構建高性能可觀測性數據流水線:使用Vector實現實時日志分析

一、可觀測性
1、可觀測性-是什么?
(1)可觀測性的基本理解
在計算機系統的領域,可觀測性可以理解為能夠監控和了解一個系統內部狀態的能力,這種能力它涵蓋了幾個方面:
- 能夠監控和理解當前系統的狀態
通過可觀測性能夠知道系統是否在正常運行中,可以及時發現不正常的狀態。
- 能幫助定位、回溯系統發生的問題
如果系統處在不正常的狀態,我們能夠高效地去定位問題,并且回溯問題產生的根源。
- 能夠預防問題的發生
對系統可能即將發生的問題有一定的預見性,能夠通過告警等方式防止重大問題的發生。
(2)為什么現在可觀測性會變得越來越重要?
隨著大數據跟云計算等技術的迅猛發展,企業內部的系統變得越來越復雜,系統逐漸地開始分布式化,微服務成為了主流,這就導致了現在企業內部的系統中需要監控的服務組件越來越多。服務的組件之間的關聯越多,系統可能發生故障的概率、類型也就越多。
如果系統能夠實現很好的可觀測性,就能更好地去應付復雜系統可能帶來的問題,更好地控制內部復雜系統。
2、可觀測性-如何實現
可觀測性的實現主要包括三個方面:
- 數據采集和關聯的能力
想要知道系統的狀態,首先要依賴于系統中各個服務產生的數據,所以第一步需要去收集數據,并將這些相互獨立的數據關聯起來。
- 分析、可視化的能力
有了原始的可觀測性數據,還需要對這些數據進行多樣分析,通過這些數據去解讀系統的狀態。另外可視化也不可或缺的部分,它能夠將分析結果以更直觀的方式呈現出來,帶來更為高效的可觀測性。
- 事件響應能力
一個可觀測性系統需要在出現或即將出現嚴重事件的時候,提供快速響應的能力,并以適當的方式通知用戶,通知系統管理員,輔助用戶恢復故障或者防范故障的發生。
3、可觀測性-數據類別
在可觀測性領域主要依賴三類數據,分別是:日志 Log、指標 Metrics 以及追蹤 Trace。
二、數據采集-我們需要什么?
合格的數據采集工具,一般具備如下特性:
首先,盡可能多地支持從不同的數據源去采集數據。
其次,能夠盡可能多地支持不同的數據分析平臺,也就是數據的消費終端。采集到的數據能夠很容易地被導入到數據的消費終端。
最后,具備一定的數據加工的能力,而不只是原封不動地把數據從源端搬運到終端而已。
在數據采集領域,有很多優秀的工具、很成熟的應用,例如 Elk 架構中的 Logstash、基于 Go 寫的 Filebeat、基于ruby的Fluentd 等等。今天主要介紹的是Datadog 公司的開源工具 Vector。
三、Vector
1、Vector 的簡單的介紹。
Vector 工具在 GitHub 上有超過 13.5K 的 Star,還有 1.1K 的 Fork,是非常熱門的項目。

根據官方網站上的介紹,Vector 是一個高性能的端到端的可觀測性數據流水線工具,可以更好地控制可觀測性數據。這個工具本身是用 Rust 開發的,所以具備 Rust 原生的內存安全、以及性能方面的優勢。支持跨平臺的部署,支持 Linux、 Mac OS、 Windows 平臺。
從上圖中可以看到 Vector 的經典功能拓撲,它可以作為 Agent 代理端部署在數據的源端,收集不同類型的可觀測性數據。同時也可以作為聚合的 Aggregator 將多個不同來源的 Agent 的數據聚合在一起并發送到不同的數據 Sink 里面。

Vector 主要有三大功能模塊,如上圖所示。
數據從 Source 進入到 Vector,經過一些 Transforms 邏輯進行數據加工,最后發往 Sink。可以看到 Vector 通過 Source、 Transform 、Sink 三種不同類型的組件組成了一個完整的數據流水線。
這里面的一個 Source 就是一個可供采集的數據源,例如文件、Kafka、Syslog 等。而一個 Sink 則是接收、消費數據的終端,比如Clickhouse、Splank、Datadog Logs 這類的數據庫,或者日志分析平臺。
簡單歸納一下 Vector 具備的兩種主要類型的功能:
- 數據采集與傳輸
它可以從數據采集端的 Source 獲取數據,并最終傳輸到數據的消費端 Sink。
- 數據加工的能力
可以通過內部的 Transform 的功能模塊對收集到的數據進行解析、采樣、聚合等不同類型的加工處理。
(1)Vector-豐富的功能支持

上圖中可以看到,官方文檔上面 Vector 支持的 Source、Sink 、Transform 類型的列表,非常豐富。圖中 Source、Sink 的列表都做了截斷,因為它支持的類型太多了,具體完整的列表可以在其官方文檔看到。
Vector 的這些 Source、 Sink 、 Transform 組件的功能都是內置的,跟 LogStash 通過擴展插件的支持方式不一樣。
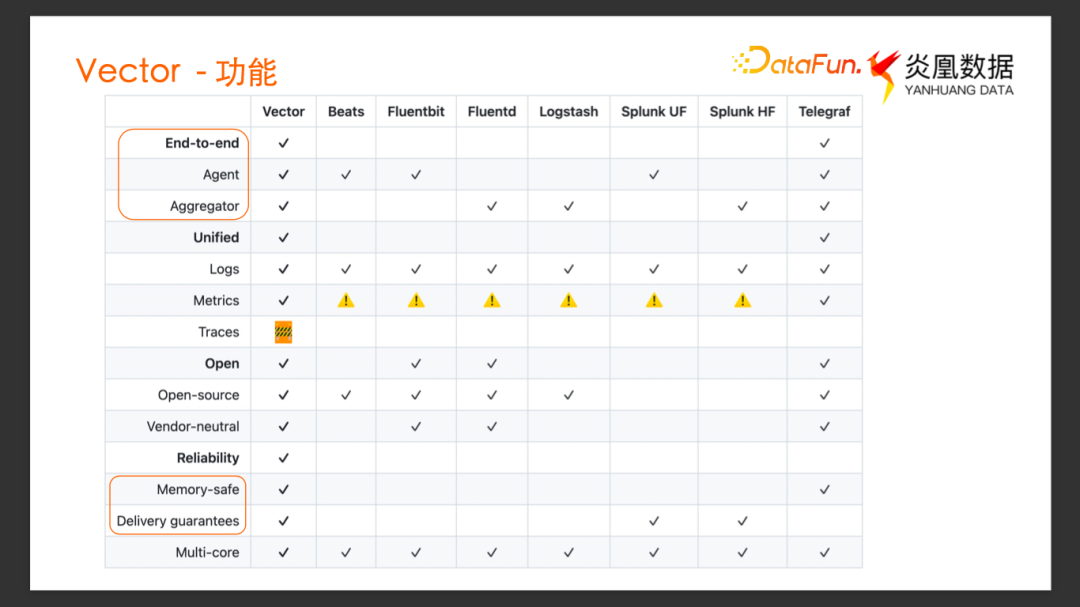
GitHub 首頁列出了Vector與其它一些可觀測性數據采集工具的對比,有幾個比較吸引人的點:
End To End 特性。既可以作為 Agent 部署采集數據,也可以作為 Aggregator 聚合數據,在部署上有很大的靈活性,能夠更好地去適應不同的場景。
可靠性。由于它使用 Rust 開發,具備內存安全的特性. 同時對于大部分的 Source、Sink 類型都支持實現了 At-Least-Once 傳輸保證。
除此之外,還有一些亮點功能,比如提供了 Buffer 功能,用戶可以選擇不同的緩沖模型,可以自己選擇是采用內存 Buffer 緩沖來提高吞吐的性能,還是采用磁盤作為 Buffer 來提供更好的持久性。
(2)Vector-性能

官方提供的性能對比圖,對比了很多知名競品。可以看到,除了正則解析方面稍微弱一些以外,其它無論是文件source發送到TCP sink, 還是 TCP source到 HTTP sink等端到端的性能測試的 Case,Vector都是有優勢的。
(3)Vector-基本用法
作為一個工具,vector的易用性很高。
它支持通過很多不同的方式安裝,安裝包下載、包管理器等等,安裝完成以后,得到一個二進制的 Binary,它唯一的依賴就是一個配置文件。
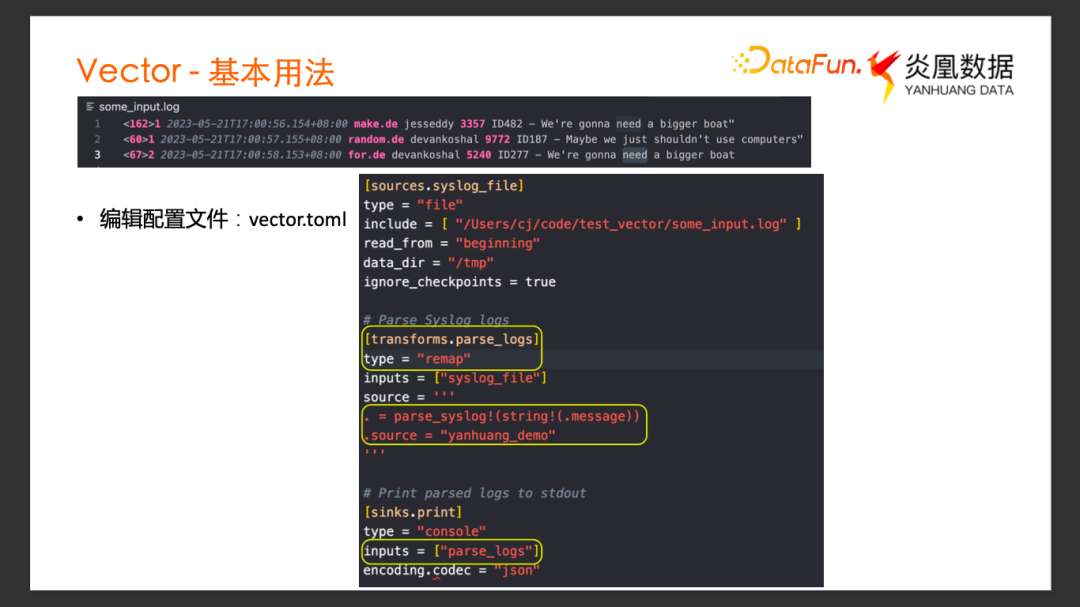
最簡單的使用場景,比如有一個作為樣例 Log 文件some-input-log,這里面有 3 條日志都是 syslog格式的。我們希望用 Vector 來采集這個文件里面的 Log,然后對 syslog的格式解析,將解析后的事件發送到 Terminal 終端,看是否正確解析。
首先創建一個配置文件 Vector.toml,Vector 的配置文件支持 Toml、 Yaml 、Json 三種不同格式。以 Toml 做示例。圖中是一個簡單的 Vector 配置文件的 Toml 格式寫法,主要分成三個部分:Source、Transform和Sink。
Source 的類型是文件, Include 這個字段寫需要采集的日志文件的路徑。
Transform 中 Input 是 Source 的 Name, 表示上游的數據源,Source 端采集到的這些日志事件通過VRL 語法做解析,把源端數據的 Message 字段做 parse_sys_log 函數調用,作用就是把 syslog的日志解析出對應的有用的字段。我們還添加了一個 Source 字段,賦值叫 yanhuang_demo。
Sink 的 Inputs 里面寫了上游數據源是哪里,是剛剛定義好的 Transform 叫 parse_logs,它的 Type 是 Console,也就是希望解析完的日志能直接打印到 Console 消費終端。

保存這個配置文件,然后在 Terminal 里面運行,只需要一個 Binary 和一個依賴配置文件, Vector -c Vector.toml 就運行起來。
可以看到,原始的數據里面只有一條完整的 syslog message,打印到 Console 的事件里有appname、facility 等字段,這些 syslog格式里面的標準字段,都被從原始 Log 中提取出來,并且我們配置的 source = yanhuang_demo 字段,也添加到了最終輸出的log事件中。
這就是最簡單的運行實例,它的配置和運行過程都很簡單。
2、Vector-transform的使用

剛才是一個很簡單的配置實例,只有一個 Source,一個 Transform 和一個 Sink。在實際的使用中,往往會有很多的 Source 需要去采集,可能需要將數據加工后發往不同的 Sink。這個時候需要用到很多不同的 Transform 單元去完成不同類型數據加工工作。官方的這張圖展示了一類實際的使用場景。
這個流水線的拓撲就相對比較復雜,可觀測的數據來自于不同的 Source,有日志文件的、系統指標等等。
第一個 Transform 單元,將來自于不同 Source 的不同類型的日志文件路由到相應的 Transform 單元,例如,如果是 Nginx 的日志,就會走到 Nginx 解析的 Transform 單元。如果是 Postgres 的日志就會走到 Postgres 的 Transform 單元。JSON 類型的文件就會走到 JSON 類型的 Transform 單元。這個示例中的服務可能都是部署在 AWS的EC2 Instance 上的, 因此前面這些 Log 和 Metrics匯總到了同一個 Transform 的 Stage 3,在這個單元里面統一處理日志的EC2 Meta Data,最后這個 Transform Stage 4 單元再對匯總來的日志事件經過采樣以后,發送到 3 個不同的 Sink,比如發往 Elastic 去做數據分析,發往 AWS 的 S3 做數據固化,發往 Prometheus 做指標分析。
可以看到這個拓撲里面通過多個 Transform 功能可以很靈活地把不同類型的多個數據源最終統一歸集在一起,得益于它豐富的 Transform 功能,才能很靈活地去構建數據采集的流水線。
Transform 含有很豐富的功能: 重映射(remap),過濾(filter)、聚合(aggregate)、路由(route)等等,還支持用戶自定義功能。
(1)Transform-Remap
Remap-VRL
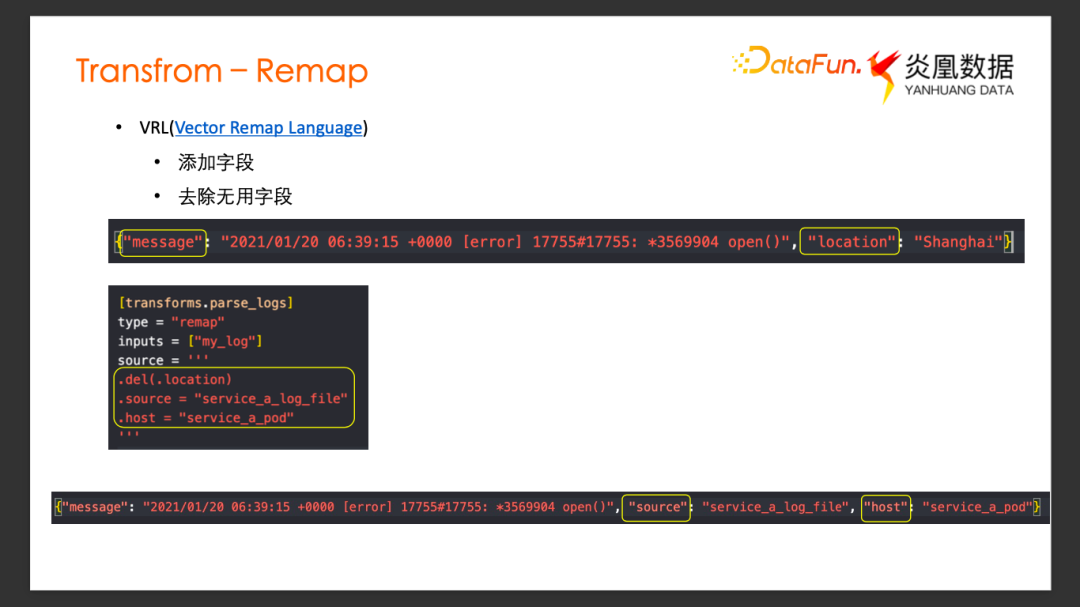
Transform最主要的用法就是 Remap。Remap 使用的是 Vector 自定義的配置語法 VRL(Vector Remap Language)。接下來結合實際案例來看 VRL 的使用。
現在希望對一條日志事件去除掉不關心的某些字段,同時添加關心的某個字段。原始數據是JSON 格式的一條Log,它有兩個字段, Message 字段和 Location 字段。希望能經過一個 Transform去掉 Location 字段,同時添加自定義的 Host 和 Source 的信息。添加一個 Transform 配置單元,可以很直觀地看到 Source字段里面采用 VRL 語法編輯一個 Transform 功能:通過 Delete 方法把 Location 字段刪除掉,同時添加了 Source、 Host字段。經過這個 Transform 以后,結果中可以看到,Location 字段已經沒有了,Source、Host 字段被添加到了下游的日志事件。
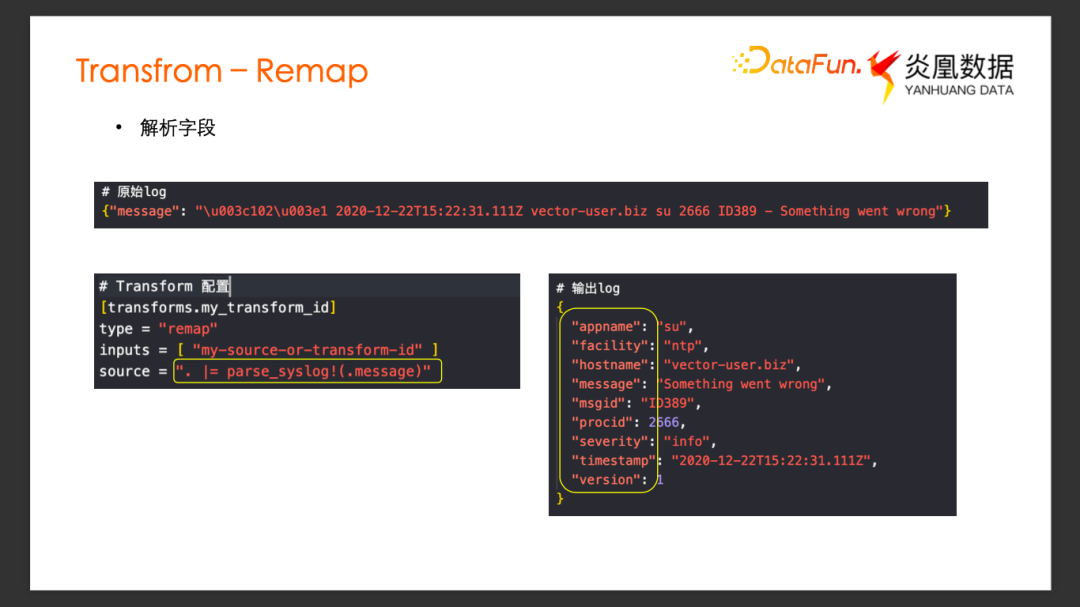
Remap-解析字段
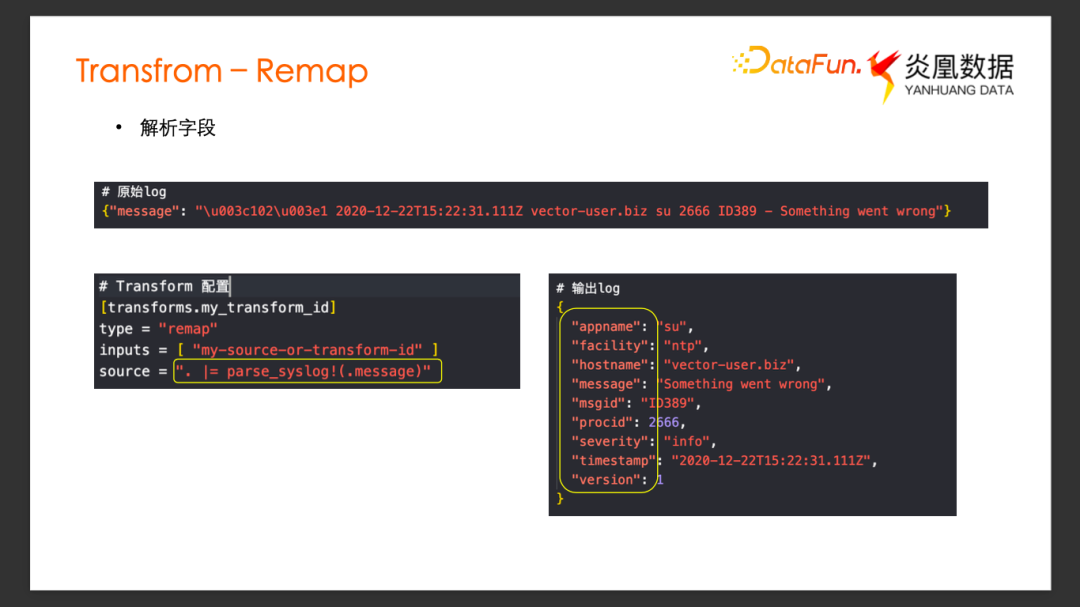
還可以利用 Remap 實現一些別的功能,比如字段解析。
假設原始 Log 有一個 Message 字段,內容是一條 syslog格式的日志,我們希望能將 Message 里面的 syslog字段都解析出來。用 VRL 里面內置的 parse_syslog方法即可把 Message字段內容作為syslog解析。提取出解析完的相應字段賦值給當前日志事件,所有解析出來的字段變成了當前的輸出下游的日志事件的新的字段。
Remap-多策略解析
在實際的使用中同一個 Transform 單元還可能需要處理不同格式的數據。同一個 Transform 單元接收到上游日志可能不是相同格式的,可以利用 VRL 的 Remap 去做多策略的解析,比如,可能是syslog、Apache access Log,或者是自定義服務的某種格式的 Log。可以在一個 Transform 單元里面去定義一個適配多種策略的 VRL 的 Remap。
這個transform中,我們先把解析完的結果放到 Structure 變量里面,先把 Message 字段通過 parse_syslog 來做解析,后面的兩個問號表示這一步如果失敗的話(event不是正確的 syslog 格式),就會 fall back 到下一個階段,也就是 parse_common_log,當做 Apache Log 去解析。如果還是解析錯誤的話,最終fall back 到 parse_regex 方法。parse_regex 通過自定義的正則表達式來解析自定義的日志格式。所以符合三種格式任意一種的事件,最終都能通過這個 VRL 的鏈路正確地解析到 Structured 變量,然后把解析完后的字段跟當前 Log 里面的其他字段去 Merge 在一起。
(2)Transform-Filter

實際的使用中,除了 Remap 還有一些其它類型的功能。比如,可以利用 Filter 類型的 Transform 過濾篩選出我們關心的 Log 事件,同時丟棄掉我們不關心的 Log 事件。比如,原始的 Log 數據源,是某個服務產生的日志文件,分為了不同的 Log Level,Debug 在最終的數據分析終端里面可能是不需要的,就可以通過這個 Vector 的Filter Transform 把它過濾掉。
Transform 的配置很直觀,Type 設置 Filter。Condition 的配置就是設置的過濾的條件,這里過濾所有的 Level 字段不等于 Debug 的事件,經過這個 Transform,最后輸出到下游的日志就只剩 Info Level 的事件了,就完成了過濾的功能。
(3)Transform-Aggregate

在收集 Metrics 的場景中可能經常需要對 Metric 做聚合,因為原始的數據源采集來的 Metrics 指標可能包含太多采樣點的指標數據了,而下游的數據消費端可能更關心相對粗的時間粒度內的指標,這時就可以使用其 Aggregate 的聚合功能。
例如,原始的 Metric 數據收集了同一個時間點的兩個不同服務的技術信息,可以看到它的 Timestamp 是一樣的,都有 Counter 這個字段,但來源于不同的 Host,下游服務不關心具體哪一個 Host,或者分別的 Counter,希望以每 5 秒為一個時間窗口的粒度統計單個時間窗口內的 Counter 總數。創建一個 Transform 的配置單元,type 這邊選擇 Aggregate,設置 interval_ms為5000ms,希望以 5 秒的時間窗口聚合。可以看到最終輸出到下游,屬于同一個時間窗口的 Metrics 數據被聚合了,Counter 的數值做了相加。
(4)Transform-更多數據加工

Vector 的 Transform 還有很多其它功能, Remap 類型包含了大量內置的數據解析、轉換等的方法。比如 Sample 類型允許通過采樣來降低 Log 收集密度,還有 Metrics 可以轉 Log, Log 轉 Metrics 等等適配下游不同的數據消費終端。
如果都不能滿足用戶的數據轉換解析的需求,它還支持通過 Lua 腳本內嵌的方式自定義 Transform 的功能,擴展原本不具有的 Transform 的能力。
簡單總結一下 Vector Transform 功能給可觀測性數據采集帶來的收益:
- 第一 減輕了數據終端的解析成本
預提取出了一些字段,可以供最終的數據終端直接索引,不需要再解析。
- 第二 可以降低存儲的成本
通過一些解析、增加刪減字段,丟棄掉了不關注的字段,減少了日志最后存儲下來的體積、存儲成本。
- 第三 增加了不同數據來源的關聯性
從很多不同的服務采集到日志以后,在 Vector 做聚合。不同服務之間是孤立的,日志也是無關聯的。可以在 Vector 根據上下文的背景添加一些字段作為 Tag,最終數據消費終端收到這些日志,通過這些 Tag 可以進行一些不同服務的關聯分析。
3、Vector-選擇理由

炎黃數據的研發內部環境中,也大量使用了 Vector ,給客戶的鴻鵠數據平臺的部署環境中也經常推薦客戶使用 Vector 進行原始數據的采集。在鴻鵠的數據平臺里面,我們也添加了使用 Vector 導入數據的原生的支持。
選擇 Vector 的理由如下:
- 第一 跨平臺的支持
主流的 OS 都可以安裝使用,可以滿足客戶不同的硬件環境。
- 第二 靈活的部署形式
可以作為 Agent,也可以作為 Aggregator。在比較復雜的分布式環境中部署具有靈活性。
- 第三 沒有環境依賴
執行只需要一個二進制的 Binary,不像有些工具可能還需要 Python 或者 Java 運行時環境。讓用戶可以進行最小化的容器部署。
- 第四 豐富的 Source 支持及強大的 Transform 的功能。
支持豐富且配置簡易靈活。在生產環境中要去新增某一種數據格式的采集時,可以很簡單地通過添加一個獨立的配置單元完成迭代。
- 最后,有良好的性能和可靠性
它包含了 Buffer 緩沖的功能、傳輸保障、內存安全等等這些特性
四、Vector + Honghu 構建可觀測性
1、搭建可觀測性數據流水線
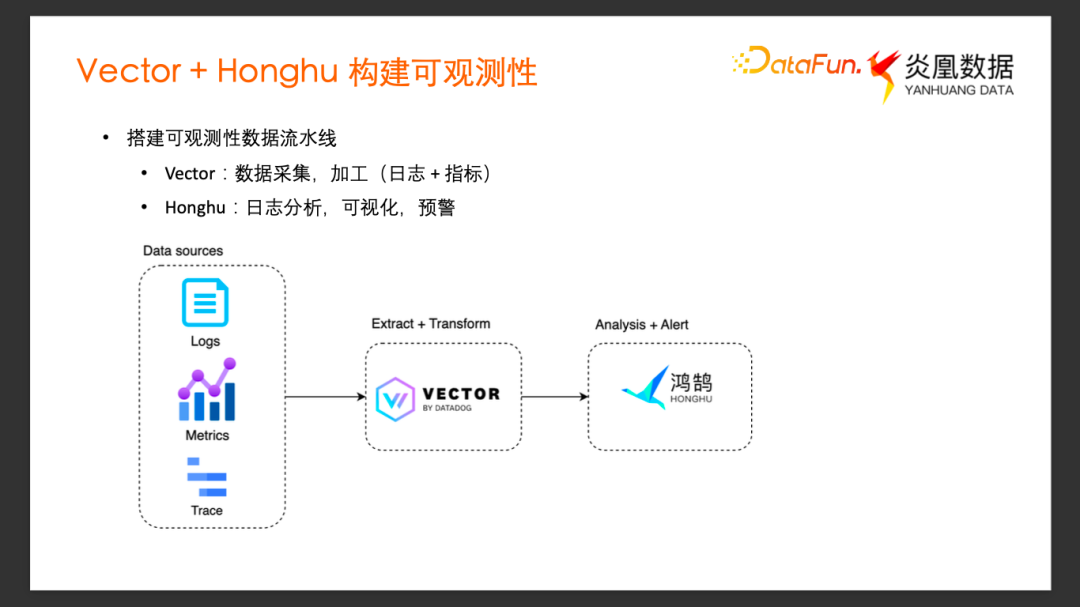
Vector 主要用于構建我們可觀測性數據流水線的前半部分。接下來介紹我們如何利用 Vector 和鴻鵠數據平臺搭建一個完整的可觀測性數據流水線。
鴻鵠是炎凰數據獨立研發的一款全棧式大數據分析平臺,它提供了從端到端的數據采集、導入、索引搜索,到最終的數據展示、任務告警等一系列服務。我們主要利用它對于異構數據的即時分析,可視化和告警這些功能,來組成可觀測性數據流水線的后半部分。
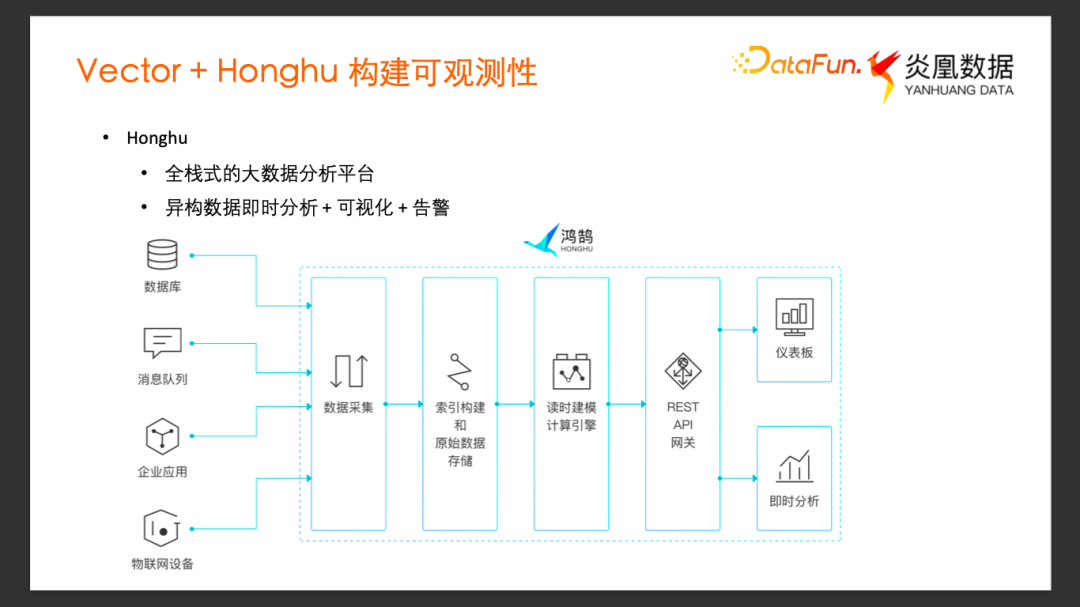
在搭建這個可觀測性數據流水線的過程中,首先使用 Vector 完成可觀測性數據的采集和加工,用它來收集日志和 Metrics 等等,然后用鴻鵠來完成日志分析、可視化和告警功能,構建最終的直觀的可觀測性。
這張圖展示了大致的數據流向,Vector 對原始的數據做采集以及加工,然后把加工過的數據 Load 到鴻鵠系統中,在鴻鵠中做數據的分析、告警等等的功能。
Vector 官方的 Sink 沒有鴻鵠 Sink,我們是怎么把數據 Load 進去的?
鴻鵠針對Vector 做了數據導入的原生支持,用戶可以通過類型為vector的Sink 直接把數據導入到鴻鵠,只需要在鴻鵠上做一些簡單的配置即可。
2、Honghu 支持通過 Vector 導入數據

首先我們在鴻鵠上開放了一個網絡端口,扮演Vector Aggregator 的角色。打開鴻鵠的 Web UI 做一些簡單配置,在鴻鵠的 web UI 上的數據導入頁面,選擇從外部數據源導入,就可以看到一個 Vector 類型的數據源,叫 system_default_vector_input,還可以看到配置里面有一個參數叫數據集范圍(在鴻鵠里面數據集就等同于傳統數據庫概念中表的概念,所有進入鴻鵠的數據必須屬于某個數據集,然后再從數據集中去查找使用它)。
我們編輯一下 Vector 的數據源配置:點擊編輯按鈕,彈出的窗口中可以配置的只有一項,就是數據集范圍,這個數據集的范圍是用來選擇“允許通過 Vector導入數據到哪一些鴻鵠的數據集”,這是一個白名單機制。接收數據的網絡端口默認是20000,不可以更改。

配置完成以后,點擊下載配置模板,在彈出的模板選項里面,選擇需要導入數據到哪一個目標數據集,以及導入的這個數據的數據源類型,比如格式 nginx.access_log,鴻鵠默認支持該數據的解析,選擇 Data Type 類型,點擊確定就會下載配置模板到本地,默認采用 Toml 格式。
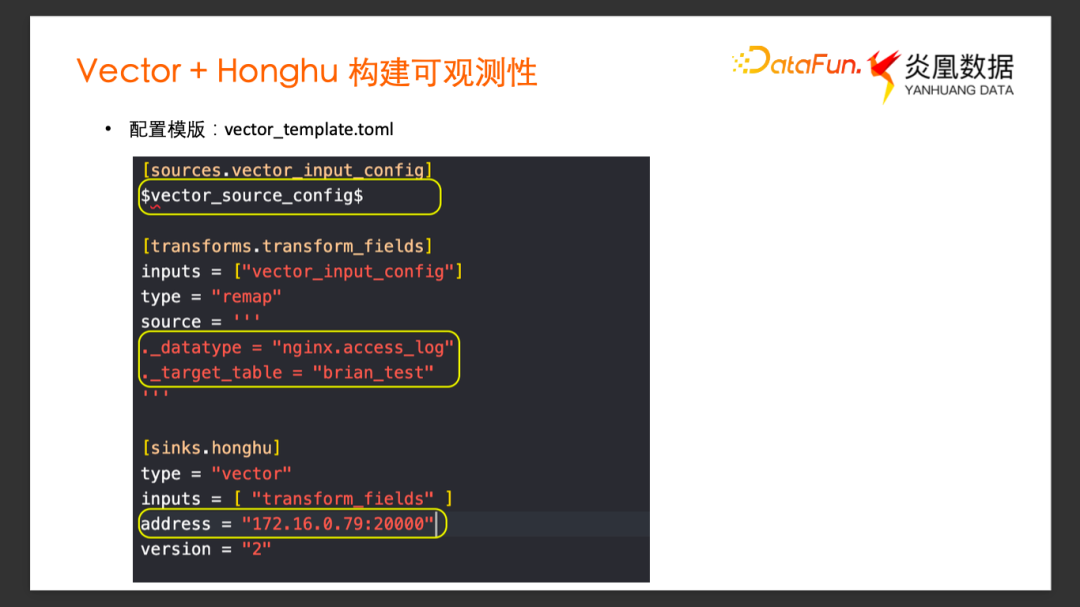
Vector template.toml 文件是標準的 vector的配置文件的模板。除了 Source 部分是預留給用戶自己添加,Transform 單元跟 Sink 單元基本都不需要再改變了。Transform 單元根據前面 UI 上的配置添加了兩個字段, _datatype 數據源類型是 nginx.access_log,_target_table 是數據最終要導入到的數據集,添加了這兩個字段以后,最終的 Transform 不需要再做額外的事情了。
最后的 Sink 單元,可以看到自動生成了鴻鵠可達 IP 地址,以及開放的端口,最終 Vector 采集的數據會通過這個網絡端口導入到鴻鵠系統中。我們接下來就可以用這個配置模板,再去添加一些 Source 相關的配置,以及增加一個前置的,用戶所需的一些 Transform 邏輯就可以完成一個完整的 Vector 配置文件了。
五、示例-構建honghu生產環境可觀測性
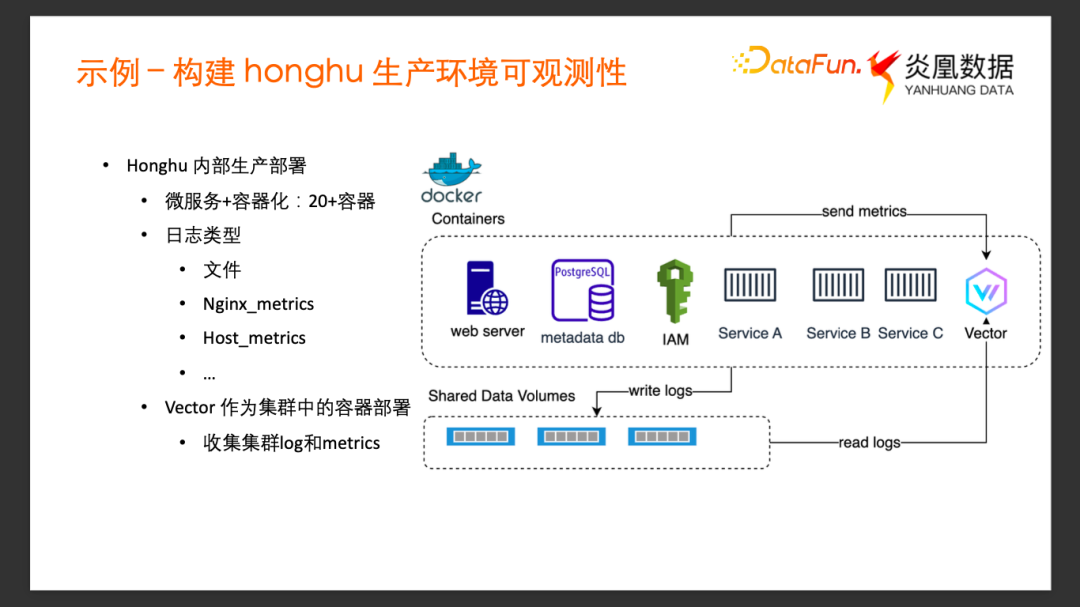
1、Honghu內部生產部署
前文對理論知識進行了介紹,接下來看一些具體的實例,
我們希望采用 Vector + 鴻鵠來構建鴻鵠內部生產環境的可觀測性。由于鴻鵠數據平臺是采用容器化 + 微服務的部署方式,在內部生產環境的部署中, 包含 Core DB 的服務、 Web 服務、 Metadata DB服務、身份認證服務等等。每一個微服務都是以容器的形式去運行的,因此鴻鵠生產環境中的每個服務都有各自的 Log,以及各自的 Metrics 需要采集。
在公司內部的鴻鵠生產環境中,除了前面提到的這些服務,由于測試需求,可能還會有更多的服務,比如,不同類型的 Database,不同的Message Queue如Kafka 等等。所以內部的部署環境有多達 20 個以上的容器微服務。日志的類型也非常多樣,有自定義的 Log、Web server 的 access log,或者容器主機的 Host Metrics 等等。
具體的部署模式參加上圖,我們把 Vector 也作為集群內的容器運行起來,首先將各個服務的日志文件Mount 到一個共享的 Volume 存儲中,這樣就可以通過內部Vector服務的文件 Source 采集所有的 Mount 到共享存儲的這些 Log 文件的數據。其他的一些 Metric 的數據,采用相應的 Metric Source 直接發送到 Vector。Vector 在采集完數據并進行加工以后,會通過配置模板里面寫好的端口直接發往鴻鵠的核心數據庫,存入到指定的數據集去供鴻鵠構建查詢與分析。
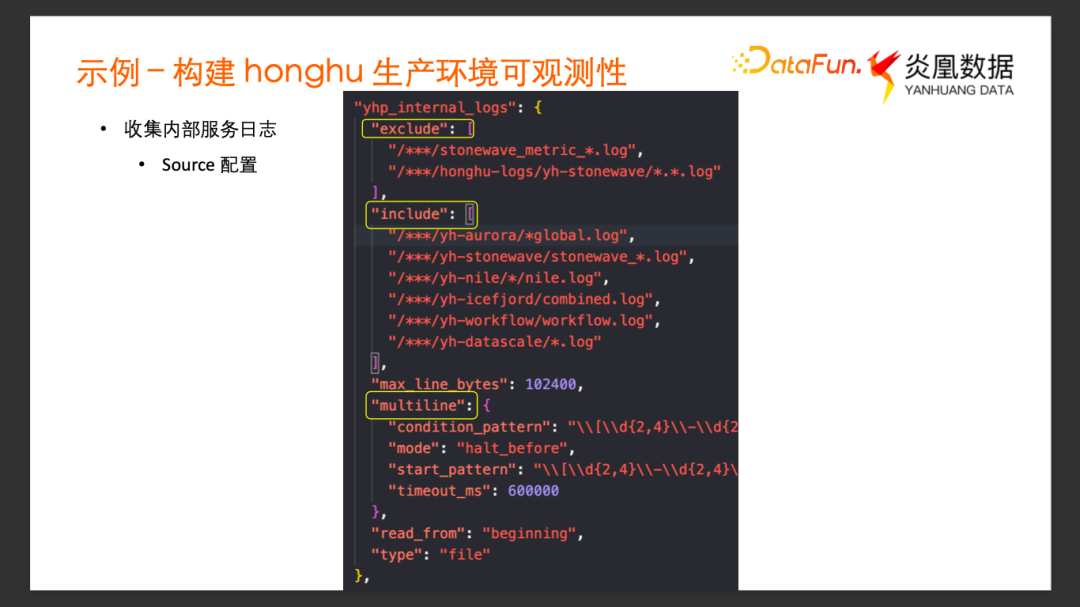
關于集群中 Vector的配置,這里僅挑選鴻鵠內部服務的 Log 文件的采集配置進行講解。
Source 配置
Source 配置(yhp_internal_logs)采集炎凰內部的日志的配置,Source Type 是文件。通過 Exclude 跟 Include 來決定哪些日志文件需要采集,哪些不需要采集。這里Multiline 的配置是 Vector 提供的用于識別多行 Log 的功能。內部的服務中有時候會打印出來含換行符的Log,或者 Log 很長寫文件的時候被自動分成多行,默認的日志采集又是以單獨的一行作為一條事件的。通過 Vector 的Multiline 的配置項,可以靈活地定義內部的多行 Log 的格式,將一些比較長的多行 Log 正確地識別為一條單獨的 Log 事件采集進來。

Transform 的配置和下載的模板文件沒有太大的差別,這里面將 _datatype 設置為 yhp__log,將_target_table設置成 _internal。

Sink 的配置基本上也不需要改動。Address 已經預填好了,是鴻鵠服務的一個可達的地址加 20000 端口。
這里面有一個叫 Compression 的選項,由于 Vector 到鴻鵠的數據傳輸是通過網絡走的,所以是否對傳輸的數據做壓縮,會影響到網絡的流量與速率。因為 Vector 跟鴻鵠的部署處于同一個主機的內部網絡中,網絡并不是瓶頸,所以在這里就選擇了 False,不對數據傳輸進行壓縮。
2、在 Honghu中查看日志

當Vector 采用定義好的配置文件跑起來以后,數據就會源源不斷地進入到配置好的目標鴻鵠數據集里面去了。在鴻鵠的管理界面上查看數據集的狀態,可以看到采集的內部的可觀測性數據,分別發往了_internal、_metrics、_audit 這三個數據集。在這個數據集的管理頁面可以看到這三個數據集的大小、事件計數以及事件的時間范圍等信息。

數據采集和接入部分完成后,接下來看一下如何通過鴻鵠構建生產環境的可觀測性。
鴻鵠是采用標準的 SQL 語言來進行數據的查詢分析的。點開查詢頁面通過一個最基本的查詢,先看看我們導入的日志事件是什么樣的。在上方的搜索輸入框里面可以看到我們對_internal 這個數據集進行了一個 select * 的查詢,通過查詢結果顯示可以看到每一條日志事件,除了其原始的日志內容以外,還有通過 Vector 采集的時候添加的字段,以及鴻鵠根據這個事件配置本身寫好的 data type做的自動抽取的字段。通過查詢的結果,進一步地去修改查詢,對日志事件進行分析,抽象出我們需要的持續的可觀測性的結果。
3、通過可視化能力創建可觀測性
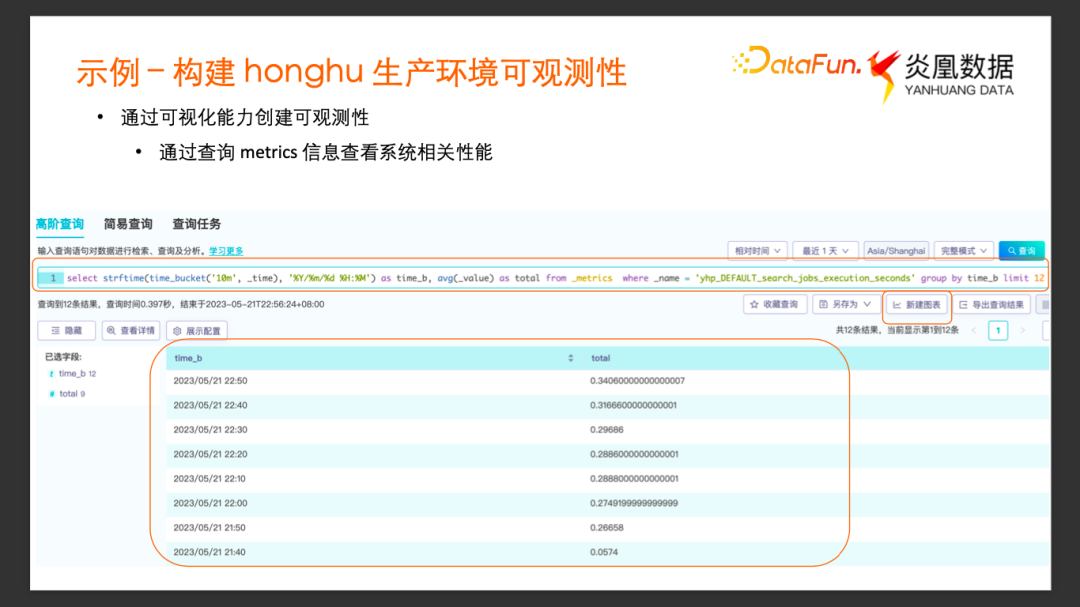
進一步通過示例來看如何通過查詢分析的過程構建可視化的可觀測性。
我們嘗試通過 _metrics 數據集中的事件,來持續觀測鴻鵠系統的查詢性能的變化。Metrics 的數據集里面導入了自定義的一些 Metrics 事件,比如yhp_DEFAULT_search_jobs_execution_seconds這個指標,代表鴻鵠查詢相關的執行時間的指標。我們希望利用這個指標數據,以每 10 分鐘為一個時間窗口統計鴻鵠查詢的平均耗時。
這個SQL分為幾個部分, 先從 _metrics 數據集中過濾出所有_name為yhp_DEFAULT_search_jobs_execution_seconds的事件。然后通過 time_bucket 的表函數劃分時間窗口,以每 10 分鐘為時間窗口來得到 time_b列 (這里_time 字段表示這個metrics收集的時間戳, _value字段表示 Job 執行耗時的具體數值。),然后以 time_b分組統計每一個時間窗口中 _value平均值,做 average 的操作。
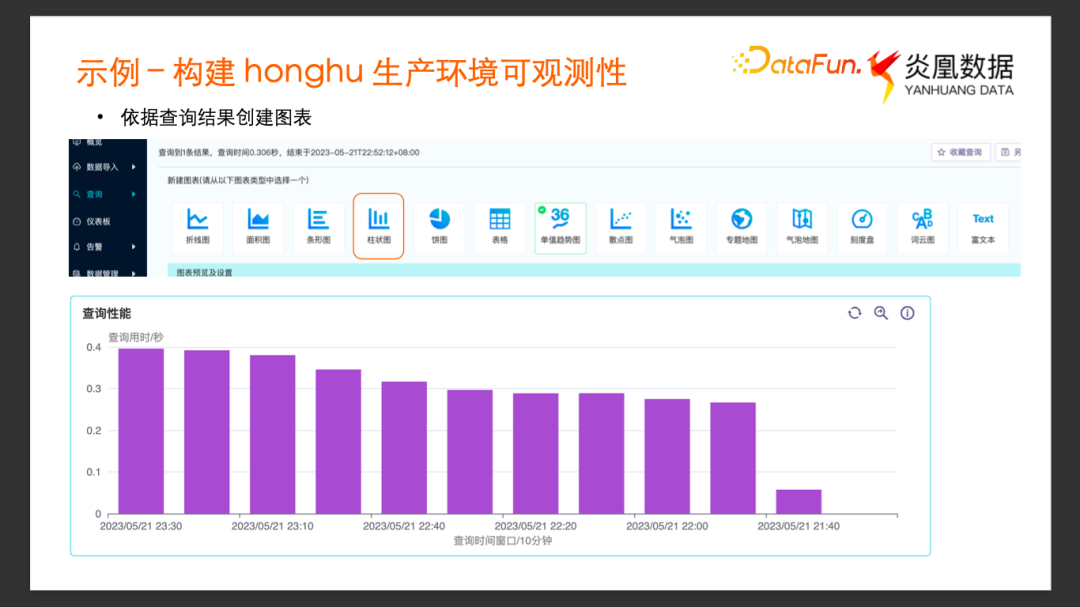
通過這個查詢可以得到如下圖所呈現的結果。
根據這個查詢結果去構建可視化的圖表,點擊右上方的新建圖表按鈕,選擇柱狀圖,通過對 X 軸、Y軸的簡單配置就可以得到下面這張查詢性能圖表。這樣就可以非常直觀地來監測系統查詢在不同時間段的性能。
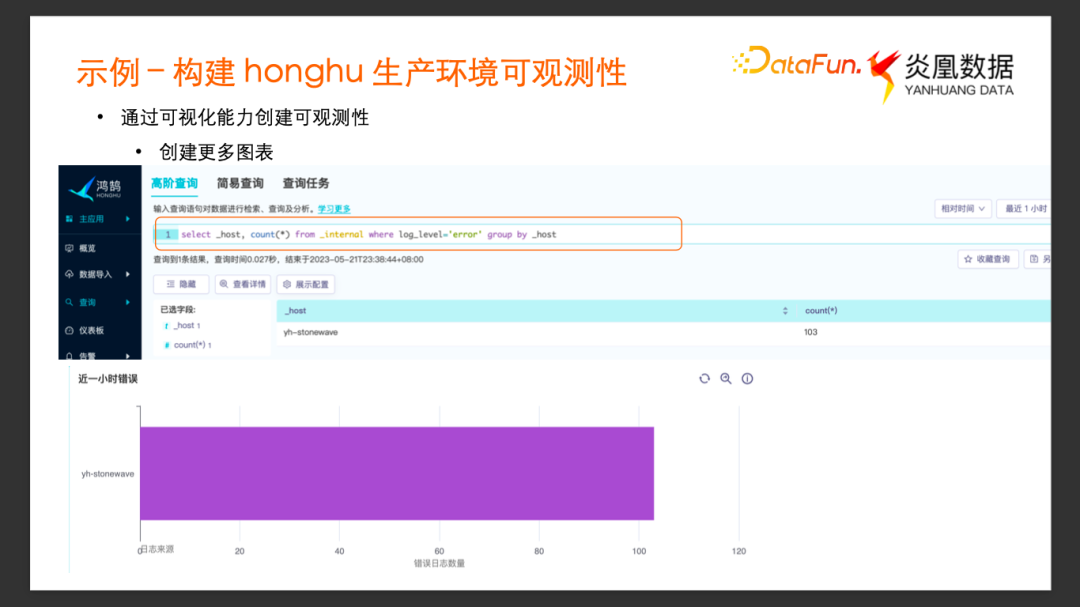
把這個圖表添加到儀表板以后,繼續添加更多的圖表。
為了檢測系統內部是否有異常狀態,可以對_internal 的 Log 進行更多的分析。比如不同服務打印的 Error Log 的數量,以及 Error Log 分別來自于哪些服務,我們以_host 作為分組指標,統計最近一個小時內 Log Level 是 Error 的計數。
查詢的結果可以看到有一個服務有 103 條 Error Log。把這個查詢新建為一張條形圖,也添加到儀表板去。
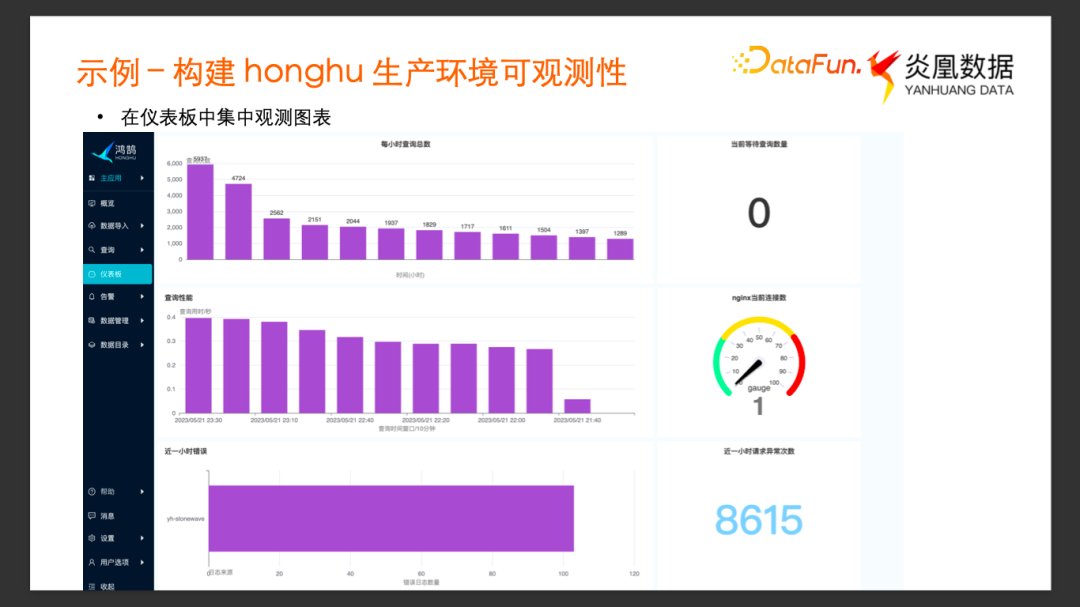
我們繼續通過不同的查詢構建不同的圖表,并添加到儀表板,最終得到了以上的示例儀表板。
通過這個儀表板,我們可以觀測到每個小時內鴻鵠系統查詢的總數,反映了系統當前的業務負載;可以觀測到每 10 分鐘內的平均查詢用時,以及當前在隊列中等待的查詢總數,通過這些圖表可以實時查看查詢系統是否過載。我們還可以通過查看 Nginx 當前連接數的儀表盤近一個小時內異常請求次數的單值圖,來觀察內部Web 服務的狀態;通過Error Log 的條數觀察內部的服務是否狀態異常等等。通過添加圖表,自由拖拽圖表排版,以及設置合適的刷新間隔,就構建了一個實時可觀測的儀表板。
4、利用查詢定位問題
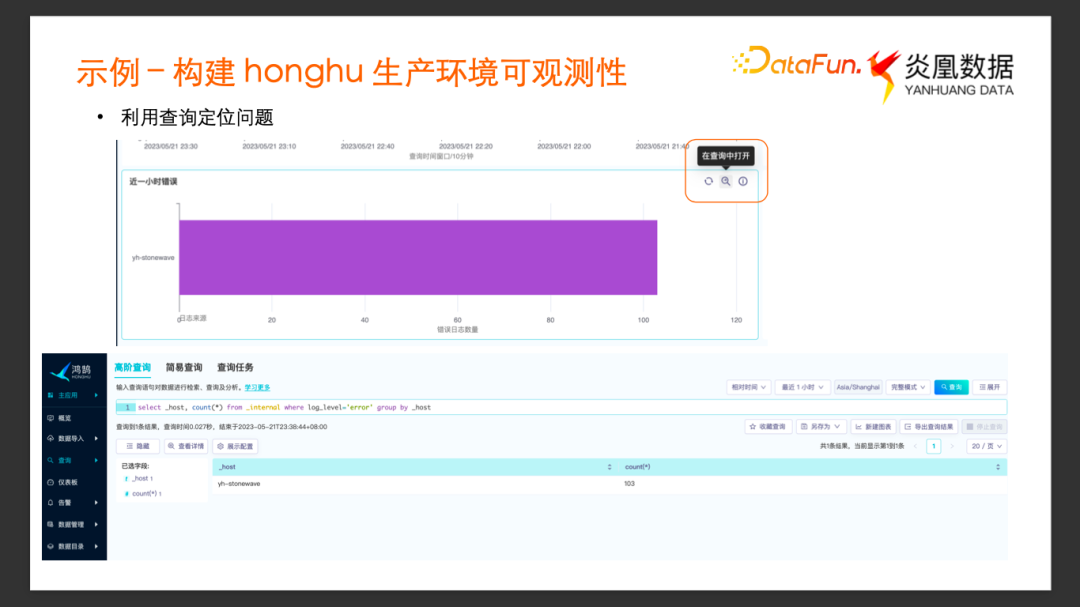
我們再來看看可觀測性系統的另一個應用場景:發現與定位系統問題。
我們在前面創建的 Error Log 計數統計圖表中,發現 stonewave這個服務打印了多條錯誤日志,于是我們嘗試通過鴻鵠去定位這個問題。
點擊圖表右上角的 “在查詢中打開” 按鍵會彈出一個窗口,進入圖表對應的查詢。為了理解發生了什么樣的錯誤,我們對查詢的 SQL 語句進行了適當的修改。

通過查詢列出這個服務具體有哪些 Error Log,通過 Error Log 內容,大致可以了解服務發生了怎樣的 Error,但是此時可能還不確定是什么原因導致了這個error。

于是進一步對單條的Log 進行分析,在有問題的這條 Log 事件操作中選擇“查看事件上下文”。

用于定位的這條 Log 被藍色高亮顯示,也可以看到這個時間點前后的一些 Log。
然后通過右上方展示的信息,我們可以知道這個事件的上下文展示的是和該條 Log 相同 Host,相同 Source 來源的 Log 事件的上下文,是不會跟其它服務混淆的。這里默認的上下文 Log 數量是50,如果數量不足以輔助我們進行分析,也可以選擇更大的行數。
通過往前回溯或者往下追蹤其他 Log,可以進一步定位是什么原因導致了這個 Error,以及這個 Error 可能產生哪些后續的影響。
這就是一個可觀測性輔助定位問題的例子。從最直觀的可視化的圖表開始去發現問題,然后通過進一步查詢及下探這個事件的上下文,最終定位問題產生的原因及可能的影響,來輔助我們決策是否需要以及如何對出現問題的服務進行干預以保證服務的正常運行。
5、示例總結
以上就是利用鴻鵠 + Vector 去構建可觀測性的實例。
在這個可觀測性的數據流水線中,我們利用 Vector 的日志采集能力完成了數據的采集和加工,并將我們關心的事件導入到鴻鵠中,然后利用鴻鵠系統的實時查詢以及可視化能力,完成對生產環境中各服務的實時分析以及可視化。最后還可以利用鴻鵠的告警功能設定一些查詢計劃,對于異常的查詢結果可以采用郵件或者 Webhook 等方式完成告警。
這里只展示了部分的可觀測性場景,在實際生產環境中檢測的系統狀態會比這里展示的更加復雜多樣。在鴻鵠的企業版里面,使用的是 Kubernetes 的集群,K8S 的集群,里面會有更多的節點和更多的服務。需要觀測的數據量也會要大得多。通過 Vector 的靈活性以及鴻鵠自身強大的異構數據的分析能力,能夠高效地構建整個集群的可觀測性。
除了上面分享的案例外,鴻鵠社區中還有很多利用 Vector 與鴻鵠構建可觀測性數據流水線的案例。

大家如果感興趣,可以通過鴻鵠的文檔社區查看具體的實踐。
以上就是本次分享的內容,感謝大家。
六、Q&A
Q1:Vector 通過 Agent 部署,支持收集 Docker 的日志,那么對于 Kubernetes 的日志來說也是能收集的。但是 Container 日志當中包含 Liveness 和 Readness probe ??的間隔信息,使用 Vector 是否可以收集并且聚合事件?
A1:Vector支持直接收集kubenetes logs,至于對liveness和readiness的聚合,可以通過 Vector 的 Transform 的功能來做,需要用戶自己去編寫 VRL配置。
Q2 :剛才陳老師有提到這個 Vector 里邊具有緩沖策略,那是不是說如果數據采集中的數據流量較大,它能夠保證數據不丟?
A2:Vector 提供具有一定靈活性的緩沖策略,能夠通過配置一定大小 Memory Buffer,或者 Disk Buffer 來緩沖未處理完的事件。但是如果超過配置的大小的時候,會按一定策略丟棄掉未處理完的事件,所以它也是可能會丟數據的,取決于具體的實踐中怎么樣去調整它的配置。如果是對數據丟失比較敏感的場景中,建議還是去搭配一些比較成熟的 Memory queue的工具,例如 Kafka 結合使用保證更健壯的 Durability 特性。
Q3:關于 Vector 的一個圖形界面的問題,目前看到的這些 Transform 的邏輯,需要專門寫 VRL 語言的代碼,是不是學習成本比較高?有沒有圖形化的界面可以拖拽來做 Transform 的操作?
A3:據我了解 Vector 好像沒有圖形界面的。關于 VRL 語言,個人覺得學習成本不算太高,大家可以看它的官方文檔,里面有比較詳細地列出了每一個的語法,以及內置的一些 Remap 函數的示例,整體的語法還是相對簡單跟清晰的。
個人覺得沒有圖形界面,是它產品本身的特點決定的,它提供了很靈活的部署的方式,所以很多時候 Vector 是作為容器部署在集群內部,作為后臺服務去運行的。只是一個簡單的可執行文件 + 配置文件的搭配,很容易地去移植到不同的容器、不同的服務中。圖形化的配置界面更適合是一些 Saas 或者基于 SaaS 的采集工具,資源都是集中在云上的,需要有一個統一的配置頁面來用來管理這些配置,跟 Vector 的應用場景可能不太一樣,所以我覺得 Vector 可能不需要也沒有動力去做圖形界面的管理工具。
Q4:Vector 運行之后是不是支持配置文件的熱加載?
A3:vector支持熱加載,可以在修改配置后reload,也可以在啟動時使用watch選項自動觀測配置文件的變化并熱加載。它可以 gracefully restart, 保證加載新的配置以后不會把之前的一些進行一半的一些任務丟掉。
Q5:運行中的 Vector Transform 的節點是否能夠根據數據量的大小做擴容和縮容, Vector 是怎么解決類似的這樣的問題的?
A5:如果是考慮到單個vector服務的并發性能的話,Vector有一個很好的 Concurrency 的并發模型,不需要通過人為地去干預它的并發配置的調整,它會根據數據量大小去相應調整并發線程。不需要用戶人為配置。
如果說的是vector節點數量的擴容的話,那其實涉及到具體的部署形式和場景的不同,可能需要考慮的東西也不一樣,沒法很籠統地概括。
Q6:采集到的數據經過多次的聚合之后,是否還能夠保持數據的有序性?
A6:每一條原始event都會有 個timestamp ,這個timestamp可能是數據源產生的,也可能是vector幫你添加的。由于聚合操作是多到一的操作,因此每經過一次聚合,產生的新的 timestamp可能就與原始事件不同了。所以雖然vector能保證原始事件采集的有序性, 但是如果你經過了自定義的聚合操作,那聚合后的數據是否還是”有序的“,就要取決于你的聚合操作里的具體邏輯了。
Q7:收集到的數據有沒有匹配的預警模型庫?
A7:這位同學可能了解過數據可觀測性相關的一些工具,比如說什么 Databend 或者 Integrate 這種工具專門用來做數據可觀測性的,把整個鏈路都做得很完善,可以直接通過某個數據模型去生成預警。
但是我們的這套策略, Vector 本身不支持這個功能,而鴻鵠是一個實時的綜合的通用的異構日志分析平臺,可以利用鴻鵠的告警功能,通過 Vector 把數據導進來,然后自己去構建針對日志數據的查詢,再通過鴻鵠的告警功能周期性地 Schedule 你關心的查詢,根據查詢的結果去觸發相關的告警的功能。這是我們是用比較通用的工具做到專用工具能做到的事情的例子。
Q8:Vector 里邊有豐富的 Transform 的功能,比如,日志解析的函數,看到最后的示例里邊好像收集鴻鵠生產環境的日志的時候,沒有用到很多的解析功能,這是什么樣原因?
A8:這位同學觀察得非常細致,在剛才采集內部日志和 Metrics 過程中,沒有用之前提到的很多的 Transform 的方法,比如,既定數據格式的解析。這里面有兩個原因,一個是當我們使用 Vector 的 Transform 去做一些解析并提取字段的時候,我們往往是很清楚自己需要這個原始的事件中的哪些字段信息的。同時會去丟棄掉一些不需要的字段信息。我們的內部 Log 其實包含了很多字段信息,在鴻鵠中做分析之前,很多時候我們不知道哪些信息是確定不需要的,所以更多的選擇不在 Vector 采集的過程中去解析原始的事件。第二個原因是由于鴻鵠本身也有很強大的導入時以及查詢時的事件解析功能,可以通過 Vector 只導入原始的事件,在鴻鵠中做字段解析,并索引解析后的字段,也可以去在查詢的時候再決定如何對原始的事件做解析,抽取出關心的字段信息。
總的來說,由于鴻鵠有比較好的解析和查詢能力,所以我們可以盡量地保留原始的日志事件,獲得對日志解析的能力。所以在自己使用的時候,就覺得沒有必要在 Vector 中提前做確定性的解析,因為這就丟失了后面可能用到的信息。
Q9:日志有做加密嗎?行業內有沒有安全存儲的要求?
A9:第一個問題日志有沒有做加密是想問日志中的一些敏感信息字段能否加密嗎?vector的 Transform 過程中有很多的方法,可以針對某一些特定字段做處理,例如redact這個VRL function就可以對敏感字段的數據做mask處理。
第二個問題行業內有沒有安全存儲的要求? 日志在進入到鴻鵠系統以后是以我們特定的格式存儲的。我不太確定你這里說的“行業內安全存儲要求”具體是指什么,如果問題能描述得更清楚些我們可以再進一步討論下。
主持人:關于這一塊加密這一塊的話可以稍微做一點補充,關于日志做加密,我猜想是想說做 Vector 做日志采集傳輸的時候,有沒有一些加密的功能?本身 Vector 可以配置這個 TSL、SSL 傳輸的,可以通過這樣的方式來保證傳輸過程當中的數據的安全可靠。也可以看一下鴻鵠社區最佳實踐的文章里面也有相關的這個文章講怎樣做加密的數據傳輸?
Q10:多節點擴容 Vector 有解決方案嗎?
A10:Vector 支持作為 Agent 以及 Aggregator 的不同部署形式,并且在配置上也支持熱加載,不同vector之間也沒有狀態耦合。這些特性決定了在集群中添加或減少vector服務數量是比較方便的。但是同樣的,“多節點擴容解決方案”也是一個比較籠統的需求,還是得看用戶具體的業務部署模型是什么樣的,才能更具體地解答這個問題。