













現(xiàn)在面試都不滿足于問進(jìn)程線程,開始問起協(xié)程了?
用 Go 語言的小伙伴對(duì)協(xié)程應(yīng)該都非常熟悉了,而 Java 直到 2022 年 9 月 20 日,JDK19 才終于提供了協(xié)程(官方說法是 Virtual Thread 虛擬線程,不過看介紹就是協(xié)程 Coroutine)的測(cè)試版本功能。
在 Java 中,我們一直依賴線程作為并發(fā)服務(wù)器應(yīng)用程序的構(gòu)建基礎(chǔ)。每個(gè)方法中的每個(gè)語句都在線程內(nèi)執(zhí)行,并且每個(gè)線程都提供一個(gè)堆棧來存儲(chǔ)局部變量和協(xié)調(diào)方法調(diào)用,以及出錯(cuò)時(shí)的上下文,開發(fā)人員可以使用線程的堆棧來跟蹤程序的具體執(zhí)行過程。
以下參考 OpenJDK 官方文檔:https://openjdk.org/jeps/425
Thread-Per-Request
Thread-Per-Request,翻譯過來就是一個(gè)請(qǐng)求一個(gè)線程。服務(wù)器應(yīng)用程序通常處理相互獨(dú)立的并發(fā)用戶請(qǐng)求,因此應(yīng)用程序通過在某個(gè)請(qǐng)求的持續(xù)時(shí)間內(nèi)將一個(gè)線程專門用于處理這個(gè)請(qǐng)求是非常有意義且必要的。這種 thread-per-request 風(fēng)格易于理解、易于編程、易于調(diào)試和分析,因?yàn)樗褂闷脚_(tái)的并發(fā)單元來表示應(yīng)用程序的線程數(shù)量,比如你有 100 個(gè)并發(fā)請(qǐng)求,那就對(duì)應(yīng) 100 個(gè)線程。
但是,服務(wù)器應(yīng)用程序的可伸縮性受 Little 定律支配,它與延遲、并發(fā)性和吞吐量相關(guān),這里我簡(jiǎn)單介紹下 Little 定律,不是什么重點(diǎn)知識(shí),大伙兒隨便看下就行:
Little 定律是由 John Little 在 1961 年提出的,在一個(gè)具有穩(wěn)定流量和容量的隊(duì)列中,平均用戶數(shù)等于平均流量和平均服務(wù)時(shí)間的乘積。
具體來說,假設(shè)我們有一個(gè)隊(duì)列,它有一定的容量,同時(shí)有一定的流量在進(jìn)出隊(duì)列。如果我們令隊(duì)列中平均用戶數(shù)為 L,平均流量為 λ,平均服務(wù)時(shí)間為 W,則 Little 定律可以表示為:
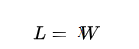
這個(gè)定律適用于任何類型的任務(wù),包括服務(wù)請(qǐng)求、進(jìn)程、線程、作業(yè)、數(shù)據(jù)包等等。它可以用來預(yù)測(cè)系統(tǒng)的吞吐量、延遲和并發(fā)性,并且在系統(tǒng)設(shè)計(jì)和性能優(yōu)化中非常有用。
- 所謂平均服務(wù)時(shí)間 W -> 其實(shí)就是請(qǐng)求處理的時(shí)間
- 平均用戶數(shù) L -> 就是同時(shí)處理的請(qǐng)求數(shù)量
- 平均流量 λ -> 就是吞吐量
如果我們想要在平均服務(wù)時(shí)間 W(請(qǐng)求處理時(shí)間)不變的情況下,增大平均流量 λ(吞吐量),那么平均用戶數(shù)(L)勢(shì)必要同比例增長(zhǎng),換句話說,對(duì)于給定的請(qǐng)求處理持續(xù)時(shí)間(即延遲),應(yīng)用程序同時(shí)處理的請(qǐng)求數(shù)(即并發(fā)性)必須與吞吐量成比例增長(zhǎng)。
例如,假設(shè)一個(gè)平均延遲為 50ms(W = 0.05) 的應(yīng)用程序通過并發(fā)處理 10 個(gè)請(qǐng)求(L = 10)來實(shí)現(xiàn)每秒 200 個(gè)請(qǐng)求的吞吐量(λ = 200)。為了使該應(yīng)用程序擴(kuò)展到每秒 2000 個(gè)請(qǐng)求的吞吐量(λ = 2000),它需要并發(fā)處理 100 個(gè)請(qǐng)求(L = 100)。
如果每個(gè)請(qǐng)求都需要一個(gè)單獨(dú)的線程進(jìn)行處理,那么隨著吞吐量的增加,線程數(shù)量將會(huì)急劇增加。
不幸的是,可用線程的數(shù)量是有限的,因?yàn)?JDK 線程的本質(zhì)其實(shí)是操作系統(tǒng)線程,詳細(xì)可看下這篇文章 Java 線程和操作系統(tǒng)的線程有啥區(qū)別?,而操作系統(tǒng)線程成本很高,所以我們不可能擁有太多線程,這使得 Thread-Per-Request 風(fēng)格難以實(shí)現(xiàn)。如果每個(gè)請(qǐng)求在其持續(xù)時(shí)間內(nèi)消耗一個(gè) Java 線程,并因此消耗一個(gè)操作系統(tǒng)線程,那么在其他資源(例如 CPU 或網(wǎng)絡(luò)連接)耗盡之前,線程的數(shù)量必定會(huì)成為性能限制的重要因素,所以 JDK 當(dāng)前的線程實(shí)現(xiàn)使得應(yīng)用程序的吞吐量被限制在遠(yuǎn)低于硬件可以支持的水平,有同學(xué)可能會(huì)說不是有線程池嗎?即使線程被池化也會(huì)發(fā)生這種情況,因?yàn)槌鼗m然有助于避免啟動(dòng)新線程的高成本,但并不會(huì)增加線程總數(shù)。
使用異步
為了充分利用硬件,開發(fā)者們放棄了 Thread-Per-Request 的風(fēng)格,轉(zhuǎn)而采用線程共享(Thread-Sharing)。不是在一個(gè)線程上從頭到尾處理一整個(gè)請(qǐng)求,而是在等待 I/O 操作完成時(shí)將該線程返回到線程池中,以便該線程可以為其他請(qǐng)求提供服務(wù), I/O 操作完成后再利用回調(diào)函數(shù)進(jìn)行通知。
通俗來說,在異步風(fēng)格中,請(qǐng)求的每個(gè)階段可能在不同的線程上執(zhí)行,并且每個(gè)線程以交錯(cuò)的方式運(yùn)行屬于不同請(qǐng)求的階段。這種細(xì)粒度的線程共享允許大量并發(fā)操作而不會(huì)消耗大量線程,消除了操作系統(tǒng)線程稀缺對(duì)吞吐量的限制。
舉個(gè)例子,假設(shè)有一個(gè)網(wǎng)絡(luò)服務(wù)器程序,需要處理來自客戶端的請(qǐng)求并進(jìn)行數(shù)據(jù)庫(kù)查詢,然后將結(jié)果返回給客戶端。如果使用傳統(tǒng)的線程池來處理請(qǐng)求,每當(dāng)有一個(gè)請(qǐng)求到來時(shí),就需要從線程池中取出一個(gè)線程進(jìn)行處理。但是在請(qǐng)求過程中,當(dāng)線程需要等待數(shù)據(jù)庫(kù)查詢結(jié)果時(shí),它就會(huì)被阻塞,無法進(jìn)行其他的請(qǐng)求處理,浪費(fèi)了一個(gè)線程資源。如果使用異步 IO 操作,當(dāng)線程需要進(jìn)行數(shù)據(jù)庫(kù)查詢時(shí),它可以將這個(gè)線程釋放給線程池中的其他請(qǐng)求,等到數(shù)據(jù)庫(kù)查詢完成后,再將線程恢復(fù)執(zhí)行,將查詢結(jié)果返回給客戶端。這樣,一個(gè)線程就可以處理多個(gè)請(qǐng)求,從而提高并發(fā)能力。
但是由于不是一個(gè)線程處理一整個(gè)請(qǐng)求,這就導(dǎo)致我們必須將請(qǐng)求處理邏輯分解為小階段,通常編寫為 lambda 表達(dá)式,然后使用 API 將它們組合成一個(gè)順序管道(比如 CompletableFuture)。
如果實(shí)際用過 lambda 表達(dá)式的同學(xué)肯定會(huì)深有感觸,這簡(jiǎn)直是對(duì) Debug 的災(zāi)難性打擊:
- 堆棧跟蹤不提供可用的上下文
- 調(diào)試器無法單步執(zhí)行請(qǐng)求處理邏輯
- 分析器無法將操作的成本與其調(diào)用者相關(guān)聯(lián)
并且,從另一個(gè)角度來說,這種編程風(fēng)格與 Java 平臺(tái)不一致,因?yàn)閼?yīng)用程序的并發(fā)單元(異步管道)不再是平臺(tái)的并發(fā)單元(簡(jiǎn)單來說就是 100 個(gè)并發(fā)請(qǐng)求不是對(duì)應(yīng) 100 個(gè)線程了,可能就對(duì)應(yīng) 10 個(gè)線程)。
使用協(xié)程
除開上述兩種編程風(fēng)格的缺點(diǎn)考慮,使用進(jìn)程/線程模型還有一個(gè)不容忽視的弊端,那就是上下文切換的開銷。而協(xié)程的上下文切換代價(jià)較小,其優(yōu)勢(shì)在于可以將一個(gè)線程切換為多個(gè)協(xié)程,每個(gè)協(xié)程之間可以輕松地進(jìn)行切換,從而提高應(yīng)用程序的吞吐量。
舉個(gè)例子,我們只需要啟動(dòng) 100 個(gè)線程,每個(gè)線程上運(yùn)行 100 個(gè)協(xié)程,這樣不僅減少了線程切換開銷,而且還能夠同時(shí)處理 100 * 100 = 10000 個(gè)請(qǐng)求。
所以什么是協(xié)程(Coroutine)?
- 協(xié)程是一種運(yùn)行在線程之上的「用戶態(tài)」模型,也稱為纖程(Fiber),協(xié)程并沒有增加線程數(shù)量,只是在線程的基礎(chǔ)之上通過分時(shí)復(fù)用(并發(fā))的方式運(yùn)行多個(gè)協(xié)程。
- 協(xié)程的切換在用戶態(tài)完成(完全由用戶控制,這一點(diǎn)就顯著區(qū)別于進(jìn)程/線程模型),它是一種非搶占式的調(diào)度方式,當(dāng)一個(gè)協(xié)程執(zhí)行完成后,可以選擇主動(dòng)讓出,讓另一個(gè)協(xié)程運(yùn)行在當(dāng)前線程之上。協(xié)程擁有自己的寄存器上下文和棧,協(xié)程調(diào)度切換時(shí),將寄存器上下文和棧保存到線程的堆區(qū),在切回來的時(shí)候,恢復(fù)先前保存的寄存器上下文和棧,直接操作棧則基本沒有內(nèi)核切換的開銷,可以不加鎖的訪問全局變量,所以上下文的切換非常快,比線程從用戶態(tài)到內(nèi)核態(tài)的代價(jià)小很多,

分析下協(xié)程相對(duì)于進(jìn)程/線程的好處:
- 輕量性:協(xié)程只需要保存少量的上下文信息,占用的資源更少,可以創(chuàng)建更多的協(xié)程。相比之下,線程/進(jìn)程需要占用較大的內(nèi)核資源,創(chuàng)建線程的開銷也更大。
- 高效性:協(xié)程切換不需要內(nèi)核態(tài)/用戶態(tài)切換,可以在用戶態(tài)直接切換上下文,速度更快。
- 靈活性:協(xié)程的切換由程序員主動(dòng)控制,可以靈活地在不同協(xié)程之間切換,實(shí)現(xiàn)并發(fā)執(zhí)行。而線程/進(jìn)程的切換由操作系統(tǒng)內(nèi)核進(jìn)行調(diào)度,限制了并發(fā)度和靈活性。
- 可維護(hù)性:由于協(xié)程是在代碼層面進(jìn)行控制,可以更容易地編寫和維護(hù)。而線程之間的同步和共享資源需要復(fù)雜的鎖機(jī)制和線程間通信。
使用協(xié)程的注意事項(xiàng)
協(xié)程運(yùn)行在線程之上,所以必然受到線程的限制。
如果協(xié)程調(diào)用了一個(gè)阻塞 IO 操作,由于操作系統(tǒng)并不知道協(xié)程的存在(因?yàn)閰f(xié)程運(yùn)行在用戶態(tài)),它只知道線程,因此在協(xié)程調(diào)用阻塞 IO 操作的時(shí)候,操作系統(tǒng)會(huì)讓協(xié)程之上對(duì)應(yīng)的線程陷入阻塞狀態(tài),也就是說當(dāng)前的協(xié)程和其它綁定在該線程之上的協(xié)程都會(huì)陷入阻塞而得不到調(diào)度。
因此在協(xié)程中要么就別調(diào)用導(dǎo)致線程阻塞的操作,要么就采用異步編程的方式。





















