Shopee 多語言商品知識圖譜技術構建方法和應用

Shopee 是一家服務于全球多個市場的電商平臺,致力于為消費者提供更加便捷,安全,快速良好的消費體驗。Shopee 深耕多種不同的語言和市場,在這種國際化的服務平臺上,需要處理多語言和混合語言的復雜語料。我個人的工作主要聚焦于電商平臺商品有關的圖譜以及圖譜算法的構建,也希望通過本次分享能給大家帶來一些收獲。其中就包含了:商品知識圖譜在多元市場的構建經驗,商品知識圖譜最新的進展以及新的應用,以及如何構建技術模型和技術框架來實現滿足電商復雜應用的訴求。
一、知識建模
首先分享一下知識建模相關的內容。
1、Knowledge Ontology

從上圖中可以看到,消費者使用 Shopee 電商 App,可以通過分類選項,找到具體分類下的商品,進行瀏覽和購買。分類體系是商品圖譜中用來管理商品信息的非常重要的本體層。商品圖譜的本體層,主要包含商品的分類和每個分類下具體的屬性,通過這樣的分類和屬性的組合,來表示整個商品圖譜中每一個商品實體的具體信息。
電商分類是一個樹狀的結構,從最粗的粒度到最細的粒度,不同的分類中有不同的深度。以移動電子類為例,在其下面又可以細分出可穿戴類的電子產品,在可穿戴類中又包括了移動手表等等。對于細分品類,我們會梳理出大家關心的屬性項和屬性值。以 T-shirt 為例,消費者和平臺可能會比較關注 T-shirt 的品牌、材質等信息,這里的品牌、材質是屬性項(Attribute Type)。我們會梳理出品牌、材質這些屬性項對應的具體屬性值(Attribute Value),比如材質里面包含純棉 Cotten、真絲 Silk 等。
通過類目(category),屬性項(Attribute Type),屬性值(Attribute Value)這樣一個組合體,就可以構建出商品知識圖譜的本體層。用這樣的本體來表達所有具體商品實體的信息。
2、Knowledge Ontology - Ontology and Entity
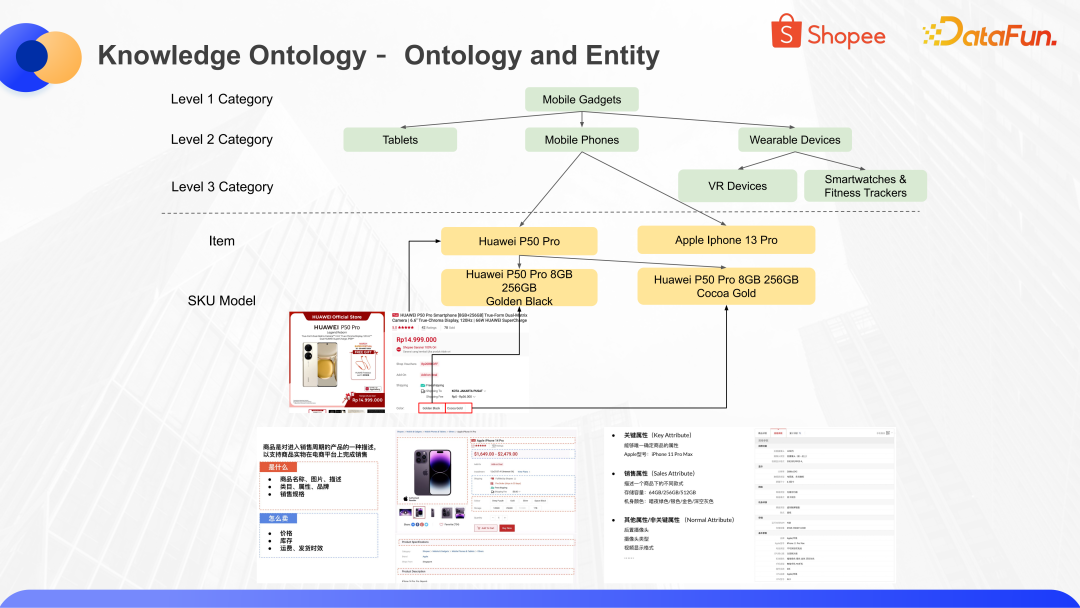
在這個圖中,上面是本體,下面是每個商品的實體。當然在商品實體里,也會有不同的粒度。比如我們日常在買東西的時候看到的一個頁面,其實是一個 item,這是商品維度。當我們選擇了一個具體的型號去購買,就是選擇了一個 SKU Model,這是最細粒度的商品信息。這樣一個本體體系和商品實體的組合,就可以實現大規模商品信息的結構化管理和表示。
3、Knowledge Ontology - Uplift All in One

隨著經濟的發展,電商為了滿足迅速變化的市場需求也在不斷地演變,電商平臺的本體層也不是一成不變的。
Shopee 建設初期,在各個語言市場有著自己的本體分類和設計。后來我們發現,統一的一套更加有利于多語言語料和多語言市場之間商品的互通,和商品信息在不同語言之間高效的轉化,所以我們把不同語言之間的本體匯總成了 Global-Category-Tree 這樣全球統一的體系。就可以在同樣的分類體系,同樣的屬性體系下面,用不同版本的語言去管理所有市場的商品實體信息。
4、Knowledge Ontology - Uplift Continuously

在圖譜本體方面,我們遇到的核心痛點是,本體如何與時俱進的去迭代變更。隨著市場的發展,會不斷涌現出新的品類、新的項和值。但是新品、新項和新值對于存量的語料來說是比較少的,那么如何能及時的捕捉到它們呢?這個技術的思想就要從 New Phrase Mining 開始。普通 NER 模型在 OOV 問題的表現上,并不能很好地滿足我們的應用訴求,我們的核心思想是引入 MINER 模型,去緩解和改善 OOV 的問題。主要思想是:以 SpanNER 為基礎模型,引入 information bottleneck 層,借助互信息的形式改造目標函數,幫助模型去優化對上下文的捕捉能力。從而提升模型的泛化能力。通過這樣不斷去挖掘新的品類詞、屬性項、屬性值的技術,實現了 Span level accuracy 提升 4.5%+,Value level recall 提升 7.4%+,效果還是比較可觀的。基于這樣一套不斷挖掘的思路,就可以幫助智能推薦本體層的調整建議,結合線上效果評估,基于新的語料去不斷進行挖掘的迭代和循環。
二、知識獲取
1、Challenges

在日常的知識獲取工作中,我們也遇到了比較多的挑戰,比如在處理商品語料的時候,會遇到各種各樣的語言,甚至是各種復雜語言的混合體。同時還要處理細粒度的分類,分類體系可以達到上千類。在這樣的細粒度分類之下,不同的分類有不同的語料特征,分類結合屬性項維度能夠達到 10K+ 的不同組合。再結合每個項下面不同的屬性值,整體能夠達到 260K+ 量級的規模。在這樣的規模下,整體服務的精度還要維持在 90% 之上。
面對這樣的挑戰,我們需要更好的技術思路,基于有限的開發人員和研發時間,能夠快速響應線上服務迭代的訴求,保證線上服務的效果,所以我們需要有一套 Scalable Technique Structure 來響應我們的應用訴求。
2、Item Category Classification

首先介紹下商品分類相關的 task 和解決方案。商品分類問題的核心目標就是理解商品的分類信息,并且提升和保障其準確性。同時還需要把分類的服務提供給商家商品發布的系統,保證系統的效率及穩定性。具體的問題可以拆分為幾個 task:
① 如何對新發的商品做精準的推薦。
② 存量的商品牽引到新的分類體系下。
③ 及時捕捉和修正存量商品信息中的錯誤。

隨著電商平臺的發展,商品信息的表達也在不斷變化來吸引用戶的關注,這對于模型而言就是一個挑戰,不僅要構建一個精準的模型,還要不斷地迭代更新保持它的效果。
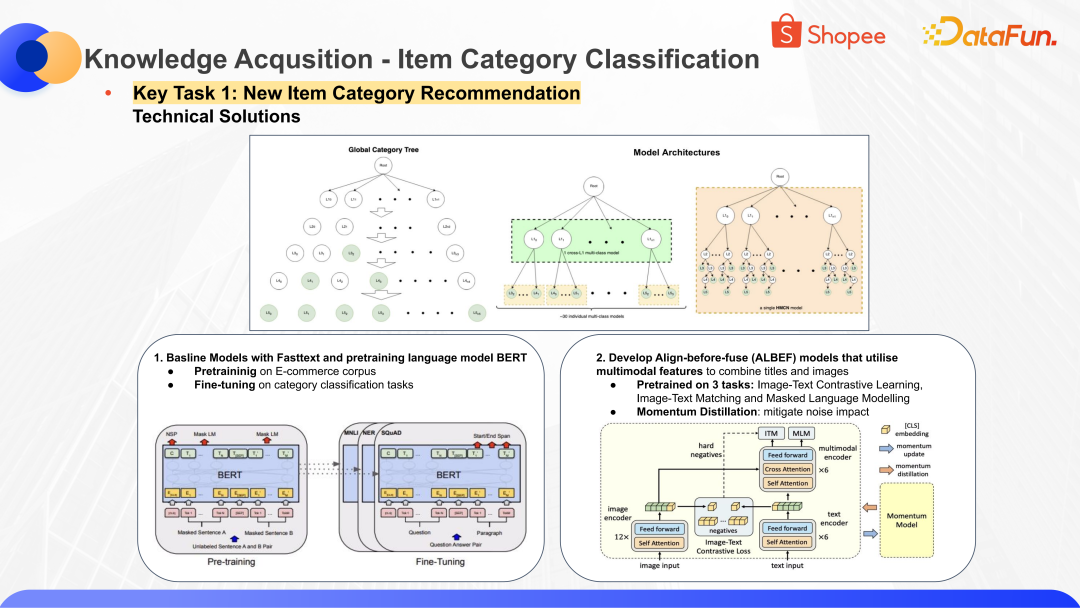
為了應對信息分類,需要設計一套模型的架構。這樣的模型架構我們有好多種,比如說第一種就是把每個商品做一個粗粒度的分類,可能分到最粗的幾十大類,在每個大類下有更細粒度的分類,這樣每個子模型需要去分類的類別量是比較小的,分類效果也會比較精細。第二種是更加 end-to-end 的框架,我們直接把商品信息輸入,去找到它使用的最細粒度的分類。
這兩種架構各有其優缺點。第一種的缺點就是需要管理的模型是很多的,以一個語言市場為例,需要管理的模型就有幾十個。再結合十多個語言市場,管理的模型量就達到上百量級。第二種模型更加端到端,但是在一些細分品類上的效果就可能各有參差,并且在細粒度品類的優化上也會同時影響其他品類的效果。這兩種體系我們會根據實際效果做更科學的選擇。
無論哪種體系,底層都依賴了文本類的分類方法和圖文結合多模態的方法。常見的文本類模型有 Fasttext 和 BERT 等等。多模態部分我們在對比各種模型后,選擇基于 Align-before-fuse 做商品類圖文信息的綜合識別,最終找到適合的分類。Align-before-fuse 模型的核心思想是先通過 Image-Text Contrastive Learning,Image-Text Matching 和 Masked Language Modelling 做預訓練,再通過 Momentum Distillation 減輕臟數據的影響,從而實現比較好的分類效果。

隨著模型的開發上線和應用,我們在各個市場的主要品類下面的精度可以維持在 85%~90%+。同時也能支持不同的發布體系的高頻率調用。

第二個任務就是對類目體系做變更之后如何快速的響應,把商品轉化到新的品類上。這里的業務背景是隨著市場的發展,很多新品的涌現以及品類的壯大。如果一直用比較粗的分類方式,是不利于下游電商系統分發和客戶消費體驗的,需要進行細化的拆分。對技術就比較有挑戰,因為新的分類是不能直接拿到天然的訓練語料的,所以工作的重點就是如何能夠智能化地構建訓練語料,升級并且響應新的分類體系的要求。

上圖展示了數據挖掘的流程和思路,核心思想是基于 Keywords-Mining 和 OOD-Detection 的方法,去挖掘有變化的或者新興品類的關鍵詞,基于關鍵詞去做自動化樣本的構建。比如挖掘出新興品類的關鍵詞之后,存量的商品或者市場上的商品能夠被這樣的關鍵詞命中,且具備較高的執行度,那么就可以添加到訓練語料當中,成為新品類的訓練樣本。對于低執行度或者有多種可能的數據語料,再進行簡單的人工核驗,就可以快速的構建訓練樣本,幫助模型高效地迭代。
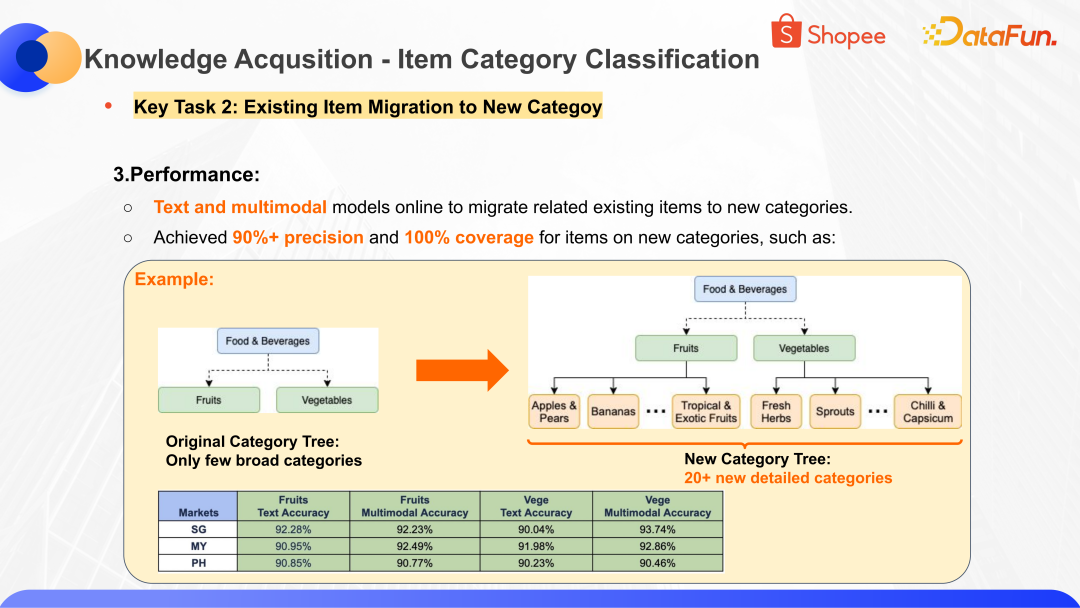
以上圖的案例為例,原始的 Global Category Tree 有兩個分類,在拓展到 20+ 的細粒度的分類之后,無論文本模型還是多模態模型在多個不同的市場都可以達到 90%+ 的精度,可以高效地響應分類調整問題。

第三個任務是如何對分類錯誤的商品去捕捉和修正。這里的業務背景是錯放的商品信息無論是對消費者還是平臺都帶來了各種各樣的負面影響。比如增加額外的物流成本,影響商家的銷量,增加對商品管控的難度。技術上的難點是,這類錯放商品,對于模型本來也是較為困難的案例,分類模型對這些數據較難精準地捕捉。
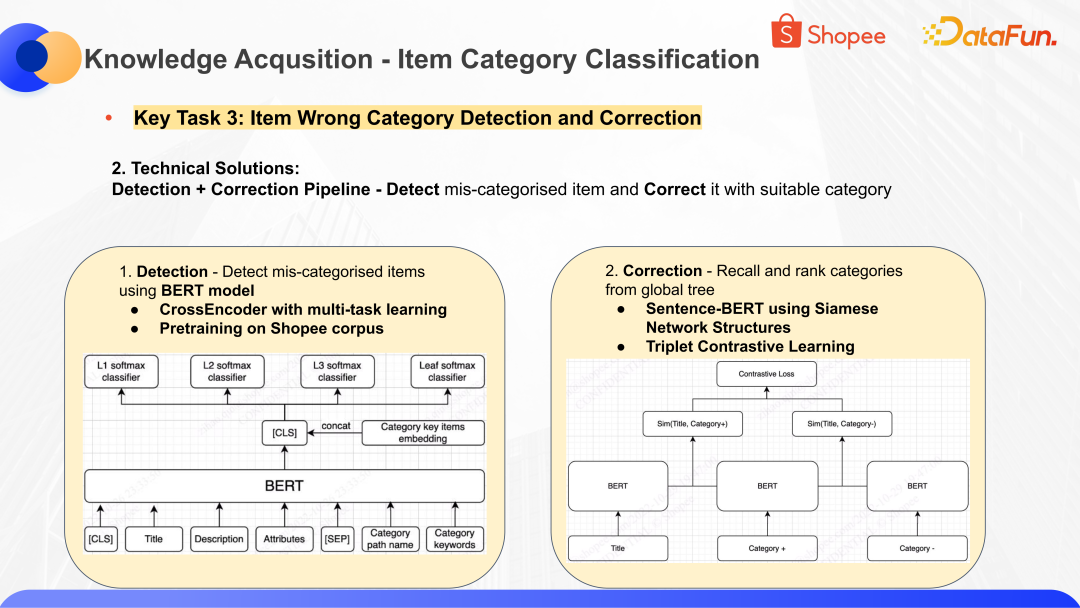
為了解決這個問題,我們構建了識別錯放商品的模型 Detection,再結合識別出來的錯放的商品做修正 Correction 的工作,找到一個更適合的分類。在 Detection 這個模型中,核心思想是基于 CrossEncoder with multi-task learning,對 Shopee 語料庫進行預訓練,然后做分類。通過對商品信息和分類信息做拼接,識別出在各個分類層上是否屬于錯誤的分類。對于錯放的商品,通過召回和排序的方式,找到最接近或者執行度最高的分類。核心思想是基于 Sentence-BERT using Siamese Network Structures 和 Triplet Contrastive Learning 優選出可信度最高的一個或多個分類,并進行修正。

這里面需要去處理或標注的存疑語料的規模是非常大的,那么如何通過只標識少量的數據就實現模型的提升呢?在這個問題之上,我們進行了數據語料優選的工作,可以理解為通過主動學習的方式,去學習語料的置信度,在經過三到四種模型,通過投票和優選的方法,學到哪些數據預料是異常值。在采樣的時候對 centorid data、outlier data、random data 都進行采樣,通過這樣的方式縮小語料的標注量,從而實現模型的提升。

結合以上這些工作,識別商品是否類目錯放的服務能夠達到 98% 以上的精度。搜索查詢相關的 badcase 在重點品類上減少了 50% 左右。
3、Item Attribute Recognition
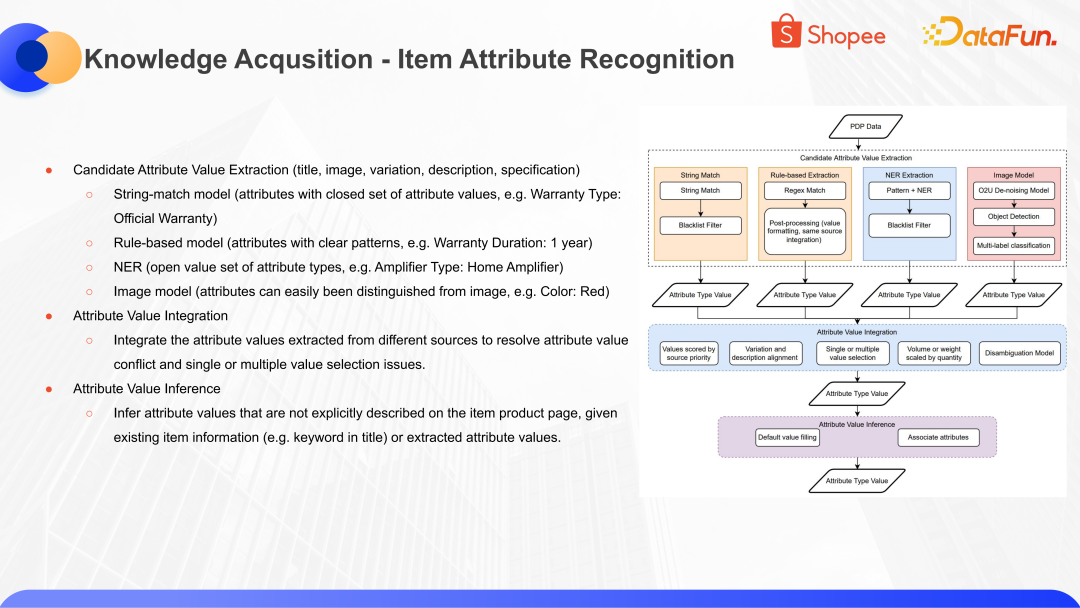
接下來介紹商品屬性新增的識別。從上圖可以看出,輸入商品的信息之后,屬性識別基于四種不同的思想:第一種是基于 String-match Model;第二種是基于 Rule-based Model,比如 Warranty Duration: 1 year,這種是符合語料的特征和規則;第三種是基于 NER model 去做屬性的識別;第四種是基于Image model,視覺和多模態相關的模型。
基于這四種不同的識別思路,從商品信息中獲取到多種可能的屬性項和值。對于這些識別到的屬性項和值,去做一層屬性值整合,結合各種信息優選出置信度較高的項和值。比如學習來源的置信度等等。在學習出了置信度較高的屬性值之后,還需要結合屬性值之間的關系,補充出商品信息之外推理出的商品知識。

開放集屬性值通常會有很多不同的表達,NER 模型比較適合去捕捉商品信息表達中已有的值。所以我們把商品信息屬性的識別做了從 NER 模型到 MRC 模型的轉換。通過 MRC 的解決思路,我們希望能夠使用 Wordpiece tokenizer 去緩解 OOV 的問題,并且通過 LaBse PLM 去解決 multi-lingual 的一些問題,通過 MRC+CRF 完成文本屬性和商品屬性的識別抽取任務。

識別和抽取出了大量的屬性值之后,會發現它的表達各種各樣,會存在拼寫錯誤或同義詞的現象。就像三星這個案例,都是藍色,但是會有 “blue” 和 “biru” 不同的表達,我們需要對這些詞做歸一,這樣才能更好地響應下游的應用,并把所有的商品信息轉化到標準的信息層,方便下游系統更高效地理解。

接下來我們還需要對這些信息做一層歧義的理解,因為我們發現從商品中抽出的信息會有沖突。比如商品標題信息里面顏色是 “red”,在詳情信息里顏色是 “yellow”,“silver” 既可以標識顏色又可以表示材質,“red” 有可能是紅色也有可能是紅米品牌信息。受到 promat approach 的啟發,我們把這一問題轉化成了一個 generation task。基于 T5 的模型,上圖是整體的流程圖,重點是將數據轉換成 Template 的格式,做 Encoder 和 Decoder,最終輸出想要識別項對應的值。通過對比使用發現 T5 的表現還是不錯的,相較于其他的模型有比較大的提升。
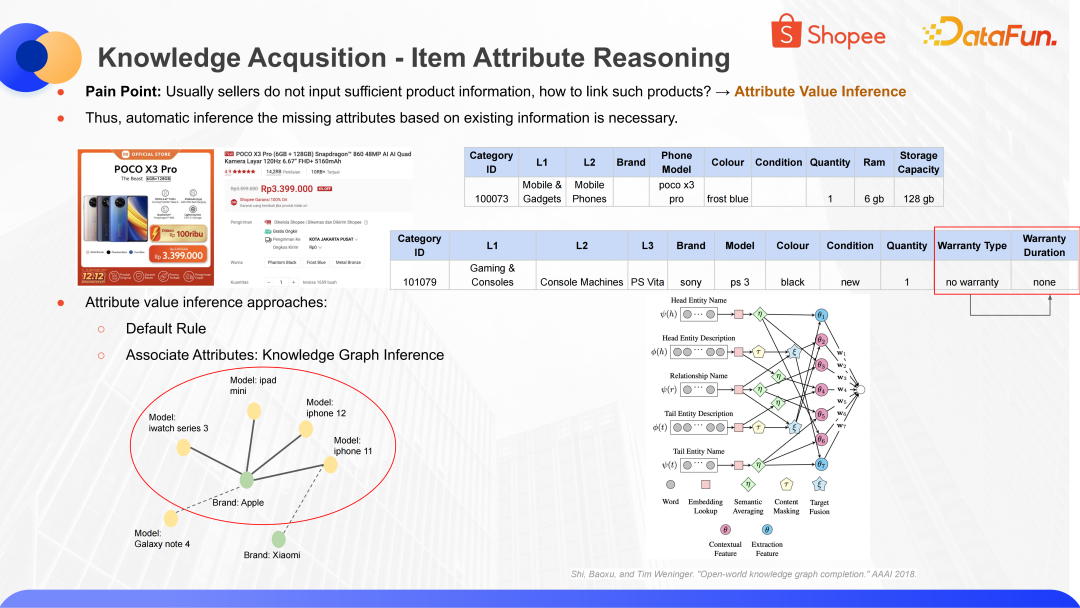
當識別出商品的信息之后,還可以利用這些信息做一些推理。比如保修類型是不保修,那保修時間這一項自然就是 None 了。這種推理可以通過挖掘知識圖譜的關聯屬性去實現。
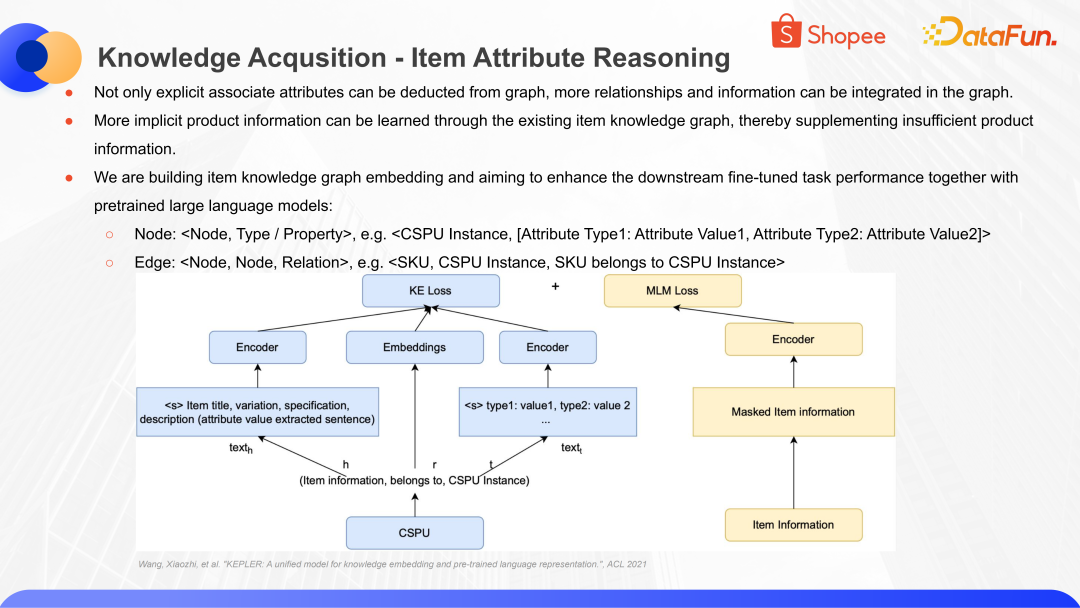
以此類推,不僅可以通過關聯屬性去補全商品信息,商品圖譜包含商品和商品間的關系,商品和屬性之間的關系,這些關系之間也可以去做一系列的信息的補全,我們也在此基礎之上構建了圖譜這樣一個體系。
三、知識融合
接下來介紹知識融合的部分,分為本體融合,實體融合和信息融合。
1、Ontology Fusion

本體層融合可以理解為商品本體,比如 Shopee 的商品分類體系和市場上其它分類體系,它們之間可以做映射和關聯,包含類目的映射、屬性項的映射、屬性值的映射。核心思想是有很多原子化的技術模塊做支撐,比如在類目的映射關聯上,可以基于商品的分類信息匯總到分類體系的映射關系。屬性項可以結合相近詞,同義詞等等,在分類下面再去構建項和值的關聯映射關系,這樣的關聯關系也會結合實際的條件做精度和條件上的限制。
2、Entity Fusion

重點介紹下實體層的融合,在電商層面可以理解為商品之間關系的識別和理解。比如同款商品、相似商品或相關商品。
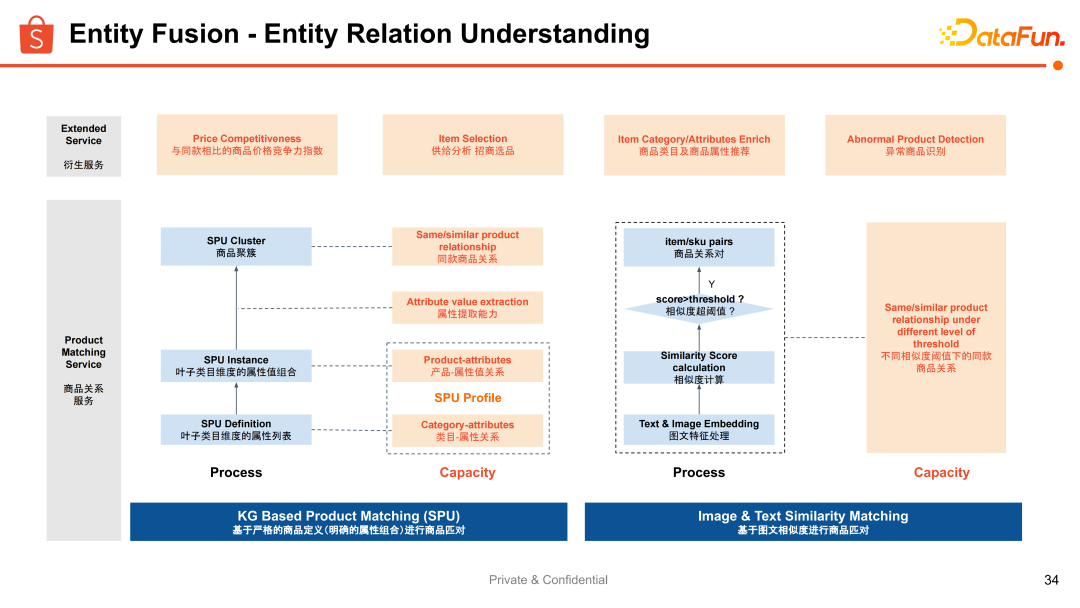
在不同關系的基礎算法上,有一些經典的思路,常見的是基于圖文相似度的匹配來找到它們的關系。更進一步的是基于商品圖譜做商品信息屬性項更細粒度的匹配,可以更加業務可解釋地去拆解出來商品之間匹配關系的具體要求。比如我們想要知道兩個商品是否滿足品牌一致、材質一致、顏色一致,還是想要更細粒度或者更粗粒度,這樣就更方便業務去定制化使用。
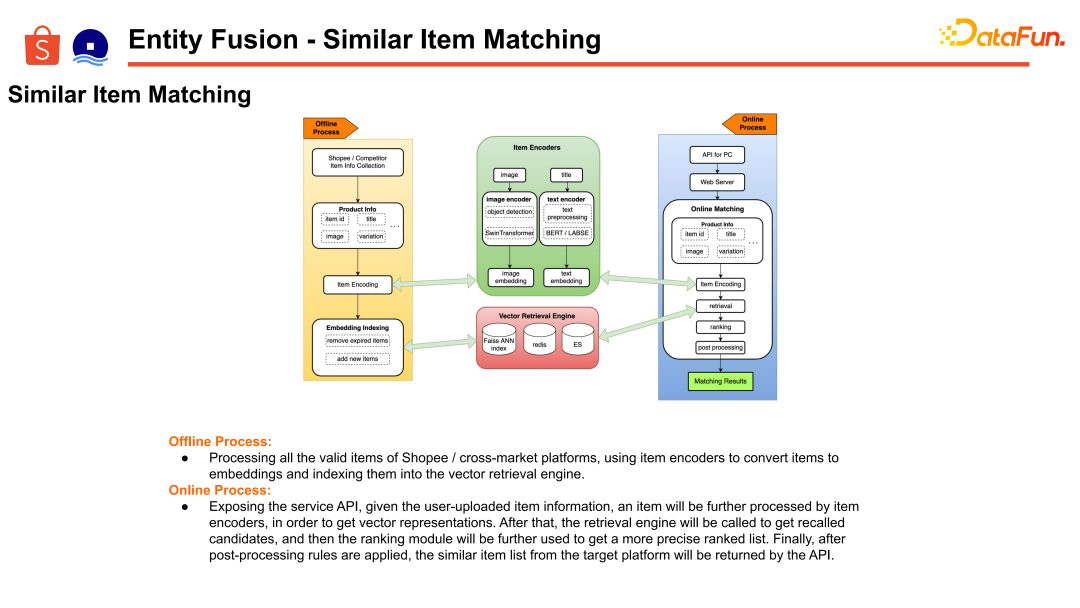
在基于圖文相似的匹配上,主要是構建了基于召回排序的框架和方法。結合商品信息做 Embedding 構建,基于圖文的 Embedding 去做檢索召回和精排,來實現基于相似度的同款關系構建。

在這個基礎之上,還希望構建更加精準的基于圖譜的屬性維度的同款關系,那么就誕生了一個概念:Standard Product Unit(spu) ,就是標準產品節點。從上圖可以看出,在每個產品的細粒度分類之下,可以定義商品關系最關注的那些項和值。比如圖上的 Apple iPhone 13 Pro 代表了一系列的產品節點,無論任何商家在任何地點售賣的 Apple iPhone 13 Pro 都是同一款產品。當然,這個產品節點還刻有更細粒度。當我們沉淀出這樣的產品節點之后,就可以連接所有符合這個產品定義的商品,來實現一個產品粒度的商品聚合。

這樣的優勢是更加可解釋,方便用戶和平臺內部運營的使用,以及定制不同粒度的聚合體。

整體的框架如上圖所示,涉及到定義的細化以及基于定義的分類,屬性的抽取,在基于定義的要求結合抽取出來的屬性做商品維度的聚合。我們把所有的模塊連接起來,就可以實現 SPU 數據資產的生產。最終不僅生產出所有的產品節點而且去連接好所有的商品信息,并且還可以把商品的信息匯到產品維度去實現最終信息層的知識融合。

所以我們就構建出了如上圖所示的知識圖譜,會有各種各樣的產品節點以及對應的分類信息、屬性信息,以及各個商品實體的連接。
四、知識應用
接下來再簡單介紹下我們一系列的知識應用。

知識應用的服務比較廣泛,比如幫助運營理解市場,做商品篩選,商品質量校驗;幫助商家在發布的時候做類目的智能化識別,價格推薦,物流信息補全;幫助消費者推薦高性價比的活動會場,以及對搜索推薦做各種智能化支撐。
五、知識圖譜展望
最后介紹下對未來知識圖譜工作的展望。

從之前的圖譜的圖可以看出來,我們的商品圖譜不只是可以連接到商品和商品屬性分類等等這樣的信息,還可以進一步拓展和用戶、商家以及各個市場平臺更高維度的信息的關聯,并且實現信息之間精準的互通和推理,基于這樣的補全去做更廣泛的業務應用。

在當前的 AIGC 時代,大量新技術的誕生沖擊著大家的思想,不斷有各種各樣的大規模語言模型誕生。隨著 chatGPT 大模型的突破,AI 的發展已經到達了一定的階段。chatGPT 的成功證實了,我們如果有足夠量的數據和足夠大的模型是能夠實現較好的知識推理的。在這樣的背景之下,做圖譜相關工作的人和我們的工作又面臨著怎樣的發展機遇和挑戰呢?
對于大模型而言,它能給圖譜提供的幫助效果并不是特別好,并不能達到端到端的需求。特別是在垂直領域,各個公司都有自己的運轉模式和業務標準。如上圖所示,我們做一個商品細粒度識別,在這個例子中,準確率大概達到 50%,還沒有達到 end-to-end 的商業應用的訴求,還需要去做細粒度的子模型的構建。并且大模型的計算在現有的算力消耗上也并不是高性價比的選擇,垂直領域的模型依然存在優勢。但是大模型可以輔助我們對垂直領域模型的優化,比如對于訓練數據的增強、樣本生成,能夠幫助垂直領域模型快速提升。
在大模型的潮流下,我們也需要思考知識圖譜能起到什么樣的作用。其實當前的大模型仍然存在著一些問題,比如大模型可能會提供非實時但看似合理的預測,以及在推理能力上對較為復雜的邏輯推理和數學推理還存在進步的空間。知識圖譜其實是在推理能力上具備一些優勢的,所以未來我們可以去探索,是否可以將知識圖譜的結構與現有的方法論做結合,并且與大模型的訓練方法做結合。
從當前的應用上來看,New Bing 已經在用搜索引擎去補充和增強 chatGPT-4 的效果了,在一定程度上也減少了知識型的錯誤。舉個例子,對于獨特的業務知識,我們是不是可以借助零微調的技術將知識圖譜的知識表達作為 prompt 去提示 GPT 大模型,來生成更符合業務場景的答案。當然這只是一些淺層的思路和應用,我相信隨著對于模型理解的不斷深入,還會有更好的結合方法。