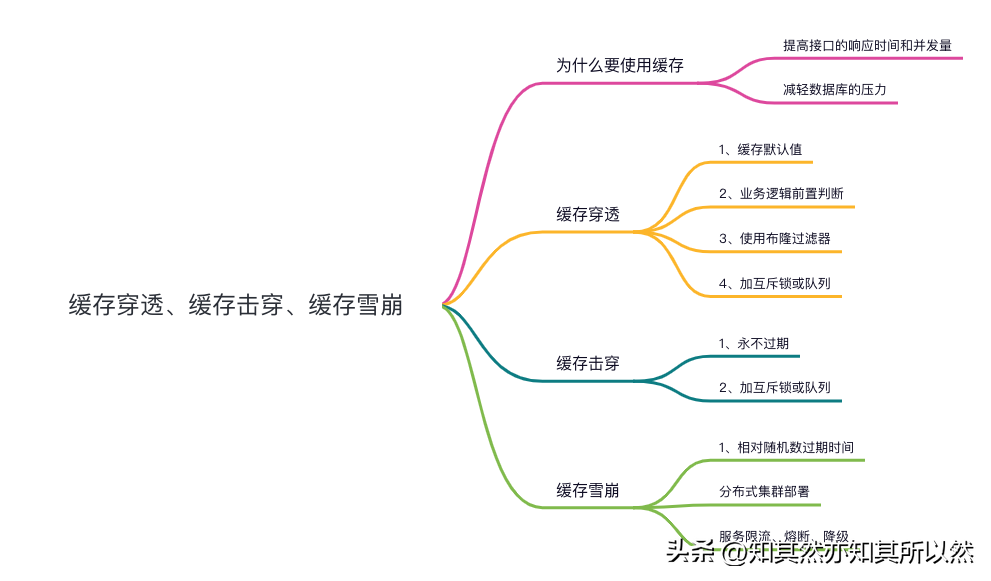
Redis:緩存穿透、緩存擊穿、緩存雪崩?
為什么要使用緩存
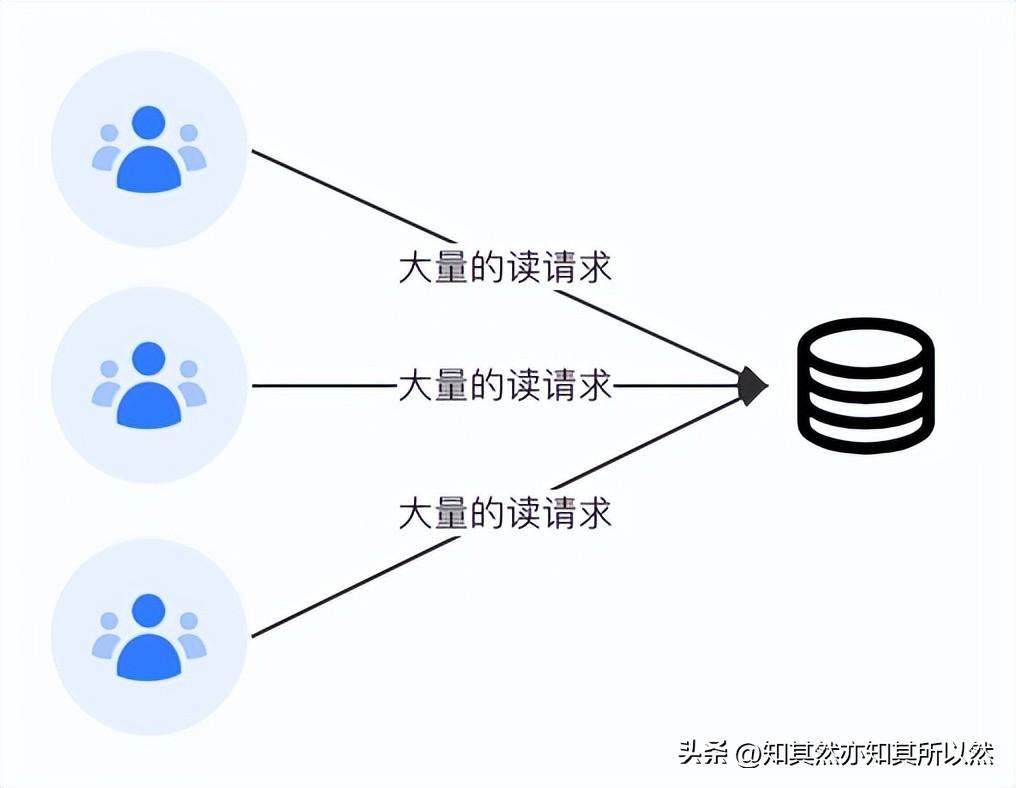
我們做的每一個項目基本上剛開始都是一個很小的項目,每天的QPS很少,那個時候系統訪問都是直接請求到數據庫;后來項目越來越大,使用的人越來越多,每天對于數據庫的壓力劇增,為了保證“有效、有限的請求”訪問到數據庫,我們放大前置環節的邏輯和成本,所以緩存應運而生。
緩存的好處有以下兩點:
- 提高接口的響應時間和并發量;
- 減輕數據庫的壓力。
但是,我們用到了緩存,就不得不考慮三個經典的場景:“緩存穿透”、“緩存擊穿”、“緩存雪崩”。本文將介紹三種場景并給出合理的解決方案,如有異議,請進行友好的評論。
緩存穿透
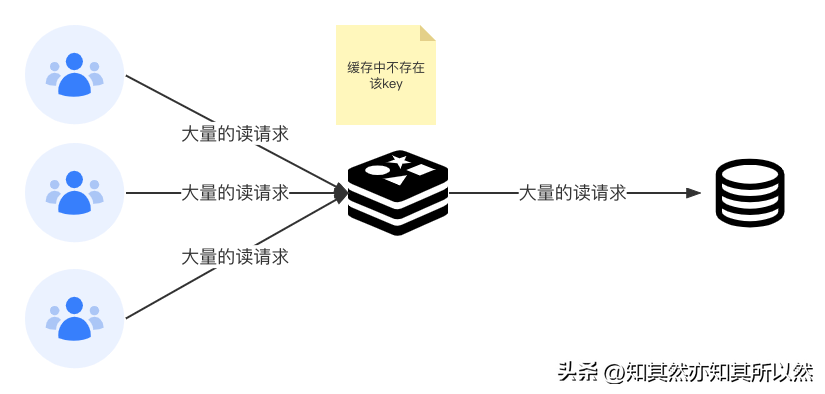
正常情況下,一個請求過來,首先判斷key是否存在,如果key存在,直接返回;如果key不存在或者已過期,查詢數據庫,如果數據庫中存在數據,則更新緩存并返回數據;如果不存在,則直接返回空。
緩存穿透(cache penetration)是用戶訪問的key在數據庫中一定不存在的數據,如果有人利用這個漏洞惡意系統,每次請求的壓力都給到數據庫,會壓垮數據庫,造成系統崩潰。
方案一:緩存默認值
在數據庫查詢不存在時,可以將其緩存為默認值。不過設置的時間不宜過長(建議設置為60s),如果過了一會兒數據庫新增了該數據,時間太長的話,就會出現數據不一致的情況。
方案二:業務邏輯前置判斷
如果有人為的惡意打擊,用不合理的參數去請求系統,按照方案一新增了大量的不存在的key到內存中,極端情況下,緩存也被撐爆了……
所以我們可以在接口處進行數據合法性校驗,進行提前拒絕。比如:a接口只允許查詢18+的成年人的數據,請求帶有未成年人就明顯不合適。
方案三:使用布隆過濾器
如果有人很巧妙的用合理的參數但是系統內不存在的key請求系統,系統按照方案一、方案二也會新增大量的不存在key到內存中,這時又怎么辦呢……
那我們可以使用布隆過濾器(本文不做擴展哈,請自行了解),當把數據寫入數據庫的時候,使用布隆過濾器進行標記,當有請求時,如果發現緩存消失,在去查詢數據庫前,先查詢布隆過濾器該key是否存在,如果不存在,直接返回,不過布隆過濾器有一定的誤判率,這個可以忽略。
方案四:加互斥鎖或隊列
經過方案一、二、三的優化,應該可以處理穿透的問題吧,但是仔細想一想,兄弟兒,我們是高并發的場景啊,所以,場景是大量的請求同一時刻都來請求同一個key,發現沒有這個key,全都去訪問數據庫,以至于系統崩潰……
在這里,我們要加一個鎖,只保證一個線程去創建緩存,其余的等待,這樣就ok了。
緩存擊穿
緩存擊穿(Cache Breakdown)指的是一個熱點key,在不停的被大量的請求訪問,當這個熱點key緩存失效的瞬間,大量的請求訪問到數據庫,以至于系統崩潰。
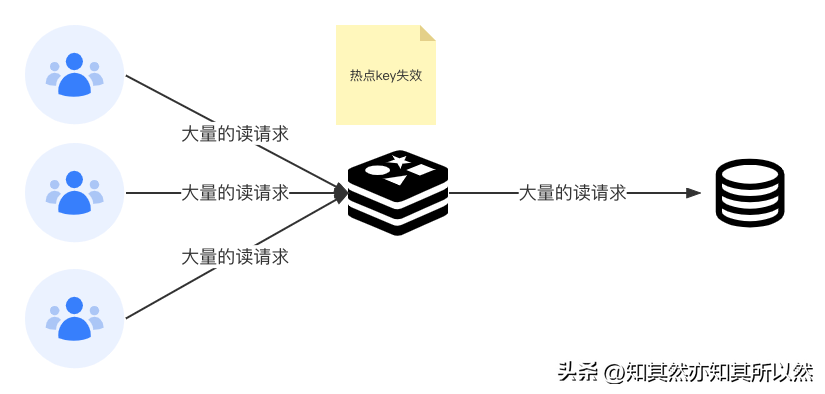
方案一:永不過期
提前把熱點數據不設置過期時間,后臺異步更新緩存。
但是!我又要說但是了!我現在舉個例子,就要推翻這個方案了,打自己的臉。
我們自家的甲秀寶商城最近3月8日女神節做一次大促,把運營童鞋收集整理的關于女性熱點商品都做了永不過期,但是大促當天發現面巾紙是賣的最多的,差點就要祭天了……
所以,真實場景是就像你根本無法知道女朋友想什么一樣,同理你也不能真正的預估到客戶想買什么,哪個是熱點商品,所以,這個方案也就是面試吹吹……
方案二:加互斥鎖或隊列
其實我理解緩存擊穿和緩存穿透差不多,所以加一個互斥鎖,讓一個線程正常請求數據庫,其他線程等待即可(這里可以使用線程池來處理),都創建完緩存,讓其他線程請求緩存即可。
緩存雪崩
緩存雪崩(Cache Avalanche)指的是當某一個時刻出現大規模的緩存失效,然后大量的請求直接訪問到數據庫,以至于壓垮數據庫,造成系統崩潰等情況。
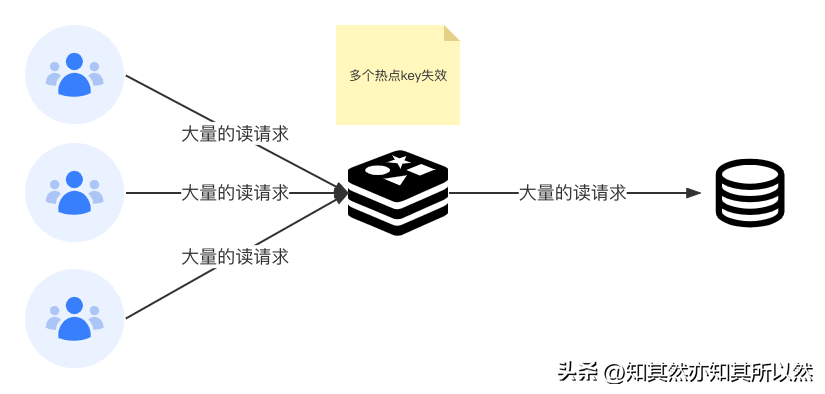
出現這種情況的可能有兩種:
- 緩存采用相同的過期時間。
- 緩存服務出現故障。
方案一:相對隨機數過期時間
key的過期時間加上一個隨機值,保證不是同一時間失效,即可。
方案二:分布式集群部署
單節點緩存服務容易宕機,那我們就部署個集群,然后把緩存均勻的分不到不同的服務器上,搞定。
方案三:服務限流、熔斷、降級
當流量到一定的閾值或者服務出現異常、故障時,直接返回“請稍后再試”的友好性處理,讓一部分用戶正常使用,其他用戶多重試幾次,不過這樣難免會降低用戶體驗,不過幾個人有問題也總比整個系統崩潰好~
END
緩存穿透、緩存擊穿、緩存雪崩,說白了核心就是“避免無效(或重復)的請求”到數據庫,所以我覺得只要是以這個思想去設計都是ok的~