作者 | 波哥
審校 | 重樓
隨著互聯網應用的不斷發展和用戶量的不斷增加,傳統的數據庫在應對高并發和大數據量的場景下面臨著巨大的挑戰。為了解決這一問題,分庫分表成為了一個非常流行的方案。分庫分表主流的技術包括MyCat和Sharding JDBC。我們來通過一張圖來了解這兩者有什么區別:
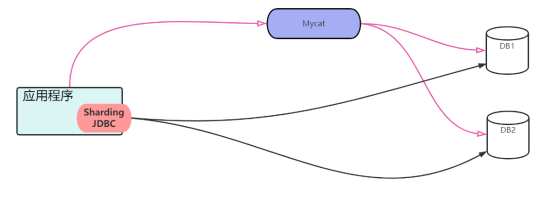
從上圖可以看到,MyCat是一個單獨的中間件,讀者朋友們可以把它理解為一個數據庫(不過它不是數據庫哦,只是對于應用端來說連接使用MyCat和數據庫是一樣的,對應用程序來說,不需要關心具體是數據庫還是MyCat;而Sharding JDBC則是整合到應用端的,它運行在應用端,和代碼的耦合性相對MyCat來說要更高)。本文筆者將深入探索Sharding JDBC,介紹其核心概念、工作原理以及使用方法,并通過一個示例幫助讀者更好地理解和應用Sharding JDBC。
1. 什么是Sharding JDBC?
Sharding JDBC是一款基于Java的開源中間件,用于簡化分庫分表的操作和管理。它提供了一套統一的接口和封裝,屏蔽了底層數據庫的細節,讓開發者可以像使用單一數據庫一樣操作分布式數據庫。
2. Sharding JDBC的核心概念
2.1 數據庫切片(Sharding)
數據庫切片是指將一個大型數據庫按照某種規則拆分成多個較小的數據庫實例,每個數據庫實例稱為一個切片。切片可以根據不同的規則進行拆分,如按照用戶ID、地域等進行劃分。
2.2 分布式表(Sharding Table)
分布式表是指將一個表按照某種規則拆分成多個子表,每個子表存儲了相同表結構的不同數據。通常,分布式表的拆分規則與數據庫切片的規則相一致。
2.3 數據庫路由(Database Sharding)
數據庫路由是指根據某種規則將數據庫的操作路由到對應的數據庫切片上。Sharding JDBC提供了路由策略的配置,可以根據業務需求進行靈活的配置。
2.4 表路由(Table Sharding)
表路由是指根據某種規則將數據操作路由到對應的分布式表上。Sharding JDBC同樣提供了靈活的表路由策略配置,支持多種分表策略。
3. Sharding JDBC的工作原理
簡單來說,Sharding JDBC的工作原理可以概括為以下幾個步驟:
- 客戶端發起數據庫操作請求。
- Sharding JDBC根據路由策略解析請求,確定對應的數據庫切片和分布式表。
- Sharding JDBC將請求轉發給對應的數據庫切片和分布式表。
- 數據庫切片和分布式表執行具體的數據庫操作。
- 結果返回給Sharding JDBC,再由Sharding JDBC返回給客戶端。
Sharding JDBC通過對數據庫操作的解析和轉發,實現了透明的分庫分表功能,對上層應用透明,使得應用無需關心分布式數據庫的復雜性。
4. 如何使用Sharding JDBC?
接下來,我們一起來看下如何使用。使用Sharding JDBC可以分為以下幾個步驟:
4.1 引入Sharding JDBC依賴
在項目的pom.xml文件中引入Sharding JDBC的相關依賴,以及對應的數據庫驅動依賴。
4.2 配置數據源和數據庫規則
在配置文件中配置數據源和數據庫規則,包括數據庫連接信息、數據庫切片和分布式表的規則等。
4.3 編寫業務代碼
編寫業務代碼時,使用Sharding JDBC提供的API進行數據庫操作,無需關心具體的數據庫切片和分布式表。
下面筆者根據上述步驟,以一個例子來詳細展示具體的使用方法:
我們以用戶表和訂單表為例,對其分庫分表。
A.引入Sharding JDBC依賴,可以通過Maven來管理項目依賴。
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>xxx</version>
</dependency>B.配置數據源和數據庫規則,在application.yaml中進行配置。
spring:
shardingsphere:
datasource:
# 數據源配置,定義兩個數據源
names: ds0, ds1
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/database0
username: root
password: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/database1
username: root
password: root
sharding:
tables:
# 訂單表的配置
order:
actualDataNodes: ds${0..1}.order_${0..3}
# 表路由策略,根據用戶ID進行分表
tableStrategy:
standard:
shardingColumn: user_id
preciseAlgorithmClassName: com.example.algorithm.PreciseModuloTableShardingAlgorithm
# 數據庫路由策略,根據用戶ID進行分庫
databaseStrategy:
standard:
shardingColumn: user_id
preciseAlgorithmClassName: com.example.algorithm.PreciseModuloDatabaseShardingAlgorithmC.編寫自定義的分表策略和分庫策略。例如,我們自定義了
PreciseModuloTableShardingAlgorithm和PreciseModuloDatabaseShardingAlgorithm兩個算法類,根據用戶ID進行分表和分庫的計算。
public class PreciseModuloTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Long> shardingValue) {
for (String tableName : tableNames) {
if (tableName.endsWith(String.valueOf(shardingValue.getValue() % 4))) {
return tableName;
}
}
throw new IllegalArgumentException("Unsupported table name: " + shardingValue.getLogicTableName());
}
}
public class PreciseModuloDatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> shardingValue) {
for (String databaseName : databaseNames) {
if (databaseName.endsWith(String.valueOf(shardingValue.getValue() % 2))) {
return databaseName;
}
}
throw new IllegalArgumentException("Unsupported database name: " + shardingValue.getLogicTableName());
}
}D. 編寫業務代碼,使用Sharding JDBC進行數據庫操作。
@Repository
public class OrderRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
public List<Order> findOrdersByUserId(Long userId) {
String sql = "SELECT * FROM `order` WHERE user_id = ?";
return jdbcTemplate.query(sql, new Object[]{userId}, new BeanPropertyRowMapper<>(Order.class));
}
public void saveOrder(Order order) {
String sql = "INSERT INTO `order` (id, user_id, amount) VALUES (?, ?, ?)";
jdbcTemplate.update(sql, order.getId(), order.getUserId(), order.getAmount());
}
}
@Service
public class OrderService {
@Autowired
private OrderRepository orderRepository;
public List<Order> getOrdersByUserId(Long userId) {
return orderRepository.findOrdersByUserId(userId);
}
public void saveOrder(Order order) {
orderRepository.saveOrder(order);
}
}在上述示例中,我們配置了兩個數據源(ds0和ds1),每個數據源對應一個數據庫實例。訂單表根據用戶ID進行分表,共分為4張表(order_0、order_1、order_2、order_3),并根據用戶ID進行分庫,共分為2個數據庫實例。在業務代碼中,我們通過Sharding JDBC的API來進行數據庫操作,無需關心具體的數據庫切片和分布式表。
本文深入探索了Sharding JDBC的核心概念、工作原理和使用方法,并通過一個用戶訂單分庫分表的示例加以完善。通過使用Sharding JDBC,開發者可以輕松應對高并發和大數據量的場景,提升系統的性能和可擴展性。希望本文對讀者理解和應用Sharding JDBC有所幫助。
作者介紹
波哥,在互聯網行業從業10余年,先后擔任項目總監及架構師。目前專攻技術,喜歡研究技術原理。技術全面,主攻Java,精通JVM底層機制及Spring全家桶底層框架原理,熟練掌握當前主流的中間件、服務網格等技術原理。