













Kubernetes 集群的災難恢復
業務連續性的重要性
業務連續性是指制定應對重大中斷和災難的策略。災難恢復(DR) 幫助組織在發生中斷或災難時恢復和恢復業務關鍵功能或正常操作。
高可用性集群 是支持關鍵業務應用程序的服務器組。應用程序在主服務器上運行,如果出現故障,應用程序操作將轉移到輔助服務器上,并在輔助服務器上繼續運行。
與容器前相比,災難恢復策略的工作方式顯著不同。那么關系就簡單直接了,應用程序和應用服務器之間是一對一的映射。對所有內容進行備份或快照以便在發生故障時進行恢復是過時的方法。
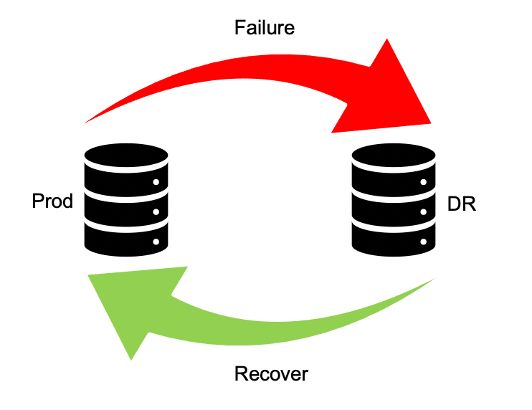
災難恢復類型
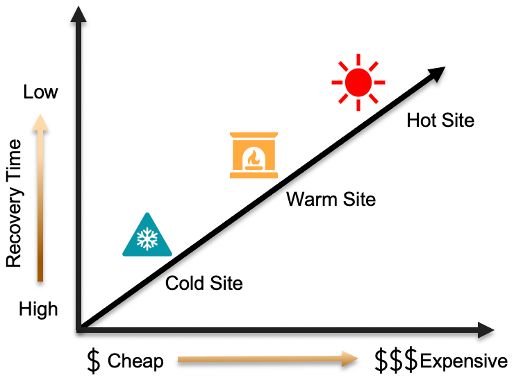
在我們討論不同的災難恢復方法之前,了解不同類型的災難恢復站點非常重要。容災站點分為冷站點、溫站點、熱站點三種。
冷站點:這是基本選項,需要最少的硬件/設備或沒有硬件/設備。將不會有連接、備份或數據同步。盡管這是最基本、最便宜的選項之一,但它還沒有準備好承受故障轉移的影響。
暖站點:與冷站點相比,這種類型的升級選項很少。可以選擇網絡連接和硬件。這具有數據同步功能,并且可以在數小時或數天內解決故障轉移,具體取決于設置類型。
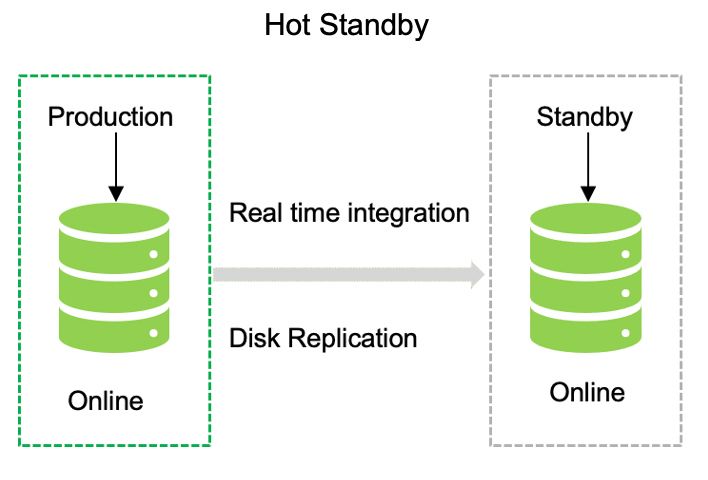
熱門站點:這是該地塊中最優質的選項,具有配備齊全的硬件和連接以及近乎完美的數據同步。與其他兩種類型的站點相比,這是一種昂貴的設置類型。
災難對組織的影響可能非常昂貴,因此首先做出最佳選擇非常重要。災難恢復管理可以減輕災難造成的破壞性事件的影響。沒有一種方法/選項是完美的,并且可能會根據企業/組織的要求和類型而有所不同。
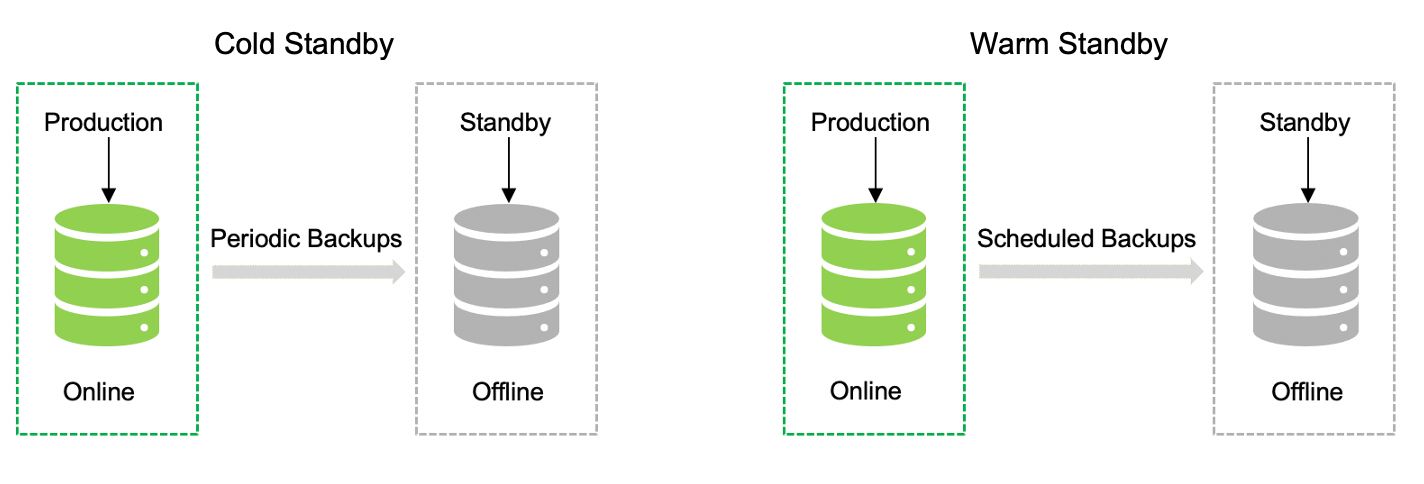
傳統災難恢復方法
選項 1:我們可以通過定期備份來實現冷備用,或者您可以通過批量/計劃復制數據來實現熱備用。這里的主要區別在于從主數據中心到災難恢復的復制類型。在此選項中,只有在線購買備用設備后,應用程序和數據才可用,并且由于定期/計劃的備份而導致數據丟失的可能性很高。
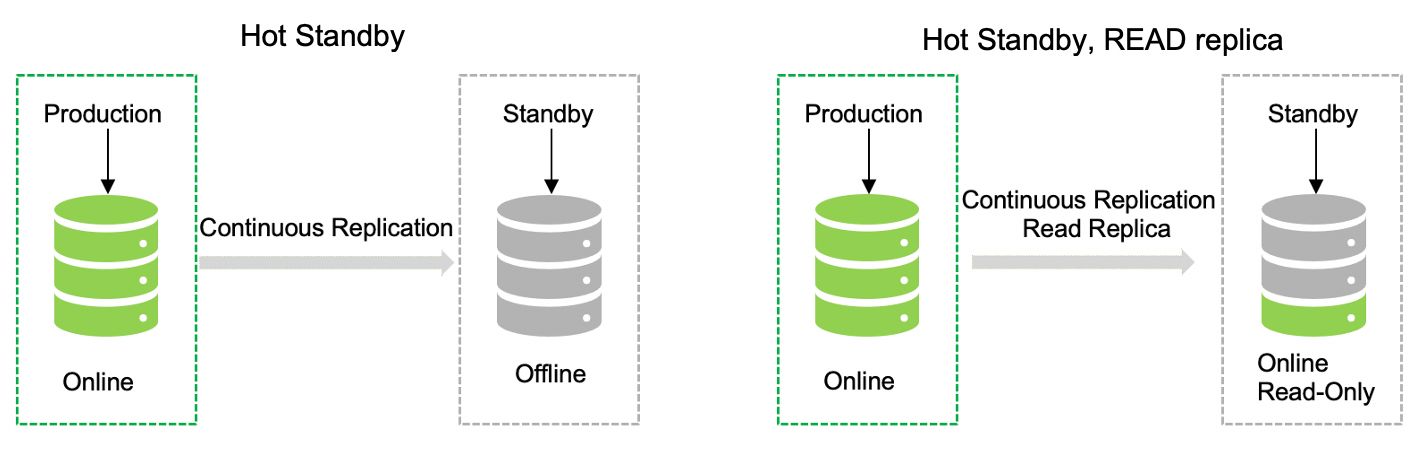
選項 2: 在這種情況下,我們采用連續復制,復制之間的基線時間非常短。這是一種熱備,另一種是帶有只讀副本的熱備。這意味著兩者在讀取數據方面將是相同的,而數據只能在主數據中心位置寫入。備用可以在發生中斷時立即使用。
選項 3:這是進行災難恢復設置的最可靠的方法。在這種情況下,您需要維護兩個具有實時數據無縫復制的活動數據中心。該模型需要使用最新技術和工具堆棧進行高級設置。這是一個綜合模型,但可能很昂貴。配置和維護可能很復雜——運行這種設置需要特定的技能。
容器災難恢復
現在,我們來討論一下如何利用容器化生態系統進行災難恢復管理。
Kubernetes 集群:部署 Kubernetes 時,您將獲得一個集群。Kubernetes 集群由一組稱為節點的工作機器組成,它們運行容器化應用程序。每個集群至少有一個工作節點。工作節點托管作為應用程序工作負載組件的Pod 。控制平面管理集群中的工作節點和 Pod。在生產環境中,控制平面通常跨多臺計算機運行,集群通常運行多個節點,提供容錯和高可用性。要了解有關集群組件的更多信息,請參閱鏈接。
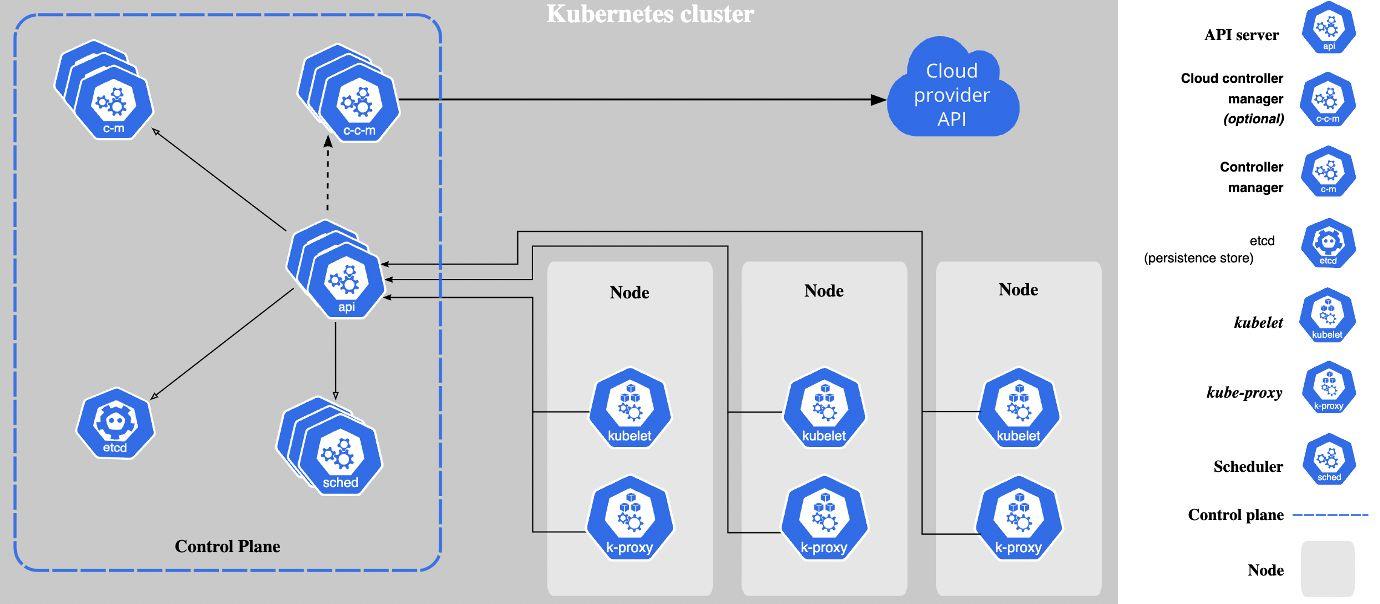
在此設置中,應用程序不會部署到一臺定義的服務器中。它可以調度在任何工作節點上。容量管理將在集群中完成,因為 Kubernetes 是一個編排工具——根據節點的可用性分配部署。
我們需要備份什么
我們知道 Kubernetes 生態系統的本質是非常動態的,這使得更傳統的備份系統和技術更難在 Kubernetes 節點和應用程序環境中良好運行。RPO 和 RTO 可能需要更加嚴格,因為應用程序需要不斷啟動和運行。
以下是備份的重要事項列表:
- 配置
- 容器鏡像
- 政策
- 證書
- 用戶訪問控制
- 持久卷
集群中有兩種類型的組件:有狀態組件和無狀態組件。狀態完整組件會留意、期待響應、跟蹤信息,并在未收到響應時重新發送請求。ETCD 和 Volumes 是有狀態組件。在 Kubernetes 平面的其余部分,工作節點和工作負載是無狀態組件。備份所有有狀態組件非常重要。
ETCD備份
ETCD 是一種分布式鍵值存儲,用于保存和管理分布式系統保持運行所需的關鍵信息。最值得注意的是,它管理流行的容器編排平臺 Kubernetes 的配置數據、狀態數據和元數據。
我們可以利用ETCD內置的快照功能來備份ETCD。另一種選擇是拍攝存儲卷的快照。第三個選項是備份 Kubernetes 對象/資源。恢復可以分別從快照、卷和對象完成。
持久卷備份
Kubernetes 持久卷是管理員配置的卷。它們是使用特定的文件系統、大小和識別特征(例如卷 ID 和名稱)創建的。
Kubernetes 持久卷具有以下屬性
- 它是動態配置的或由管理員配置的
- 使用特定文件系統創建
- 有特定的尺寸
- 具有識別特征,例如卷 ID 和名稱
為了讓 pod 開始使用這些卷,需要聲明它們,以及 pod 規范中引用的聲明。持久卷聲明描述 Pod 所需的存儲量和特征,查找任何匹配的持久卷,并聲明這些。存儲類描述默認卷信息。
從持久卷創建卷快照:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: new-snapshot-test
spec:
volumeSnapshotClassName: csi-hostpath-snapclass
source:
persistentVolumeClaimName: pvc-test
恢復卷快照
您可以引用 aVolumeSnapshot來PersistentVolumeClaim使用現有卷中的數據配置新卷,或將卷恢復到您在快照中捕獲的狀態。VolumeSnapshot要在 a 中引用 a PersistentVolumeClaim,請將數據源字段添加到您的PersistentVolumeClaim.
在此示例中,您引用VolumeSnapshot在新聲明中創建的PersistentVolumeClaim并更新Deployment來使用新聲明。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-restore
spec:
dataSource:
name: my-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
storageClassName: standard-rwo
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
恢復 Kubernetes 平臺操作
我們可以通過兩種方式恢復k8s平臺:重建或恢復。以下是恢復平臺運營的一些策略:
- 平臺備份與恢復
我們需要使用備份工具來運行此操作,該工具將從與應用程序 ETCD、配置和映像相關的源集群中獲取備份,并將這些信息存儲在備份存儲庫中。備份完成后,您需要使用相同的備份工具從目標集群運行此恢復操作,并且可以從復制存儲庫恢復信息。
- 從快照恢復虛擬機
該策略僅適用于 ETCD 恢復。從 ETCD 快照恢復 Kubernetes 集群所涉及的步驟可能會有所不同,具體取決于 Kubernetes 環境的設置方式,但下面描述的步驟旨在讓您熟悉基本過程。還值得注意的是,下面描述的過程替換了現有的 ETCD 數據庫,因此如果組織需要保留數據庫內容,則必須在繼續之前創建數據庫的備份副本。
- 安裝ETCD客戶端
- 確定適當的 IP 地址
- 編輯清單文件以更新路徑
- 找到規格部分
- 將初始集群令牌添加到文件中
- 更新掛載路徑
- 替換軟管路徑的名稱
- 驗證新恢復的數據庫
- 故障轉移到另一個集群
如果一個集群出現故障,我們會使用故障轉移集群。這些集群與基礎設施和無狀態應用程序相同。然而,配置和秘密可能不同。在設置時,這兩種類型的集群可以與 CI/CD 同步。由于我們有并行運行的雙集群,因此在設置和維護方面可能會很昂貴。
- 在多站點情況下故障轉移到另一個站點
在這個策略中,我們需要構建一個跨多個站點的集群。這適用于云和本地。由于 ETCD 仲裁,始終建議擁有兩個以上站點且站點數量為奇數,以便在一個站點發生故障時保持集群運行。與其他選項相比,這是一種流行且有效的方式。節省收益取決于我們如何管理產能。
- 從頭開始重建
這就是所謂的GitOps,這里的概念是,我們為什么不在出現故障的情況下重建系統而不是修復呢?如果集群出現故障,我們可以從git包裝器構建整個集群,并且不需要對ETCD進行備份。這非常適合無狀態應用程序,但如果您將其與持久性數據相結合,那么我們需要尋找支持和恢復存儲的選項。
結論/總結
根據需求、復雜性和預算來規劃和設計自己的災難恢復策略非常重要。提前做好計劃非常重要。我們需要知道基礎設施的容忍程度是多少,可以承受多少服務損失等,從而設計出經濟高效的災難恢復策略。所需的另一項關鍵了解是關于工作負載。我們正在運行有狀態的工作負載還是無狀態的工作負載?我們需要了解與備份和恢復相關的底層技術和依賴項。當涉及需要 100% 正常運行時間和可用性的任務關鍵型云原生應用程序的 DevOps 時。在發生災難時,應用程序需要繼續可用并順利運行。














