如何使用地理分區來遵守數據法規并在全球范圍內提供低延遲
譯文譯者 | 李睿
審校 | 重樓
在當今互聯互通的世界中,用戶可以跨越多個大洲和國家使用應用程序。在處理數據監管要求的同時,在遙遠的地理位置保持低延遲可能是一個挑戰。分布式SQL數據庫的地理分區功能可以通過將用戶數據固定到所需的位置來幫助解決這一挑戰。

因此,以下探討如何使用YugabyteDB Managed部署符合數據規則并跨多個區域提供低延遲的地理分區數據庫集群。
使用YugabyteDB Managed部署地理分區集群
YugabyteDB是一個基于PostgreSQL的開源分布式SQL數據庫。用戶可以使用YugabyteDB Managed (YugabyteDB的DBaaS版本)在幾分鐘內部署地理分區集群。
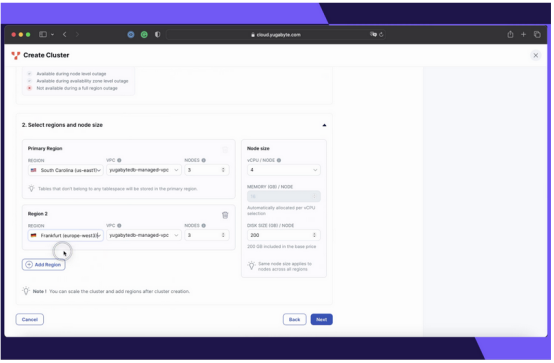
開始使用地理分區的YugabyteDB托管集群很容易。只需遵循以下步驟:
1.選擇“多區域部署”選項。在創建專用YugabyteDB Managed集群時,選擇“多區域”選項,以確保數據分布在多個區域。
2.將數據分布模式設置為“分區”。選擇“按區域劃分”數據分發選項,以便用戶可以將數據固定到特定的地理位置。
3.選擇目標云區域。將數據庫節點放置在用戶選擇的云區域中。在這篇博客文章中,將數據分散到兩個區域——南卡羅來納州(美國東部)和法蘭克福(歐洲西部)。
一旦設置了地理分區的YugabyteDB Managed集群,就可以連接到它并創建帶有分區數據的表。
創建地理分區表
為了演示地理分區如何改善延遲和數據法規的合規性,以一個帳號表為例。
首先,創建PostgreSQL表空間,讓用戶可以將數據固定在USA (usa_tablespace)或Europe (europe_tablespace)的YugabyteDB節點上。
SQL
CREATE TABLESPACE usa_tablespace WITH (
replica_placement = '{"num_replicas": 3, "placement_blocks":
[
{"cloud":"gcp","region":"us-east1","zone":"us-east1-c","min_num_replicas":1},
{"cloud":"gcp","region":"us-east1","zone":"us-east1-d","min_num_replicas":1},
{"cloud":"gcp","region":"us-east1","zone":"us-east1-b","min_num_replicas":1}
]}'
);
CREATE TABLESPACE europe_tablespace WITH (
replica_placement = '{"num_replicas": 3, "placement_blocks":
[
{"cloud":"gcp","region":"europe-west3","zone":"europe-west3-a","min_num_replicas":1},
{"cloud":"gcp","region":"europe-west3","zone":"europe-west3-b","min_num_replicas":1},
{"cloud":"gcp","region":"europe-west3","zone":"europe-west3-c","min_num_replicas":1}
]}'
);- num_replicas: 3——每個表空間要求用戶在一個區域內的三個可用性區域中存儲數據副本。這使用戶能夠容忍云中的區域級中斷。
其次,創建帳號表并按country_code列對其進行分區:
SQL
CREATE TABLE Account (
id integer NOT NULL,
full_name text NOT NULL,
email text NOT NULL,
phone text NOT NULL,
country_code varchar(3)
)
PARTITION BY LIST (country_code);第三,為美國和歐洲記錄定義分區表
SQL
CREATE TABLE Account_USA PARTITION
OF Account (id, full_name, email, phone, country_code,
PRIMARY KEY (id, country_code))
FOR VALUES IN ('USA') TABLESPACE usa_tablespace;
CREATE TABLE Account_EU PARTITION
OF Account (id, full_name, email, phone, country_code,
PRIMARY KEY (id, country_code))
FOR VALUES IN ('EU') TABLESPACE europe_tablespace;- FOR VALUES IN ('USA')——如果country_code等于‘USA',則自動從存儲在usa_tablespace(南卡羅來納州的區域)中的Account_USA分區中放置或查詢該記錄。
- FOR VALUES IN ('EU') ——否則,如果記錄屬于歐洲(country_code等于‘EU’),那么它將存儲在europe_tablespace(法蘭克福地區)的Account_EU分區中。
現在檢查一下用戶從美國連接時的讀寫延遲。
從美國連接時的延遲
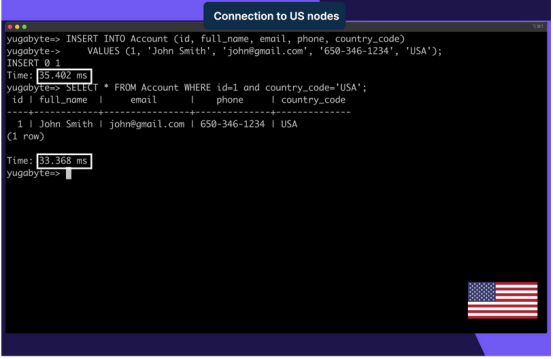
打開一個從愛荷華州(us-central1)到位于南卡羅來納州(us-east1)的數據庫節點的客戶端連接,并插入一條新的帳戶記錄:
SQL
INSERT INTO Account (id, full_name, email, phone, country_code)
VALUES (1, 'John Smith', 'john@gmail.com', '650-346-1234', 'USA');只要country_code為“USA”,記錄就會存儲在來自南卡羅來納州的數據庫節點上。寫入和讀取延遲大約為30毫秒,因為客戶端請求需要在衣阿華州和南卡羅來納州之間傳輸。
接下來,看看當添加和查詢country_code設置為‘EU’的帳戶時會發生什么:
SQL
INSERT INTO Account (id, full_name, email, phone, country_code)
VALUES (2, 'Emma Schmidt', 'emma@gmail.com', '49-346-23-1234', 'EU');
SELECT * FROM Account WHERE id=2 and country_code='EU';由于這一帳戶必須存儲在歐洲數據中心中,并且必須在美國和歐洲之間傳輸,因此增加了延遲。
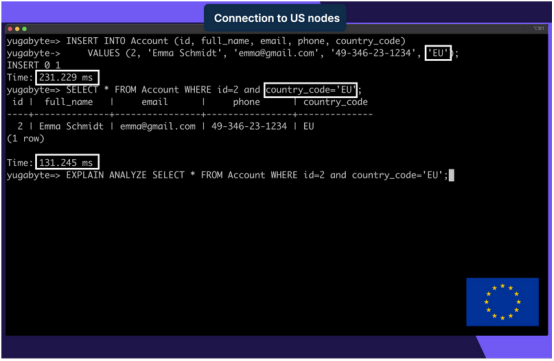
- INSERT的延遲(230毫秒)高于SELECT的延遲(130毫秒),因為在INSERT期間,記錄會在法蘭克福的三個可用性區域中復制。
美國的客戶端連接和歐洲的數據庫節點之間的延遲更高,這意味著地理分區集群使用戶符合數據監管要求。即使來自美國的客戶端連接到基于美國的數據庫節點并寫入/讀取來自歐洲居民的記錄,這些記錄也將始終從歐洲的數據庫節點存儲/檢索。
從歐洲連接時的延遲
讓我們看看,如果打開從法蘭克福(europe-west3)到同一區域的數據庫節點的客戶端連接,并查詢最近從美國添加的歐洲記錄,延遲是如何改善的:
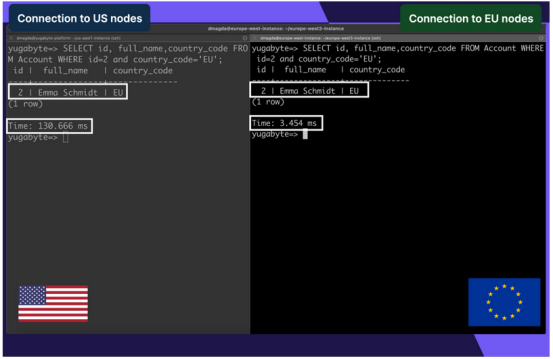
這一次延遲低至3毫秒(從美國查詢同一條記錄時為130毫秒),因為該記錄存儲在歐洲數據中心并從歐洲數據中心檢索。
只要數據不復制到美國,添加和查詢另一個歐洲記錄也可以保持低延遲。
SQL
INSERT INTO Account (id, full_name, email, phone, country_code)
VALUES (3, 'Otto Weber', 'otto@gmail.com', '49-546-33-0034', 'EU');
SELECT * FROM Account WHERE id=3 and country_code='EU';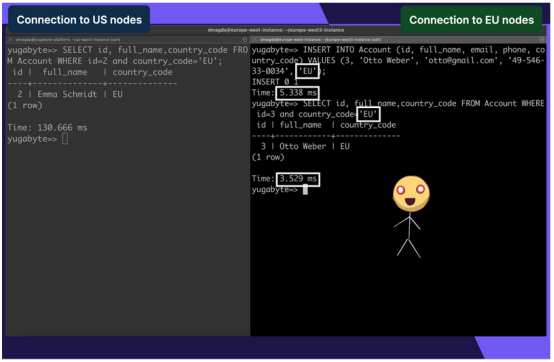
當訪問存儲在同一區域的數據時,延遲顯著降低。其結果是在遵守數據監管要求的同時提供了更好的用戶體驗。
結語
地理分區是一種符合數據規則和實現全局低延遲的有效方法。通過使用YugabyteDB Managed部署地理分區集群,可以智能地跨區域分發數據,同時保持高性能查詢功能。
原文標題:How To Use Geo-Partitioning to Comply With Data Regulations and Deliver Low Latency Globally,作者:Denis Magda