













我們一起聊聊并發編程:線程池
一、線程池的實現原理
下圖所示為線程池的實現原理:調用方不斷地向線程池中提交任務;線程池中有一組線程,不斷地 從隊列中取任務,這是一個典型的生產者—消費者模型。
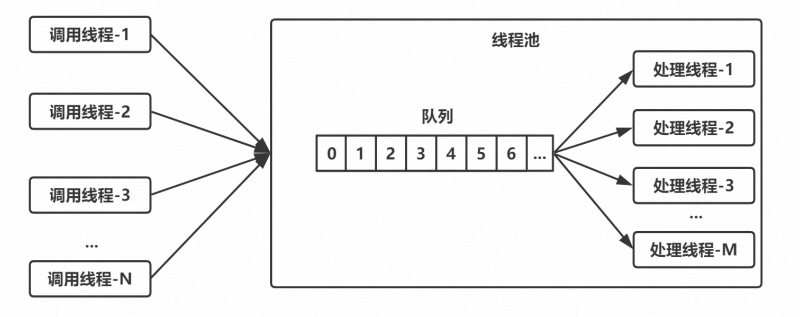
要實現這樣一個線程池,有幾個問題需要考慮:
1. 隊列設置多長?如果是無界的,調用方不斷地往隊列中放任務,可能導致內存耗盡。如果是有 界的,當隊列滿了之后,調用方如何處理?
2. 線程池中的線程個數是固定的,還是動態變化的?
3. 每次提交新任務,是放入隊列?還是開新線程?
4. 當沒有任務的時候,線程是睡眠一小段時間?還是進入阻塞?如果進入阻塞,如何喚醒?
針對問題4,有3種做法:
1. 不使用阻塞隊列,只使用一般的線程安全的隊列,也無阻塞/喚醒機制。當隊列為空時,線程 池中的線程只能睡眠一會兒,然后醒來去看隊列中有沒有新任務到來,如此不斷輪詢。
2. 不使用阻塞隊列,但在隊列外部、線程池內部實現了阻塞/喚醒機制。
3. 使用阻塞隊列。
很顯然,做法3最完善,既避免了線程池內部自己實現阻塞/喚醒機制的麻煩,也避免了做法1的睡 眠/輪詢帶來的資源消耗和延遲。正因為如此,接下來要講的
ThreadPoolExector/ScheduledThreadPoolExecutor都是基于阻塞隊列來實現的,而不是一般的隊列, 至此,各式各樣的阻塞隊列就要派上用場了
二、線程池的類繼承體系
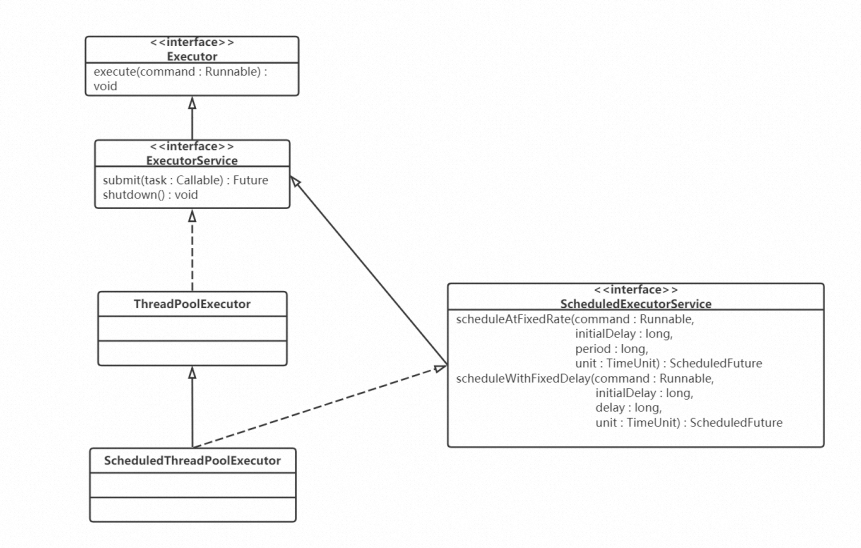
在這里,有兩個核心的類: ThreadPoolExector 和
ScheduledThreadPoolExecutor ,后者不僅 可以執行某個任務,還可以周期性地執行任務。
向線程池中提交的每個任務,都必須實現 Runnable 接口,通過最上面的 Executor 接口中的 execute(Runnable command) 向線程池提交任務。
然后,在ExecutorService 中,定義了線程池的關閉接口 shutdown() ,還定義了可以有返回值 的任務,也就是 Callable ,后面會詳細介紹。
三、ThreadPoolExecutor
1、核心數據結構
基于線程池的實現原理,下面看一下ThreadPoolExector的核心數據結構。
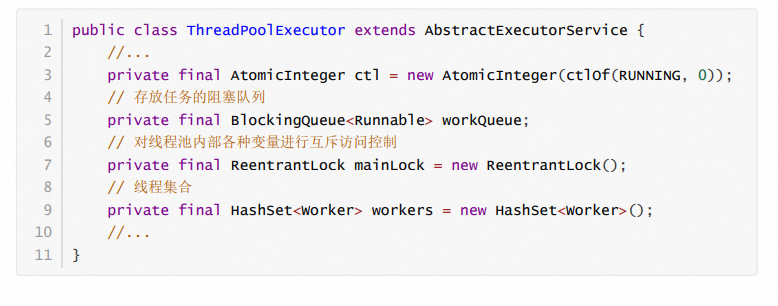
每一個線程是一個Worker對象。Worker是ThreadPoolExector的內部類,核心數據結構如下:

由定義會發現,Worker繼承于AQS,也就是說Worker本身就是一把鎖。這把鎖有什么用處呢?用于線程池的關閉、線程執行任務的過程中。
2、核心配置參數解釋
ThreadPoolExecutor在其構造方法中提供了幾個核心配置參數,來配置不同策略的線程池。
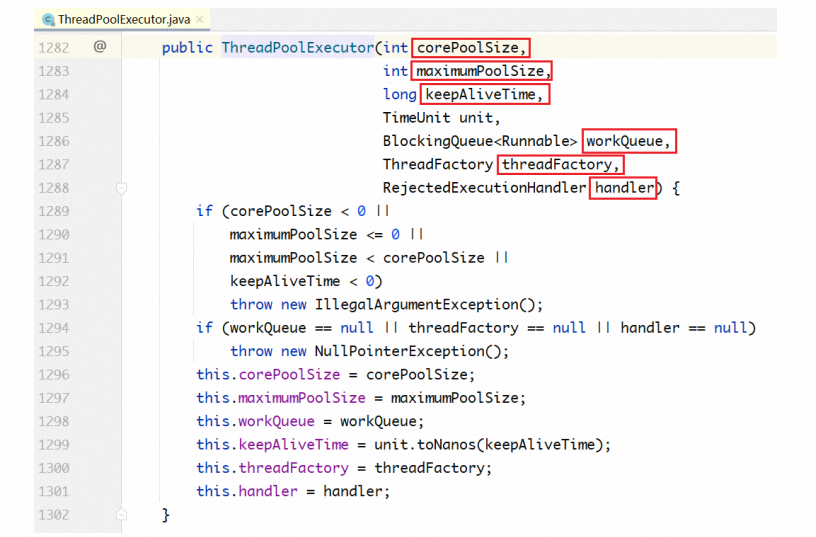
上面的各個參數,解釋如下:
1. corePoolSize:在線程池中始終維護的線程個數。
2. maxPoolSize:在corePooSize已滿、隊列也滿的情況下,擴充線程至此值。
3. keepAliveTime/TimeUnit:maxPoolSize 中的空閑線程,銷毀所需要的時間,總線程數收縮 回corePoolSize。
4. blockingQueue:線程池所用的隊列類型。
5. threadFactory:線程創建工廠,可以自定義,有默認值
Executors.defaultThreadFactory()
6. RejectedExecutionHandler:corePoolSize已滿,隊列已滿,maxPoolSize 已滿,最后的拒 絕策略。
下面來看這6個配置參數在任務的提交過程中是怎么運作的。在每次往線程池中提交任務的時候,有 如下的處理流程:
步驟一:判斷當前線程數是否大于或等于corePoolSize。如果小于,則新建線程執行;如果大于, 則進入步驟二。
步驟二:判斷隊列是否已滿。如未滿,則放入;如已滿,則進入步驟三。
步驟三:判斷當前線程數是否大于或等于maxPoolSize。如果小于,則新建線程執行;如果大于, 則進入步驟四。
步驟四:根據拒絕策略,拒絕任務。
總結一下:首先判斷corePoolSize,其次判斷blockingQueue是否已滿,接著判斷maxPoolSize, 最后使用拒絕策略。 很顯然,基于這種流程,如果隊列是無界的,將永遠沒有機會走到步驟三,也即maxPoolSize沒有 使用,也一定不會走到步驟四。





























