一種KV存儲的GC優化實踐

一、背景介紹
當前公司內部沒有統一的KV存儲服務,很多業務都將 Redis 集群當作KV存儲服務在使用,但是部分業務可能不需要 Redis 如此高的性能,卻承擔著巨大的機器資源成本(內存價格相對磁盤來說更加昂貴)。為了降低存儲成本的需求,同時盡可能減少業務遷移的成本,我們基于 TiKV 研發了一套磁盤KV存儲服務。
1.1 架構簡介
以下對這種KV存儲(下稱磁盤KV)的架構進行簡單描述,為后續問題描述做鋪墊。
1.1.1 系統架構
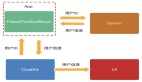
磁盤KV使用目前較流行的計算存儲分離架構,在TiKV集群上層封裝計算層(后稱Tula)模擬Redis集群(對外表現是不同的Tula負責某些slot范圍),直接接入業務Redis客戶端。

圖1:磁盤KV架構圖示
業務寫入數據基于Tula轉換成TiKV中存儲的KV對,基于類似的方式完成業務數據的讀取。
注意:Tula中會選舉出一個leader,用于進行一些后臺任務,后續詳細說。
1.1.2 數據編碼
TiKV對外提供的是一種KV的讀寫功能,但是Redis對外提供的是基于數據結構提供讀寫能力(例如SET,LIST等),因此需要基于TiKV現有提供的能力,將Redis的數據結構進行編碼,并且可以方便地在TiKV中進行讀寫。
TiKV提供的API比較簡單:基于key的讀寫接口,以及基于字典序的迭代器訪問。
因此,Tula層面基于字典序的機制,對Redis的數據結構基于字典序進行編碼,便于訪問。
注意:TiKV的key是可以基于字典序進行遍歷(例如基于某個前綴進行遍歷等),后續的編碼,機制基本是基于字典序的特性進行設計。
為了可以更好地基于字典序排列的搜索特性下對數據進行讀寫,對于復雜的數據結構,我們會使用另外的空間去存放其中的數據(例如SET中的member,HASH中的field)。而對于簡單的數據結構(類似STRING),則可以直接存放到key對應的value中。
為此,我們在編碼設計上,會分為metaKey和dataKey。metaKey是基于用戶直接訪問的key進行編碼,是編碼設計中直接對外的一層;dataKey則是metaKey的存儲指向,用來存放復雜數據結構中的具體內部數據。
另外,為了保證訪問的數據一致性,我們基于TiKV的事務接口進行對key的訪問。
(1)編碼&字段
以下以編碼中的一些概念以及設定,對編碼進行簡述。
key的編碼規則如下:

圖2:key編碼設計圖示
以下對字段進行說明
- namespace
為了方便在一個TiKV集群中可以存放不同的磁盤KV數據,我們在編碼的時候添加了前綴namespace,方便集群基于這個namespace在同一個物理TiKV空間中基于邏輯空間進行分區。 - dbid
因為原生Redis是支持select語句,因此在編碼上需要預留字段表示db的id,方便后續進行db切換(select語句操作)的時候切換,表示不同的db空間。 - role
用于區分是哪種類型的key。
對于簡單的數據結構(例如STRING),只需要直接在key下面存儲對應的value即可。
但是對于一些復雜的數據結構(例如HASH,LIST等),如果在一個value下把所有的元素都存儲了,對與類似SADD等指令的并發,為了保證數據一致性,必然可以預見其性能不足。
因此,磁盤KV在設計的時候把元素數據按照獨立的key做存儲,需要基于一定的規則對元素key進行訪問。這樣會導致在key的編碼上,會存在key的role字段,區分是用戶看到的key(metaKey),還是這種元素的key(dataKey)。
其中,如果是metaKey,role固定是M;如果是dataKey,則是D。 - keyname
在metaKey和dataKey的基礎上,可以基于keyname字段可以較方便地訪問到對應的key。 - suffix
針對dataKey,基于不同的Redis數據結構,都需要不同的dataKey規則進行支持。因此此處需要預留suffix區間給dataKey在編碼的時候預留空間,實現不同的數據類型。
以下基于SET類型的SADD指令,對編碼進行簡單演示:

圖3: SADD指令的編碼設計指令圖示
- 基于userKey,通過metaKey的拼接方式,拼接metaKey并且訪問
- 訪問metaKey獲取value中的
- 基于value中的uuid,生成需要的dataKey
- 寫入生成的dataKey
(2)編碼實戰
編碼實戰中,會以SET類型的實現細節作為例子,描述磁盤KV在實戰中的編碼細節。
在這之前,需要對metaKey的部分實現細節進行了解
(3)metaKey存儲細節
所有的metaKey中都會存儲下列數據。

圖4:metaKey編碼設計圖示
- uuid:每一個metaKey都會有一個對應的uuid,表示這個key的唯一身份。
- create_time:保存該元數據的創建時間
- update_time: 保存該元數據的最近更新時間
- expire_time: 保存過期時間
- data_type: 保存該元數據對應的數據類型,例如SET,HASH,LIST,ZSET等等。
- encode_type: 保存該數據類型的編碼方式
(4)SET實現細節
基于metaKey的存儲內容,以下基于SET類型的數據結構進行講解。
SET類型的dataKey的編碼規則如下:
- keyname:metaKey的uuid
- suffix:SET對應的member字段
因此,SET的dataKey編碼如下:

圖5:SET數據結構dataKey編碼設計圖示
以下把用戶可以訪問到的key稱為user-key。集合中的元素使用member1,member2等標注。
這里,可以梳理出訪問邏輯如下:

圖6:SET數據結構訪問流程圖示
簡述上圖的訪問邏輯:
- 基于user-key拼接出metaKey,讀取metaKey的value中的uuid。
- 基于uuid拼接出dataKey,基于TiKV的字典序遍歷機制獲取uuid下的所有member。
1.1.3 過期&GC設計
對標Redis,目前在user-key層面滿足過期的需求。
因為存在過期的數據,Redis基于過期的hash進行保存。但是如果磁盤KV在一個namespace下使用一個value存放過期的數據,顯然在EXPIRE等指令下存在性能問題。因此,這里會有獨立的編碼支持過期機制。
鑒于過期的數據可能無法及時刪除(例如SET中的元素),對于這類型的數據需要一種GC的機制,把數據完全清空。
(1)編碼設計
針對過期以及GC(后續會在機制中詳細說),需要額外的編碼機制,方便過期和GC機制的查找,處理。
- 過期編碼設計
為了可以方便地找到過期的key(下稱expireKey),基于字典序機制,優先把過期時間的位置排到前面,方便可以更快地得到expireKey。
編碼格式如下:

圖7:expireKey編碼設計圖示
其中:
- expire-key-prefix:標識該key為expireKey,使用固定的字符串標識
- slot:4個字節,標識slot值,對user-key進行hash之后對256取模得到,方便并發掃描的時候線程可以分區掃描,減少同key的事務沖突
- expire-time:標識數據的過期時間
- user-key:方便在遍歷過程中找到user-key,對expireKey做下一步操作
- GC編碼設計
目前除了STRING類型,其他的類型因為如果在一次過期操作中把所有的元素都刪除,可能會存在問題:如果一個user-key下面的元素較多,過期進度較慢,這樣metaKey可能會長期存在,占用空間更大。
因此使用一個GC的key(下稱gcKey)空間,安排其他線程進行掃描和清空。
編碼格式如下:

圖8:gcKey編碼設計圖示
(2)機制描述
基于前面的編碼,可以對Tula內部的過期和GC機制進行簡述。
因為過期和GC都是基于事務接口,為了減少沖突,Tula的leader會進行一些后臺的任務進行過期和GC。
- 過期機制
因為前期已經對過期的user-key進行了slot分開,expireKey天然可以基于并發的線程進行處理,提高效率。

圖9:過期機制處理流程圖示
簡述上圖的過期機制:
- 拉起各個過期作業協程,不同的協程基于分配的slot,拼接協程下的expire-key-prefix,掃描expireKey
- 掃描expireKey,解析得到user-key
- 基于user-key拼接得到metaKey,訪問metaKey的value,得到uuid
- 根據uuid,添加gcKey
- 添加gcKey成功后,刪除metaKey
就目前來說,過期速度較快,而且key的量級也不至于讓磁盤KV存在容量等過大負擔,基于hash的過期機制目前表現良好。
- GC機制
目前的GC機制比較落后:基于當前Tula的namespace的GC前綴(gc-key-prefix),基于uuid進行遍歷,并且刪除對應的dataKey。

圖10:GC機制處理流程圖示
簡述上圖的GC機制:
- 拉起一個GC的協程,掃描gcKey空間
- 解析掃描到的gcKey,可以獲得需要GC的uuid
- 基于uuid,在dataKey的空間中基于字典序,刪除對應uuid下的所有dataKey
因此,GC本來就是在expire之后,會存在一定的滯后性。
并且,當前的GC任務只能單線程操作,目前來說很容易造成GC的遲滯。
1.2 問題描述
1.2.1 問題現象
業務側多次反饋,表示窗口數據(定期刷入重復過期數據)存在的時候,磁盤KV占用的空間特別大。
我們使用工具單獨掃描對應的Tula配置namespace下的GC數據結合,發現確實存在較多的GC數據,包括gcKey,以及對應的dataKey也需要及時進行刪除。
1.2.2成因分析
現網的GC過程速度比不上過期的速度。往往expireKey都已經沒了,但是gcKey很多,并且堆積。
這里的問題點在于:前期的設計中,gcKey的編碼并沒有像expireKey那樣提前進行了hash的操作,全部都是uuid。
如果有一個類似的slot字段可以讓GC可以使用多個協程進行并發訪問,可以更加高效地推進GC的進度,從而達到滿足優化GC速度的目的,窗口數據的場景可以得到較好的處理。
下面結合兩個機制的優劣,分析存在GC堆積的原因。

圖11:GC堆積成因圖示
簡單來說,上圖的流程中:
- 過期的掃描速度以及處理速度很快,expireKey很快及時的被清理并且添加到gcKey中
- GC速度很慢,添加的gcKey無法及時處理和清空
從上圖分析可以知道:如果窗口數據的寫入完全超過的GC的速度的話,必然導致GC的數據不斷堆積,最后導致所有磁盤KV的存儲容量不斷上漲。
二、優化
2.1 目標
分析了原始的GC機制之后,對于GC存在滯后的情況,必然需要進行優化。
如何加速GC成為磁盤KV針對窗口數據場景下的強需求。
但是,畢竟TiKV集群的性能是有上限的,在進行GC的過程也應該照顧好業務請求的表現。
這里就有了優化的基本目標:在不影響業務的正常使用前提下,對盡量減少GC數據堆積,加速GC流程。
2.2.實踐
2.2.1 階段1
在第一階段,其實并沒有想到需要對GC這個流程進行較大的變動,看可不可以從當前的GC流程中進行一些簡單調整,提升GC的性能。
- 分析
GC的流程相對簡單:

圖12:GC流程圖示
可以看到,如果存在gcKey,會觸發一個批次的刪除gcKey和dataKey的流程。
最初設計存在sleep以及批次的原因在于減少GC對TiKV的影響,降低對現網的影響。
因此這里可以調整的范圍比較有限:按照批次進行控制,或者縮短批次刪除之間的時間間隔。
- 嘗試
縮短sleep時間(甚至縮短到0,去掉sleep過程),或者提高單個批次上限。
- 結果
但是這里原生sleep時間并不長,而且就算提高批次個數,畢竟單線程,提高并沒有太大。
- 小結
原生GC流程可變動的范圍比較有限,必須打破這種局限才可以對GC的速度得以更好的優化。
2.2.2 階段2
第一階段過后,發現原有機制確實局限比較大,如果需要真的把GC進行加速,最好的辦法是在原有的機制上看有沒有辦法類似expireKey一樣給出并發的思路,可以和過期一樣在質上提速。
但是當前現網已經不少集群在使用磁盤KV集群,并發提速必須和現網存量key設計一致前提下進行調整,解決現網存量的GC問題。
- 分析
如果有一種可能,更改GC的key編碼規則,類似模擬過期key的機制,添加slot位置,應該可以原生滿足這種多協程并發進行GC的情況。
但是基于當前編碼方式,有沒有其他辦法可以較好地把GC key分散開來?
把上述問題作為階段2的分析切入點,再對當前的GC key進行分析:

圖13:gcKey編碼設計圖示
考慮其中的各個字段:
- namespace:同一個磁盤KV下GC空間的必然一致
- gc-key-prefix:不管哪個磁盤KV的字段必然一致
- dbid:現網的磁盤KV都是基于集群模式,dbid都是0
- uuid:映射到對應的dataKey
分析下來,也只有uuid在整個gcKey的編碼中是變化的。
正因為uuid的分布應該是足夠的離散,此處提出一種比較大膽的想法:基于uuid的前若干位當作hash slot,多個協程可以基于不同的前綴進行并發訪問。
因為uuid是一個128bit長度(8個byte)的內容,如果拿出前面的8個bit(1個byte),可以映射到對應的256個slot。
- 嘗試
基于上述分析,uuid的前一個byte作為hash slot的標記,這樣,GC流程變成:

圖14:基于uuid劃分GC機制圖示
簡單描述下階段2的GC流程:
- GC任務使用協程,分成256個任務
- 每一個任務基于前綴掃描的時候,從之前掃描到dbid改成后續補充一個byte,每個協程被分配不同的前綴,進行各自的任務執行
- GC任務執行邏輯和之前單線程邏輯保持不變,處理gcKey以及dataKey。
這樣,基于uuid的離散,GC的任務可以拆散成并發協程進行處理。
這樣的優點不容置疑,可以較好地進行并發處理,提高GC的速度。
- 結果
基于并發的操作,GC的耗時可以縮短超過一半。后續會有同樣條件下的數據對比。
- 小結
階段2確實帶來一些突破:再保留原有gcKey設計的前提下,基于拆解uuid的方法使得GC的速度有質的提高。
但是這樣會帶來問題:對于dataKey較多(可以理解為一個HASH,或者一個SET的元素較多)的時候,刪除操作可能對TiKV的性能帶來影響。這樣帶來的副作用是:如果并發強度很高地進行GC,因為TiKV集群寫入(無論寫入還是刪除)性能是一定的,這樣是不是可能導致業務的正常寫入可能帶來了影響?
如何可以做到兼顧磁盤KV日常的寫入和GC?這成了下一個要考慮的問題。
2.2.3 階段3
階段2之后,GC的速度是得到了較大的提升,但是在測試過程中發現,如果在過程中進行寫入,寫入的性能會大幅度下降。如果因為GC的性能問題忽視了現網的業務正常寫入,顯然不符合線上業務的訴求。
磁盤KV的GC還需要一種能力,可以調節GC。
- 分析
如果基于階段2,有辦法可以在業務低峰期的時候進行更多的GC,高峰期的時候進行讓路,也許會是個比較好的方法。
基于上面的想法,我們需要在Tula層面可以比較直接地知道當前磁盤KV的性能表現到底到怎樣的層面,當前是負荷較低還是較高,應該用怎樣的指標去衡量當前磁盤KV的性能?
- 嘗試
此處我們進行過以下的一些摸索:
- 基于TiKV的磁盤負載進行調整
- 基于Tula的時延表現進行調整
- 基于TiKV的接口性能表現進行調整
暫時發現TiKV的接口性能表現調整效果較好,因為基于磁盤負載不能顯式反饋到Tula的時延表現,基于Tula的時延表現應該需要搜集所有的Tula時延進行調整(對于同一個TiKV集群接入多個不同的Tula集群有潛在影響),基于TiKV的接口性能表現調整可以比較客觀地得到Tula的性能表現反饋。
在階段1中,有兩個影響GC性能的參數:
- sleep時延
- 單次處理批次個數
加上階段2并發的話,會有三個可控維度,控制GC的速度。
調整后的GC流程如下:

圖15:自適應GC機制圖示
階段3對GC添加自適應機制,簡述如下:
①開啟協程,搜集TiKV節點負載
- 發現TiKV負載較高,控制GC參數,使得GC緩慢進行
- 發現TiKV負載較低,控制GC參數,使得GC激進進行
②開啟協程,進行GC
- 發現不需要GC,控制GC參數,使得GC緩慢進行
- 結果
基于監控表現,可以明顯看到,GC不會一直強制占據TiKV的所有性能。當Tula存在正常寫入的時候,GC的參數會響應調整,保證現網寫入的時延。
- 小結
階段3之后,可以保證寫入和但是從TiKV的監控上看,有時候GC并沒有完全把TiKV的性能打滿。
是否有更加高效的GC機制,可以繼續提高磁盤KV的GC性能?
2.2.4 階段4
基于階段3繼續嘗試找到GC性能更高的GC方式。
- 分析
基于階段3的優化,目前基于單個節點的Tula應該可以達到一個可以較高強度的GC,并且可以給現網讓路的一種情況。
但是,實際測試的時候發現,基于單個節點的刪除,速度應該還有提升空間(從TiKV的磁盤IO可以發現,并沒有占滿)。
這里的影響因素很多,例如我們發現client-go側存在獲取tso慢的一些報錯。可能是使用客戶端不當等原因造成。
但是之前都是基于單個Tula節點進行處理。既然每個Tula都是模擬了Redis的集群模式,被分配了slot區間去處理請求。這里是不是可以借鑒分片管理數據的模式,在GC的過程直接讓每個Tula管理對應分片的GC數據?
這里先review一次優化階段2的解決方式:基于uuid的第一個byte,劃分成256個區間。leader Tula進行處理的時候基于256個區間。
反觀一個Tula模擬的分片范圍是16384(0-16383),而一個byte可以表示256(0-255)的范圍。
如果使用2個byte,可以得到65536(0-65535)的范圍。
這樣,如果一個Tula可以基于自己的分片范圍,映射到GC的范圍,基于Tula的Redis集群模擬分片分布去做基于Tula節點的GC分片是可行的。
假如某個Tula的分片是從startSlot到endSlot(范圍:0-16383),只要經過簡單的映射:
- startHash = startSlot* 4
- endHash = (endSlot + 1)* 4 - 1
基于這樣的映射,可以直接把Tula的GC進行分配,而且基本在優化階段2中無縫銜接。
- 嘗試
基于分析得出的機制如下:

圖16:多Tula節點GC機制圖示
可以簡單地描述優化之后的GC流程:
① 基于當前拓撲劃分當前Tula節點的startHash與endHash
② 基于步驟1的startHash與endHash,Tula分配協程進行GC,和階段2基本一致:
- GC任務使用協程,分成多個任務。
- 每一個任務基于前綴掃描的時候,從之前掃描到dbid改成后續補充2個byte,每個協程被分配不同的前綴,進行各自的任務執行。
- GC任務執行邏輯和之前單線程邏輯保持不變,處理gcKey以及dataKey。
基于節點分開之后,可以滿足在每個節點并發地前提下,各個節點不相干地進行GC。
- 結果
基于并發的操作,GC的耗時可以在階段2的基礎上繼續縮短。后續會有同樣條件下的數據對比。
- 小結
基于節點進行并發,可以更加提高GC的效率。
但是我們在這個過程中也發現,client-go的使用上可能存在不當的情況,也許調整client-go的使用后可以獲得更高的GC性能。
三、優化結果對比
我們基于一個寫入500W的SET作為寫入數據。其中每一個SET都有一個元素,元素大小是4K。
因為階段2和階段4的提升較大,性能基于這兩個進行對比:

表1:各階段GC耗時對照表
可以比較明顯地看出:
- 階段2之后的GC時延明顯縮減
- 階段4之后的GC時延可以隨著節點數的增長存在部分縮減
四、后續計劃
階段4之后,我們發現Tula的單節點性能應該有提升空間。我們會從以下方面進行入手:
- 補充更多的監控項目,讓Tula更加可視,觀察client-go的使用情況。
- 基于上述調整跟進client-go在不同場景下的使用情況,嘗試找出client-go在使用上的瓶頸。
- 嘗試調整client-go的使用方式,在Tula層面提高從指令執行,到GC,過期的性能。
五、總結
回顧我們從原來的單線程GC,到基于編碼機制做到了多線程GC,到為了減少現網寫入性能影響,做到了自適應GC,再到為了提升GC性能,進行多節點GC。
GC的性能提升階段依次經歷了以下過程:
- 單進程單協程
- 單進程多協程
- 多進程多協程
突破點主要在于進入階段2(單進程多協程)階段,設計上的困難主要來源于:已經存在存量數據,我們需要兼顧存量數據的數據分布情況進行設計,這里我們必須在考慮存量的gcKey存在的前提下,原版gcKey的編碼設計與基于字典序的遍歷機制對改造造成的約束。
但是這里基于原有的設計,還是有空間進行一些二次設計,把原有的問題進行調優。
這個過程中,我們認為有幾點比較關鍵:
- 在第一次設計的時候,應該從多方面進行衡量,思考好某種設計會帶來的副作用。
- 在上線之前,對各種場景(例如不同的指令,數據大小)進行充分測試,提前發現出問題及時修正方案。
- 已經是存量數據的前提下,更應該對原有的設計進行重新梳理。也許原有的設計是有問題的,遵循當前設計的約束,找出問題關鍵點,基于現有的設計嘗試找到空間去調整,也許存在調優的空間。