













CMU大牛全面總結「多模態機器學習」六大挑戰:36頁長文+120頁PPT,全干貨!
隨著各種語言、視覺、視頻、音頻等大模型的性能不斷提升,多模態機器學習也開始興起,通過整合多種模態的數據,研究人員們開始設計更復雜的計算機智能體,能夠更好地理解、推理和學習現實世界。
在發展過程中,多模態機器學習的研究也帶來了計算、理論上的挑戰,在融合多模態、智能體自主性,以及多傳感器融合等應用場景下,還存在異構數據源等新興的數據模式發現方法。

最近,來自卡內基梅隆大學的研究人員發表了一篇關于多模態機器學習的全面總結,并在ICML 2023會議上舉辦了Tutorial,通過對應用領域和理論框架進行綜述,對多模態機器學習的計算和理論基礎進行概述。

論文鏈接:https://arxiv.org/pdf/2209.03430.pdf
演示文稿:https://drive.google.com/file/d/1qIYBuYrSW2-e95DL7LndfLFqGkIWFG21
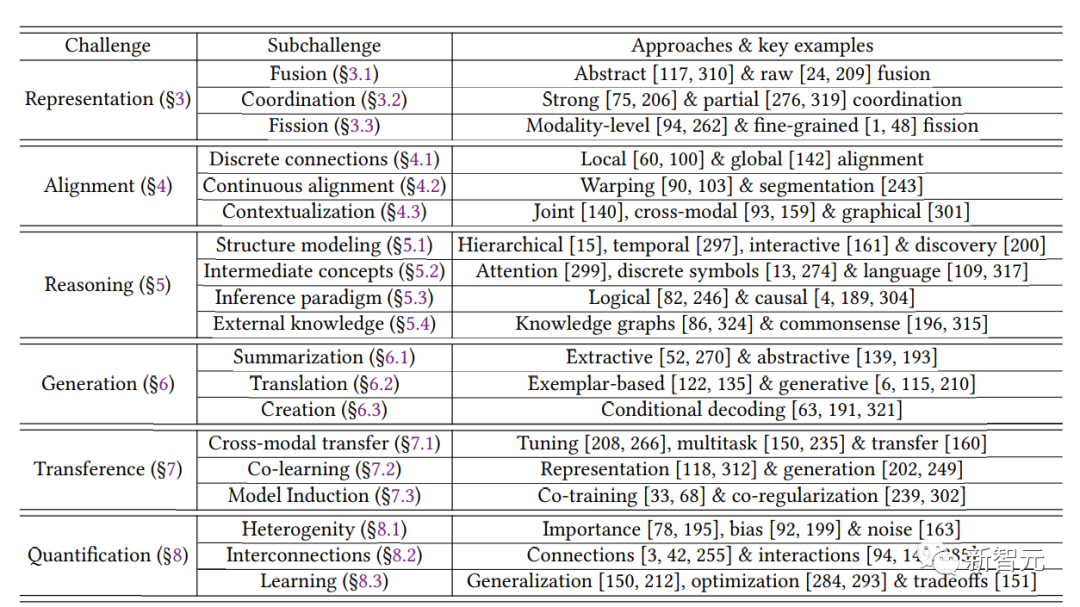
研究人員首先定義了驅動后續創新的模態異質性、連接和交互的三個關鍵原則,并提出了六個核心技術挑戰的分類:表征、對齊、推理、生成、遷移和量化,文中涵蓋多模態機器學習的研究歷史以及近期趨勢。

論文作者Paul Pu Liang是卡耐基梅隆大學機器學習系的博士生,導師為Louis-Philippe Morency和Ruslan Salakhutdinov,主要研究方向為多模態機器學習的基礎,及其在社交智能AI、自然語言處理、醫療保健和教育上的應用。
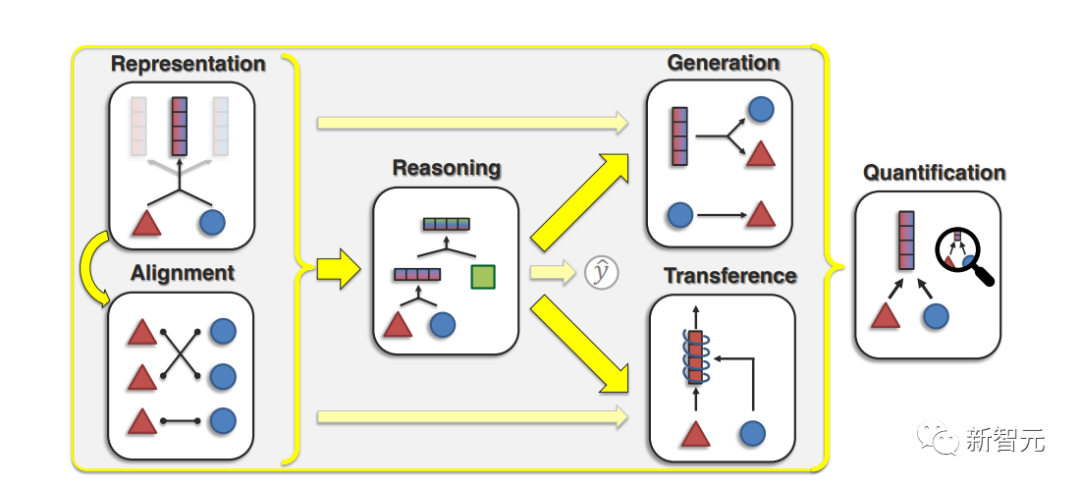
挑戰1:表征 Representation
如何學習能反映不同模態中單個元素之間跨模態交互的表征是一個問題,可以把這個挑戰視為學習元素之間的局部表征,或使用整體特征的表征。
論文中主要介紹了三個子問題:
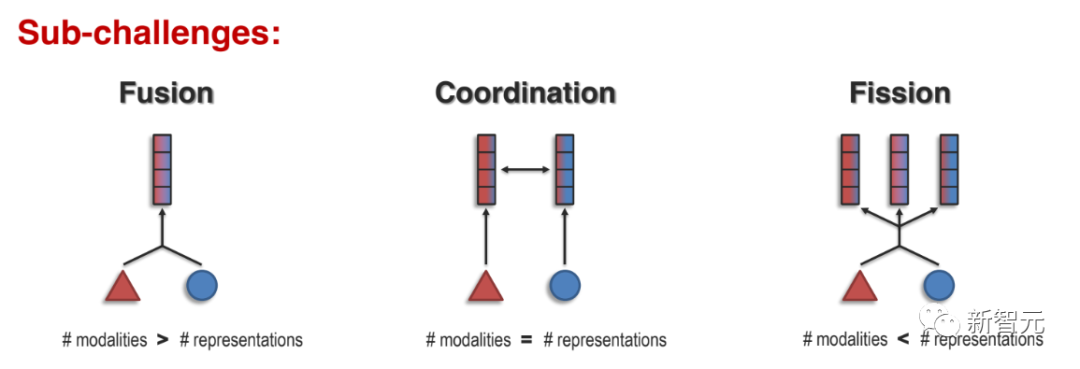
1. 表征融合(Representation Fusion)
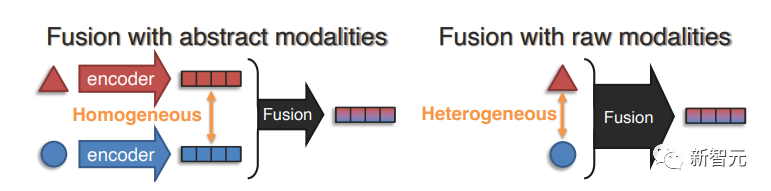
表征融合的目的是學習到一種聯合表征,可以模擬不同模態中各個元素之間的跨模態交互,從而有效減少獨立表征的數量。
研究人員將這些方法分為兩類:
(1)抽象模態融合,先應用合適的單模態編碼器來捕捉每個元素(或全部模態)的整體表征,然后使用表征融合的幾個構件來學習聯合表征,即融合發生在抽象表征層面。
(2)原始模態融合,在早期階段進行表征融合,只需要進行簡單的預處理,甚至可以直接輸入原始模態數據本身。
2. 表征協調(Representation Coordination)
其目的是學習多模態語境化表征,這些表征通過相互關聯而相互協調;與表征融合不同的是,協調保持了表征的數量不變,但改進了多模態語境化。
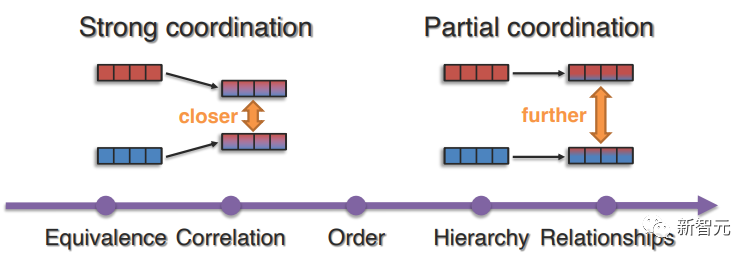
文中首先討論了強制模態元素之間強等價性的強協調,然后再討論部分協調,部分協調可以捕捉到更普遍的聯系,如相關性、順序、層次或超越相似性的關系。
3. 表征裂變(Representation Fission)
其目的是創建一套新的解耦表征(通常比輸入表征集的數量要多),以反映內部多模態結構的知識,如數據聚類、獨立的變化因素或特定模態信息。
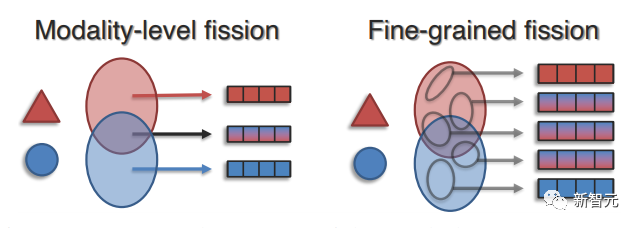
與聯合表征和協調表征相比,表征裂變可實現細致的解釋和細粒度的可控性,根據解耦因素的粒度,可將方法分為模態級裂變和細粒度裂變。
挑戰2:對齊(Alignment)
對齊的作用是識別多種模態元素之間的跨模態連接和互動,例如在分析人類主體的語音和手勢時,應該如何才能將特定手勢與口語單詞或語句對齊?
模態之間的對齊可能存在長距離的依賴關系,或是涉及模糊的分割(如單詞或語句),而且可能是一對一、多對多或根本不存在對齊關系,所以非常具有挑戰性。
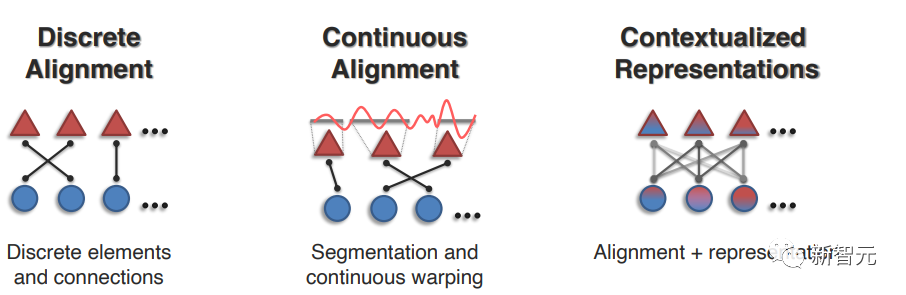
1. 離散對齊(Discrete Alignment)
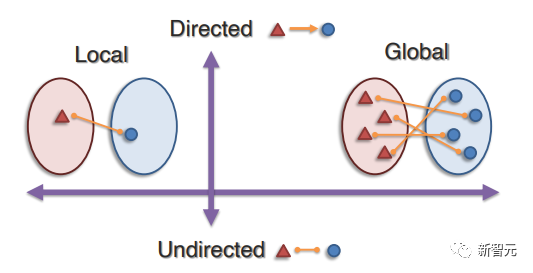
其目標為識別多種模態離散元素之間的聯系,最近的工作主要包括兩種方法:局部對齊發現給定匹配的一對模態元素之間的連接;全局對齊,必須在全局范圍內進行對齊,以學習連接和匹配。
2. 連續對齊(Continuous Alignment)
之前的方法基于一個重要假設,即模態元素已經被分割和離散化。
雖然某些模態存在清晰的分割(如句子中的單詞/短語或圖像中的對象區域),但在許多情況下,分割邊界并不容易找到,如連續信號(如金融或醫療時間序列)、時空數據或沒有清晰語義邊界的數據(如核磁共振圖像)。
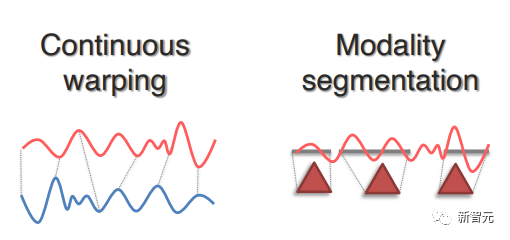
在最近的一些工作中提出了基于連續扭曲(Continuous warping)和以適當的粒度將連續信號分割為離散元素的模態分割(Modality segmentation)的方法。
3. 上下文表征(Contextualized Representations)
其目的是為所有模態連接和交互建模,以學習更好的表征,可以當作是中間步驟(潛在步驟),能夠在語音識別、機器翻譯、媒體描述和視覺問題解答等一系列下游任務中取得更好的性能。
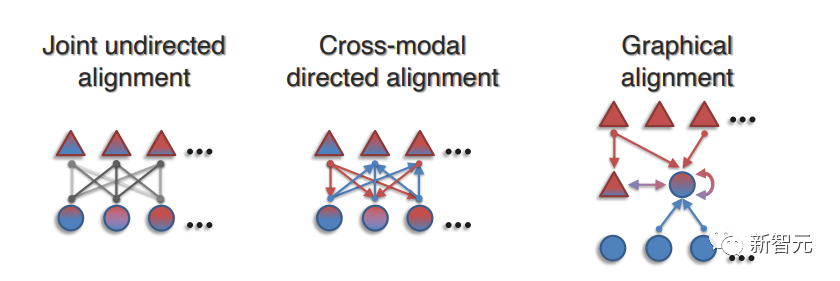
文中將上下文表征方面的工作分為:
(1)聯合無向對齊(Joint undirected alignment),可以捕捉跨模態對的無向連接,這些連接在任一方向上都是對稱的;
(2)跨模態有向對齊(Cross-modal directed alignment),以有向方式將源模態中的元素與目標模態聯系起來,可建立非對稱連接模型;
(3)圖網絡對齊(Graphical alignment),將無向或有向對齊中的順序模式推廣到元素之間的任意圖結構中。
挑戰3:推理
推理的定義為結合知識,通常通過多個推理步驟,利用多模態排列和問題結構。
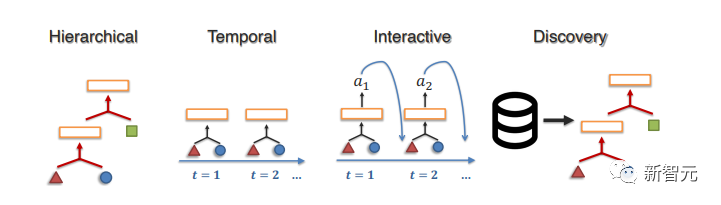
1. 結構建模(Structure Modeling)
這一步的目的在于捕捉組合的層次關系,通常是通過參數化原子、關系和推理過程的數據結構來實現。
常用的數據結構包括樹、圖或神經模塊,文中介紹了最近在潛在層次結構、時間結構和交互結構建模方面的工作,以及在潛在結構未知的情況下發現結構的工作。
2. 中間概念(Intermediate Concepts)
這個問題研究了如何在推理過程中對單個多模態概念進行參數化。
雖然在標準神經架構中,中間概念通常是密集的向量表征,但在可解釋的注意力圖(attention map)、離散符號和語言作為推理的中間媒介方面,也有大量相關工作。
3. 推理范式( Inference Paradigms)
這一部分主要解決如何從單個多模態證據中推斷出越來越抽象的概念。
雖然局部表征融合(如加法、乘法、基于張量、基于注意力和順序融合)方面的進展在此也普遍適用,但推理的目標是通過有關多模態問題的領域知識,在推理過程中提高可解釋性,文中主要舉例說明通過邏輯和因果運算符對推理過程進行顯式建模的最新方向。
4. 外部知識
從定義組成和結構的研究中推導知識,其中知識通常來自特定任務數據集上的領域知識。
作為使用領域知識預先定義組成結構的替代方法,近期的研究工作還探索了使用數據驅動方法自動推理的方法,例如在直接任務領域之外廣泛獲取但監督較弱的數據。
挑戰4:生成
模型需要學習生成過程,通過摘要、翻譯和創造,生成反映跨模態交互、結構和連貫性的原始模態,這三個類別沿用了文本生成的分類方法,根據從輸入模態到輸出模態的信息變化來進行區分。
1. 摘要(Summarization)
摘要的目的是壓縮數據,創建一個能代表原始內容中最重要或最相關信息的摘要,除了文本格式外,還包括圖像、視頻、音頻等模態的摘要。
雖然大多數方法只關注從多模態數據中生成文本摘要,但也有幾個方向探索了生成摘要圖像以補充生成的文本摘要。
2. 翻譯(Translation)
翻譯的目的是將一種模態映射到另一種模態,同時尊重語義聯系和信息內容,例如為圖像生成描述性標題有助于提高視覺內容對盲人的可及性。
多模態翻譯也帶來了新的難題,例如高維結構化數據的生成及其評估,主流方法可分為基于范例的方法和生成模型的方法,前者僅限于從訓練實例中檢索以在不同模態之間進行翻譯,但能保證翻譯的保真度;后者可翻譯成數據之外的任意插值實例,但在質量、多樣性和評估方面面臨挑戰。
盡管存在這些挑戰,最近在大規模翻譯模型方面取得的進展已經在文本到圖像、文本到視頻、音頻到圖像、文本到語音、語音到姿態、說話者到聽眾、語言到姿態以及語音和音樂生成等方面產生了令人印象深刻的高質量生成內容。
3. 創造(Creation)
創造的目的是從小規模的初始示例或潛在的條件變量生成新穎的高維數據(可涵蓋文本、圖像、音頻、視頻和其他模態),該條件解碼過程極具挑戰性,需要模型具有:
(1)有條件:保留從初始種子到一系列遠距離并行模態的語義映射;
(2)同步:跨模態的語義一致性;
(3)隨機:在特定狀態下捕捉許多可能的后代;
(4)在可能的遠距離范圍內自動回歸。
挑戰5:遷移(Transference)
其目的是在模態及其表征之間遷移知識,主要它探索從第二種模態中學到的知識(如預測標簽或表征)如何幫助在第一模態上訓練的模型?
當主模態的資源有限(如缺乏標注數據、輸入噪聲大或標簽不可靠)時,解決這一問題尤為重要,因為次模態信息的遷移會產生主模態從未見過的新行為。
1. 跨模態遷移(Cross-modal Transfer)
在大多數情況下,收集第二模態的標注或非標注數據并訓練強大的監督或預訓練模型可能更容易,然后可以針對涉及主模態的下游任務對這些模型進行調節或微調,從而將單模態遷移和微調擴展到了跨模態環境中。
2. 多模態協同學習(Multimodal Co-learning)
多模態協同學習旨在通過共享兩種模態之間的中間表征空間,將通過次模態學習到的信息遷移到包含主模態的目標任務中,這些方法的本質是在所有模態中建立一個單一的聯合模型。
3. 模型歸納(Model Induction)
與協同學習不同,模型歸納方法將主模態和次模態的單模態模型分開,但目的是歸納兩個模型的行為。
聯合訓練就是模型歸納的一個例子:在聯合訓練中,兩種學習算法分別在數據的每個視圖上進行訓練,然后使用每種算法的預測對未標記的新示例進行偽標記,以擴大另一個視圖的訓練集,也就是說,信息是通過模型預測而不是共享表示空間在多個視圖之間傳遞的。
挑戰6:量化
量化的目的是對多模態模型進行更深入的實證和理論研究,以獲得洞察力并提高其在實際應用中的穩健性、可解釋性和可靠性。
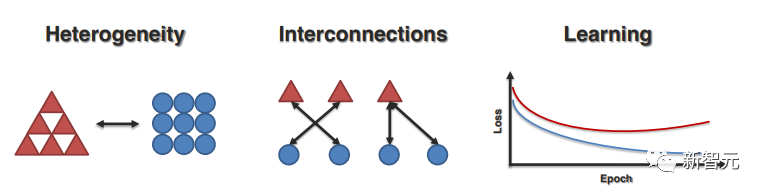
1. 異質性的維度(Dimensions of Heterogeneity)
這部分主要了解多模態研究中常見的異質性維度,以及后續如何影響建模和學習。
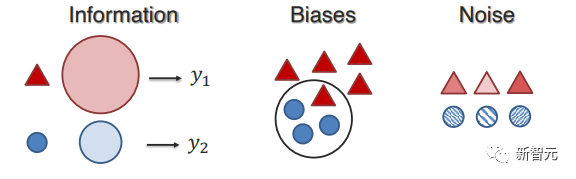
2. 模態互聯(Modality Interconnections)
模態之間的連接和交互是多模態模型的重要組成部分,激發了可視化和理解數據集和訓練模型中模態互連性質的相關工作。
研究人員將近期的工作分為以下兩個方面的量化:
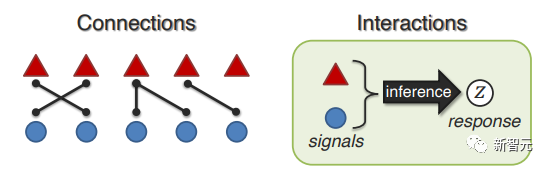
(1)連接:模態之間如何關聯并共享共性;
(2)交互:推理過程中模態元素如何交互。
3. 多模態學習過程(Multimodal Learning Process)
最后一個問題主要解決模型從異構數據中學習時所面臨的學習和優化挑戰,文中主要從三方面介紹了相關工作:
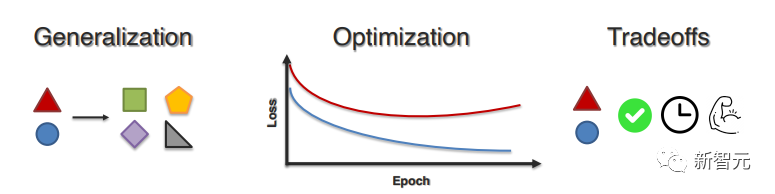
(1) 跨模態和跨任務的泛化;
(2) 更好地優化以實現均衡高效的訓練;
(3) 在實際部署中性能、魯棒性和復雜性之間的權衡。



















