精準推薦的秘術:阿里解耦域適應無偏召回模型詳解

一、場景介紹

首先來介紹一下本文涉及的場景—— “有好貨”場景。它的位置是在淘寶首頁的四宮格,分為一跳精選頁和二跳承接頁。承接頁主要有兩種形式,一種是圖文的承接頁,另一種是短視頻的承接頁。這個場景的目標主要是為用戶提供滿意的好貨,帶動 GMV 的增長,從而進一步撬動達人的供給。
二、流行度偏差是什么,為什么
接下來進入本文的重點,流行度偏差。流行度偏差是什么?為什么會產生流行度偏差?
1、流行度偏差是什么

流行度偏差有很多別名,比如馬太效應、信息繭房,直觀來講它是高爆品的狂歡,越熱門的商品,越容易曝光。這會導致優質的長尾商品或者達人創作的新商品沒有曝光的機會。其危害主要有兩點,第一點是用戶的個性化不足,第二點是達人創作的新商品得不到足夠的曝光,使得達人參與感降低,因此我們希望緩解流行度偏差。
從上圖右邊的藍色柱狀圖可以看出,曝光 top10% 的商品在某一天中占據了 63% 的曝光,這證明在有好貨的場景下馬太效應是非常嚴重的。
2、為什么會產生流行度偏差
接下來我們去歸因為什么會產生流行度偏差。首先,需要闡明我們為什么會在召回截斷做緩解流行度偏差的工作。排序模型擬合的是商品的 CTR,它的訓練樣本包含正樣本和負樣本,CTR 越高的商品越容易獲得曝光。但是在召回階段,我們通常會采用雙塔模型,它的負樣本通常會通過兩種方式產生,第一種是全局隨機負采樣,第二種是 batch 內負采樣,batch 內負采樣是將同一個 batch 取正樣本的其它曝光日志當作負樣本,所以它在一定程度上可以緩解馬太效應。但是,通過實驗我們發現,全局負采樣實際的線上效率型效果會更好。不過,推薦系統中的全局隨機負采樣可能導致流行度偏差,因為它只為模型提供了正反饋。這種偏差可能歸因于流行度分布差異和先驗知識干擾,即用戶傾向于點擊更受歡迎的物品。因此,模型可能會優先推薦熱門物品,而不考慮它們的相關性。
我們也分析了流行度分布差異,如上圖右邊綠線所示,通過將商品按照曝光頻率分組并計算每組的正樣本平均分,發現即使所有樣本都是正樣本,平均分數也隨曝光頻率的下降而下降。推薦系統模型訓練時存在流行度分布差異和長尾分布差異。模型會傾向于把流行度信息注入到商品的 ID 特征中,導致流行度分布差異。高爆品獲得的訓練次數遠大于長尾商品,使得模型過擬合于高爆品,長尾商品難以得到充足訓練和合理向量表示。如上圖右邊的 TSN 圖所示,藍點表示高曝商品的商品向量,而紅點表示長尾商品的商品向量,顯示出分布上的顯著差異。而且如上圖右邊的紅線所示,hit ratio 也會隨著曝光數的降低而降低。所以,我們把流行度偏差的產生歸因于流行度分布差異和長尾分布差異。
三、流行度偏差當前解決方案

當前業界的解決方案主要包括兩種,分別是逆傾向評分(IPS)和因果推斷。
1、逆傾向評分(IPS)
通俗來講就是將主任務損失函數中高曝光概率商品的權重調低以避免過度關注于高曝光概率商品,從而可以更平均地關注整個正樣本分布。但是,這種方法需要提前預測曝光概率,這種預測是不穩定的,容易失效或者波動較大。
2、因果推斷
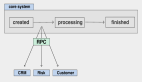
我們需要構建一張因果圖,i 代表商品特征,u 代表用戶特征,c 代表點擊概率,這張圖就表示給模型輸入用戶特征和商品特征,預測點擊率。如果我們把流行度偏差也考慮到這個模型中,用 z 來代表,它不僅會影響點擊率,還會影響商品的特征表示 i,因果推斷的方法是嘗試去阻斷 z 對 i 的影響。
比較簡單的方法是利用商品的一些統計特征單獨得到一個 bias 塔,此時模型會輸出兩個分,一個是真實的點擊率,另一個是商品的流行度分,在線上預測的時候會將商品的流行度分去掉,實現對流行度偏差的解耦。
第二種方法是將用戶點擊歸因為兩類,一類是從眾興趣,一類是真實興趣,分別構建樣本聯合訓練。相當于得到兩個模型,一個模型去得到用戶的從眾興趣分,一個模型去得到用戶的真實興趣分。因果推斷其實也存在問題,它解決了流行度分布差異,但不能解決長尾商品缺乏訓練數據的問題。當前的解決方案傾向于消除流行度偏見,但這對于需要“馬太效應”來生存的推薦系統可能并不總是有益的。所以,我們建議不要完全去除推薦系統中的流行度偏差,因為流行的項目通常更優質,用戶也有從眾心理和真實興趣兩種心理,完全去除流行度偏差會影響用戶從眾興趣的滿足。應該合理利用流行度偏差,不加劇偏差。
四、CD2AN 基本框架

我們這一次探索的工作就是如何合理地利用流行度偏差,要想合理地利用流行度偏差,需要解決一個難點:“如何提取無偏且學習充分的商品表示?”針對流行度分布差異,我們需要從商品 ID 中解耦出真實內容向量和流行度向量。針對長尾分布差異,我們借鑒了域適應的范式將整體分布對齊,借鑒了對比學習的范式將實例分布對齊。
先來介紹 base 模型的基本結構,base 模型其實就是一個經典的雙塔模型。接下來詳細介紹下我們是如何解決前面提到的兩個問題的(流行度分布差異和長尾分布差異)。
1、特征解耦模塊緩解流行度分布差異

特征解耦模塊是本文針對推薦系統中的流行度偏差問題提出的一種解決方案。該模塊通過將物品向量表示中的流行度信息與屬性信息分離開來,從而減輕流行度對物品向量表示的影響。具體地,該模塊包括流行度編碼器和屬性編碼器,通過多層感知器的組合學習得到每個物品的屬性和流行度向量表示。這個模塊的輸入是物品的屬性特征,例如物品 ID、物品類目、品牌等,如上圖模型結構中的右邊部分所示。這里會有兩個約束,包括正交正則化和流行度相似度正則化,旨在將流行度信息與物品屬性信息分離。其中,通過流行度相似度正則化,模塊被鼓勵將嵌入物品屬性的流行度信息與真實流行度信息對齊,而通過正交正則化,模塊被鼓勵在編碼中保留不同的信息,從而實現分離流行度信息和物品屬性信息的目標。
我們還需要一個學習真實流行度的模塊,如上圖模型結構中的左邊部分所示,它的輸入主要就是商品的統計特征,然后經過一個 MLP 得到真實的流行度表示。
2、正則化緩解分布差異

接下來,我們想要解決長尾分布差異的問題。
我們借鑒了遷移學習的思想,實現熱門商品和長尾商品的分布對齊。我們在原來的雙塔模型中,引入了一個未曝光商品,使用了 MMD 的損失函數(如上圖左上所示),這個損失函數希望熱門商品域和長尾商品域的簇中心盡可能靠近,如上圖右上示意圖所示。由于這種域對齊是無監督的,可能會產生負遷移,我們做了如下優化:曝光樣本在域對齊損失上的梯度被停止,防止影響到任務損失;對于未曝光樣本,引入精排分進行知識蒸餾。
我們還借鑒了實例對齊的思想,希望可以學習得到更好的商品向量表示,主要思想就是有效共現次數越多的商品,向量表示越相似。這里的難點是如何去構造 pair。在用戶有過往行為的商品序列中,天然存在這樣的 pair。以一個用戶舉例,一條樣本包含了一個用戶的行為序列和目標商品,那么目標商品和用戶行為序列中的每個商品就能構成共現的 pair。我們在經典的對比學習的損失函數的基礎上還考慮了用戶的興趣多樣性和商品頻率,具體的損失函數公式可見上圖中左下部分。
我們可以看一個直觀的示意圖,如上圖中右下所示,灰色的點是目標商品,橙色的點是用戶的行為序列,藍色的點是我們隨機負采樣得到的負樣本。我們希望借鑒對比學習的方法去約束用戶行為序列中每個商品都和目標商品靠近。
3、有偏無偏聯合訓練

以上模塊有效地得到了商品的無偏內容表示和解耦的流行度表示,我們應該怎樣去應用呢?我們利用了無偏模型和有偏模型聯合訓練的方式,無偏商品向量可以基于解耦模塊及正則化提取,為了能夠利用流行度信息,我們還引入了流行度特征,有偏模型只會繼承流行度偏差,不會加劇偏差。線上服務部分,如上圖右邊所示,我們將無偏的商品表示和有偏的商品表示通過參數 α 融合起來得到線上的商品表示,這樣即可通過用戶向量來召回商品,這個 α 是調節召回關注流行度信息的程度。
4、離線及線上實驗

上圖中展示了這個模型離線及線上的效果。在離線實驗中,我們引入了 C-Ratio 的指標,來衡量召回結果中有多少商品是高曝光商品。通過離線實驗我們可以看出各個模塊都有一定程度的貢獻。無偏模型在線上效率指標方面并沒有收益,說明流行度信息是有用的,我們還是需要使用有偏模型去利用流行度信息。

最后,我們對模型結果做了可視化的展示。我們發現新的模型結構的確可以將高爆商品和長尾商品的分布記性對齊,解耦出來的流行度表示向量和商品無偏的內容表示幾乎是沒有交集的,并且同類目的商品能有更緊密的聯系,通過對 α 的調整,可以讓模型有方向地去擬合用戶的從眾興趣和真實興趣。
今天的分享論文標題是《Co-training Disentangled Domain Adaptation Network for Leveraging Popularity Bias in Recommenders》。
五、問答環節
Q1:未曝光樣本是怎么加入到樣本中的?
A1:離線生成的,針對一條樣本,我們可以拿到目標正樣本及對應的類目,然后離線地隨機采樣出若干個和目標正樣本相同類目的商品,掛載到訓練樣本中。
Q2:引入同類的未曝光樣本,會不會增加學習難度?
A2:引入的未曝光樣本是沒有標簽的,是通過無監督的方式來進行分布對齊,可能會存在負遷移的情況,我們用了兩個技巧來解決這個問題:曝光樣本在域對齊損失上的梯度被停止,防止影響到任務損失;對于未曝光樣本,可以引入精排分進行知識蒸餾。
Q3:未曝光樣本獲取精排分成本會不會很高?
A3:離線對樣本用精排模型打一遍分,作為特征來使用,性能還好。
Q4:未曝光樣本是進精排未曝光的樣本嗎?
A4:不是,這樣大概率還是一個高爆品,我們使用的是全局同類目下隨機采樣的結果。