













我們如何結合OpenTelemetry跟蹤和Prometheus指標構建強大的警報機制?
譯文譯者 | 布加迪
審校 | 重樓
工程團隊卓越的品質之一是另辟蹊徑,找到解決難題的創造性方法。作為開發領導者,我們有責任向下一代開發人員傳授技巧,幫助他們盡可能透過表面解決復雜的業務問題,并充分利用開源社區的力量。
在Helios,這種基因最近引導我們將復雜的邏輯委托給一個經過驗證的開源項目(Prometheus)。我們竭力為產品添加警報機制。現在,警報不是新鮮事——許多軟件產品提供警報向用戶通知系統/產品中的事件,但事實上,它不是新鮮事并不意味著就沒有挑戰性。我們利用Prometheus(具體地說是AWS托管Prometheus,我們選擇用它來減少內部管理的維護開銷)解決了這個挑戰——OpenTelemetry收集器度量管道已經在使用Prometheus,以構建警報機制,既滿足了用戶的產品需求,又節省了開發和維護它的大量時間和精力。
本文將介紹這一解決方案,并希望它能夠激勵開發者創造性地思考可能遇到的日常挑戰。希望我們的經驗展示了我們如何使用開源項目構建了一種大大提高了效率的解決方案,以便工程團隊可以花寶貴的時間去解決更多的業務挑戰。
構建警報機制:不需要重新發明輪子
OpenTelemetry(OTel)是一種開源可觀察性框架,可以幫助開發人員生成、收集和導出來自分布式應用程序中的遙測數據。我們用OTel收集的數據包括幾種不同的信號:分布式跟蹤數據(比如HTTP請求、DB調用以及發送到各種通信基礎設施的消息)以及指標(比如CPU使用情況、內存消耗和OOM事件等)。
我們開始基于這些數據以及來自其他來源的數據構建警報機制,使用戶能夠根據系統中的事件來配置條件。比如說,用戶可能會收到關于API失效、DB查詢所花時間比預期長或Lambda出現OOM的警報,他們就可以根據想要的精細度和想要的通知頻率來設置警報。
如前所述,許多軟件產品都需要提供警報機制,以便用戶能夠了解應用程序或其他重要業務KPI所發生的事件方面的最新情況。這是一項常見特性,但構建起來依然很復雜。
我們希望解決方案實現這三個目標:
1. 無縫地基于分布式跟蹤數據實施警報(不需要太費力!)
2. 使一切內容對OTel數據模型而言都是原生的
3. 快速進入市場
為此,我們轉向開源工具:我們利用了Prometheus的Alerts Manager模塊。Prometheus是用于監視和警報的開源行業標準,旨在跟蹤應用程序和基礎設施的性能和運行狀況。Prometheus從各種來源收集指標,并提供靈活的查詢語言以分析和可視化數據。它是收集OTel指標的最常見后端之一,我們的后端已經有了Prometheus來支持指標收集。
我們依靠像Prometheus這樣的開源工具為我們做這些工作,因為這類解決方案是由許多聰明而有經驗的開發人員構建的,他們有多年的豐富經驗,調整改動解決方案以支持許多用例,已碰到過該領域的所有或至少大部分陷阱。我們對警報機制的設計進行了內部討論,利用Prometheus的想法是由團隊的一些成員根據他們以前的經驗提出的。
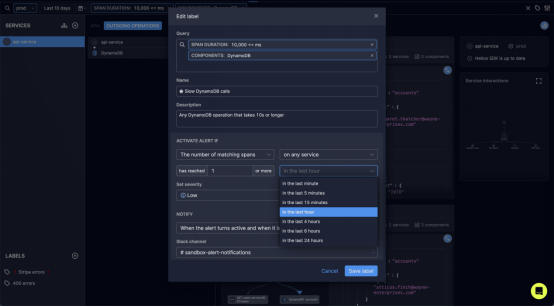
圖1. 設置基于分布式跟蹤數據的警報——由Prometheus Alert Manager提供支持;這個標簽可以在Helios Sandbox中訪問
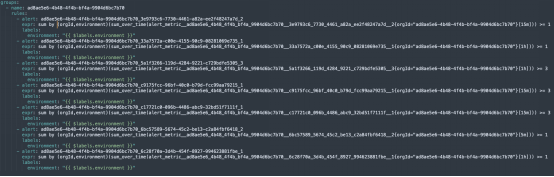
圖2. 這個例子表明了Prometheus中如何配置來自Helios Sandbox的不同警報
深入探討:我們如何構建警報機制?
有了Prometheus,我們開始著手添加警報機制。我們想從跟蹤警報入手,或者更準確地說從跟蹤的基本模塊:span入手(比如HTTP請求或DB查詢的結果)。Prometheus提供了指標警報,但我們需要跟蹤警報。來自跟蹤的數據不會按原樣抵達Prometheus——它需要轉換成數據模型。因此,為了讓Prometheus實際發出span警報,我們需要獲取span,將其轉換成指標,并配置由它觸發的警報。當跟蹤(span)匹配警報條件時(比如DB查詢耗時超過5秒),我們將span轉換成Prometheus指標。
Prometheus模型符合我們旨在實現的目標。針對每個事件,我們從OTel獲得原始數據,并通過Prometheus將其作為指標來饋送。然后我們可以說,如果某個特定的操作錯誤在五分鐘內出現超過三次,就應該激活警報。
我們沒有止步于此。在Helios中,對我們用戶來說一大好處是我們可以從分布式跟蹤數據到一個指標,也可以從一個指標返回到特定的跟蹤,因為我們維護指標上下文。用戶可以設置基于跟蹤的警報,然后從警報返回到E2E流,以便快速分析根本原因。這為用戶提供了終極可見性,以便深入了解應用程序的性能和運行狀況。可用的上下文(基于測量數據)可幫助用戶輕松確定應用程序流中的問題和瓶頸,以便快速排除故障,并縮短平均解決時間(MTTR)。
基于跟蹤的警報
在警報機制中,我們構建的機制旨在對可以根據跟蹤數據定義的行為發出警報,比如服務A向服務B發出的失敗的HTTP請求,MongoDB對特定集合的查詢超過500毫秒,或者Lambda函數調用失敗。
以上每一項都可以描述為基于標準OTel屬性(比如HTTP狀態碼、span持續時間等)的span過濾器。在這些過濾器之上,我們支持各種聚合邏輯(比如,如果匹配span的數量在Y時間內達到X)。因此,警報定義實際上是過濾器和聚合邏輯。
實施包括三個部分:
1. 為每個警報定義創建唯一的指標。
2. 將聚合邏輯轉換成PromQL查詢,并使用警報定義更新Prometheus Alert Manager。
3. 將匹配警報過濾器的span持續轉換成Prometheus時間序列,這將符合警報聚合定義,并觸發警報。
我們希望盡可能保持OTel原生,因此基于OTel收集器構建警報管道,具體做法如下:
1. 創建alert matcher collector,它使用kafka receiver來處理從“一線”收集器(接收來自客戶的OTel SDK的數據)發送的OTLP格式的span。
2. kafka receiver連接(作為跟蹤管道的一部分)到alert matcher processor,這是我們構建的自定義處理程序,它加載我們的客戶在Helios UI中配置的過濾器,并相應地過濾span。
3. 在過濾相關的span之后,我們需要將它們作為指標導出到Prometheus。為此,我們實施了連接器,這是一項比較新的OTel收集器特性,允許連接不同類型的管道(本例中是跟蹤和指標)。spans-to-metrics連接器將每個匹配的span轉換成指標,具有以下屬性:
- 它的名稱是根據數據庫中的客戶ID和警報定義ID構建的。
- 它的標簽是跟蹤ID、span ID、時間戳和服務名稱等。
4. 使用Prometheus遠程寫入導出器將指標導出到托管的AWS Prometheus。
Prometheus幾乎直接就能發揮功效,我們要注意幾個小細節,因為它是AWS管理的(比如只能使用SNS-SQS來報告警報)。
從警報到根本原因
我們已有了基于跟蹤的警報,但為了確保快速分析根本原因,我們還希望在觸發警報時提供完整的應用程序上下文。觸發警報后,我們向Prometheus查詢警報定義的時間序列(客戶和警報定義ID的組合),并獲得作為警報查詢實例的指標列表——每個指標都有匹配的span和跟蹤ID。比如說,如果警報針對長時間運行的DB查詢配置,示例跟蹤將含有查詢本身及整個跟蹤。
整個機制看起來是這樣的:
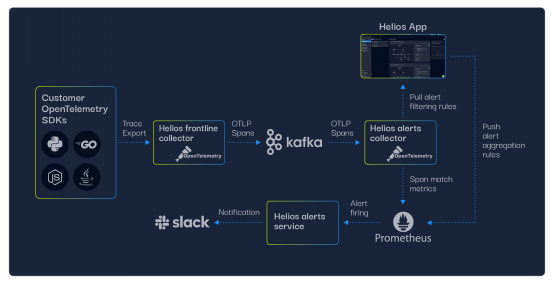
圖3. Helios的警報機制架構——從客戶的OpenTelemetry SDK報告的span到Slack中的警報
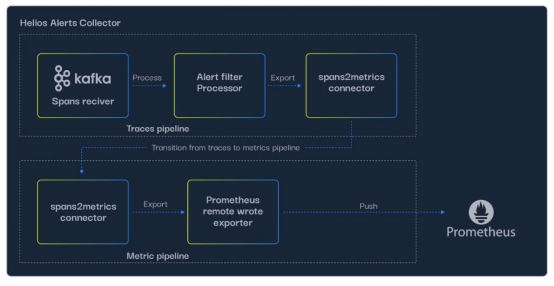
圖4. Helios Alerts Collector架構——從跟蹤管道到度量管道的轉換
使用Prometheus警報作為我們方法的利弊
我們用于警報機制的方法是將OTel跟蹤數據轉換成Prometheus指標,以便利用Prometheus的Alert Manager,因而不需要實施我們自己的警報后端。不妨看看這種方法的一些優缺點。
盡管優點多多,但有時使用開源工具或團隊無法控制的任何外部組件可能很棘手,因為您實際上得到的是“黑盒子”——如果其API和集成機制不適合您的架構,您可能需要做更多的工作,甚至完全受阻。
不妨看一個例子。在Prometheus中,可以通過使用API調用來更新YAML定義以配置警報。然而,我們使用的AWS Managed Prometheus支持使用AWS API調用來更新這些定義,并不直接更新Prometheus,而是在周期性同步中進行實際更新。為了防止這種行為方面的問題(比如由于第一次更新還沒有同步,持續更新警報定義失敗),我們必須實施自己的定期同步機制,以封裝更新。如果我們從頭開始構建這個解決方案,就可以全面控制這個機制,可以隨時進行更新。在這里,由于AWS Managed Prometheus,我們沒有這種控制,這迫使我們構建一個額外的同步機制。
此外,您可能希望調整解決方案的一些特性——比如在該例子中,我們希望在發送警報時提供精度更細的數據——這可能是個繁瑣的過程。比如在接收到警報(作為Prometheus報告的警報的有效負載的一部分)時為它們直接觸發的警報獲取匹配的span ID在默認情況下不適用于我們,因此我們必須向Prometheus發送另一個API調用并查詢它們,這增加了一些小小的開銷。
盡管存在這些挑戰,但我們知道在不依賴Prometheus的情況下自己實施這種功能要困難得多。我們有一個開箱即用的解決方案,節省了大量的開發時間,而不是從頭開始開發警報邏輯,不然這需要設計(不同的組件和存儲等)、實施,可能還需要幾次錯誤修復和反饋的迭代。
有了Prometheus這個功能豐富的成熟開源工具,我們就省心多了。我們知道未來的用例會得到這款工具的支持,它已準備好用于生產環境,許多用戶會對它進行微調,這給了我們很大的信心,同時節省了時間。我們知道,我們將來可能想到的任何警報邏輯都可能已經在Prometheus中實現了。如果我們自行構建,錯誤的設計選擇可能意味著我們不得不破壞設計或編寫糟糕的代碼來支持新用例。
此外,我們這種方法的好處之一是使所有內容對OTel數據模型而言都是原生的。這意味著OTel收集器將過濾、處理、導出和接收所有內容,至于它是span(比如失敗的HTTP請求)還是指標(比如高CPU使用率)都無關緊要。
結論
在Helios開發警報機制可能很困難,但借助一些創造性思維和開源協作,我們高效而從容地完成了這項任務。我們利用了OTel和Prometheus,在穩定的周轉時間內提供了復雜的警報機制。我們找到了一種關聯span和指標的方法,這樣當我們獲取span并將其轉換成指標時,就知道如何將警報重新與業務邏輯聯系起來。
但愿這段經歷不僅能激勵開發者利用開源解決復雜的問題,還能成為我們用戶的好伙伴。創新是關鍵,但除了為了創新而創新之外,我們還希望對用戶產生影響,改善他們的體驗,希望您也能這樣做。
原文標題:How we combined OpenTelemetry traces with Prometheus metrics to build a powerful alerting mechanism,作者:Ran Nozik





















