沒看錯!一行Python代碼就可以幫您獲取圖片中的文字信息
最近工作中有需求需要用python對圖片中的文字進行識別,調研了一下,選擇了tesseract,
目前在github上有50.5k個star!python可以調用,安裝也十分方便,pip install pytesseract 即可。如果沒有Pillow 包,還需要執行pip install Pillow。
核心代碼
讀取圖片中文字信息的核心api如下:
from PIL import Image
import pytesseract
captcha_text = pytesseract.image_to_string(Image.open("d:/tmp/img4.png"), lang='chi_sim')
print(captcha_text)上面這段代碼中需要解釋的是如果圖片中有中文字符則需要添加參數lang='chi_sim',并在安裝的過程中添加識別中文的字符庫,后面會講到!
運行代碼遇到的問題
直接運行上面的代碼,會遇到下面的問題
raise TesseractNotFoundError()
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.我們來分析一下這個錯誤!錯誤提示tesseract沒有安裝,但是我們明明已經執行了pip install pytesseract,那么問題會出在哪里呢?
我們需要先了解一下pytesseract,它是一款用于光學字符識別(OCR)的python工具,即從圖片中識別出和“讀取”其中嵌入的文字,底層使用的是Google的Tesseract-OCR 引擎,pytesseract只是對Tesseract-OCR的一層封裝!看到這里我們就能夠理解 ,運行python代碼
pytesseract.image_to_string() 報錯的原因了!因為我的PC上并沒有安裝Tesseract-OCR,pytesseract是無法調用Tesseract-OCR的api為我們干活的!
安裝Tesseract-OC
Tesseract-OCR windows 版本的下載鏈接如下:https://github.com/UB-Mannheim/tesseract/wiki
下載成功后,只需默認安裝,在安裝的過程中,如果想對其他國家語言文字識別可以選擇相對應的語言包,如下圖
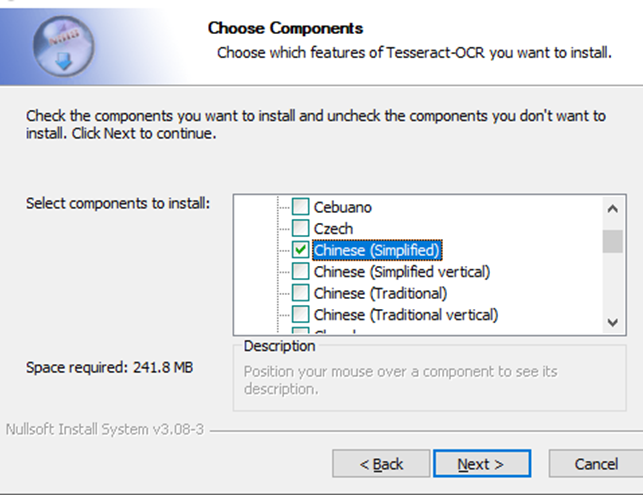
安裝成功后配置路徑 C:\Program Files\Tesseract-OCR 到環境變量中即可。
再次運行,正常執行!大家可以自己做一張文字圖片的截圖查看效果。
復雜的登錄校驗碼無法識別
另外我測試了Tesseract-OCR對復雜校驗碼的識別情況,如下圖:

結論是:復雜的校驗碼仍然無法識別。