阿里云數(shù)據(jù)湖統(tǒng)一元數(shù)據(jù)與存儲(chǔ)管理實(shí)踐

一、云上數(shù)據(jù)湖架構(gòu)
首先介紹一下數(shù)據(jù)湖相關(guān)的概念和架構(gòu)。

不同的云產(chǎn)商對數(shù)據(jù)湖有著不同的定義。但是從關(guān)鍵詞上來看,基本上都是圍繞這幾個(gè)特性和目標(biāo):
(1)統(tǒng)一存儲(chǔ),即數(shù)據(jù)湖是一個(gè)統(tǒng)一的中心化的數(shù)據(jù)存儲(chǔ)。
(2)可以用來放一些原始數(shù)據(jù)。
(3)支持多種格式,包括結(jié)構(gòu)化的數(shù)據(jù)和非結(jié)構(gòu)化的數(shù)據(jù)。
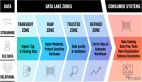
首先,統(tǒng)一存儲(chǔ)主要是為了解決數(shù)據(jù)孤島的問題。因?yàn)閭鹘y(tǒng)的數(shù)據(jù)庫或者是數(shù)據(jù)倉庫在設(shè)計(jì)上是存算一體的,也就是在不同的查詢引擎之間,數(shù)據(jù)需要經(jīng)過清洗和同步。這樣不管是在存儲(chǔ)空間上,還是效率上,都存在一定的浪費(fèi)。而數(shù)據(jù)湖上則是使用存算分離的查詢引擎,典型的比如 Hadoop 生態(tài)的 Hive 和 Spark。再加上開放的存儲(chǔ)格式,如 Parquet、ORC 等,來實(shí)現(xiàn)使用不同的引擎同時(shí)可以查詢同一個(gè)數(shù)據(jù)的功能。這就是早期數(shù)據(jù)湖的架構(gòu)。
在存儲(chǔ)實(shí)現(xiàn)上,數(shù)據(jù)湖通常會(huì)使用擴(kuò)展性比較高的,廉價(jià)的存儲(chǔ),比如 HDFS,或者云上的 OSS、S3 等對象存儲(chǔ)。這樣大家可以把更多的原始數(shù)據(jù),非結(jié)構(gòu)化數(shù)據(jù)直接放入,避免原始數(shù)據(jù)的丟失。
為了能夠讀取這些原始數(shù)據(jù),計(jì)算引擎通常支持類似 schema on read 的方式,采取事后建模的高靈活性的解析方式,對數(shù)據(jù)格式?jīng)]有很強(qiáng)的約束。這種靈活性也帶來了一些弊端,比如其高度開放性可能導(dǎo)致對安全和權(quán)限的管理相比于數(shù)倉是有所差距的。另外,因?yàn)殚_放存儲(chǔ),并發(fā)寫入的場景尤其是流式寫入的場景,事務(wù)上對 ACID 的要求會(huì)更高。
是否有一種辦法使我們既能夠利用數(shù)據(jù)湖的優(yōu)勢,也能讓數(shù)據(jù)湖擁有數(shù)倉的功能特性呢?
前兩年 Databrick 提出了 Lakehouse 湖倉一體的概念,希望讓數(shù)據(jù)湖能夠?qū)崿F(xiàn)更多數(shù)倉的企業(yè)級能力,讓用戶可以像使用數(shù)倉一樣地使用數(shù)據(jù)湖。

Lakehouse 概念是在數(shù)據(jù)庫的基礎(chǔ)之上,添加了幾層內(nèi)容。
首先在存儲(chǔ)上層,做了元數(shù)據(jù)的統(tǒng)一。對上層提供統(tǒng)一的元數(shù)據(jù)結(jié)構(gòu)化 SQL 的接口,讓不同的應(yīng)用,可以使用相同的元數(shù)據(jù)訪問數(shù)據(jù)。
另外在性能上,支持 cache,來優(yōu)化數(shù)據(jù)湖讀取性能。
并且,利用數(shù)據(jù)湖格式實(shí)現(xiàn)事務(wù)層。目前很火熱的數(shù)據(jù)湖格式,Delta Lake、Hudi 和 Iceberg,使得我們現(xiàn)在提到數(shù)據(jù)湖場景,基本就跟這幾個(gè)數(shù)據(jù)湖格式劃等號了。雖然這有些夸張,但也足以證明它們在數(shù)據(jù)湖架構(gòu)中的重要地位。
最后在底層的數(shù)據(jù)湖存儲(chǔ)的實(shí)現(xiàn)上,相比于 HDFS,目前在云上也有使用對象存儲(chǔ)作為數(shù)據(jù)湖存儲(chǔ)的趨勢。因?yàn)樵粕蠈ο蟠鎯?chǔ)的擴(kuò)展性相比于自建 HDFS 要高很多。不管是在成本上,還是在可用性上其實(shí)都是會(huì)高一些。

阿里云提供了一些產(chǎn)品功能來幫助用戶使用數(shù)據(jù)湖的架構(gòu)。
首先支持多引擎計(jì)算分析,比如常見的 EMR 的 Spark 和 Hive、Presto、StarRocks 這些引擎,以及阿里云自研的引擎,如 MaxCompute、Hologres,都可以進(jìn)行湖上數(shù)據(jù)分析。可以根據(jù)不同場景來選擇合適的引擎。
另一方面這些引擎為了能夠無縫對接湖上的結(jié)構(gòu)化數(shù)據(jù),DLF(data lake formation)產(chǎn)品提供了統(tǒng)一的元數(shù)據(jù)和湖上的權(quán)限管理,作為整個(gè) lakehouse 架構(gòu)里的元數(shù)據(jù)管理層。在后面還會(huì)展開介紹。
最后在存儲(chǔ)層上,云上的對象存儲(chǔ) OSS 是天生適合做數(shù)據(jù)湖存儲(chǔ)的,并且成本不高。同時(shí)現(xiàn)在 OSS 也支持兼容 HDFS 接口的產(chǎn)品,OSS-HDFS,是完全支持 HDFS 接口的,更適合對接一些老版本的大數(shù)據(jù)引擎。

DLF 的核心能力是提供一個(gè)全托管的統(tǒng)一元數(shù)據(jù)服務(wù),因?yàn)閿?shù)據(jù)都已經(jīng)放在數(shù)據(jù)湖上了,元數(shù)據(jù)需要一個(gè)中心化的管理才能實(shí)現(xiàn)多個(gè)引擎的無縫對接,這體現(xiàn)了元數(shù)據(jù)服務(wù)在數(shù)據(jù)湖里的重要性。這樣不同引擎讀寫同一份數(shù)據(jù)是圍繞統(tǒng)一的 schema 做操作的,而不是每個(gè)引擎都需要單獨(dú)建外表。
同時(shí)圍繞元數(shù)據(jù),我們提供對數(shù)據(jù)的細(xì)粒度的權(quán)限管控。
另外也提供了數(shù)據(jù)湖上的一些存儲(chǔ)管理的功能。
二、數(shù)據(jù)湖統(tǒng)一元數(shù)據(jù)
下面就來具體介紹阿里云數(shù)據(jù)湖的一個(gè)重要能力,數(shù)據(jù)湖上的統(tǒng)一元數(shù)據(jù)。

在開源大數(shù)據(jù)體系里,從早期的 map-reduce 到類似 SQL 查詢語言 Hive 的誕生之后,Hive 逐漸成為了開源數(shù)倉的事實(shí)標(biāo)準(zhǔn),圍繞著 Hive 的元數(shù)據(jù) Hive Metastore 也成為了對接開源數(shù)倉的元數(shù)據(jù)標(biāo)準(zhǔn)。從此以后各個(gè)引擎,包括 Spark、Presto 等都是支持對接 Hive Metastore,圍繞 Hive Metastore 做元數(shù)據(jù)管理。
Hive Metastore 是一個(gè)常駐的無狀態(tài)的服務(wù),它可以部署一個(gè)或者多個(gè)實(shí)例。大數(shù)據(jù)引擎通過 thrift 協(xié)議連接 Hive Metastore 進(jìn)行元數(shù)據(jù)的讀寫。
Hive Metastore 的元數(shù)據(jù)本身是需要存儲(chǔ)到數(shù)據(jù)庫上,通常會(huì)用 MySQL 作為 Hive Metastore 元數(shù)據(jù)的底層存儲(chǔ)。
這就形成了常見的開源大數(shù)據(jù)元數(shù)據(jù)體系。

使用 Hive Metastore 管理元數(shù)據(jù)也存在著一些問題和挑戰(zhàn)。
首先在功能層面上它是沒有做多版本的,不能追溯之前的元數(shù)據(jù)版本。ACID 的特性和 LOCK 接口是和 Hive 引擎綁定的,在湖上多引擎的場景下,是沒有辦法利用到它的一些功能的。
另外因?yàn)樗┞兜氖?thrift 協(xié)議的接口,如果你自有服務(wù),或者自研引擎需要去對接會(huì)相對麻煩一些。有時(shí)可能還需要直接連 MySQL 去讀一些元數(shù)據(jù),這也不是一個(gè)比較好的方法。
還有一個(gè)問題是它存在性能瓶頸,存在單點(diǎn)問題和運(yùn)維成本,尤其是對元數(shù)據(jù)量比較大的用戶,這是一個(gè)比較常見的問題。因?yàn)閱吸c(diǎn)的 Hive Metastore Server 和 Metastore 后端連接的 MySQL 都可能會(huì)成為瓶頸,需要一些性能調(diào)優(yōu)的工作。
上圖中還列出了一些真實(shí)的客戶問題。在 Hive Metastore 的使用過程中,首先會(huì)遇到的就是 JDBC 連接的問題,可能會(huì)遇到一些錯(cuò)誤。比如有的時(shí)候我們查詢元數(shù)據(jù)的所有請求都突然變慢了,這時(shí)首先要檢查 MySQL 的狀態(tài),查看 MySQL 監(jiān)控是否有慢 SQL。如果分區(qū)數(shù)總量很大的話,MySQL 表數(shù)量可能會(huì)達(dá)到上千萬,會(huì)導(dǎo)致查詢比較慢。這個(gè)時(shí)候,需要做一些數(shù)據(jù)清理,刪除一些分區(qū)來緩解這個(gè)問題。另外在自建的數(shù)據(jù)管理系統(tǒng)或者外部系統(tǒng)中,通常不會(huì)用 thrift 協(xié)議去調(diào)用 Hive 的 Metastore Server,而是直連 JDBC,這樣連接數(shù)多的話,也可能會(huì)帶來一些額外的壓力。
在內(nèi)存方面,Hive Metastore Server 的內(nèi)存存在 OOM 的風(fēng)險(xiǎn)。因?yàn)橛行┎僮鳎热?list partition,會(huì)加載全部分區(qū)對象,如果有人寫了一個(gè)糟糕的查詢,比如在一個(gè)很大的分區(qū)表上,沒有加分區(qū)查詢條件,就可能會(huì)拿到上百萬的分區(qū),最后導(dǎo)致整個(gè) Hive Metastore 內(nèi)存出現(xiàn) full gc 或者 OOM 的情況,一旦 Hive Metastore 出問題,整個(gè)集群的作業(yè)都會(huì)受到影響。
列舉幾個(gè)我們遇到過的 StackoverflowError 的情況。如果 drop partition 的分區(qū)數(shù)量很多的話,在 Hive Metastore 的內(nèi)部實(shí)現(xiàn)是遞歸的,可能會(huì)導(dǎo)致堆棧溢出報(bào)錯(cuò),無法直接執(zhí)行。
最后就是超時(shí)問題,因?yàn)?HMS 的客戶端設(shè)計(jì)沒有分頁,是全量返回的。所以在拉取元數(shù)據(jù)的時(shí)候,可能會(huì)出現(xiàn)超時(shí)的情況,這也是一個(gè)風(fēng)險(xiǎn)點(diǎn)。
這些都是我們在使用 HMS 時(shí)候遇到的一些問題。

因此在云上,我們提供了全托管的元數(shù)據(jù)服務(wù)的 DLF(data lake formation),采用的是完全不同的架構(gòu),來解決上面大部分問題和痛點(diǎn)。
首先作為云產(chǎn)品,我們通過標(biāo)準(zhǔn)的 open API 暴露接口,提供了兼容 Hive2 和 Hive3 的 Metastore 接口的 client。這個(gè) client 可以直接替換掉引擎的 Hive Metastore client 實(shí)現(xiàn)類,原本訪問 Hive 元數(shù)據(jù)的地方可以直接替換為訪問我們客戶端的實(shí)現(xiàn)類,實(shí)現(xiàn)了無縫對接。
另外除了開源體系的引擎以外,我們也對接了阿里云上的其它大數(shù)據(jù)引擎,包括 Max Compute、Hologres、Flink 等等。云上其他大數(shù)據(jù)引擎也可以利用我們的統(tǒng)一元數(shù)據(jù)來進(jìn)行元數(shù)據(jù)管理。這樣真正做到了統(tǒng)一 catalog,用一個(gè)引擎寫入,其它引擎讀取。比如用 Flink 入湖,之后可以直接使用 Spark 查,再用 Hologres 等做 OLAP 分析,這些都可以直接采用同一個(gè)元數(shù)據(jù)來完成。
不同于 HMS 使用 MySQL,擴(kuò)展性比較差,我們的元數(shù)據(jù)服務(wù)底層實(shí)現(xiàn)是用阿里云的表格存儲(chǔ)。表格存儲(chǔ)也是阿里云提供的一種服務(wù),面向海量數(shù)據(jù)有非常強(qiáng)的伸縮能力,擴(kuò)展性很高,所以不用擔(dān)心分區(qū)數(shù)過大帶來的擴(kuò)展性問題。
因?yàn)槲覀兪且粋€(gè)全托管的服務(wù),對使用方提供 SLA,高可用保障,前面提到的運(yùn)維問題也可以避免。
總結(jié)一下,我們的統(tǒng)一元數(shù)據(jù)的優(yōu)勢為,一方面因?yàn)槭侨泄埽梢詼p少元數(shù)據(jù)運(yùn)維成本;另一方面真正實(shí)現(xiàn)了對接云上多引擎。

再補(bǔ)充一些關(guān)于元數(shù)據(jù)本身實(shí)現(xiàn)的細(xì)節(jié)。
首先元數(shù)據(jù)的客戶端是兼容 Hive Metastore 行為的,實(shí)現(xiàn)了 Hive Metastore 的接口,可以直接去對接 Hive 生態(tài)相關(guān)的大數(shù)據(jù)引擎。Hive Metastore 內(nèi)部的有些行為,比如在創(chuàng)建 partition 的時(shí)候統(tǒng)計(jì) table size 等動(dòng)作,都會(huì)保留在客戶端里,所以不用擔(dān)心兼容性問題。
另外客戶端會(huì)做一些性能優(yōu)化,包括異常重試、并發(fā)讀取、分頁查詢等。對于重復(fù)提交的請求,客戶端也會(huì)做一些合并壓縮,減少 IO 開銷。
在服務(wù)內(nèi)部,除了剛才提到的存儲(chǔ)層的高擴(kuò)展性以外,我們也通過一些自動(dòng)的分區(qū)索引,再做一些分區(qū)過濾的性能提升。
總體來講在元數(shù)據(jù)的性能上,在一些小表上可能跟 RDS 有些差距,但是并不明顯。在大分區(qū)表上,比如單表有 300 萬分區(qū)的場景下,我們的查詢性能會(huì)有比較明顯的優(yōu)勢。比如在 300 萬分區(qū)表下,如果分區(qū)條件全部命中,list partition by filter 在我們的元數(shù)據(jù)可以在 0.5 秒內(nèi)返回,但是在 RDS 上因?yàn)樗姆謪^(qū)值沒有索引,需要花 5 秒左右才能返回。

在元數(shù)據(jù)的功能上再舉幾個(gè)例子。
首先是元數(shù)據(jù)多版本,我們會(huì)記住元數(shù)據(jù)每一次更新的前后狀態(tài),可以看到什么時(shí)間點(diǎn)加了什么字段,是誰做的修改的。有比較好的回溯機(jī)制,實(shí)現(xiàn)元數(shù)據(jù)審計(jì)。在元數(shù)據(jù)檢索上,我們的元數(shù)據(jù)本身會(huì)把內(nèi)容同步到 ES 搜索引擎里,對外暴露,可以通過字段搜表,也可以做全局搜索。

再來看一下權(quán)限相關(guān)的問題。
在開源大數(shù)據(jù)場景下做用戶級別的權(quán)限控制,通常會(huì)有這么幾種方案:
Hive 本身提供的認(rèn)證能力,storage-based authorization和sql-standard-based authorization。但是 Hive 的實(shí)現(xiàn)都是跟 Hive 引擎綁定的。通常在其它引擎是無法使用到它的功能的,基本上也沒有人真正會(huì)在其它引擎上去使用。
大家通常做法是用 Ranger 來做權(quán)限管理。Ranger 是一個(gè)通用的多引擎方案,它可以對 SQL 進(jìn)行權(quán)限管理,也可以對文件系統(tǒng)做權(quán)限管理。它的原理是從 LDAP 同步用戶信息,提供 UI 供用戶配置權(quán)限。在大數(shù)據(jù)引擎這一側(cè),可以添加各種插件,通過插件來實(shí)現(xiàn)權(quán)限的攔截和檢查。Ranger 是目前一個(gè)可行的方案,但是在公有云上面對我們自研的大數(shù)據(jù)引擎,是沒法直接對接的。另一方面雖然它包括了如 SparkSQL 等類插件,但是官方的支持并不好,更多還是需要自研一些插件,或者找第三方插件,整體部署起來并沒有那么簡單。

因此在權(quán)限這一塊,DLF 統(tǒng)一元數(shù)據(jù)也提供了鑒權(quán)的能力。
權(quán)限控制默認(rèn)是沒有開啟的,因?yàn)椴灰欢ㄋ杏脩舳夹枰怯脩艨梢园?catalog 級別進(jìn)行開關(guān)。catalog 是基于 database 之上的一層管理模型,如果基于 catalog 設(shè)置權(quán)限之后,管理員就可以在控制臺進(jìn)行具體的授權(quán)操作。包括 database、table、column、function 這些粒度都可以進(jìn)行授權(quán)。也可以設(shè)置不同 action 的權(quán)限,比如只給某個(gè)人對某個(gè) table 設(shè)置 select 權(quán)限,而不設(shè)置 insert 的權(quán)限。同時(shí)也支持 RBAC,可以把權(quán)限包在 role 里,統(tǒng)一賦權(quán)給一組用戶,這些基本的能力都是具備的。
在鑒權(quán)環(huán)節(jié)的實(shí)現(xiàn)上,我們提供了兩個(gè)層面的鑒權(quán),第一層面是元數(shù)據(jù)的 API,我想要查看 table 或者 create table,這種動(dòng)作會(huì)在服務(wù)端上鑒權(quán)。因?yàn)槲覀兊脑品?wù)會(huì)直接去鑒權(quán),判斷發(fā)送請求的用戶角色是否有相應(yīng)動(dòng)作的權(quán)限,如果沒有就會(huì)進(jìn)行攔截。另外因?yàn)橛行?SQL 操作在元數(shù)據(jù)層面感知不到,比如在元數(shù)據(jù)上可能就是查一張表,但是并不知道是在往里寫數(shù)據(jù)還是在讀數(shù)據(jù),這個(gè)時(shí)候和 Ranger 類似,我們也提供了引擎的插件,可以放在 Spark、Hive 上做一層攔截。和 Ranger 類似,會(huì)在內(nèi)部檢查代理用戶到底有沒有 select 權(quán)限,沒有的話去做攔截。這兩層的鑒權(quán)模型,適用于不同的場景。

再介紹一個(gè)額外功能,就是元數(shù)據(jù)遷移。元數(shù)據(jù)本身無論在云上,還是自建的 MySQL 的元數(shù)據(jù),如果想要遷移,都需要一個(gè)遷移的過程。為了簡化這個(gè)過程,我們在產(chǎn)品上做了元數(shù)據(jù)遷移的功能,在控制臺上就可以做數(shù)據(jù)遷移。
簡單來講我們會(huì)去連遠(yuǎn)端的 MySQL 數(shù)據(jù)庫,如果這個(gè)數(shù)據(jù)庫在阿里云 VPC 內(nèi),會(huì)自動(dòng)打通網(wǎng)絡(luò),通過 JDBC 直接拉取元數(shù)據(jù),轉(zhuǎn)換成我們云上的 DLF 元數(shù)據(jù),這是直接產(chǎn)品化的。除了導(dǎo)入需求,可能還會(huì)有導(dǎo)出需求,包括兩邊元數(shù)據(jù)對比的需求。這些也提供了現(xiàn)成的工具可以直接使用。在元數(shù)據(jù)遷移方面,不管是導(dǎo)入導(dǎo)出還是其它方面的需求,我們都保持開放性,不需要擔(dān)心元數(shù)據(jù)被綁定的問題。

除了元數(shù)據(jù)遷移,可能在有些場景下還需要做元數(shù)據(jù)抽取,快速構(gòu)建出湖上的元數(shù)據(jù)。元數(shù)據(jù)抽取適合于這樣的場景,比如數(shù)據(jù)湖上已經(jīng)有一些數(shù)據(jù)文件了,可能是從其它數(shù)倉拷貝過來的,或者是一些零散的 CSV 數(shù)據(jù)集文件等等。這個(gè)時(shí)候因?yàn)槲覀儧]有對應(yīng)表的元數(shù)據(jù),就需要用 DDL 語句自己去建表,再做查詢,比較麻煩的,也容易出錯(cuò)。尤其是對于像 JSON 這種半結(jié)構(gòu)化的嵌套類型,更難去寫建表語句。這種情況下使用我們這個(gè)元數(shù)據(jù)抽取功能就比較方便,可以直接把元數(shù)據(jù)給推斷出來。用戶只需要填寫 OSS 路徑,我們會(huì)根據(jù)路徑格式自動(dòng)掃描下面的表,包括分區(qū)值,創(chuàng)建好之后,就會(huì)寫入到元數(shù)據(jù)里進(jìn)行直接查詢了。包括 CSV、JSON、Parquet 、ORC 等各種格式,也包括湖格式都是可以識別出來的。值得注意的是因?yàn)槲覀冏龈袷酵茢嘈枰獟呙杷袛?shù)據(jù),會(huì)比較耗時(shí),于是我們采用了快速采樣的方式。
三、數(shù)據(jù)湖存儲(chǔ)管理與優(yōu)化
接下來介紹我們在數(shù)據(jù)湖存儲(chǔ)分流方面做的一些管理和優(yōu)化。

首先介紹一下元倉,元倉是我們在元數(shù)據(jù)存儲(chǔ)之外做的一個(gè)在線的元數(shù)據(jù)的數(shù)據(jù)倉庫。因?yàn)樵獢?shù)據(jù)存儲(chǔ)本身是在線服務(wù),需要比較高的讀寫事務(wù)保障,有些后臺分析,包括一些聚合查詢是不適合在這里做的。于是我們做了一個(gè)實(shí)時(shí)的元數(shù)據(jù)倉庫。元倉底層是基于 Max Compute 和 Hologres 實(shí)現(xiàn)的,它會(huì)收集元數(shù)據(jù)的變更信息,也會(huì)收集計(jì)算引擎的查詢和寫入的信息,包括存儲(chǔ)上的信息都會(huì)實(shí)時(shí)收集到。這樣我們就形成了圍繞 database 的 table partition 做的指標(biāo)庫,即 data profile 指標(biāo)。我們會(huì)把這些指標(biāo)通過標(biāo)準(zhǔn)的 API 暴露出來。一方面可以在控制臺上可以做統(tǒng)計(jì)分析,包括對接我們的一些云產(chǎn)品,如 dataworks 之類,做一些數(shù)據(jù)展示和預(yù)估。另一方面這些指標(biāo)可以用來做存儲(chǔ)生命周期的優(yōu)化和管理。

接下來舉例介紹一下 Data Profile 指標(biāo)的幾個(gè)實(shí)現(xiàn)。
首先是表和分區(qū)的大小,這是一個(gè)比較基礎(chǔ)的屬性。通常來講,表和分區(qū)大小是寫在元數(shù)據(jù)層,即 Hive 元數(shù)據(jù)的 table property 里面,本身就定義了,計(jì)算引擎會(huì)在創(chuàng)建表或者分區(qū)的時(shí)候?qū)懭搿5遣煌鎸懭氲臉?biāo)準(zhǔn)會(huì)不一樣,比如 Hive 是叫 totalSize,Spark 是以 Spark 開頭的屬性值。另外,這些寫入也需要一些參數(shù)去開啟,不開啟是不會(huì)進(jìn)行寫入的。所以在實(shí)際情況中會(huì)發(fā)現(xiàn)元數(shù)據(jù)本身存儲(chǔ)的表大小是不準(zhǔn)確的。
在元倉里,因?yàn)槲覀兡J(rèn)大部分?jǐn)?shù)據(jù)湖使用的是 OSS,我們會(huì)通過 OSS 的底層存儲(chǔ)來獲取表分區(qū)的大小,這樣可以最大限度保證數(shù)據(jù)的準(zhǔn)確性。因?yàn)?OSS 提供了一個(gè) t+1 更新的存儲(chǔ)清單,這一點(diǎn)類似于 LAMBDA 架構(gòu),會(huì) t+1 更新存儲(chǔ)清單的表和分區(qū)的存儲(chǔ)大小。另外對于實(shí)時(shí)表和分區(qū)的變更,我們也會(huì)監(jiān)聽到,再實(shí)時(shí)的從 OSS 那邊拿到最新的大小去做更新。也就是通過存量加增量的流程去獲取表分區(qū)的大小,拿到大小之后,會(huì)每天產(chǎn)出一些分析報(bào)表,比如表的存儲(chǔ)排名,文件大小占比等等。因此我們可以看到哪些表,哪些分區(qū)的存儲(chǔ)占用比較大,去做相應(yīng)的優(yōu)化。
上面是一個(gè)比較完整的湖上管理視圖。

另外再介紹兩個(gè)關(guān)鍵指標(biāo)。
第一個(gè)指標(biāo)是表和分區(qū)的訪問頻次,通過訪問頻次可以鑒別那些仍然在用但訪問不頻繁的表。這些表可以在 OSS 底層置為低頻存儲(chǔ),照常讀取的同時(shí)可以節(jié)省一些成本。在原理上我們通過使用引擎的 Hook 來實(shí)現(xiàn)對訪問頻次的獲取,我們解析 SQL 的 plan,拿到它讀取的表和分區(qū),再提交到元數(shù)據(jù)服務(wù)里去做記錄,最后把訪問頻次指標(biāo)統(tǒng)計(jì)出來。
第二個(gè)指標(biāo)是表和分區(qū)的最后訪問時(shí)間。它可以用來識別這個(gè)表和分區(qū)是否還有人在訪問。為了保證指標(biāo)的準(zhǔn)確性,最后訪問時(shí)間是通過 OSS 底層的訪問日志獲取的。這樣不管通過任何引擎任何途徑讀這里面的數(shù)據(jù),訪問時(shí)間都會(huì)獲取到。最后對于沒有人使用的表和分區(qū),就可以考慮做歸檔或者刪除。

結(jié)合這幾個(gè)指標(biāo),更有利于我們做庫表分區(qū)的生命周期管理。因?yàn)楹仙芷诠芾硪彩且淮笾攸c(diǎn),因?yàn)閿?shù)倉是有存儲(chǔ)分層的概念,但在數(shù)據(jù)湖上是沒有一個(gè)比較完整的管理能力。我們目前就在做這方面相關(guān)的事情。
首先我們使用的標(biāo)準(zhǔn)型 OSS 對象存儲(chǔ)是提供了存儲(chǔ)分層能力的,也可以按需設(shè)置成低頻歸檔,冷歸檔這些層次。設(shè)置好歸檔之后,會(huì)對數(shù)據(jù)訪問方式產(chǎn)生影響,但是存儲(chǔ)成本會(huì)大幅降低。
用戶首先可以設(shè)置一些規(guī)則,包括基于分區(qū)值,分區(qū)的創(chuàng)建時(shí)間,上面提到的訪問頻次等指標(biāo),配置規(guī)則設(shè)定閾值,比如多長時(shí)間沒人訪問或者 30 天內(nèi)訪問頻次低于幾次。后臺就會(huì)定期把符合這些條件的分區(qū)的整個(gè)目錄做歸檔,或置為低頻等。
另外歸檔和冷歸檔做了之后是不能直接訪問的,需要一個(gè)解凍的流程。如果用戶有一天需要訪問已經(jīng)歸檔的數(shù)據(jù),可以一鍵解凍,整個(gè)目錄就可以直接使用,而不需要像 OSS 那樣逐個(gè)文件進(jìn)行解凍操作。這種存儲(chǔ)生命周期管理的存儲(chǔ)優(yōu)化,對于存儲(chǔ)量比較高的數(shù)據(jù)湖用戶來說會(huì)是一個(gè)比較好的實(shí)踐。
四、數(shù)據(jù)湖格式管理與優(yōu)化
最后介紹一下在數(shù)據(jù)湖格式層面,我們做的管理和優(yōu)化。

常見湖格式 Hudi、Iceberg 有幾個(gè)特點(diǎn),為了實(shí)現(xiàn) ACID,它們的底層數(shù)據(jù)文件更新,copy on write 之后,讀取的都是新版本的數(shù)據(jù)文件,但是老版本的數(shù)據(jù)還會(huì)保留在存儲(chǔ)側(cè)。時(shí)間一長就需要清理歷史版本的數(shù)據(jù)文件。另一方面頻繁流式寫入會(huì)產(chǎn)生很多小文件,通常可以使用命令手動(dòng)清理,或者結(jié)合在 streamming 任務(wù)當(dāng)中,配置一些參數(shù),比如多少 commit 清理一次,但是這對流式寫入本身的性能會(huì)產(chǎn)生影響。針對這種情況,業(yè)內(nèi)很多公司都使用額外部署 table service 的方式,不影響流式寫入,另起一個(gè)批作業(yè)去清理和優(yōu)化。DLF 把這種 table service 做在了云服務(wù)里面,這樣使用 DLF 湖格式的用戶,可以直接在控制臺上配置規(guī)則,比如基于版本號更新多少次就做一次清理。后臺就會(huì)跑任務(wù)做 vacuum 或者 optimize 命令,整個(gè)過程也是全托管的,用戶不用關(guān)心背后使用的資源。
具體實(shí)現(xiàn)原理為,元倉會(huì)維護(hù)很多元數(shù)據(jù)的變化和引擎消息,也會(huì)感知到哪些湖格式表發(fā)生了寫入和變化。每一次表的寫入,就會(huì)觸發(fā)規(guī)則引擎去做一次判斷是否滿足條件,如果滿足條件就會(huì)觸發(fā)動(dòng)作的執(zhí)行。目前我們對 Delta Lake 已經(jīng)有比較完整的支持了,對 Hudi 的支持也在進(jìn)行當(dāng)中。這是一個(gè)比較新的模塊。

再具體介紹下湖格式管理的幾種優(yōu)化策略。
第一種也是最常見的,基于版本間隔,清理清理歷史文件或者合并小文件。比如寫入了 20 個(gè) commit 之后就會(huì)自動(dòng)觸發(fā)整個(gè)表的清理,或者小文件合并。這個(gè)閾值是可以隨用戶級別或者作業(yè)級別做配置的。內(nèi)部會(huì)把這些合并的任務(wù)放在一個(gè)隊(duì)列里,這樣前一個(gè)合并任務(wù)還沒有跑完,是不會(huì)跑下一個(gè)合并任務(wù)的,避免并發(fā)執(zhí)行,產(chǎn)生寫沖突現(xiàn)象。
第二種合并規(guī)則是我們在客戶實(shí)踐過程當(dāng)中覺得比較實(shí)用的,基于時(shí)間分區(qū)自動(dòng)合并上一個(gè)分區(qū)的小文件。因?yàn)樵诹魇綄懭氲膱鼍跋拢ǔ?huì)按時(shí)間順序去命名分區(qū)值,每寫入一個(gè)新分區(qū)就代表上一個(gè)分區(qū)寫入停止。在這個(gè)時(shí)候,一旦發(fā)現(xiàn)有新分區(qū)創(chuàng)建,就可以去對上一個(gè)分區(qū)做一些優(yōu)化和合并的動(dòng)作。這樣上一個(gè)分區(qū)后續(xù)的查詢性能就能得到保證,同時(shí)這種做法也能最大程度避免合并任務(wù)和寫入流任務(wù)的寫沖突。當(dāng)然為了實(shí)現(xiàn)這個(gè)方案,我們內(nèi)部也是做了時(shí)間格式的支持,自動(dòng)處理了很多分區(qū)值的時(shí)間格式。這樣我們就可以自動(dòng)識別這些時(shí)間分區(qū)哪個(gè)分區(qū)是最新的,哪個(gè)分區(qū)是上一分區(qū)的。
五、問答環(huán)節(jié)
Q1:DLF 元數(shù)據(jù)的管理,跟 Databricks 推的 unity catalog 有什么區(qū)別?
A1:DLF 元數(shù)據(jù)管理有點(diǎn)類似于 Hive Metastore 的升級。Databricks 推的 unity catalog 其實(shí)是跟它的執(zhí)行引擎,Databricks 的 Spark 的綁定比較多,它是基于 Databricks 的引擎去做很多事情。我們對單個(gè)引擎的集成沒有 unity catalog 那么完整,但是更聚焦在云上的統(tǒng)一元數(shù)據(jù),即同一份元數(shù)據(jù)可以被云上各種各樣的引擎,包括自研的和開源的引擎,都能統(tǒng)一的進(jìn)行讀寫。總結(jié):我們對云上統(tǒng)一的數(shù)據(jù)這個(gè)角度做的比較多,針對的是多引擎的打通。對某一個(gè)引擎內(nèi)部做的集成沒有 unity catalog 那么深入。
Q2:DLF 的 OPEN API 是開源的嗎?
A2:首先我們是一個(gè)全托管的云產(chǎn)品,內(nèi)部的實(shí)現(xiàn)是做成云服務(wù)。然后我們會(huì)提供標(biāo)準(zhǔn)的 API,用戶可以通過阿里云的 SDK 對 API 的調(diào)用和使用。最后我們的元數(shù)據(jù) client,適配 Hive client,同時(shí) client 本身也是開源的,內(nèi)部的元數(shù)據(jù)服務(wù)是在云上實(shí)現(xiàn)的。
Q3:DLF 針對小文件治理,計(jì)算資源控制。跟湖格式相關(guān)的小文件合并的問題。
A3:目前因?yàn)槲覀兊暮袷降男∥募卫懋a(chǎn)品還處在公測階段,還沒有進(jìn)行真正的計(jì)費(fèi)。底層的資源我們是內(nèi)部提供的,不使用用戶的資源。我們內(nèi)部是會(huì)做一些針對單租戶的,最大的使用量的限制的。目前計(jì)費(fèi)策略還沒有明確的推出。這個(gè)可能會(huì)等到后續(xù)足夠完善之后再去做相關(guān)事情。
Q4:現(xiàn)在的 Hive Hook 解析 HSQ 的 SQL,Matestore 的 listener 能監(jiān)聽 DDL 嗎?
A4:我們現(xiàn)在實(shí)現(xiàn)的 listener 是能夠監(jiān)聽到 DDL 的。首先 DLF 元數(shù)據(jù)本身,因?yàn)閯偛盘岬搅宋覀円灿性獋}。其實(shí)內(nèi)部是會(huì)監(jiān)聽到所有元數(shù)據(jù)的變更,同時(shí)我們也會(huì)基于引擎的 Hook 去監(jiān)聽表查詢的信息,維護(hù)到 DLF 元倉里面。因?yàn)槲覀兊膶?shí)現(xiàn)是沒有 Metastore 的,用戶可以從 DLF 的 Data Profile 的 API 進(jìn)行獲取。如果想自己實(shí)現(xiàn)像以前的 Hive Metastore 一樣的 Metastore 的 listener,這是不支持的。但是可以基于我們云上的 API 去獲取元信息。