













處理缺失值的三個層級的方法總結(jié)
缺失值
缺失值是現(xiàn)實數(shù)據(jù)集中的常見問題,處理缺失值是數(shù)據(jù)預(yù)處理的關(guān)鍵步驟。缺失值可能由于各種原因而發(fā)生,例如數(shù)據(jù)的結(jié)構(gòu)和質(zhì)量、數(shù)據(jù)輸入錯誤、傳輸過程中的數(shù)據(jù)丟失或不完整的數(shù)據(jù)收集。這些缺失的值可能會影響機器學(xué)習(xí)模型的準(zhǔn)確性和可靠性,因為它們可能會引入偏差并扭曲結(jié)果,有些模型甚至在在缺少值的情況下根本無法工作。所以在構(gòu)建模型之前,適當(dāng)?shù)靥幚砣笔е凳潜匾摹?/p>

本文將展示如何使用三種不同級別的方法處理這些缺失值:
- 初級:刪除,均值/中值插補,使用領(lǐng)域知識進行估計
- 中級:回歸插補, K-Nearest neighbors (KNN) 插補
- 高級:鏈?zhǔn)椒匠?MICE)的多元插補, MICEforest
檢查缺失的值
首先必須檢查每個特性中有多少缺失值。作為探索性數(shù)據(jù)分析的一部分,我們可以使用以下代碼來做到這一點:
導(dǎo)入pandas并在數(shù)據(jù)集中讀取它們,對于下面的示例,我們將使用葡萄酒質(zhì)量數(shù)據(jù)集。
然后可以用下面的代碼行檢查缺失的值。
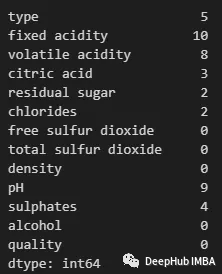
可以使用以下方法查看任何特性中包含缺失值的行:

現(xiàn)在我們可以開始處理這些缺失的值了。
初級方法
最簡單的方法是刪除行或列(特性)。這通常是在缺失值的百分比非常大或缺失值對分析或結(jié)果沒有顯著影響時進行的。
刪除缺少值的行。

使用以下方法刪除列或特性:
通過刪除行,我們最終得到一個更短的數(shù)據(jù)集。當(dāng)刪除特征時,我們最終會得到一個完整的數(shù)據(jù)集,但會丟失某些特征。

這兩種方法都最直接的方法,而且都會導(dǎo)致丟失有價值的數(shù)據(jù)——所以一般情況下不建議使用。
均值/中值插補
下一個初級的方法是用特征的平均值或中值替換缺失的值。在這種情況下不會丟失特征或行。但是這種方法只能用于數(shù)值特征(如果使用平均值,我們應(yīng)該確保數(shù)據(jù)集沒有傾斜或包含重要的異常值)。
比如下面用均值來計算缺失值:
現(xiàn)在讓我們檢查其中一個估算值:

如果要用中值,可以使用:

可以看到這里中值和平均值還是有區(qū)別的。
眾數(shù)
與上面的方法一樣,該方法用特征的模式或最常見的值替換缺失的值。這種方法可以用于分類特征。
首先,讓我們檢查一下是否有一個類別占主導(dǎo)地位。我們可以通過value_counts方法來實現(xiàn):
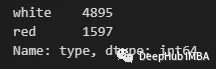
可以看到有一個“白色”數(shù)量最多。因此可以用下面的方式進行填充:
Scikit-Learn的SimpleImputer類
也可以使用Scikit-learn的SimpleImputer類執(zhí)行平均值、中值和眾數(shù)的插補。將策略設(shè)置為“mean”,“median”或“most_frequency”即可
我們也可以將策略設(shè)置為' constant ',并指定' fill_value '來填充一個常量值。
均值/中位數(shù)/眾數(shù)的優(yōu)點:
- 簡單和快速實現(xiàn)
- 它保留了樣本量,并降低了下游分析(如機器學(xué)習(xí)模型)的偏差風(fēng)險。
- 與更復(fù)雜的方法相比,它的計算成本更低。
缺點:
- 沒有說明數(shù)據(jù)的可變性或分布,可能會導(dǎo)致估算值不能代表真實值。
- 可能會低估或高估缺失值,特別是在具有極端值或異常值的數(shù)據(jù)集中。
- 減少方差和人為夸大相關(guān)系數(shù)在估算數(shù)據(jù)集。
- 它假設(shè)缺失的值是完全隨機缺失(MCAR),這可能并不總是這樣
使用領(lǐng)域知識進行評估
處理缺失數(shù)據(jù)的另一種可能方法是使用基于領(lǐng)域知識或業(yè)務(wù)規(guī)則的估計來替換缺失的值。可以通過咨詢相關(guān)領(lǐng)域的專家,讓他們提供專業(yè)的見解,這樣能夠估算出合理和可信的缺失值。
但是這種方法并不一定在現(xiàn)實中就能夠很好的實施,因為我們需要專業(yè)的人士來確保它產(chǎn)生準(zhǔn)確和可靠的估算,但是這樣的領(lǐng)域?qū)<也⒉欢唷K晕覀冞@里把它歸在初級方法中。
中級方法
還有一些稍微高級一些的技術(shù)來填充那些缺失的值,我們將使用預(yù)測模型來解決問題。但在此之前需要更好地理解缺失值的性質(zhì)。
缺失值的類型
在我們繼續(xù)使用更高級的技術(shù)之前,需要考慮一下在數(shù)據(jù)集中可能遇到的缺失類型。數(shù)據(jù)集中有不同類型的缺失,了解缺失類型有助于確定合適的方法。以下是一些常見的類型:
完全隨機缺失( Missing Completely at Random):在這種類型中,缺失的值是完全隨機的,這意味著一個值缺失的概率不依賴于任何觀察到的或未觀察到的變量。例如,如果一個受訪者在調(diào)查中不小心跳過了一個問題,這就是MCAR。
隨機丟失(Missing at Random):在這種類型中,一個值缺失的概率取決于觀察到的變量,而不是值本身。例如,如果調(diào)查對象不太可能回答敏感問題,但不回答問題的傾向取決于可觀察到的變量(如年齡、性別和教育),那么這就是MAR。
非隨機丟失(Missing Not at Random):在這種類型中,一個值缺失的概率取決于未觀察到的變量,包括缺失值值本身。例如,如果抑郁程度較高的個體不太可能報告他們的抑郁水平,而不報告的傾向在數(shù)據(jù)中是無法觀察到的,那么這就是MNAR。
回歸插補
我們將使用一個回歸模型來對那些缺失的值進行有根據(jù)的猜測,通過分析數(shù)據(jù)集中的其他特征,并使用它們的相關(guān)性來填補。
在處理遵循某種模式(MAR或MCAR)的缺失數(shù)據(jù)時,回歸插補特別有用。因為當(dāng)特征之間存在很強的相關(guān)性時,這種方法很有效。
我們這里將創(chuàng)建一個不包含分類特征的數(shù)據(jù)版本。然后以為每一列的缺失值擬合線性回歸模型。這里就需要使用Scikit-learn的線性回歸模塊。

回歸插補的優(yōu)點:
- 可以處理大量缺失值。
- 可以保留數(shù)據(jù)集的統(tǒng)計屬性,例如均值、方差和相關(guān)系數(shù)。
- 可以通過減少偏差和增加樣本量來提高下游分析(例如機器學(xué)習(xí)模型)的準(zhǔn)確性。
回歸插補的缺點:
- 它假設(shè)缺失變量和觀察到的變量之間存在線性關(guān)系。
- 如果缺失值不是隨機缺失 (MAR) 或完全隨機缺失 (MCAR),則可能會引入偏差。
- 可能不適用于分類或有序變量。
- 在計算上昂貴且耗時,尤其是對于大型數(shù)據(jù)集。
(KNN) 插補
另一種方法是聚類模型,例如K-最近鄰 (KNN) 來估計那些缺失值。這與回歸插補類似,只是使用不同的算法來預(yù)測缺失值。

這里我們就要介紹一個包fancyimpute,它包含了各種插補方法:
使用的方法如下:
KNN 插補的優(yōu)點:
- 可以捕獲變量之間復(fù)雜的非線性關(guān)系。
- 不對數(shù)據(jù)的分布或變量之間的相關(guān)性做出假設(shè)。
- 比簡單的插補方法(例如均值或中值插補)更準(zhǔn)確,尤其是對于中小型數(shù)據(jù)集。
缺點:
- 計算上可能很昂貴,尤其是對于大型數(shù)據(jù)集或高維數(shù)據(jù)。
- 可能對距離度量的選擇和選擇的最近鄰居的數(shù)量敏感,這會影響準(zhǔn)確性。
- 對于高度傾斜或稀疏的數(shù)據(jù)表現(xiàn)不佳。
高級方法
通過鏈?zhǔn)椒匠?(MICE) 進行多元插補
MICE 是一種常用的估算缺失數(shù)據(jù)的方法。它的工作原理是將每個缺失值替換為一組基于模型的合理值,該模型考慮了數(shù)據(jù)集中變量之間的關(guān)系。
該算法首先根據(jù)其他完整的變量為數(shù)據(jù)集中的每個變量創(chuàng)建一個預(yù)測模型。然后使用相應(yīng)的預(yù)測模型估算每個變量的缺失值。這個過程重復(fù)多次,每一輪插補都使用前一輪的插補值,就好像它們是真的一樣,直到達到收斂為止。
然后將多個估算數(shù)據(jù)集組合起來創(chuàng)建一個最終數(shù)據(jù)集,其中包含所有缺失數(shù)據(jù)的估算值。MICE 是一種強大而靈活的方法,可以處理具有許多缺失值和變量之間復(fù)雜關(guān)系的數(shù)據(jù)集。它已成為許多領(lǐng)域(包括社會科學(xué)、健康研究和環(huán)境科學(xué))中填補缺失數(shù)據(jù)的流行選擇。
fancyimpute包就包含了這個方法的實現(xiàn),我們可以直接拿來使用
這個實現(xiàn)沒法對分類變量進行填充,那么對于分類變量怎么辦呢?
MICEforest
MICEforest 是 MICE的變體,它使用 lightGBM 算法來插補數(shù)據(jù)集中的缺失值,這是一個很奇特的想法,對吧。
我們可以使用 miceforest 包來實現(xiàn)它
使用也很簡單:
可以看到,分類變量 'type' 的缺失值已經(jīng)被填充了
總結(jié)
我們這里介紹了三個層級的缺失值的處理方法,這三種方法的選擇將取決于數(shù)據(jù)集、缺失數(shù)據(jù)的數(shù)量和分析目標(biāo)。也需要仔細考慮輸入缺失數(shù)據(jù)對最終結(jié)果的潛在影響。處理缺失數(shù)據(jù)是數(shù)據(jù)分析中的關(guān)鍵步驟,使用合適的填充方法可以幫助我們解鎖隱藏在數(shù)據(jù)中的見解,而從主題專家那里尋求輸入并評估輸入數(shù)據(jù)的質(zhì)量有助于確保后續(xù)分析的有效性。
最后我們介紹的兩個python包的地址,有興趣的可以看看:
https://pypi.org/project/fancyimpute/
https://pypi.org/project/miceforest/















