),任何一個(gè)參數(shù)的確切值通常都不重要。通過(guò)用16位而不是32位來(lái)表示數(shù)字,可以一次性在Tensor Core寄存器中擬合更多參數(shù),增加每個(gè)操作的并行性。

但FP16的訓(xùn)練是存在挑戰(zhàn)性的。因?yàn)镕P16不能表示絕對(duì)值大于65,504或小于5.96e-8的數(shù)字。深度學(xué)習(xí)框架例如如PyTorch帶有內(nèi)置工具來(lái)處理FP16的限制(梯度縮放和自動(dòng)混合精度)。但即使進(jìn)行了這些安全檢查,由于參數(shù)或梯度超出可用范圍而導(dǎo)致大型訓(xùn)練工作失敗的情況也很常見(jiàn)。深度學(xué)習(xí)的一些組件在FP32中發(fā)揮得很好,但是例如BN通常需要非常細(xì)粒度的調(diào)整,在FP16的限制下會(huì)導(dǎo)致數(shù)值不穩(wěn)定,或者不能產(chǎn)生足夠的精度使模型正確收斂。這意味著模型并不能盲目地轉(zhuǎn)換為FP16。
所以深度學(xué)習(xí)框架使用自動(dòng)混合精度(AMP),它通過(guò)一個(gè)預(yù)先定義的FP16訓(xùn)練安全操作列表。AMP只轉(zhuǎn)換模型中被認(rèn)為安全的部分,同時(shí)將需要更高精度的操作保留在FP32中。另外在混合精度訓(xùn)練中模型中通過(guò)給一些接近于零梯度(低于FP16的最小范圍)的損失乘以一定數(shù)值來(lái)獲得更大的梯度,然后在應(yīng)用優(yōu)化器更新模型權(quán)重時(shí)將按比例向下調(diào)整來(lái)解決梯度過(guò)小的問(wèn)題,這種方法被稱為梯度縮放。
下面是PyTorch中一個(gè)典型的AMP訓(xùn)練循環(huán)示例。

梯度縮放器scaler會(huì)將損失乘以一個(gè)可變的量。如果在梯度中觀察到nan,則將倍數(shù)降低一半,直到nan消失,然后在沒(méi)有出現(xiàn)nan的情況下,默認(rèn)每2000步逐漸增加倍數(shù)。這樣會(huì)保持梯度在FP16范圍內(nèi),同時(shí)也防止梯度變?yōu)榱恪?/p>
訓(xùn)練不穩(wěn)定的案例
盡管框架都盡了最大的努力,但PyTorch和TensorFlow中內(nèi)置的工具都不能阻止在FP16中出現(xiàn)的數(shù)值不穩(wěn)定情況。
在HuggingFace的T5實(shí)現(xiàn)中,即使在訓(xùn)練之后模型變體也會(huì)產(chǎn)生INF值。在非常深的T5模型中,注意力值會(huì)在層上累積,最終達(dá)到FP16范圍之外,這會(huì)導(dǎo)致值無(wú)窮大,比如在BN層中出現(xiàn)nan。他們是通過(guò)將INF值改為在FP16的最大值解決了這個(gè)問(wèn)題,并且發(fā)現(xiàn)這對(duì)推斷的影響可以忽略不計(jì)。
另一個(gè)常見(jiàn)問(wèn)題是ADAM優(yōu)化器的限制。作為一個(gè)小更新,ADAM使用梯度的第一和第二矩的移動(dòng)平均來(lái)適應(yīng)模型中每個(gè)參數(shù)的學(xué)習(xí)率。
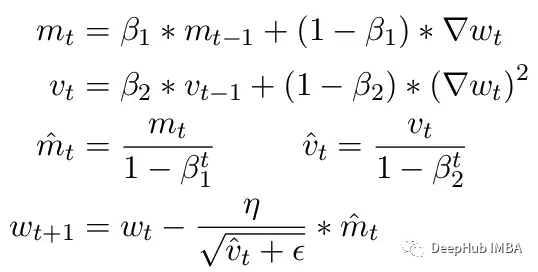
這里Beta1 和 Beta2 是每個(gè)時(shí)刻的移動(dòng)平均參數(shù),通常分別設(shè)置為 .9 和 .999。用 beta 參數(shù)除以步數(shù)的冪消除了更新中的初始偏差。在更新步驟中,向二階矩參數(shù)添加一個(gè)小的 epsilon 以避免被零除產(chǎn)生錯(cuò)誤。epsilon 的典型默認(rèn)值是 1e-8。但 FP16 的最小值為 5.96e-8。這意味著如果二階矩太小,更新將除以零。所以在 PyTorch 中為了訓(xùn)練不會(huì)發(fā)散,更新將跳過(guò)該步驟的更改。但問(wèn)題仍然存在尤其是在 Beta2=.999 的情況下,任何小于 5.96e-8 的梯度都可能會(huì)在較長(zhǎng)時(shí)間內(nèi)停止參數(shù)的權(quán)重更新,優(yōu)化器會(huì)進(jìn)入不穩(wěn)定狀態(tài)。
ADAM的優(yōu)點(diǎn)是通過(guò)使用這兩個(gè)矩,可以調(diào)整每個(gè)參數(shù)的學(xué)習(xí)率。對(duì)于較慢的學(xué)習(xí)參數(shù),可以加快學(xué)習(xí)速度,而對(duì)于快速學(xué)習(xí)參數(shù),可以減慢學(xué)習(xí)速度。但如果對(duì)多個(gè)步驟的梯度計(jì)算為零,即使是很小的正值也會(huì)導(dǎo)致模型在學(xué)習(xí)率有時(shí)間向下調(diào)整之前發(fā)散。
另外PyTorch目前還一個(gè)問(wèn)題,在使用混合精度時(shí)自動(dòng)將epsilon更改為1e-7,這可以幫助防止梯度移回正值時(shí)發(fā)散。但是這樣做會(huì)帶來(lái)一個(gè)新的問(wèn)題,當(dāng)我們知道梯度在相同的范圍內(nèi)時(shí),增加ε會(huì)降低了優(yōu)化器適應(yīng)學(xué)習(xí)率的能力。所以盲目的增加epsilon也不能解決由于零梯度而導(dǎo)致訓(xùn)練停滯的情況。
CLIP訓(xùn)練中的梯度縮放
為了進(jìn)一步證明訓(xùn)練中可能出現(xiàn)的不穩(wěn)定性,我們?cè)贑LIP圖像模型上構(gòu)建了一系列實(shí)驗(yàn)。CLIP是一種基于對(duì)比學(xué)習(xí)的模型,它通過(guò)視覺(jué)轉(zhuǎn)換器和描述這些圖像的文本嵌入同時(shí)學(xué)習(xí)圖像。對(duì)比組件試圖在每批數(shù)據(jù)中將圖像匹配回原始描述。由于損失是在批次中計(jì)算的,在較大批次上的訓(xùn)練已被證明能提供更好的結(jié)果。
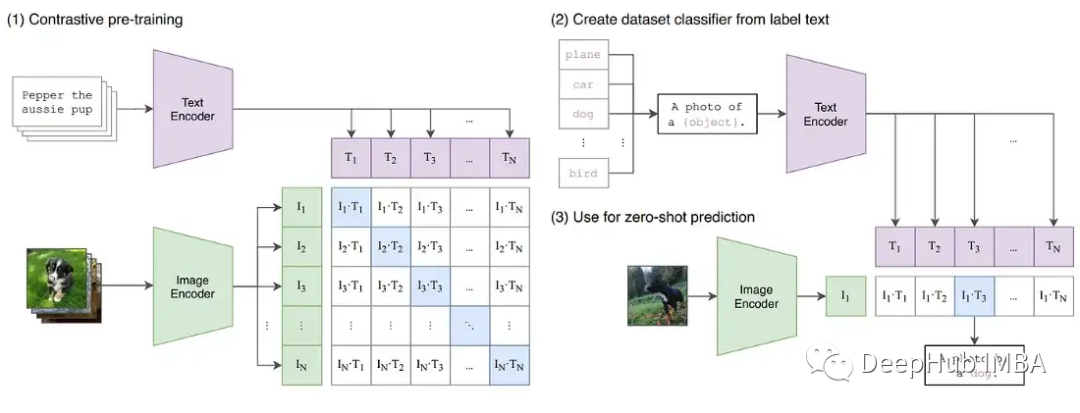
CLIP同時(shí)訓(xùn)練兩個(gè)transformers模型,一個(gè)類似GPT的語(yǔ)言模型和一個(gè)ViT圖像模型。兩種模型的深度都為梯度增長(zhǎng)創(chuàng)造了超越FP16限制的機(jī)會(huì)。OpenClip(arxiv 2212.07143)實(shí)現(xiàn)描述了使用FP16時(shí)的訓(xùn)練不穩(wěn)定性。
Tensor Collection Hook
為了更好地理解訓(xùn)練期間的內(nèi)部模型狀態(tài),我們開(kāi)發(fā)了一個(gè)Tensor Collection Hook (TCH)。TCH可以包裝一個(gè)模型,并定期收集關(guān)于權(quán)重、梯度、損失、輸入、輸出和優(yōu)化器狀態(tài)的摘要信息。
例如,在這個(gè)實(shí)驗(yàn)中,我們要找到和記錄訓(xùn)練過(guò)程中的梯度條件。比如可能想每隔10步從每一層收集梯度范數(shù)、最小值、最大值、絕對(duì)值、平均值和標(biāo)準(zhǔn)差,并在 TensorBoard 中可視化結(jié)果。

然后可以用out_dir作為--logdir輸入啟動(dòng)TensorBoard。

實(shí)驗(yàn)
為了重現(xiàn)CLIP中的訓(xùn)練不穩(wěn)定性,用于OpenCLIP訓(xùn)練Laion 50億圖像數(shù)據(jù)集的一個(gè)子集。我們用TCH包裝模型,定期保存模型梯度、權(quán)重和優(yōu)化器時(shí)刻的狀態(tài),這樣就可以觀察到不穩(wěn)定發(fā)生時(shí)模型內(nèi)部發(fā)生了什么。
從vvi - h -14變體開(kāi)始,OpenCLIP作者描述了在訓(xùn)練期間存在穩(wěn)定性問(wèn)題。從預(yù)訓(xùn)練的檢查點(diǎn)開(kāi)始,將學(xué)習(xí)率提高到1-e4,與CLIP訓(xùn)練后半段的學(xué)習(xí)率相似。在訓(xùn)練進(jìn)行到300步時(shí),有意連續(xù)引入10個(gè)難度較大的訓(xùn)練批次。
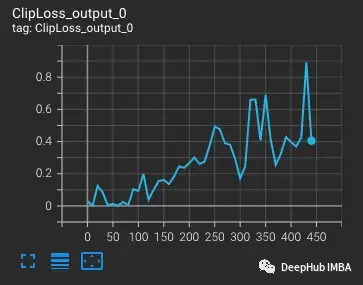
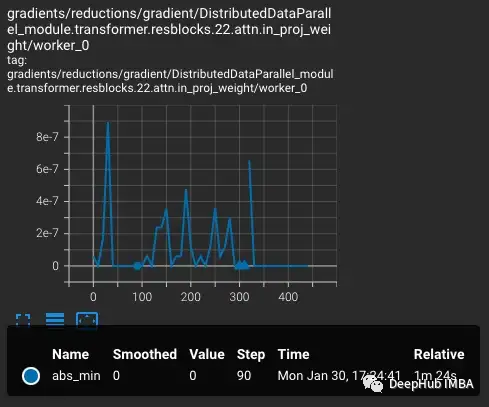
損失會(huì)隨著學(xué)習(xí)率的增加而增加,這是可預(yù)期的。當(dāng)在第300步引入難度較大的情況時(shí),損失會(huì)有一個(gè)小的,但不是很大的增加。該模型發(fā)現(xiàn)難度較大的情況,但沒(méi)有更新這些步驟中的大部分權(quán)重,因?yàn)閚an出現(xiàn)在梯度中(在第二個(gè)圖中顯示為三角形)。通過(guò)這組難度較大的情況后,梯度降為零。
PyTorch梯度縮放
這里發(fā)生了什么?為什么梯度是零?問(wèn)題就出在PyTorch的梯度縮放。梯度縮放是混合精度訓(xùn)練中的一個(gè)重要工具。因?yàn)樵诰哂袛?shù)百萬(wàn)或數(shù)十億個(gè)參數(shù)的模型中,任何一個(gè)參數(shù)的梯度都很小,并且通常低于FP16的最小范圍。
當(dāng)混合精確訓(xùn)練剛剛提出時(shí),深度學(xué)習(xí)的科學(xué)家發(fā)現(xiàn)他們的模型在訓(xùn)練早期通常會(huì)按照預(yù)期進(jìn)行訓(xùn)練,但最終會(huì)出現(xiàn)分歧。隨著訓(xùn)練的進(jìn)行梯度趨于變小,一些下溢的 FP16 變?yōu)榱悖褂?xùn)練變得不穩(wěn)定。

為了解決梯度下溢,早期的技術(shù)只是簡(jiǎn)單地將損失乘以一個(gè)固定的量,計(jì)算更大的梯度,然后將權(quán)重更新調(diào)整為相同的固定量(在混合精確訓(xùn)練期間,權(quán)重仍然存儲(chǔ)在FP32中)。但有時(shí)這個(gè)固定的量仍然不夠。而較新的技術(shù),如PyTorch的梯度縮放,從一個(gè)較大的乘數(shù)開(kāi)始,通常是65536。但是由于這可能很高,導(dǎo)致大的梯度會(huì)溢出FP16值,所以梯度縮放器監(jiān)視將溢出的nan梯度。如果觀察到nan,則在這一步跳過(guò)權(quán)重更新將乘數(shù)減半,然后繼續(xù)下一步。這一直持續(xù)到在梯度中沒(méi)有觀察到nan。如果在2000步中梯度縮放器沒(méi)有檢測(cè)到nan,它將嘗試使乘數(shù)加倍。
在上面的例子中,梯度縮放器完全按照預(yù)期工作。我們向它傳遞一組比預(yù)期損失更大的情況,這會(huì)產(chǎn)生更大的梯度導(dǎo)致溢出。但問(wèn)題是現(xiàn)在的乘數(shù)很低,較小的梯度正在下降到零,梯度縮放器不監(jiān)視零梯度只監(jiān)視nan。
上面的例子最初看起來(lái)可能有些故意的成分,因?yàn)槲覀冇幸鈱⒗щy的例子分組。但是經(jīng)過(guò)數(shù)天的訓(xùn)練,在大批量的情況下,產(chǎn)生nan的異常情況的概率肯定會(huì)增加。所以遇到足夠多的nan將梯度推至零的幾率是非常大。其實(shí)即使不引入困難的樣本,也經(jīng)常會(huì)發(fā)現(xiàn)在幾千個(gè)訓(xùn)練步驟后,梯度始終為零。
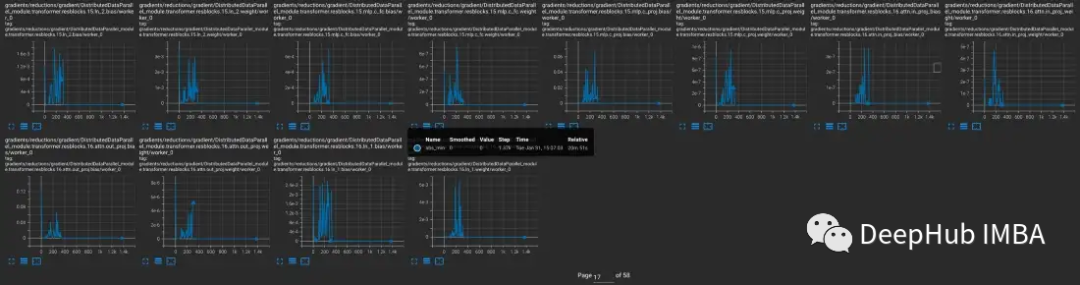
產(chǎn)生梯度下溢的模型
為了進(jìn)一步探索問(wèn)題何時(shí)發(fā)生,何時(shí)不發(fā)生,將CLIP與通常在混合精度下訓(xùn)練的較小CV模型YOLOV5進(jìn)行了比較。在這兩種情況下的訓(xùn)練過(guò)程中跟蹤了每一層中零梯度的頻率。

在前9000步的訓(xùn)練中,CLIP中5-20%的層顯示梯度下溢,而Yolo中的層僅顯示偶爾下溢。CLIP中的下溢率也隨著時(shí)間的推移而增加,使得訓(xùn)練不太穩(wěn)定。
使用梯度縮放并不能解決這個(gè)問(wèn)題,因?yàn)镃LIP范圍內(nèi)的梯度幅度遠(yuǎn)遠(yuǎn)大于YOLO范圍內(nèi)的梯度幅度。在CLIP的情況下,當(dāng)梯度縮放器將較大的梯度移到FP16的最大值附近時(shí),最小的梯度仍然低于最小值。
如何解決解CLIP中的梯度不穩(wěn)定性
在某些情況下,調(diào)整梯度縮放器的參數(shù)可以幫助防止下溢。在CLIP的情況下,可以嘗試修改以一個(gè)更大的乘數(shù)開(kāi)始,并縮短增加間隔。

但是我們發(fā)現(xiàn)乘數(shù)會(huì)立即下降以防止溢出,并迫使小梯度回到零。

改進(jìn)縮放比例的一種解決方案是使其更適應(yīng)參數(shù)范圍。比如論文 Adaptive Loss Scaling for Mixed Precision Training 建議按層而不是整個(gè)模型執(zhí)行損失縮放,這樣可以防止下溢。而我們的實(shí)驗(yàn)表明需要一種更具適應(yīng)性的方法。由于 CLIP 層內(nèi)的梯度仍然覆蓋整個(gè) FP16 范圍,縮放需要適應(yīng)每個(gè)單獨(dú)的參數(shù)以確保訓(xùn)練穩(wěn)定性。但是這種詳細(xì)的縮放需要大量?jī)?nèi)存會(huì)減少了訓(xùn)練的批大小。
較新的硬件提供了更有效的解決方案。比如BFloat16 (BF16) 是另一種 16 位數(shù)據(jù)類型,它以精度換取更大的范圍。FP16 處理 5.96e-8 到 65,504,而B(niǎo)F16 可以處理 1.17e-38 到 3.39e38,與 FP32 的范圍相同。但是 BF16 的精度低于 FP16,會(huì)導(dǎo)致某些模型不收斂。但對(duì)于大型的transformers模型,BF16 并未顯示會(huì)降低收斂性。
我們運(yùn)行相同的測(cè)試,插入一批困難的觀察結(jié)果,在 BF16 中,當(dāng)引入困難的情況時(shí),梯度會(huì)出現(xiàn)尖峰,然后返回到常規(guī)訓(xùn)練,因?yàn)樘荻瓤s放由于范圍增加而從未在梯度中觀察到 NaN。

對(duì)比FP16和BF16的CLIP,我們發(fā)現(xiàn)BF16中只有偶爾的梯度下溢。

在PyTorch 1.12及更高版本中,可以通過(guò)對(duì)AMP的一個(gè)小更改來(lái)啟動(dòng)BF16。

如果需要更高的精度,可以試試Tensorfloat32 (TF32)數(shù)據(jù)類型。TF32由英偉達(dá)在安培GPU中引入,是一個(gè)19位浮點(diǎn)數(shù),增加了BF16的額外范圍位,同時(shí)保留了FP16的精度。與FP16和BF16不同,它被設(shè)計(jì)成直接取代FP32,而不是在混合精度下啟用。要在PyTorch中啟用TF32,在訓(xùn)練開(kāi)始時(shí)添加兩行。

這里需要注意的是:在PyTorch 1.11之前,TF32在支持該數(shù)據(jù)類型的gpu上默認(rèn)啟用。從PyTorch 1.11開(kāi)始,它必須手動(dòng)啟用。TF32的訓(xùn)練速度比BF16和FP16慢,理論FLOPS只有FP16的一半,但仍然比FP32的訓(xùn)練速度快得多。
如果你用亞馬遜的AWS:BF16和TF32在P4d、P4de、G5、Trn1和DL1實(shí)例上是可用的。
在問(wèn)題發(fā)生之前解決問(wèn)題
上面的例子說(shuō)明了如何識(shí)別和修復(fù)FP16范圍內(nèi)的限制。但這些問(wèn)題往往在訓(xùn)練后期才會(huì)出現(xiàn)。在訓(xùn)練早期,模型會(huì)產(chǎn)生更高的損失并對(duì)異常值不太敏感,就像在OpenCLIP訓(xùn)練中發(fā)生的那樣,在問(wèn)題出現(xiàn)之前可能需要幾天的時(shí)間,這回浪費(fèi)了昂貴的計(jì)算時(shí)間。
FP16和BF16都有優(yōu)點(diǎn)和缺點(diǎn)。FP16的限制會(huì)導(dǎo)致不穩(wěn)定和失速訓(xùn)練。但BF16提供的精度較低,收斂性也可能較差。所以我們肯定希望在訓(xùn)練早期識(shí)別易受FP16不穩(wěn)定性影響的模型,這樣我們就可以在不穩(wěn)定性發(fā)生之前做出明智的決定。所以再次對(duì)比那些表現(xiàn)出和沒(méi)有表現(xiàn)出后續(xù)訓(xùn)練不穩(wěn)定性的模型,可以發(fā)現(xiàn)兩個(gè)趨勢(shì)。

在FP16中訓(xùn)練的YOLO模型和在BF16中訓(xùn)練的CLIP模型都顯示出梯度下溢率一般小于1%,并且隨著時(shí)間的推移是穩(wěn)定的。

在FP16中訓(xùn)練的CLIP模型在訓(xùn)練的前1000步中下溢率為5-10%,并隨著時(shí)間的推移呈現(xiàn)上升趨勢(shì)。
所以通過(guò)使用TCH來(lái)跟蹤梯度下溢率,能夠在訓(xùn)練的前4-6小時(shí)內(nèi)識(shí)別出更高梯度不穩(wěn)定性的趨勢(shì)。當(dāng)觀察到這種趨勢(shì)時(shí)可以切換到BF16。
總結(jié)
混合精確訓(xùn)練是訓(xùn)練現(xiàn)有大型基礎(chǔ)模型的重要組成部分,但需要特別注意數(shù)值穩(wěn)定性。了解模型的內(nèi)部狀態(tài)對(duì)于診斷模型何時(shí)遇到混合精度數(shù)據(jù)類型的限制非常重要。通過(guò)用一個(gè)TCH包裝模型,可以跟蹤參數(shù)或梯度是否接近數(shù)值極限,并在不穩(wěn)定發(fā)生之前執(zhí)行訓(xùn)練更改,從而可能減少不成功的訓(xùn)練運(yùn)行天數(shù)。