騰訊TRS之元學(xué)習(xí)與跨域推薦的工業(yè)實(shí)戰(zhàn)

一、元學(xué)習(xí)
1、個(gè)性化建模的痛點(diǎn)

在推薦場(chǎng)景會(huì)遇到數(shù)據(jù)二八分布的問(wèn)題,20%的場(chǎng)景應(yīng)用80%的樣本,這就導(dǎo)致一個(gè)問(wèn)題:?jiǎn)文P蛯?duì)大場(chǎng)景預(yù)估更友好。如何兼顧各場(chǎng)景,提升模型個(gè)性化能力是個(gè)性化建模的痛點(diǎn)。
業(yè)界方案:
- PPNet/Poso:這種模型通過(guò)偏置gate等實(shí)現(xiàn)個(gè)性化,性能和成本較優(yōu),但是多個(gè)場(chǎng)景共享一套模型參數(shù),個(gè)性化表征受限制。
- 端上個(gè)性化:在每一個(gè)端上部署一個(gè)模型,利用端上的實(shí)時(shí)數(shù)據(jù)進(jìn)行訓(xùn)練,實(shí)現(xiàn)端模型參數(shù)的個(gè)性化,但是會(huì)依賴(lài)端的性能,并且模型不能特別大,需要使用小模型進(jìn)行訓(xùn)練。
針對(duì)業(yè)界模型存在的問(wèn)題,我們提出了如下解決思路:
- 利用云端豐富算力,為每個(gè)場(chǎng)景部署一套模型,實(shí)現(xiàn)模型的極致個(gè)性化;
- 模型通用性強(qiáng),可應(yīng)用于用戶(hù)/人群/item等個(gè)性化建模場(chǎng)景。
2、元學(xué)習(xí)解決模型個(gè)性化問(wèn)題

- 需求:為每個(gè)用戶(hù)、人群部署一套個(gè)性化的模型,模型對(duì)成本和性能是沒(méi)有損失的。
- 方案選型:如果為每一個(gè)用戶(hù)都部署一套模型,模型結(jié)構(gòu)不一樣、模型參數(shù)也不一樣,會(huì)造成模型訓(xùn)練和服務(wù)的成本比較高。我們考慮在同一模型結(jié)構(gòu)下,為每個(gè)場(chǎng)景提供個(gè)性化的模型參數(shù),來(lái)解決模型個(gè)性化的問(wèn)題。
- 部署地點(diǎn):將模型部署在云上,利用云上的豐富算力進(jìn)行計(jì)算;同時(shí)想在云上,對(duì)模型進(jìn)行靈活控制。
- 算法思路:傳統(tǒng)的元學(xué)習(xí)是解決少樣本和冷啟動(dòng)的問(wèn)題,通過(guò)對(duì)算法的充分了解,在推薦領(lǐng)域,運(yùn)用元學(xué)習(xí)的創(chuàng)新性來(lái)解決模型極致個(gè)性化的問(wèn)題。
整體思路是利用元學(xué)習(xí)在云端為每一個(gè)用戶(hù)部署一套個(gè)性化模型參數(shù),最終達(dá)到對(duì)成本和性能沒(méi)有損失的效果。
3、元學(xué)習(xí)(meta-learing)介紹

元學(xué)習(xí)指的是學(xué)習(xí)到通用知識(shí)來(lái)指導(dǎo)新任務(wù)的算法,使得網(wǎng)絡(luò)具有快速的學(xué)習(xí)能力。例如:上圖中的分類(lèi)任務(wù):貓和鳥(niǎo)、花朵和自行車(chē),我們將這種分類(lèi)任務(wù)定義成K-short N-class 的分類(lèi)任務(wù),希望通過(guò)元學(xué)習(xí),學(xué)習(xí)到分類(lèi)知識(shí)。在預(yù)估finetune過(guò)程,我們希望對(duì)于狗和水獺這樣的分類(lèi)任務(wù),用很少的樣本,進(jìn)行微調(diào)就能得到極致的預(yù)估效果。再舉一例,我們?cè)趯W(xué)習(xí)四則混合運(yùn)算時(shí),先學(xué)習(xí)加減,后學(xué)習(xí)乘除,當(dāng)這兩個(gè)知識(shí)掌握了,我們就能夠?qū)W習(xí)這兩個(gè)知識(shí)融在一起如何來(lái)算,對(duì)于加減乘除混合運(yùn)算,我們并不是分開(kāi)來(lái)算,而是在加減乘除的基礎(chǔ)上,學(xué)習(xí)先乘除后加減的運(yùn)算規(guī)則,再用一些樣本來(lái)訓(xùn)練這個(gè)規(guī)則,以便快速了解這個(gè)規(guī)則,以至于在新的預(yù)估數(shù)據(jù)上得到比較好的效果。元學(xué)習(xí)的思路與此類(lèi)似。

傳統(tǒng)的學(xué)習(xí)方法,目標(biāo)是學(xué)習(xí)到使得所有數(shù)據(jù)達(dá)到最優(yōu)的θ,即全局最優(yōu)的θ。元學(xué)習(xí)是以task為維度,來(lái)學(xué)習(xí)場(chǎng)景上的通用 ,在所有場(chǎng)景上面loss都能達(dá)到最優(yōu)。傳統(tǒng)的學(xué)習(xí)方法學(xué)到的θ,更靠近大場(chǎng)景的人群,對(duì)大場(chǎng)景預(yù)估更好,對(duì)中長(zhǎng)尾預(yù)估效果一般;元學(xué)習(xí)是學(xué)習(xí)到各個(gè)場(chǎng)景都相近的一個(gè)點(diǎn),在用每個(gè)場(chǎng)景的數(shù)據(jù)或新的場(chǎng)景的數(shù)據(jù)在這個(gè)點(diǎn)上進(jìn)行微調(diào),達(dá)到各個(gè)場(chǎng)景最優(yōu)的一個(gè)點(diǎn)。所以可以實(shí)現(xiàn),在每一個(gè)場(chǎng)景構(gòu)建個(gè)性化的模型參數(shù),達(dá)到極致個(gè)性化的目標(biāo)。上述實(shí)例中是以人群為task進(jìn)行元學(xué)習(xí),也適用于用戶(hù)或item為task進(jìn)行建模。
,在所有場(chǎng)景上面loss都能達(dá)到最優(yōu)。傳統(tǒng)的學(xué)習(xí)方法學(xué)到的θ,更靠近大場(chǎng)景的人群,對(duì)大場(chǎng)景預(yù)估更好,對(duì)中長(zhǎng)尾預(yù)估效果一般;元學(xué)習(xí)是學(xué)習(xí)到各個(gè)場(chǎng)景都相近的一個(gè)點(diǎn),在用每個(gè)場(chǎng)景的數(shù)據(jù)或新的場(chǎng)景的數(shù)據(jù)在這個(gè)點(diǎn)上進(jìn)行微調(diào),達(dá)到各個(gè)場(chǎng)景最優(yōu)的一個(gè)點(diǎn)。所以可以實(shí)現(xiàn),在每一個(gè)場(chǎng)景構(gòu)建個(gè)性化的模型參數(shù),達(dá)到極致個(gè)性化的目標(biāo)。上述實(shí)例中是以人群為task進(jìn)行元學(xué)習(xí),也適用于用戶(hù)或item為task進(jìn)行建模。

元學(xué)習(xí)有三種分類(lèi):
- 基于度量的方法(Metric-based):利用KNN、K-means等度量學(xué)習(xí)方法,來(lái)學(xué)習(xí)新的場(chǎng)景和當(dāng)前已經(jīng)存在的場(chǎng)景的距離,預(yù)估屬于哪一個(gè)分類(lèi),代表算法是Convolutional Siamese、Neural Network、Matching Networks、Prototypical Networks.
- 基于模型的方法(Model_based):通過(guò)memory或RNN等快速學(xué)習(xí)模型參數(shù),代表算法是:Memeory-Augmented、Neural Networks
- 基于優(yōu)化的方法(Optimization-based):這是近幾年比較流行的方法,利用梯度下降方法為每一個(gè)場(chǎng)景計(jì)算loss,來(lái)獲取最優(yōu)參數(shù),代表算法是MAML,目前是采用這種算法來(lái)進(jìn)行個(gè)性化建模。
4、元學(xué)習(xí)算法

Model-Agnostic Meta-Learning(MAML)是與模型結(jié)構(gòu)無(wú)關(guān)的算法,適合通用化,分為兩部分:meta-train和finetune。
meta-train有一個(gè)初始化θ,進(jìn)行兩次采樣,場(chǎng)景采樣和場(chǎng)內(nèi)樣本采樣。第一步,場(chǎng)景采樣在這一輪采樣過(guò)程中,全體樣本有十萬(wàn)甚至上百萬(wàn)的task,會(huì)從上百萬(wàn)的task中采樣出n個(gè)task;第二步,在每個(gè)場(chǎng)景上,為這個(gè)場(chǎng)景采樣batchsize個(gè)樣本,把batchsize個(gè)樣本分為兩部分,一部分是Support Set,另一部分是Query Set;用Support Set 使用隨機(jī)梯度下降法更新每個(gè)場(chǎng)景的θ;第三步,再用Query Set為每個(gè)場(chǎng)景計(jì)算loss;第四步,把所有的loss相加,梯度回傳給θ;整體進(jìn)行多輪計(jì)算,直到滿(mǎn)足終止條件。
其中,Support Set可以理解為訓(xùn)練集合,Query Set理解為validation集合。

Finetune過(guò)程和meta-train過(guò)程很接近,θ放在具體的場(chǎng)景中,獲取場(chǎng)景的support set,利用梯度下降法(SGD),獲得場(chǎng)景的最優(yōu)參數(shù) ;使用
;使用 對(duì)task場(chǎng)景待打分的樣本(query set)產(chǎn)生預(yù)估結(jié)果。
對(duì)task場(chǎng)景待打分的樣本(query set)產(chǎn)生預(yù)估結(jié)果。
5、元學(xué)習(xí)工業(yè)化挑戰(zhàn)

將元學(xué)習(xí)算法應(yīng)用在工業(yè)化的場(chǎng)景中會(huì)有比較大的挑戰(zhàn):元學(xué)習(xí)算法的meta-train過(guò)程涉及到兩次采樣,場(chǎng)景采樣和樣本采樣。對(duì)于樣本而言,需要把樣本組織好,同時(shí)按照?qǐng)鼍暗捻樞虼鎯?chǔ)下來(lái)并進(jìn)行處理,同時(shí)需要一個(gè)字典表來(lái)存儲(chǔ)樣本和場(chǎng)景的對(duì)應(yīng)關(guān)系,這個(gè)過(guò)程十分消耗存儲(chǔ)空間和計(jì)算性能,同時(shí)需要將樣本放到worker中進(jìn)行消費(fèi),這對(duì)工業(yè)化場(chǎng)景具有非常大的挑戰(zhàn)。
我們有如下的解決方法:
- 解法1:在meta-train batch內(nèi)進(jìn)行樣本選擇,同時(shí),對(duì)于千萬(wàn)量級(jí)的模型訓(xùn)練,我們修改無(wú)量框架,以便支持元學(xué)習(xí)樣本組織和千萬(wàn)量級(jí)的模型訓(xùn)練。傳統(tǒng)的模型部署方式是在每一個(gè)場(chǎng)景中都部署一套模型,這會(huì)導(dǎo)致千萬(wàn)量級(jí)模型size非常大,訓(xùn)練和serving成本增加。我們采用即調(diào)即用即釋放的方式,只存儲(chǔ)一套模型參數(shù),這樣可以避免增加模型大小。同時(shí),為了節(jié)省性能,我們只學(xué)習(xí)核心網(wǎng)絡(luò)部分。
- 解法2:在serving過(guò)程進(jìn)行finetune,傳統(tǒng)的樣本存儲(chǔ)鏈路,使樣本的維護(hù)成本較高,因此我們摒棄傳統(tǒng)的方式,只存儲(chǔ)中間層的數(shù)據(jù),作為元學(xué)習(xí)的輸入。
6、元學(xué)習(xí)方案

首先在meta-train中實(shí)現(xiàn)batch內(nèi)場(chǎng)景和樣本的選擇,每個(gè)batch內(nèi)會(huì)有多條數(shù)據(jù),每個(gè)數(shù)據(jù)屬于一個(gè)task。在一個(gè)batch內(nèi),將這些數(shù)據(jù)按照task抽取出來(lái),抽取出來(lái)的樣本放到meta-train訓(xùn)練過(guò)程中,這樣就解決了需要獨(dú)立維護(hù)一套場(chǎng)景選擇和樣本選擇的處理鏈路的問(wèn)題。

通過(guò)實(shí)驗(yàn)調(diào)研以及閱讀論文,我們發(fā)現(xiàn),在fine-tune以及在元學(xué)習(xí)過(guò)程中,越接近預(yù)估層,對(duì)模型的預(yù)估效果影響越大,同時(shí)emb層對(duì)模型的預(yù)估效果影響較大,中間層對(duì)預(yù)估效果沒(méi)有很大的影響。所以我們的思路是,元學(xué)習(xí)只選取離預(yù)估層較近的參數(shù)就可以,從成本上考慮,emb層會(huì)導(dǎo)致學(xué)習(xí)的成本增加,對(duì)emb層就不進(jìn)行元學(xué)習(xí)的訓(xùn)練了。

整體訓(xùn)練過(guò)程,如上圖中的mmoe的訓(xùn)練網(wǎng)絡(luò),我們對(duì)tower層的參數(shù)進(jìn)行學(xué)習(xí),其他場(chǎng)景的參數(shù)還是按照原始的訓(xùn)練方式來(lái)學(xué)習(xí)。以u(píng)ser為維度來(lái)進(jìn)行樣本的組織,每一個(gè)用戶(hù)有自己的訓(xùn)練數(shù)據(jù),把訓(xùn)練數(shù)據(jù)分為兩部分,一部分是support set,一部分是query set。在support set中,只學(xué)習(xí)local側(cè)的內(nèi)容進(jìn)行tower update,進(jìn)行參數(shù)訓(xùn)練;再用query set數(shù)據(jù)對(duì)整體的網(wǎng)絡(luò)進(jìn)行l(wèi)oss計(jì)算后梯度回傳,來(lái)更新整個(gè)網(wǎng)絡(luò)的參數(shù)。
因此,整個(gè)訓(xùn)練過(guò)程是:整體網(wǎng)絡(luò)原訓(xùn)練方式不變;元學(xué)習(xí)只學(xué)習(xí)核心網(wǎng)絡(luò);從成本方面考慮,embedding不參與元學(xué)習(xí);loss=原loss+元loss;fintune時(shí),把emb進(jìn)行存儲(chǔ)。serving過(guò)程,用emb微調(diào)核心網(wǎng)絡(luò),同時(shí)可用開(kāi)關(guān)來(lái)控制元學(xué)習(xí)隨開(kāi)隨關(guān)。
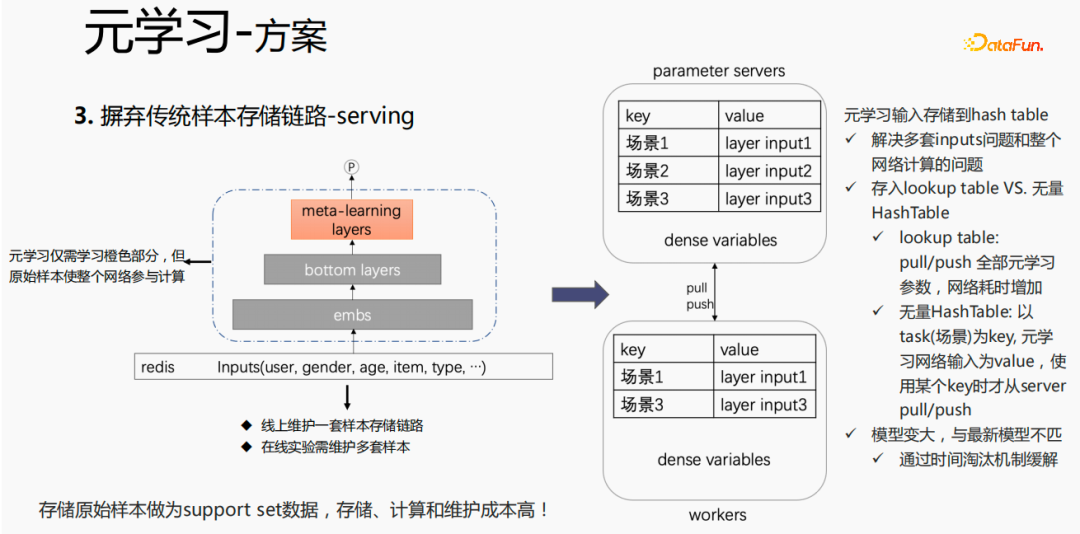
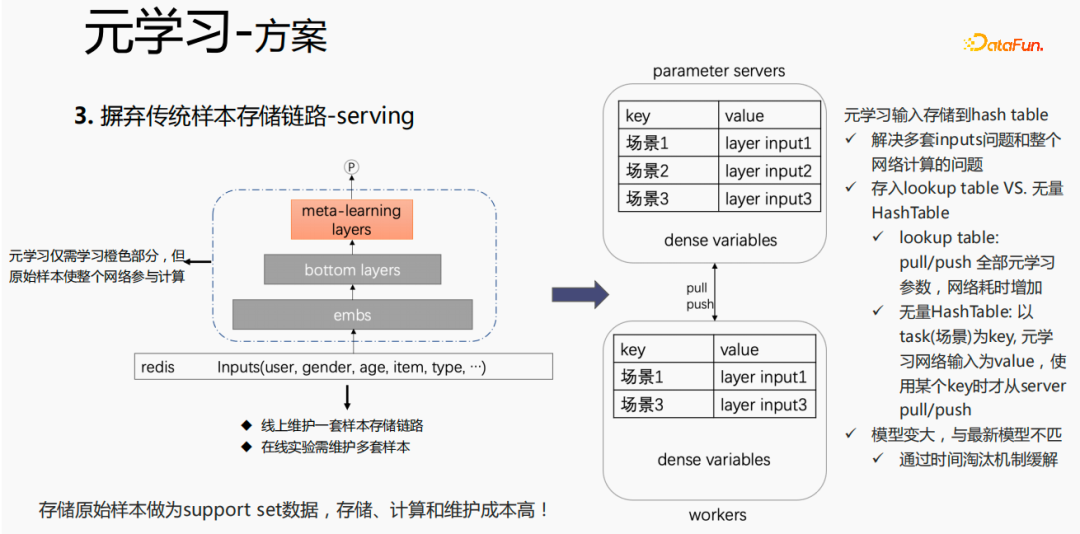
對(duì)于傳統(tǒng)的樣本存儲(chǔ)方式,如果在serving過(guò)程,直接進(jìn)行finetune,會(huì)存在較嚴(yán)重的問(wèn)題:需要在線(xiàn)上維護(hù)一套樣本存儲(chǔ)鏈路;多套在線(xiàn)實(shí)驗(yàn)需要維護(hù)多套樣本。同時(shí),finetune過(guò)程,用原始樣本進(jìn)行finetune,樣本要經(jīng)過(guò)emb層、bottom layers層以及meta-learning層,但是元學(xué)習(xí)在serving過(guò)程僅需要學(xué)習(xí)meta-learning layers,不關(guān)心其他部分。我們考慮在serving過(guò)程,僅保存meta-learning input 存到模型中,這樣就能節(jié)省樣本鏈路的維護(hù),同時(shí)達(dá)到一定的效果,如果只存emb這一部分,可節(jié)省該部分的計(jì)算成本和維護(hù)成本。
我們采用如下的方法:
把存儲(chǔ)放到模型的lookup table中,lookup table 會(huì)被認(rèn)為是一個(gè) dense 的 variables,存儲(chǔ)在ps中,所有的參數(shù)都會(huì)pull到worker 上,更新時(shí),也會(huì)push到所有的 variables ,這樣會(huì)增加網(wǎng)絡(luò)的耗時(shí)。另一種方式是使用無(wú)量HashTable,HashTable是以key、value的形式存儲(chǔ),key是場(chǎng)景,value是meta layer的input,這樣做的好處是,只需將所需要的場(chǎng)景的input layer從ps上進(jìn)行push或者pull,整體會(huì)節(jié)省網(wǎng)絡(luò)的耗時(shí),所以我們采樣該方法來(lái)存儲(chǔ)meta layer 的input。同時(shí),如果將 meta-learning layers 存儲(chǔ)到模型中,會(huì)使得模型變大,也會(huì)遇到過(guò)期的問(wèn)題,導(dǎo)致和目前的模型不匹配,我們使用時(shí)間淘汰極致來(lái)解決該問(wèn)題,即淘汰掉過(guò)期embedding,這樣既使得模型變小,也能解決實(shí)時(shí)性的問(wèn)題。

這個(gè)模型在 serving 階段,會(huì)使用embedding,embedding輸入到bottom layers,打分時(shí),并不像原始的方式一樣,而是通過(guò)meta-learning layers拿到support set 中的數(shù)據(jù),將該層的參數(shù)更新,使用更新后的參數(shù)進(jìn)行打分。這個(gè)過(guò)程在GPU上無(wú)法進(jìn)行計(jì)算,因此我們?cè)贑PU上執(zhí)行該過(guò)程。同時(shí),無(wú)量GPU推理做了Auto Batch合并,將多個(gè)請(qǐng)求進(jìn)行合并,合并后的請(qǐng)求在GPU上進(jìn)行計(jì)算,這樣處理,梯度會(huì)隨著batch的增加而變化,針對(duì)該問(wèn)題,我們?cè)赽atch和grad的基礎(chǔ)上,增加一個(gè)num維度,計(jì)算梯度時(shí),將grad進(jìn)行相加,按照num 進(jìn)行處理后,保持梯度的穩(wěn)定性。最終實(shí)現(xiàn)成本和性能可控,同時(shí)實(shí)現(xiàn)了千境千模。
7、元學(xué)習(xí)工業(yè)化實(shí)踐

借助框架、組件將元學(xué)習(xí)通用化,用戶(hù)接入時(shí),只需修改模型代碼,用戶(hù)無(wú)需關(guān)心訓(xùn)練和serving,只需調(diào)用我們已經(jīng)實(shí)現(xiàn)好的接口,例如:support set讀寫(xiě)接口、meta-train和finetune實(shí)現(xiàn)接口以及GPU serving適配接口等。用戶(hù)只需傳入loss、task inputs、label等業(yè)務(wù)相關(guān)參數(shù)。這樣設(shè)計(jì),節(jié)省了算法工程師調(diào)研、開(kāi)發(fā)、實(shí)驗(yàn)和試錯(cuò)的成本,提升了算法的迭代效率;同時(shí),通用化的代碼,可服務(wù)多個(gè)業(yè)務(wù)場(chǎng)景,節(jié)省人力和資源成本。
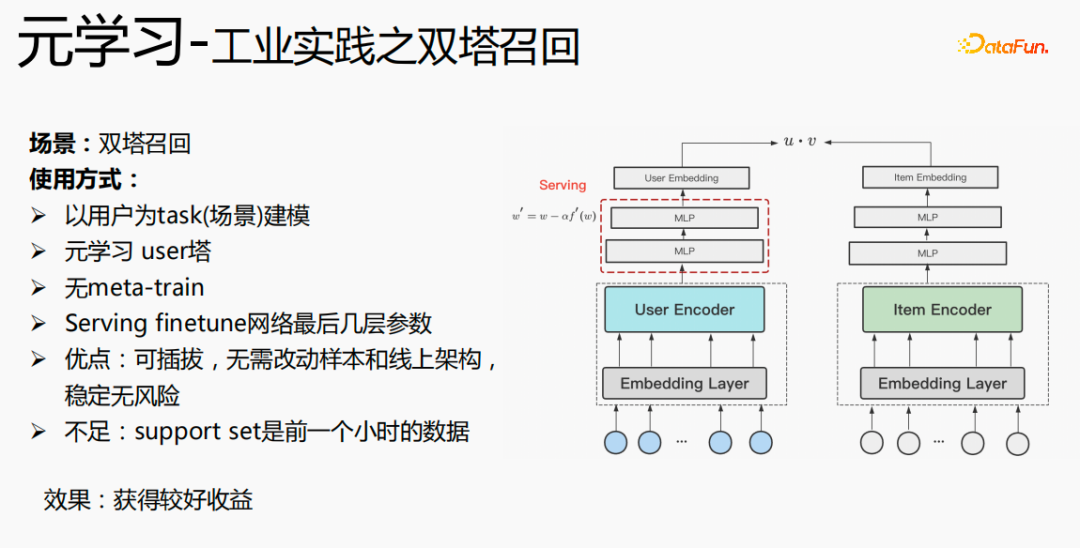
元學(xué)習(xí)在雙塔召回場(chǎng)景下的使用,是以用戶(hù)為維度進(jìn)行建模,包括user塔和item塔。模型的優(yōu)點(diǎn)是:可插拔,無(wú)需改動(dòng)樣本和線(xiàn)上架構(gòu),穩(wěn)定無(wú)風(fēng)險(xiǎn);缺點(diǎn)是support set是前一個(gè)小時(shí)的數(shù)據(jù),存在實(shí)時(shí)性的問(wèn)題。

元學(xué)習(xí)的另一個(gè)應(yīng)用場(chǎng)景是在序列召回場(chǎng)景,該場(chǎng)景是以用戶(hù)為場(chǎng)景來(lái)建模,以用戶(hù)的行為序列作為support set,用戶(hù)行為序列只有正樣本,我們會(huì)維護(hù)一個(gè)負(fù)樣本隊(duì)列,采樣隊(duì)列中樣本做為負(fù)樣本,并拼接上正樣本作為support set。這樣做的好處是:實(shí)時(shí)性更強(qiáng),成本更低。

最后,元學(xué)習(xí)也應(yīng)用在排序場(chǎng)景中,如上圖中的mmoe精排模型,實(shí)現(xiàn)方式有兩種:僅使用finetune,以及同時(shí)使用meta-train和finetune。第二種實(shí)現(xiàn)方式效果更優(yōu)。

元學(xué)習(xí)在不同的場(chǎng)景中都取得了較好的收益。
二、跨域推薦
1、跨域推薦痛點(diǎn)

每個(gè)場(chǎng)景有多個(gè)推薦的入口,需要為每個(gè)場(chǎng)景都建立一套召回、粗排到精排的鏈路,成本較高。尤其小場(chǎng)景和中長(zhǎng)尾流量數(shù)據(jù)稀疏,優(yōu)化空間受限。我們能否將一個(gè)產(chǎn)品內(nèi)相似推薦入口的樣本、離線(xiàn)訓(xùn)練和在線(xiàn)服務(wù)融合成一套,達(dá)到節(jié)省成本并提升效果的目的。

但是,這樣做也存在一定的挑戰(zhàn)。在瀏覽器上搜索谷愛(ài)凌,會(huì)出現(xiàn)相關(guān)搜索詞,點(diǎn)擊具體的內(nèi)容并返回后,會(huì)出現(xiàn)結(jié)果點(diǎn)擊后的推薦,這兩種的流量占比、點(diǎn)擊率以及特征分布的差異都比較大,同時(shí)在預(yù)估目標(biāo)上也有差異。

如果將跨域的模型使用多任務(wù)模型,就會(huì)產(chǎn)生比較嚴(yán)重的問(wèn)題,并不能拿到比較好的收益。

在騰訊實(shí)現(xiàn)跨場(chǎng)景建模具有較大挑戰(zhàn)。首先在其他企業(yè),兩個(gè)場(chǎng)景的特征能夠一一對(duì)應(yīng),但在騰訊的跨域推薦領(lǐng)域兩個(gè)場(chǎng)景的特征無(wú)法對(duì)齊,一條樣本只能屬于一個(gè)場(chǎng)景,數(shù)據(jù)分布差異大,預(yù)估目標(biāo)難對(duì)齊。

針對(duì)騰訊跨域推薦場(chǎng)景的個(gè)性化需求,采用上述方式進(jìn)行處理。對(duì)于通用特征進(jìn)行shared embedding,場(chǎng)景個(gè)性化的特征自己獨(dú)立 embedding空間,在模型部分,有共享的expert和個(gè)性化的expert,所有的數(shù)據(jù)都會(huì)流入共享的expert,每個(gè)場(chǎng)景的樣本會(huì)數(shù)據(jù)各自的個(gè)性化expert,通過(guò)個(gè)性化gate將共享expert和個(gè)性化expert融合,輸入到tower,用star的方式來(lái)解決不同場(chǎng)景的目標(biāo)稀疏的問(wèn)題。對(duì)于expert部分,可以采用任意的模型結(jié)構(gòu),例如Share bottom、MMoE、PLE,也可以是業(yè)務(wù)場(chǎng)景上的全模型結(jié)構(gòu)。該方式的優(yōu)點(diǎn)是:模型的通用性強(qiáng),適合各類(lèi)模型融合接入;由于可以直接將場(chǎng)景expert遷移,對(duì)原場(chǎng)景效果無(wú)損,實(shí)現(xiàn)跨場(chǎng)景知識(shí)遷移效果提升;融合后模型減小,訓(xùn)練速度提升,同時(shí)節(jié)省成本。
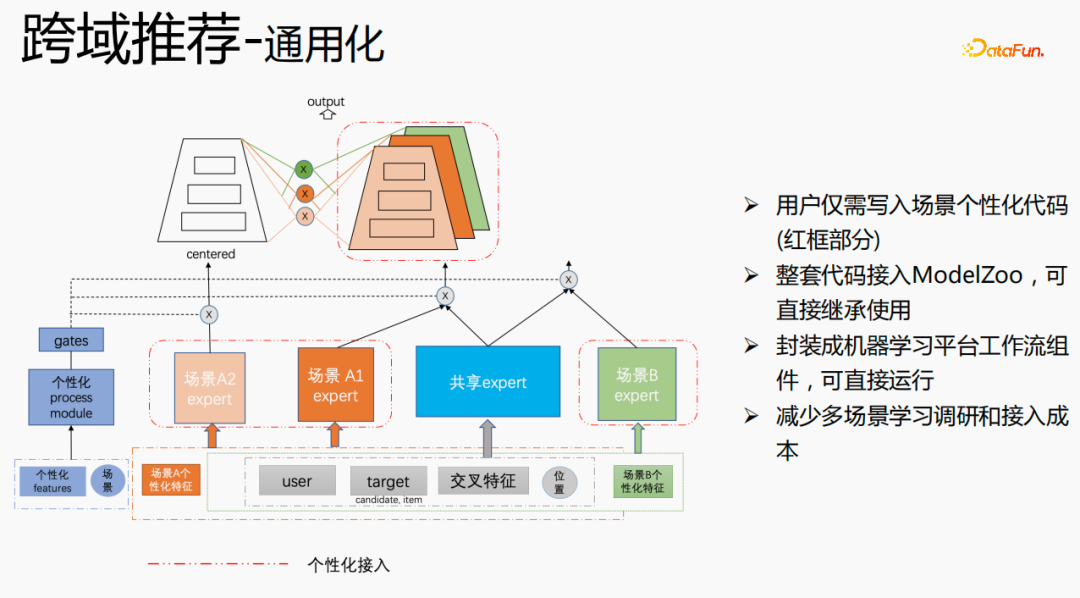
我們進(jìn)行了通用化建設(shè),紅色部分是需要個(gè)性化接入的內(nèi)容,例如:個(gè)性化特征、個(gè)性化模型結(jié)構(gòu)等,用戶(hù)只需寫(xiě)入個(gè)性化的代碼即可。其他部分,我們已經(jīng)將整套代碼接入ModelZoo,可直接繼承使用,并將其封裝成機(jī)器學(xué)習(xí)平臺(tái)工作流組件,可直接運(yùn)行,該方式減少了多場(chǎng)景學(xué)習(xí)調(diào)研和接入成本。

這種方式使樣本量變多,模型結(jié)構(gòu)變得復(fù)雜,但效率反而提升了。原因如下:由于一些特征是共享的,融合后的特征數(shù)比兩個(gè)場(chǎng)景特征數(shù)的加和要少;由于shared embedding的功能,batch內(nèi)key均值,比兩個(gè)場(chǎng)景的加和要小;減小了從server端pull或push的時(shí)間,從而節(jié)省了通信耗時(shí),整體降低了訓(xùn)練耗時(shí)。
多場(chǎng)景的融合能使整體成本減少:離線(xiàn)樣本處理,能夠減少21%的成本;采用CPU追數(shù)據(jù),會(huì)節(jié)省24%的成本,同時(shí)模型的迭代時(shí)間也會(huì)減少40%,在線(xiàn)訓(xùn)練成本、在線(xiàn)服務(wù)成本、模型大小都會(huì)降低,所以使全鏈路的成本降低了。同時(shí),將多個(gè)場(chǎng)景的數(shù)據(jù)融合在一起,更適合GPU計(jì)算,將兩個(gè)單場(chǎng)景的CPU融合到GPU上,節(jié)省的比例會(huì)更高。

跨域推薦可通過(guò)多種方式來(lái)使用。第一種,多場(chǎng)景單目標(biāo)的模型結(jié)構(gòu),可直接使用多場(chǎng)景的建模架構(gòu),不建議使用tower側(cè)的star;第二種,多場(chǎng)景多目標(biāo)的融合,可直接使用多場(chǎng)景的建模框架;第三種,同一個(gè)精排產(chǎn)品,不同目標(biāo)模型融合,可直接使用多場(chǎng)景建模框架,不建議使用tower側(cè)的star;最后一種,同產(chǎn)品多個(gè)召回、粗排模型融合,目前正在進(jìn)行中。

跨域推薦不僅在效果上有提升,在成本上也節(jié)省了很多。