未來已來:數據如何驅動AI大模型的競爭

隨著人工智能的迅猛發展,高質量數據的重要性已愈發明顯。以大型語言模型為例,近年來的飛躍式進展在很大程度上依賴于高質量和豐富的訓練數據集。相比于GPT-2,GPT-3在模型架構上的改變微乎其微,更大的精力是投入到了收集更大、更高質量的數據集來進行訓練。例如,ChatGPT與GPT-3的模型架構類似,但使用了RLHF(來自人工反饋過程的強化學習)來生成用于微調的高質量標注數據。
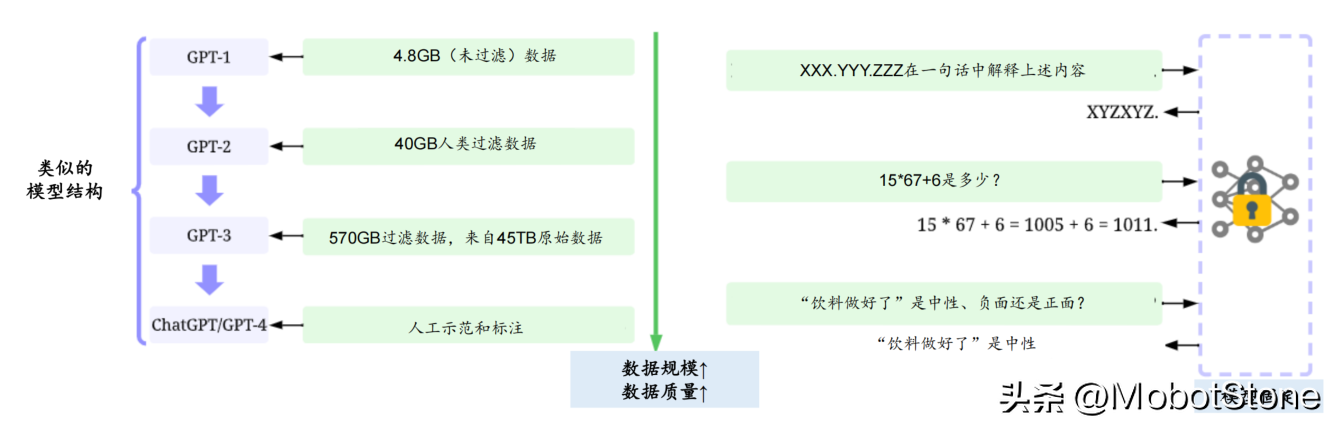
認識到這一現象,人工智能領域的權威學者吳承恩發起了“以數據為中心的 AI”運動,這是一種新的理念,它主張在模型架構相對固定的前提下,通過提升數據的質量和數量來提升整個模型的訓練效果。這其中包括添加數據標記、清洗和轉換數據、數據縮減、增加數據多樣性、持續監測和維護數據等。因此,未來在大模型開發中,數據成本(包括數據采集、清洗、標注等成本)所占的比例可能會逐步提高。
AI大模型需要的數據集應具備以下特性:
(1)高質量:高質量的數據集可以提高模型的精度和可解釋性,同時縮短模型收斂到最優解的時間,也就是訓練時長。
(2)大規模:在《Scaling Laws for Neural Language Models》一文中,OpenAI提出了LLM模型的"伸縮法則",即獨立增加訓練數據量、模型參數規模或延長模型訓練時間,預訓練模型的效果會持續提升。
(3)多樣性:數據的多樣性有助于提高模型的泛化能力,過于單一的數據可能會導致模型過度擬合訓練數據。
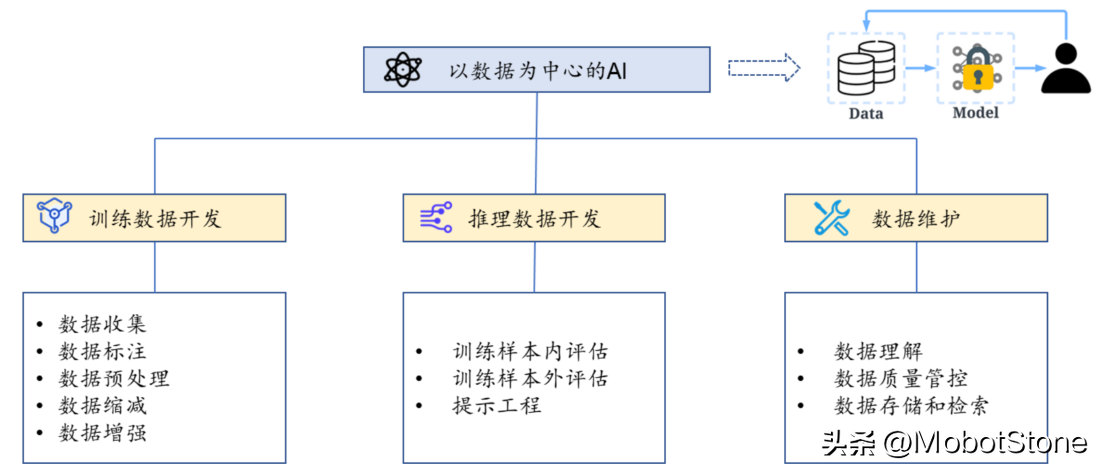
數據集的生成與處理
數據集的建立流程主要包括以下步驟:
- 數據采集:數據采集的對象可能包括各種類型和格式的視頻、圖片、音頻和文本等。數據采集常用的方式有系統日志采集方法、網絡數據采集方法以及ETL。
- 數據清洗:因為采集到的數據可能存在缺失值、噪聲數據、重復數據等質量問題,數據清洗就顯得尤為重要。數據清洗作為數據預處理中至關重要的環節,清洗后的數據質量在很大程度上決定了AI算法的有效性。
- 數據標注:這是流程中最重要的一個環節。管理員會根據不同的標注需求,將待標注的數據劃分為不同的標注任務。每一個標注任務都有不同的規范和標注點要求,一個標注任務將會分配給多個標注員完成。
- 模型訓練:模型訓練人員會利用標注好的數據訓練出需要的算法模型。
- 模型測試:測試人員進行模型測試并將測試結果反饋給模型訓練人員,模型訓練人員通過不斷地調整參數,以便獲得性能更好的算法模型。
- 產品評估:產品評估人員需要反復驗證模型的標注效果,并對模型是否滿足上線目標進行評估。只有經過產品評估環節的數據才算是真正過關。
然而,盡管中國的數據資源豐富,但由于數據挖掘不足,數據無法在市場上自由流通等因素,導致優質的中文數據集仍然稀缺。據統計,ChatGPT的訓練數據中,中文資料的比重不足千分之一,而英文資料占比超過92.6%。此外,加利福尼亞大學和Google研究機構的研究發現,目前機器學習和自然語言處理模型使用的數據集有50%是由12家頂級機構提供,其中10家為美國機構,1家為德國機構,只有1家機構來自中國,即香港中文大學。
我們認為,國內缺乏高質量數據集的原因主要有以下幾點:
- 高質量數據集需要巨大的資金投入,但目前國內對數據挖掘和數據治理的投入不足。
- 國內相關公司往往缺乏開源意識,導致數據無法在市場上自由流通。
- 國內相關公司成立較晚,數據積累相對于國外公司要少。
- 在學術領域,中文數據集的重視程度低。
- 國產數據集的市場影響力和普及度相對較低。
目前,國內科技互聯網頭部企業主要通過公開數據和自身特有數據來訓練大模型。例如,百度的“文心”大模型使用的特有數據主要包括萬億級的網頁數據,數十億的搜索數據和圖片數據等。阿里的“通義”大模型的訓練數據主要來自阿里達摩院。騰訊的“混元”大模型的特有訓練數據主要來自微信公眾號、微信搜索等優質數據。華為的“盤古”大模型的訓練數據,除了公開數據,還有B端行業數據加持,包括氣象、礦山、鐵路等行業數據。商湯的“日日新”模型的訓練數據中,包括了自行生成的Omni Objects 3D多模態數據集。
中國的數據環境和未來
盡管現狀尚有不足,但中國的數據環境仍有巨大的潛力。首先,中國是全球最大的互聯網用戶群體,日產數據量巨大,為構建大規模高質量數據集提供了基礎。其次,中國政府對于AI和數據治理的重視,無論是政策支持還是資金投入,都為數據環境的改善和發展提供了有利條件。
未來,中國需要在以下幾個方面進行努力:
- 建立數據采集和清洗系統:建立一套完整的數據采集和清洗系統,確保數據的質量和有效性,為后續的模型訓練提供可靠的數據基礎。
- 提高公開數據的可獲取性和使用性:鼓勵公司、研究機構等公開數據,讓數據在市場中自由流通,從而提高數據的可獲取性和使用性。
- 加大數據標注投入:通過提高標注效率和質量,降低標注成本,從而獲取更多、更高質量的標注數據。
- 培養更多的數據科學家和AI工程師:通過教育和培訓,增加數據科學家和AI工程師的數量和素質,以推動中國的AI研究和應用。
- 加強國內外的數據合作:通過數據合作,借鑒國外的成功經驗,改進數據的采集、處理、使用等方面的技術和方法,以提升中國數據的質量和價值。
數據是AI模型的"燃料",未來AI大模型的競爭,無疑將更加依賴高質量的數據。因此,對數據的投入和利用,將決定中國在全球AI競賽中的地位和成績。