針對Mapper文件的SQL優化

簡介
MyBatis是一款開源的持久層框架,它封裝了JDBC操作數據庫時的常用API,并提供了ORM映射的功能,使得開發者可以使用Java對象來操作數據庫。開發者可以通過XML配置或注解方式自定義SQL語句和參數映射規則,從而使得應用開發人員無需過多的了解數據庫,就可以開發出功能完善應用程序。
但是天下沒有免費的午餐,使用MyBatis也使得應用開發人員進行SQL調優變得困難。通過MyBatis開發的應用程序,傳統方式下需要通過模擬應用的接口調用、啟動數據庫的SQL日志、獲取應用的SQL查詢語句、對獲取的SQL進行優化,這讓整個SQL調優的流程復雜且費時。
PawSQL為了方便應用開發人員進行SQL性能調優,提供了基于Mybatis的mapper文件創建SQL優化任務的功能,讓應用開發人員在頁面上通過鼠標操作,完成其應用的SQL性能優化。
工作原理
Mapper文件
在 MyBatis 中,Mapper 文件是一種用于配置 SQL 語句和 SQL 操作的配置文件。
Mapper 文件通常包含四個主要部分:
- 命名空間,用于指定對應操作的實體類或其接口類的全路徑名。
- SQL語句片段,可以通過 select、insert、update、delete 等標簽來定義不同的 SQL 語句。
- 映射語句定義,可以通過映射語句來將操作的參數和返回值與上述 SQL 語句進行綁定的方式。
- 流程控制標簽,如<if>、where、foreach等標簽,根據不同的條件動態生成SQL語句,以便滿足不同的需求。
通過使用 Mapper 文件,應用開發人員可以實現簡便、靈活的 SQL 操作,同時也能更好地維護 SQL 與 Java 代碼之間的解耦。
Mapper文件=>SQL語句
為了對Mapper中的SQL進行優化,我們需要對Mapper文件進行解析,排列組合所有可能的合法SQL語句,并對其中的變量進行替換,以便生成合法的SQL語句,并進行優化。
- SQL片段排列組合
譬如對于以下的mapper文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.example.mapper.CustInfoMapper">
<select id="custInfoList">
select * from customer
<where>
<if test="nationkey != null and nationkey != ''">
and c_nationkey = #{nationkey}
</if>
<choose>
<when test="C_MKTSEGMENT != null and C_MKTSEGMENT != ''">
and c_mktsegment = #{C_MKTSEGMENT}
</when>
<otherwise>
and c_phone LIKE '139%'
</otherwise>
</choose>
</where>
</select>
</mapper>由于<if>標簽里的片段滿足條件才出現,所以c_nationkey = ? 可出現可不出現;而<choose>標簽里的內容必須且只能出現其中一個,所以其排列組合只可能出現下面的四種情況。
select * as cnt from customer where c_phone like '139%';
select * as cnt from customer where c_nationkey = #{nationkey} and c_phone like '139%';
select * as cnt from customer where c_mktsegment = #{C_MKTSEGMENT};
select * as cnt from customer where c_nationkey = #{nationkey} and c_mktsegment = #{C_MKTSEGMENT};通過排列組合方式產生的SQL,有可能會有一些SQL永遠不會在真實的生產環境中出現。但這些SQL可能會對SQL優化的過程產生影響,譬如推薦了一些無用的索引,或是索引中出現了一些不會被使用的列。所以用戶需要根據自己具體的業務場景,在PawSQL的SQL篩選預覽頁面,排除掉那些不會真實出現的SQL組合。
- 變量替換
對于mapper文件中的變量,我們會根據它所在的上下文,推測其數據類型,并根據數據庫的統計信息(如有)選擇一個合適常量來進行替換。譬如對于以上的四個SQL,我們會將#{nationkey}替換為整型常量,而將#{C_MKTSEGMENT}替換為字符串常量,所以最終提交到PawSQL優化引擎的是這樣的SQL。
select * as cnt from customer_n where c_phone like '139%';
select * as cnt from customer_n where c_nationkey = 128 and c_phone like '139%';
select * as cnt from customer_n where c_mktsegment = 'A234913';
select * as cnt from customer_n where c_nationkey = 16 and c_mktsegment = 'B123498';上手指南 - Mapper文件錄入SQL
我們知道,使用PawSQL進行SQL優化分為三步:
第一步定義工作空間,
第二步錄入待優化SQL,使用Mapper文件進行SQL優化發生在此步中。
第三步配置優化選項、進行優化。
PawSQL目前支持六種SQL錄入方式,包括本文介紹的Mapper文件。
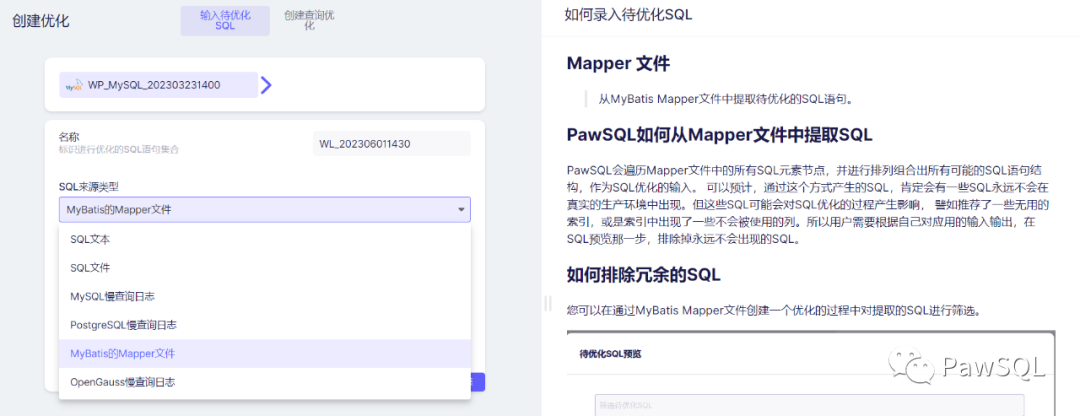
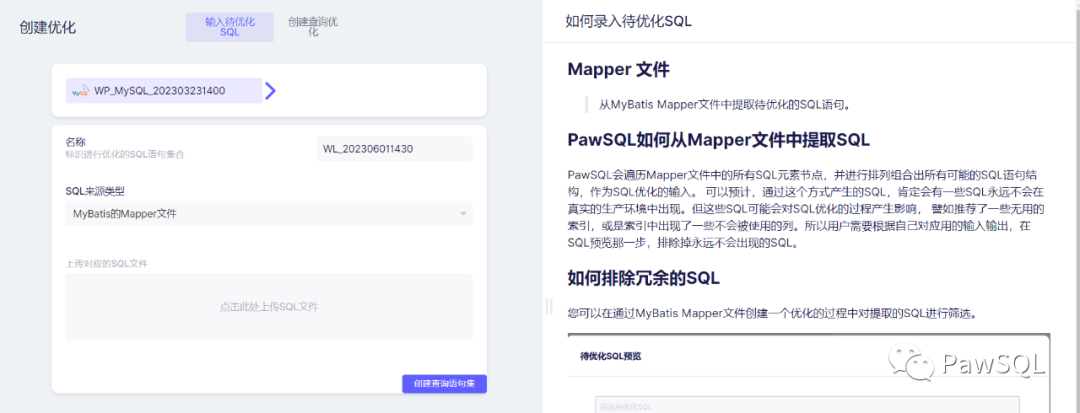
- 這里我們選擇Mapper文件的錄入方式, 點擊上傳按鈕上傳對應的Mapper.xml文件。
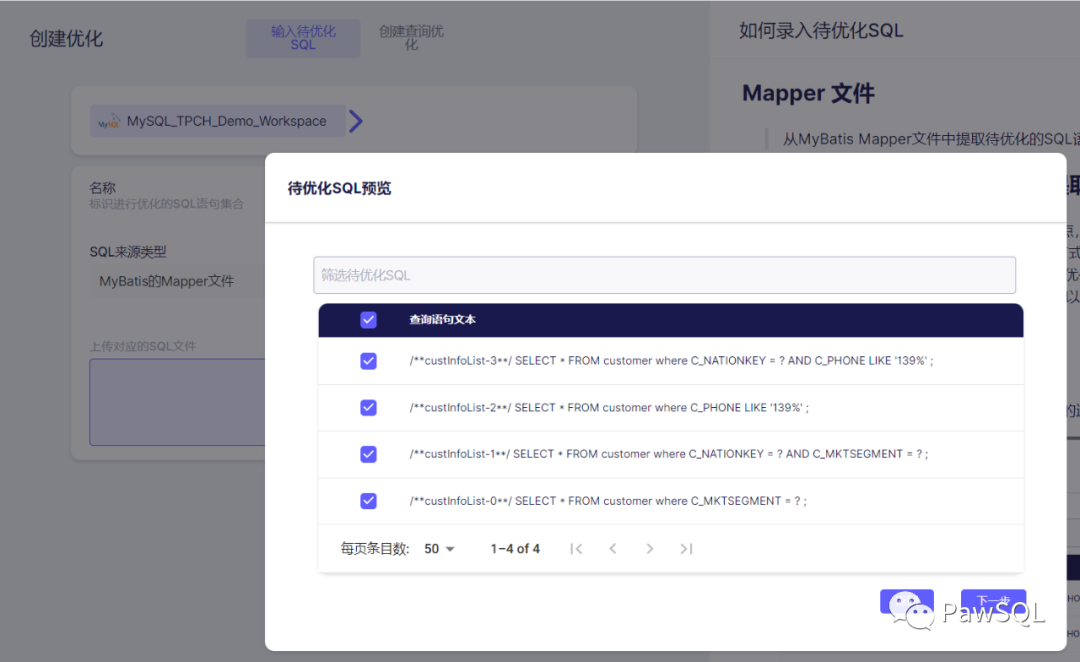
- 點擊創建查詢語句集按鈕來到'待優化SQL預覽'頁面,在此頁面中,您需要排查一些永遠都不會出現的SQL組合,以避免生成無效的優化建議。
- 后續的步驟是一致的,點擊下一步,完成SQL優化任務的執行。
以上就是使用Mapper文件創建PawSQL優化的全部內容了, 到這里創建自己的賬號快去試試吧!
關于PawSQL
PawSQL專注數據庫性能優化的自動化和智能化,支持MySQL,PostgreSQL,Opengauss等,提供的SQL優化產品包括
- PawSQL Cloud,在線自動化SQL優化工具,支持SQL審查,智能查詢重寫、基于代價的索引推薦,適用于數據庫管理員及數據應用開發人員,
- PawSQL Advisor,IntelliJ 插件, 適用于數據應用開發人員,可以IDEA/DataGrip應用市場通過名稱搜索“PawSQL Advisor”安裝。
- PawSQL Engine, 是PawSQL系列產品的后端優化引擎,可以獨立安裝部署,并通過http/json的接口提供SQL優化服務。PawSQL Engine以docker鏡像的方式提供部署安裝。