上線3年0故障,混合云下的數據庫中間件建設

講師介紹
林靜,現任貨拉拉核心基礎設施技術專家、數據庫中間件團隊負責人,對數據庫中間件研發有深刻的理解和豐富的實戰經驗;曾任摩托羅拉子公司UniqueSoft的Java專家,主導自動逆向工程系統Java方向研發;曾任阿里本地生活中間件技術專家,負責DAL中間件的研發,同時負責多活體系中全局控制中心和數據層的建設。
分享概要
一、混合云自建數據庫中間件背景介紹
二、混合云自建數據庫中間件實踐
三、混合云自建數據庫中間件展望
四、混合云自建數據庫中間件思考
一、混合云自建數據庫中間件背景介紹
貨拉拉是一家業務分布國內海內外多個國家和地區的互聯網企業,在不同的地區,我們會根據當地的情況,選擇合適的云商。因此我們的基礎就是一個多云多數據中心的架構。
1、問題與挑戰

隨著業務的不斷發展,數據的總量不斷膨脹,同時業務線也在不斷增多。這給數據庫帶來了巨大的壓力,因為它們需要處理海量的數據,并保持高性能和穩定性。
此外,我們的技術底層也在不斷演進,新老服務也在不斷交替。這就要求我們的數據層架構能夠適應多語言異構的環境,同時具備高度的可擴展性和可維護性。
在混合云背景下,這些挑戰變得更加復雜。因為混合云意味著我們的架構設計必須具有跨云特性,需要能適配不同的云環境,不依賴特定的云廠商的獨有產品。從業務研發視角看,就是統一的解決方案,不需要重復開發的代碼來適配底層環境。
2、歷史HLL服務架構
我們先來看一下曾經的架構。

1)業務層存在多語言技術棧并存,技術適配困難的問題。技術棧眾多,本身不是問題,問題在于缺乏統一的維護,當需要做公司級別的改造時,需要各個業務團隊只能各自為政,不能形成有效的合力。
2)基礎中間件很多時候還停留在部署起來能跑的程度。缺乏長效的治理,比如apollo這種配置中心就部署了多套,各個業務團隊各自維護一份配置數據,關鍵數據散落各處沒法管理。
3)數據庫中間件其實也是這種情況。本身無論是“SmartCLient”方式也好,“Proxy”方式也好,都是比較優秀的開源解決方案。問題在于缺乏系統性的建設,沒有完整的監控報警,沒有相應的故障應急,沒有自動化運維,不能滿足企業對高可用和可運維的訴求。
4)DB層客觀存在的云商差異讓運維工作復雜度倍增。
總的來說,當時的整體架構處于勉強能夠應對業務訴求的程度,但在穩定性和可運維性上存在不足。
二、混合云自建數據庫中間件實踐
1、HLL數據層架構
我們再來看當前的技術架構。當前的HLL架構已經補齊了大部分的中間件。

接入層包含了開源的統一流量網關KONG,自研服務化網關LAPIGateway,自建安全網關WAF,商用高防網關等組件。
基礎框架方面,建設了基礎框架JAF,微服務框架HLL-SOA,任務系統LLjob,監控報警系統HLL-Monitor等模塊。
變化最大的其實是數據庫中間件的部分。我們通過自建數據庫中間件DBProxy統一了這一層的標準:
- 異構proxy架構,實現了對上層開發語言的兼容;
- 集成HLL體系,集成了HLL的DMS,LLMonitor,配置中心,注冊中心等基礎組件,讓數據庫中間件不再是數據孤島,和各個組件形成合力;
- 跨云適配 + 場景化分庫分表,讓DBProxy能夠屏蔽底層差異,給業務服務提供一致的體驗。幫助業務服務高效安全的從歷史存留各種數據庫中間件遷移到DBProxy上來;
- 高可用設計,讓DBProxy本身不會成為系統的弱點;
- 高性能架構,讓DBProxy擁有超過同類的產品的性能表現;
- DB穩定性保障,讓DBProxy能夠滿足各個云臺下rds通用的穩定性訴求;
- 企業級的可運維性,是DBProxy能夠解決歷史遺留問題的核心。我們有嚴格的開發流程,全面的應急預案,完善的監控報警體系,自動化的管理運維手段。
隨著自建數據中間件的落地,讓HLL的系統的穩定性和可運維性都獲得了巨大的提升。
2、為什么選擇自建

選擇自建數據庫中間件,是混合云背景下的必然選擇。
大廠目前普遍都有自己的數據庫中間件,經歷過大廠復雜業務場景考驗,無論是功能還是穩定性都值得信賴。可惜就是不開源,而開源出來的產品和內部線上產品往往有代差。
云產品是我們比較理想的選擇,上線快、穩定性好、功能成熟,但不能做到跨云通用,不符合我們“跨云通用”的基本訴求。
開源產品幫助我們解決了許多問題。無論是功能豐富的開源產品,還是友好的開源社區,都讓我們在系統演化的道路上受益匪淺。伴隨著企業的發展,我們對產品提出了更多定制化的需求,而這些肯定是不能通過開源產品實現的。
因此我們選擇了自建數據庫中間件這條道路。
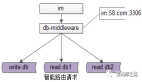
3、數據庫中間件架構
HLL數據庫中間件的架構還是比較簡單的,我們由下往上看:

1)技術棧:
- 采用Java技術棧,為了保證GC停頓時間盡量短,使用了ZGC這種低停頓垃圾回收方式;
- 采用了異步網絡框架 Netty,保證系統對高并發的支持;
- 采用了事件異步驅動編程模型,保證了系統的高可用和高性能;
- 采用異構Proxy架構,保證了對多語言的兼容。
2)可運維性(“平滑”是最主要的關鍵詞):
- 平滑升級,連接預熱,快啟動,慢退出,連接平滑釋放等細節來達成變更平滑、管理平滑、運維平滑;
- 監控報警,是一個系統長期穩定的關鍵之一。在越早的階段發現問題,問題的影響就越小,而監控報警是發現識別問題的關鍵。監控報警既要全面,又要準確,必須有一個持續收斂保鮮的過程才能保證它的有效。
3)高可用設計(體現在方方面面):
- 分集群部署,是解決不同業務對資源有不同側重的問題;
- 擁塞設計是非常重要的。假設一條SQL返回100個G的結果,如果沒有合理的擁塞機制,輕易就能撐爆DBProxy的內存。所以必須有合理的擁塞機制,DBProxy要盡快把數據吐到客戶端,要像TCP滑動窗口一樣,根據客戶端的數據接收能力,對數據流速作出調整;
- 線程收斂是DBProxy性能保障的核心之一,一旦線程數過多,額外的內存和CPU開銷就會增多。同時很多框架機制都是和線程數相關的,比如ZGC在線程數增多的時候,效果就會變差。
4)功能特性比較多,我們挑幾個來簡單聊一聊:
- 限流:我們的限流采用的是限制DB并發數的令牌桶算法。為什么不是采用更好理解的QPS或者連接數限制呢?主要因為這兩個維度在不同的SQL應用場景下數值差距太大,需要付出非常大的運維成本。而基于DB核數設定并發數的動態限流,更符合數據庫領域的特征。
- 動態index hint注入:這個功能解決的是,SQL由于數據量變化等原因沒有走到合理的索引,變異成慢SQL的問題。在業務高峰的時候直接在DB上加索引,或者改業務SQL是不現實的。通過DBProxy,可以動態給SQL添加index hint,等過了業務高峰期,再常規修復是非常安全高效的做法。
- ShardingMapingKey:這個功能是為滿足Sharding表的額外映射訴求。比如有一張表包含兩個唯一ID,根據其中一個ID做分庫分表后,用另一ID查數據就只能全分片掃,才能找到對應的數據,這可能導致上千倍的讀放大。ShardingMapingKey能自動維護一張Mapping表,來管理兩個ID的映射關系,這樣就避免全分片掃的問題。
總的來說,沒有什么出人意料的技術技巧,有的只是為了滿足業務的訴求,而細細打磨的過程。
4、數據庫中間件建設成果

主要成果是:
- 跨云通用的MySQL水平擴容能力。理論上能夠支持1024倍的擴容,能夠滿足企業未來3-5年的業務發展訴求。
- 跨云通用的MySQL保護能力。能夠阻斷常規的MySQL風險,具備應對各種突發異常的應急能力。
此外,HLL數據庫中間件具備低延遲、高可用、低成本的特性。HLL DBProxy已經上線快3年了,自身一直保持0故障,通過攔截異常SQL,消弭流量沖擊,阻擋連接風暴等能力,為數據庫提供了強有力的保護。
5、數據庫領域還有哪些問題

首先是數據安全問題:過去我們的SQL審計只能由業務研發,在業務邏輯中插入特定代碼實現,存在覆蓋不全、成本高、推進難的問題。
然后是SQL治理問題:由于我們的數據庫全部由云商托管,很多細節不再對DBA和研發暴露。觀察SQL詳情的手段只有類似吞吐量,RT95線這樣的監控報警,不能很好地了解SQL執行的細節,存在SQL治理粒度不夠細,SQL無法追蹤的問題。
還有是SQL預警問題:很多時候,風險SQL只有到了生產并造成一定破壞后,我們才能發現,這個時候已經只能亡羊補牢了。雖然亡羊補牢,為時未晚,但我們更想要防患于未然。
最后是壓測SQL流量失真問題:壓力測試是保障系統容量的核心手段,但在DB領域,我們經常因為測試SQL和線上真實運行的SQL存在差異,而無法有效驗證出數據庫的真實容量,存在容量風險和資源浪費的雙重問題。
6、為什么不直接使用云上SQL治理產品

1)部分云商提供了類似的產品,但價格普遍比較昂貴。由于成本壓力,我們只會開幾天然后盡早關閉,只能應急,不能當作常規手段。
2)在這些領域,不同云商提供的產品服務差別非常大。有的云商提供了非常豐富的相關產品服務,但在另外的云商那里卻是一片空白。跨云差異巨大,完全不能通用。
3)云商提供的能力和我們的實際需求還是存在一些差異,畢竟云服務只會支持通用場景,而不會按照企業的需求做定制。
4)云上產品也不是只要能用就好,還要考慮集成問題,比如研發使用習慣,監控報警,溝通,審計,管控等。
7、基于DBProxy的旁路SQL能力建設

SQL安全審計:基于DBProxy的“SQL安全審計”能力,對業務沒有侵入,隨著DBProxy對業務的全面覆蓋,所有的DB都自動納入了審計范圍。解決了推廣覆蓋難、接入成本高的問題。
SQL深度洞察:基于DBProxy的“SQL深入洞察”能力,不僅收集分析了SQL的執行細節,而且集成了SQL指紋(SQLID)和業務調用的Trace信息,解決了SQL觀察粒度粗、難以追蹤的問題。
SQL線下預警:“SQL深入洞察”能夠在預發環境就識別出風險SQL,解決了問題SQL后知后覺的問題。
SQL流量仿真:“SQL流量仿真”能夠精準還原線上真實SQL流量,保障系統數據庫容量安全,同時避免資源浪費。
8、SQL深度洞察效果圖

這里有兩個主要的應用場景:
- 一個場景是,先看DB整體情況,比如影響行數過多的,RT太長的,可以根據SQLID反溯它的來源。
- 另一個場景是,先通過業務視角發現某條SQL比較反常,可以通過SQLID來查看它的更詳細的情況,比如使用頻率和RT抖動幅度等。
四、混合云自建數據庫中間件思考
1、下一步最直接的挑戰是“多AZ”

“多AZ”架構可以簡單理解為云上的同城多活架構。
云上“多AZ”對比一般自建同城多活,優勢在于成本更低、粒度更靈活。由于基礎設施的部分已經由云商建設好,企業可以有選擇性地落地多AZ架構,比如只有MySQL使用多AZ架構,其他部分保持單AZ。
圖中是一個簡化的三AZ部署案例,每個AZ可以承擔50%的流量。任意一個AZ出問題,系統都能正常工作。
“多AZ”架構還是有門檻的:
- 首先是AZ間的網絡延遲(一般AZ間的延遲在1-10ms)。必須充分地考量業務系統的延遲敏感度,確保業務系統能夠在這種延遲中正常工作。
- 然后是IT成本。在剛才的例子中,我們有三個50%的AZ,假設容量和IT成本成正比,我們起碼需要承擔1.5倍的IT成本。
- 還有一個不能忽視的部分是AZ間的網絡穩定性。AZ間的網絡穩定性是遠不如AZ內部的,如果業務系統自身不夠健壯,網絡一抖就崩潰。那么這種情況下“多AZ”的架構并不會提升系統穩定性,反而會有所降低。
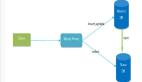
2、當前多AZ高可用架構設計

建設AZ級別的故障轉移能力,對企業來說是十分必要的。我們之前遇到過一次類似的故障:由于第三方的意外操作,機房內部100多個機架斷電,相關服務組件全部故障,系統不可用持續長達1個多小時。假如當時我們的系統具備AZ級別故障轉移能力,這次事故就能完全避免掉。
圖中是一個簡化的多AZ架構設計,采用的是雙AZ對等部署的方式。系統整體沒有額外的IT成本,AZ故障后,利用K8S的彈性能力,在健康的AZ內快速彈出足夠的容量。
而數據庫中間件在“多AZ”架構里是存在不足的:
- 首先是AZ間延遲放大問題。當業務節點和DBProxy不在同一個AZ時,一個SQL請求需要經歷兩次跨AZ延遲,這對系統RT容忍性提出了更高的要求。
- 然后是彈性能力不足問題。我們需要投入額外的IT成本和運維開銷來適配AZ容災場景。
這方面“RedisMesh”已經領先了一步,通過K8S DaemonSet+Sidecar的近客戶端部署架構,規避了中間件放大跨AZ延遲的問題,也解決了彈性問題。
3、未來數據庫中間件的展望

未來我們期望把DBProxy、KafkaGateway這樣的數據層中間件都轉型到sidecar模式,和現有的RedisMesh集成,打造新一代的數據層中間件DataMesh。
DataMesh不僅具備原來數據庫中間件的基礎能力,而且具備遠超當前數據庫中間件的云環境適應性,能夠靈活適配未來復雜多變云上架構。
當然這個過程不是一蹴而就的。
4、混合云數據庫中間件走向何處

對于數據庫中間件前進的方向和節奏,我們是這樣的考慮的。
首先是避免“唯技術”,技術是手段不是目的,不能因為喜歡什么技術就投入進去。
然后“比業務快半步”,就是說基礎技術要像一碗剛做好的面一樣,溫度剛剛好。太晚了不行,不能讓業務餓著了,太早了也不行,面就涼。
最后是“面向云原生”,我們不能試圖去撇開云環境去做什么,而應該更靠近云,讓業務服務更容易享受的云時代的便利。
三、混合云自建數據庫中間件展望
1、無論什么時候穩定性都是第一位

我們的核心工作是為企業帶來穩定性價值和效率價值。穩定性永遠是第一位的。這方面,我們比較信奉海恩法則。
簡單來說,故障的發生是有跡可循的,我們應該通過流程和機制把故障消滅在萌芽狀態。
2、高可用設計有哪些要點

就像前面說的高可用是可以通過建設來達成的。簡單總結下來就是:
- 做最壞的打算,不要有僥幸心理;
- 要解決大部分人的問題,符合大部分人的使用習慣,不要標新立異;
- 不要單打獨斗,借助整個公司基礎設施的力量,形成合力;
- 把好的機制和流程沉淀到工具去。
3、數據庫中間件研發培養

最后跟大家分享一點關于如何培養數據庫中間件研發的想法,培養中間件領域的研發,應該從這三方面入手:領域知識、產品意識、編程技巧。一名優秀的數據庫中間件開發應該同時具備這三方面的能力,三者缺一不可。