













離譜!面試為啥都問(wèn)Redis緩存?趕緊補(bǔ)一下

大家好,我是哪吒。
我第一次接觸緩存的時(shí)候,是用map做的,當(dāng)時(shí)做一個(gè)實(shí)時(shí)數(shù)據(jù)同步的功能。
需求看似簡(jiǎn)單,一取一傳
- 當(dāng)時(shí)是通過(guò)websocket獲取服務(wù)端數(shù)據(jù)。
- 然后根據(jù)數(shù)據(jù)類別,將數(shù)據(jù)緩存到本地map中。
- 做了一個(gè)定時(shí)任務(wù),通過(guò)ftp上傳給第三方服務(wù)器。
當(dāng)有并發(fā)時(shí),map是不行的,數(shù)據(jù)會(huì)錯(cuò)亂,使用ConcurrentHashMap可以解決并發(fā)數(shù)據(jù)錯(cuò)亂問(wèn)題。
- 現(xiàn)場(chǎng)網(wǎng)絡(luò)很不穩(wěn)定,F(xiàn)TP時(shí)好時(shí)壞。
- 做的是一個(gè)安全問(wèn)題的實(shí)時(shí)監(jiān)控系統(tǒng),第三方數(shù)據(jù)要求還很嚴(yán)格,必須100%準(zhǔn)確。
這矛盾怎么解決,無(wú)解了。
起初,是通過(guò)重啟的方式解決的,哈哈,重啟解決一切煩惱。
- 添加一個(gè)心跳功能,實(shí)時(shí)監(jiān)控FTP服務(wù)的狀態(tài)。
- 如果斷了7秒以上,就采取報(bào)警功能,我記得設(shè)置的是火警的音樂(lè),提示現(xiàn)場(chǎng)人員排查FTP網(wǎng)絡(luò)。
- 如果斷了1分鐘以上,就將軟件自動(dòng)重啟。
但是,又出現(xiàn)了一個(gè)新的問(wèn)題,數(shù)據(jù)丟了。
因?yàn)橛玫氖荂oncurrentHashMap緩存數(shù)據(jù),也就是本地緩存,你重啟了,數(shù)據(jù)不就沒(méi)了嗎?兄弟。
到后來(lái),才發(fā)現(xiàn),當(dāng)時(shí)做的真的是稀爛,本地緩存應(yīng)該具有很多功能,當(dāng)時(shí)這些,壓根就沒(méi)有。
- 超過(guò)最大限制有對(duì)應(yīng)淘汰策略如LRU、LFU。
- 過(guò)期時(shí)間淘汰如定時(shí)、懶式、定期。
- 持久化。
- 統(tǒng)計(jì)監(jiān)控。
下面從緩存、本地緩存、Redis緩存、Redis緩存策略幾個(gè)維度,全方位、系統(tǒng)的學(xué)習(xí)一下緩存到底是個(gè)啥?
一、緩存
緩存就是把訪問(wèn)量較高的熱點(diǎn)數(shù)據(jù)從傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)中加載到內(nèi)存中,當(dāng)用戶再次訪問(wèn)熱點(diǎn)數(shù)據(jù)時(shí),是從內(nèi)存中加載,減少了對(duì)數(shù)據(jù)庫(kù)的訪問(wèn)量,解決了高并發(fā)場(chǎng)景下容易造成數(shù)據(jù)庫(kù)宕機(jī)的問(wèn)題。
緩存有哪些分類:
- 操作系統(tǒng)磁盤(pán)緩存,減少磁盤(pán)機(jī)械操作。
- 數(shù)據(jù)庫(kù)緩存,減少文件系統(tǒng) I/O。
- 應(yīng)用程序緩存,減少對(duì)數(shù)據(jù)庫(kù)的查詢。
- Web 服務(wù)器緩存,減少應(yīng)用程序服務(wù)器請(qǐng)求。
- 客戶端瀏覽器緩存,減少對(duì)網(wǎng)站的訪問(wèn)。
本地緩存:在客戶端本地的物理內(nèi)存中劃出一部分空間,來(lái)緩存客戶端回寫(xiě)到服務(wù)器的數(shù)據(jù)。當(dāng)本地回寫(xiě)緩存達(dá)到緩存閾值時(shí),將數(shù)據(jù)寫(xiě)入到服務(wù)器中。
二、分析一下本地緩存的優(yōu)勢(shì)
數(shù)據(jù)緩存帶來(lái)了諸多優(yōu)勢(shì),其中兩個(gè)核心優(yōu)點(diǎn)是:
- 降低數(shù)據(jù)庫(kù)壓力:通過(guò)將常用的數(shù)據(jù)存儲(chǔ)在快速訪問(wèn)的內(nèi)存中,緩存有效地減輕了對(duì)后端數(shù)據(jù)庫(kù)的壓力。這意味著數(shù)據(jù)庫(kù)可以更專注地處理復(fù)雜的查詢和更新操作,而不必頻繁地處理重復(fù)的讀取請(qǐng)求。
- 提高響應(yīng)速度:將數(shù)據(jù)存儲(chǔ)在緩存中,使得系統(tǒng)能夠更迅速地響應(yīng)用戶的請(qǐng)求。相比每次都從數(shù)據(jù)庫(kù)中獲取數(shù)據(jù),緩存可以在毫秒級(jí)別內(nèi)提供所需信息,從而極大地改善用戶體驗(yàn)。

三、本地緩存解決方案?
上面介紹了ConcurrentHashMap,這里不再贅述。
1、基于Guava Cache實(shí)現(xiàn)本地緩存
Guava是Google團(tuán)隊(duì)開(kāi)源的一款 Java 核心增強(qiáng)庫(kù),包含集合、并發(fā)、緩存、IO、反射等工具箱性能和穩(wěn)定性上都有保障應(yīng)用十分廣泛。
Guava Cache支持很多特性:
- 支持最大容量限制。
- 支持兩種過(guò)期刪除策略插入時(shí)間和訪問(wèn)時(shí)間。
- 支持簡(jiǎn)單的統(tǒng)計(jì)功能。
- 基于LRU算法實(shí)現(xiàn)。
2、基于Caffeine實(shí)現(xiàn)本地緩存
Caffeine是基于java8實(shí)現(xiàn)的新一代緩存工具,緩存性能接近理論最優(yōu),可以看作是Guava Cache的增強(qiáng)版,功能上兩者類似。
不同的是Caffeine采用了一種結(jié)合LRU、LFU優(yōu)點(diǎn)的算法W-TinyLFU在性能上有明顯的優(yōu)越性。
3、基于Encache實(shí)現(xiàn)本地緩存
Encache是一個(gè)純Java的進(jìn)程內(nèi)緩存框架具有快速、精干等特點(diǎn)。
同Caffeine和Guava Cache相比,Encache的功能更加豐富擴(kuò)展性更強(qiáng)。
優(yōu)點(diǎn):
- 支持多種緩存淘汰算法包括LRU、LFU和FIFO。
- 緩存支持堆內(nèi)存儲(chǔ)、堆外存儲(chǔ)、磁盤(pán)存儲(chǔ)支持持久化三種。
- 支持多種集群方案解決數(shù)據(jù)共享問(wèn)題。
四、引入Redis
后來(lái),因?yàn)橐淮问鹿剩追奖槐O(jiān)管平臺(tái)罰了100萬(wàn),本質(zhì)原因就是丟數(shù)據(jù)問(wèn)題。
這可如何是好,我也是嚇了一身冷汗,連夜想整改方案,最終的解決方案是,“引入Redis”。
Redis作為一款高性能、內(nèi)存存儲(chǔ)的緩存數(shù)據(jù)庫(kù),被廣泛應(yīng)用于緩存數(shù)據(jù)的場(chǎng)景。
- 用戶第一次訪問(wèn)數(shù)據(jù)時(shí),緩存中沒(méi)有數(shù)據(jù),要從數(shù)據(jù)庫(kù)中獲取數(shù)據(jù),因?yàn)槭菑拇疟P(pán)中拿數(shù)據(jù)讀取數(shù)據(jù)的過(guò)程比較慢。
- 拿到數(shù)據(jù)后,將數(shù)據(jù)存儲(chǔ)在緩存中。
- 用戶第二次訪問(wèn)數(shù)據(jù)時(shí),可以從緩存中直接獲取,因?yàn)榫彺媸侵苯硬僮鲀?nèi)存的,訪問(wèn)數(shù)據(jù)速度比較快。
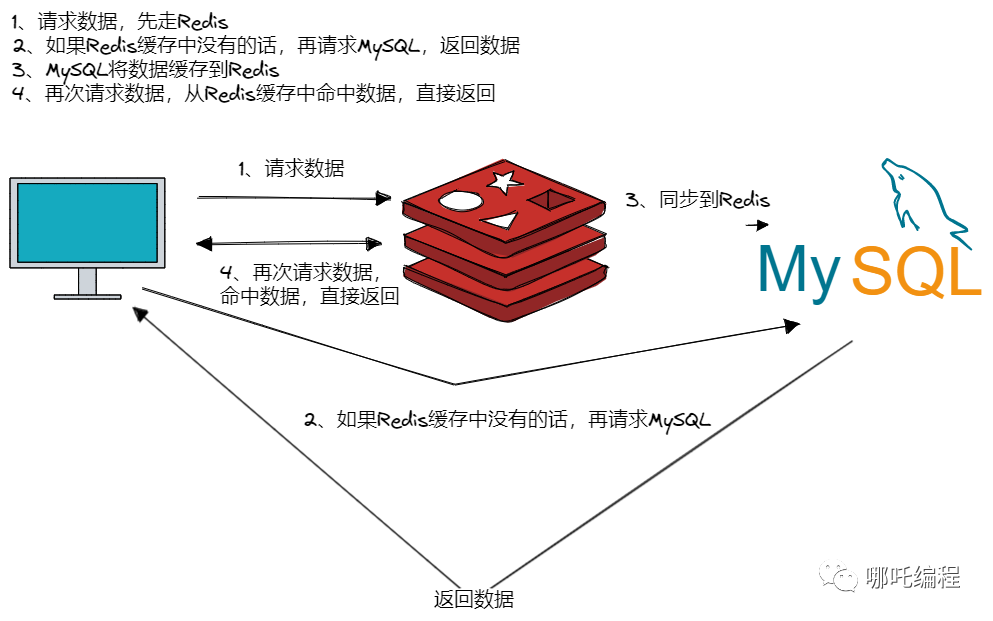
下面將深入探討Redis的數(shù)據(jù)緩存策略,重點(diǎn)解析LRU(最近最少使用)、LFU(最不經(jīng)常使用)等算法,并分享如何通過(guò)性能優(yōu)化來(lái)提升緩存系統(tǒng)的效率。
五、Redis數(shù)據(jù)緩存策略
1、為什么需要數(shù)據(jù)緩存策略
在現(xiàn)代應(yīng)用中,數(shù)據(jù)緩存發(fā)揮著至關(guān)重要的作用。
通過(guò)將頻繁訪問(wèn)的數(shù)據(jù)存儲(chǔ)在內(nèi)存中,我們能夠避免不必要的數(shù)據(jù)庫(kù)查詢,從而顯著提升系統(tǒng)的響應(yīng)速度和吞吐量。
然而,隨著應(yīng)用規(guī)模和用戶訪問(wèn)量的不斷增加,有效的數(shù)據(jù)緩存策略變得尤為重要。
我們需要在性能和資源利用之間找到最佳平衡,以應(yīng)對(duì)不同需求和挑戰(zhàn)。
這進(jìn)一步引出了一個(gè)關(guān)鍵問(wèn)題:如何選擇適合的數(shù)據(jù)緩存策略來(lái)滿足不同的應(yīng)用場(chǎng)景?
下圖詳細(xì)地說(shuō)明了數(shù)據(jù)緩存的優(yōu)勢(shì)和選擇適合的數(shù)據(jù)緩存策略的過(guò)程:
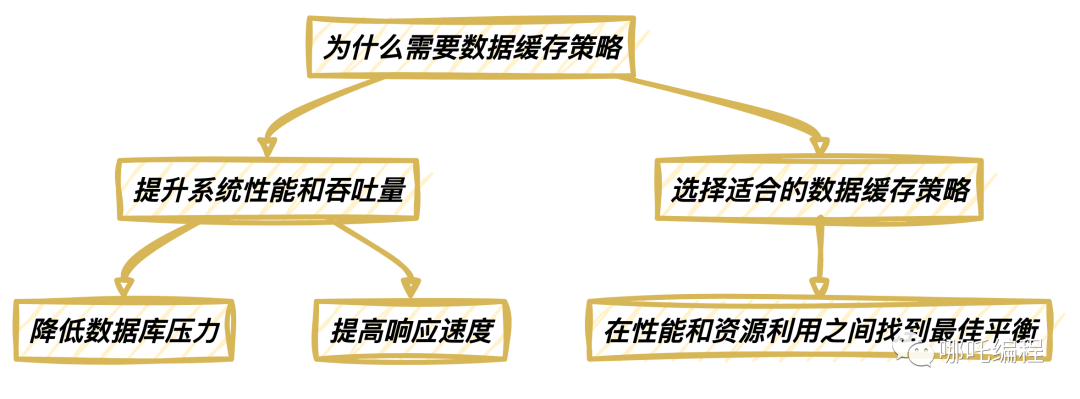
通過(guò)上圖,我們深入探討了數(shù)據(jù)緩存的優(yōu)勢(shì),并展示了在選擇合適的緩存策略時(shí),我們?nèi)绾卧谔嵘阅芎唾Y源利用之間找到最佳平衡。
選擇適合的策略能夠有效地降低數(shù)據(jù)庫(kù)壓力,并通過(guò)提高響應(yīng)速度來(lái)提供更出色的用戶體驗(yàn)。
2、Redis作為緩存的優(yōu)勢(shì)
Redis(Remote Dictionary Server)是一款強(qiáng)大的高性能開(kāi)源內(nèi)存數(shù)據(jù)庫(kù),不僅被廣泛應(yīng)用于緩存場(chǎng)景,還可用作隊(duì)列、發(fā)布訂閱系統(tǒng)等。作為緩存數(shù)據(jù)庫(kù),Redis擁有一系列突出的優(yōu)勢(shì):
(1)高性能特點(diǎn)
Redis的數(shù)據(jù)存儲(chǔ)在內(nèi)存中,因此具備出色的讀寫(xiě)性能。其高效的數(shù)據(jù)結(jié)構(gòu)和優(yōu)化的算法使得絕大多數(shù)情況下,讀寫(xiě)操作能夠在微秒級(jí)別內(nèi)完成,滿足了高并發(fā)應(yīng)用的需求。
(2)多樣性的緩存策略
Redis提供了多種數(shù)據(jù)緩存策略,使開(kāi)發(fā)者可以根據(jù)業(yè)務(wù)特點(diǎn)選擇合適的策略。這種靈活性允許我們根據(jù)數(shù)據(jù)的訪問(wèn)模式、使用頻率以及其他因素來(lái)決定數(shù)據(jù)何時(shí)被清理或保留。
下圖說(shuō)明緩存策略的選擇過(guò)程:
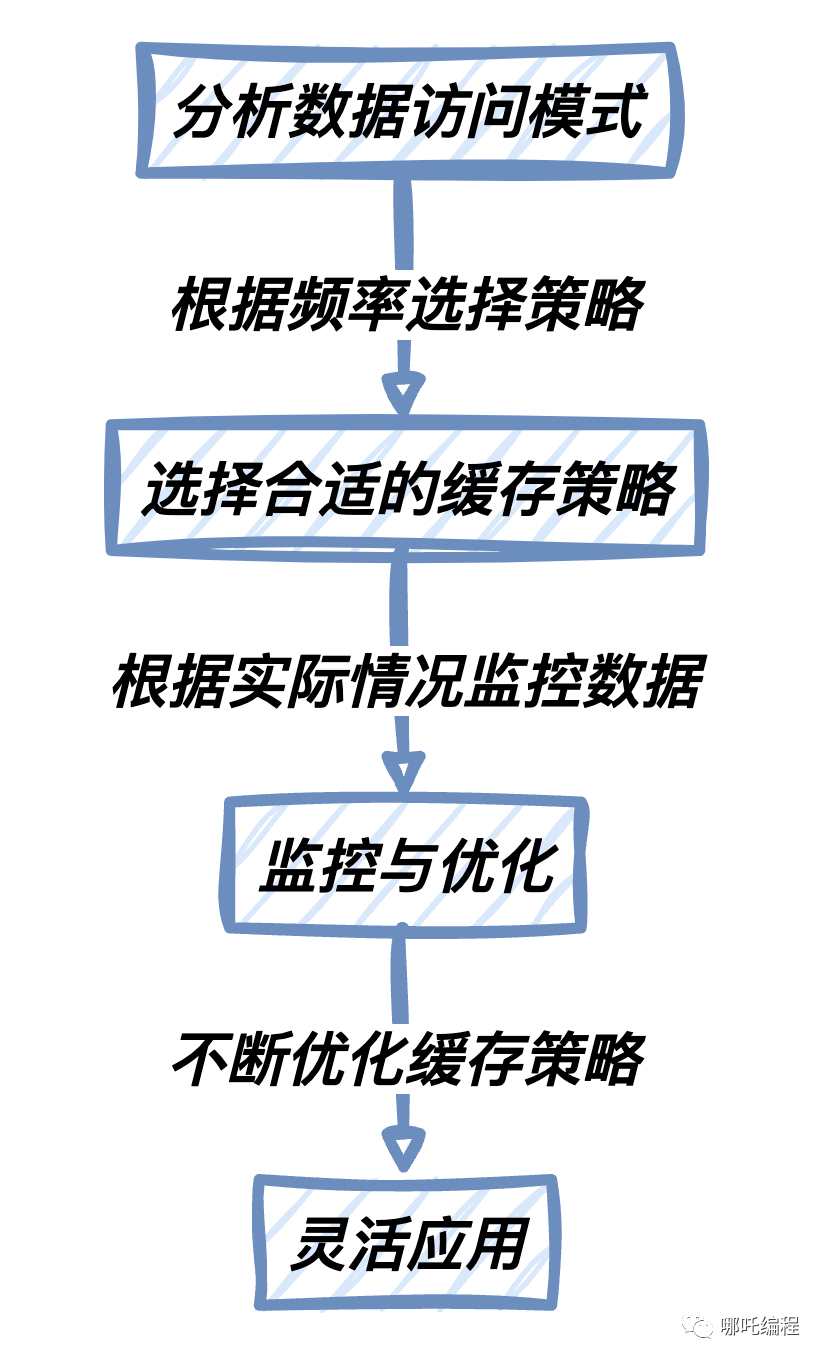
通過(guò)分析數(shù)據(jù)訪問(wèn)模式,根據(jù)數(shù)據(jù)的訪問(wèn)頻率選擇合適的緩存策略。根據(jù)實(shí)際情況不斷地監(jiān)控?cái)?shù)據(jù)的訪問(wèn)情況,并優(yōu)化緩存策略,在不同的場(chǎng)景中靈活應(yīng)用這些策略。
六、LRU算法:最近最少使用
LRU(Least Recently Used)算法是一種經(jīng)典的緩存替換策略,它的核心思想是優(yōu)先淘汰最近最少使用的數(shù)據(jù),以便為新數(shù)據(jù)騰出空間。在數(shù)據(jù)緩存場(chǎng)景中,LRU算法能夠保留熱門(mén)數(shù)據(jù),從而提高緩存的命中率。
1、LRU算法原理解析
LRU算法的原理非常直觀:當(dāng)緩存空間滿了,系統(tǒng)會(huì)優(yōu)先淘汰最久未被訪問(wèn)的數(shù)據(jù)。這個(gè)策略的背后思想是,如果某個(gè)數(shù)據(jù)在最近一段時(shí)間內(nèi)沒(méi)有被訪問(wèn),那么它在未來(lái)也可能不會(huì)被訪問(wèn)。這種替換策略有助于保持緩存中的數(shù)據(jù)是熱數(shù)據(jù),即最近被頻繁訪問(wèn)的數(shù)據(jù)。
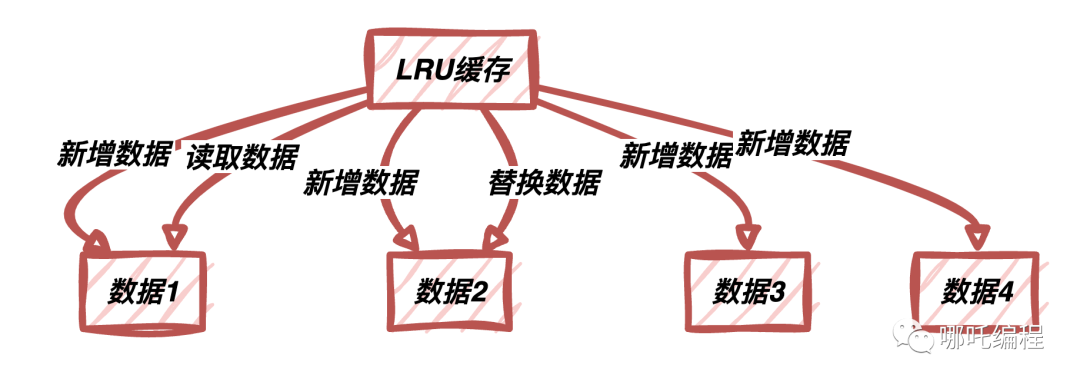
上圖說(shuō)明了LRU算法如何根據(jù)訪問(wèn)順序來(lái)保留緩存中的數(shù)據(jù)。最近訪問(wèn)的數(shù)據(jù)會(huì)被保留在緩存中,而最早訪問(wèn)的數(shù)據(jù)會(huì)被優(yōu)先替換。
示例代碼如下,展示了如何通過(guò)繼承LinkedHashMap來(lái)實(shí)現(xiàn)LRU緩存:
import java.util.LinkedHashMap;
import java.util.Map;
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int MAX_CAPACITY;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
MAX_CAPACITY = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > MAX_CAPACITY;
}
}在這個(gè)示例中,我們創(chuàng)建了一個(gè)LRUCache類,繼承自LinkedHashMap。通過(guò)重寫(xiě)removeEldestEntry方法,我們指定了當(dāng)緩存大小超過(guò)一定閾值時(shí),自動(dòng)刪除最久未被訪問(wèn)的數(shù)據(jù)。
2、redis中應(yīng)用LRU算法
在Redis中,我們可以通過(guò)配置maxmemory-policy選項(xiàng)來(lái)啟用LRU算法的緩存策略。當(dāng)Redis的內(nèi)存使用達(dá)到限制時(shí),LRU算法將被用于淘汰部分?jǐn)?shù)據(jù),以便騰出空間給新數(shù)據(jù)。
以下是如何在Redis中啟用LRU緩存策略的示例:
# 啟用LRU緩存策略
CONFIG SET maxmemory-policy allkeys-lru3、LRU算法的優(yōu)點(diǎn)與限制
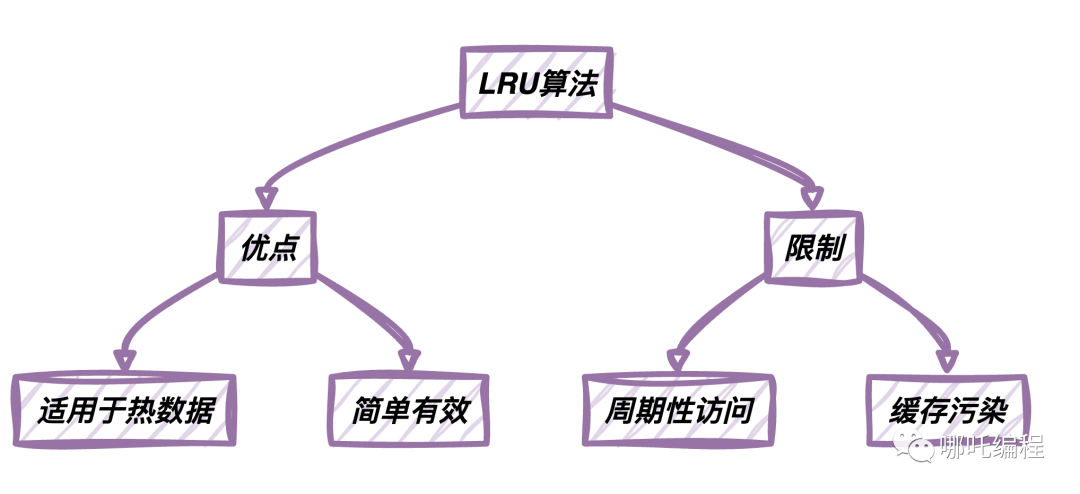
LRU(Least Recently Used)算法是一種常用的數(shù)據(jù)緩存策略,它在管理緩存數(shù)據(jù)時(shí)有一些明顯的優(yōu)點(diǎn)和一些限制。
優(yōu)點(diǎn)
優(yōu)點(diǎn) | 描述 |
適用于熱數(shù)據(jù) | LRU算法保留了最近最常訪問(wèn)的數(shù)據(jù),因此非常適用于具有明顯訪問(wèn)熱點(diǎn)的場(chǎng)景。 |
簡(jiǎn)單有效 | LRU算法的實(shí)現(xiàn)相對(duì)簡(jiǎn)單,不需要復(fù)雜的計(jì)算和維護(hù)。 |
限制
限制 | 描述 |
周期性訪問(wèn) | LRU算法可能會(huì)因?yàn)閿?shù)據(jù)的周期性訪問(wèn)而導(dǎo)致不必要的數(shù)據(jù)替換,特別是在某些特殊業(yè)務(wù)場(chǎng)景中。 |
緩存污染 | LRU算法容易受到突發(fā)的大量訪問(wèn)影響,可能導(dǎo)致緩存中的“熱·數(shù)據(jù)被淘汰,從而影響緩存效果。 |
七、LFU算法:最不經(jīng)常使用
LFU(Least Frequently Used)算法是一種與LRU相似的緩存替換策略,它的核心思想是優(yōu)先淘汰最不經(jīng)常使用的數(shù)據(jù),以便為新數(shù)據(jù)騰出空間。在某些特定場(chǎng)景下,LFU算法能夠更好地適應(yīng)數(shù)據(jù)訪問(wèn)模式的變化。
1、LFU算法原理解析
LFU算法的原理與LRU算法類似,但不同之處在于LFU算法基于數(shù)據(jù)被訪問(wèn)的頻率來(lái)做出替換決策,而不僅僅是訪問(wèn)的時(shí)間順序。LFU算法維護(hù)了一個(gè)數(shù)據(jù)訪問(wèn)頻率的記錄,當(dāng)需要淘汰數(shù)據(jù)時(shí),會(huì)優(yōu)先選擇訪問(wèn)頻率最低的數(shù)據(jù)。
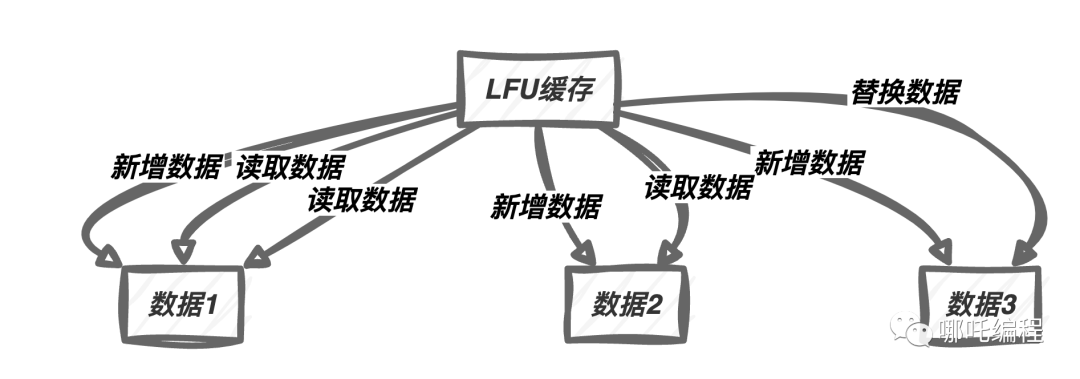
上圖說(shuō)明了LFU算法如何根據(jù)數(shù)據(jù)的訪問(wèn)頻率來(lái)保留緩存中的數(shù)據(jù)。頻繁訪問(wèn)的數(shù)據(jù)會(huì)被保留,而不經(jīng)常訪問(wèn)的數(shù)據(jù)會(huì)被優(yōu)先替換。
2、在Redis中應(yīng)用LFU算法
在Redis中,您可以通過(guò)配置maxmemory-policy選項(xiàng)來(lái)啟用LFU算法的緩存策略。當(dāng)Redis的內(nèi)存使用達(dá)到限制時(shí),LFU算法將用于淘汰部分?jǐn)?shù)據(jù),以便為新數(shù)據(jù)騰出空間。
以下是如何在Redis中啟用LFU緩存策略的示例:
# 啟用LFU緩存策略
CONFIG SET maxmemory-policy allkeys-lfu3、LFU算法的優(yōu)點(diǎn)與限制
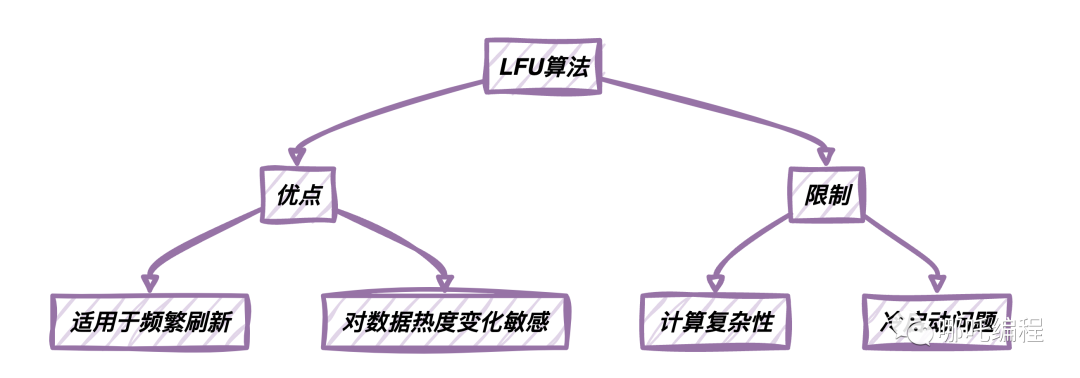
LFU(Least Frequently Used)算法是一種另類的數(shù)據(jù)緩存策略,它在不同的場(chǎng)景下具有一些明顯的優(yōu)點(diǎn)和一些限制。
優(yōu)點(diǎn)
優(yōu)點(diǎn) | 描述 |
適用于頻繁刷新 | LFU算法能夠優(yōu)先保留頻繁被刷新的數(shù)據(jù),適合某些周期性訪問(wèn)的場(chǎng)景。 |
對(duì)數(shù)據(jù)熱度變化敏感 | 相比于LRU算法,LFU算法更能適應(yīng)數(shù)據(jù)訪問(wèn)模式的變化,能夠更好地反映數(shù)據(jù)的熱度。 |
限制
限制 | 描述 |
計(jì)算復(fù)雜性 | LFU算法需要維護(hù)數(shù)據(jù)的訪問(wèn)頻率記錄,這可能導(dǎo)致一定的計(jì)算復(fù)雜性,特別是在大規(guī)模數(shù)據(jù)場(chǎng)景下。 |
冷啟動(dòng)問(wèn)題 | 對(duì)于剛開(kāi)始訪問(wèn)的數(shù)據(jù),由于沒(méi)有足夠的訪問(wèn)頻率信息,LFU算法可能難以做出合適的替換決策。 |
八、其他數(shù)據(jù)緩存策略
1、Least Recently Used with Sampling(LRUS)
除了傳統(tǒng)的LRU算法,還存在一種改進(jìn)的版本,即LRUS(Least Recently Used with Sampling)算法。LRUS算法通過(guò)周期性的采樣來(lái)記錄數(shù)據(jù)的訪問(wèn)情況,從而更好地估計(jì)最近使用的數(shù)據(jù),減少了LRU算法中的“冷啟動(dòng)·問(wèn)題。
LRUS算法原理
LRUS算法引入了采樣機(jī)制,通過(guò)周期性地記錄一部分?jǐn)?shù)據(jù)的訪問(wèn)情況,從而更準(zhǔn)確地判斷哪些數(shù)據(jù)是熱數(shù)據(jù),哪些是冷數(shù)據(jù)。與傳統(tǒng)的LRU算法不同,LRUS算法能夠更好地適應(yīng)數(shù)據(jù)訪問(wèn)模式的變化,提高數(shù)據(jù)緩存的命中率。
上圖LRUS算法通過(guò)周期性采樣記錄數(shù)據(jù)的訪問(wèn)情況,從而更精確地判斷哪些數(shù)據(jù)應(yīng)該被保留,哪些應(yīng)該被替換。
2、Random Replacement(隨機(jī)替換)
隨機(jī)替換是一種簡(jiǎn)單但有效的緩存策略。與LRU和LFU不同,隨機(jī)替換策略不考慮數(shù)據(jù)的訪問(wèn)時(shí)間或頻率,而是隨機(jī)選擇要替換的數(shù)據(jù)。盡管這聽(tīng)起來(lái)不太智能,但在某些場(chǎng)景下,隨機(jī)替換策略表現(xiàn)出意外的優(yōu)勢(shì)。
隨機(jī)替換的原理
隨機(jī)替換的核心思想是,每次需要替換數(shù)據(jù)時(shí),從緩存中隨機(jī)選擇一條數(shù)據(jù)進(jìn)行替換。雖然這種策略沒(méi)有考慮數(shù)據(jù)的熱度或頻率,但在一些特殊情況下,隨機(jī)替換能夠避免特定數(shù)據(jù)被頻繁淘汰,從而維持一定的數(shù)據(jù)多樣性。
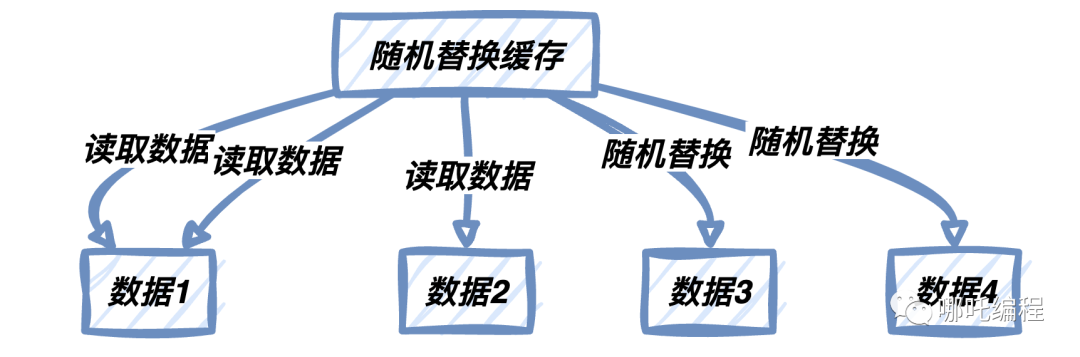
上圖中,隨機(jī)替換算法隨機(jī)選擇要替換的數(shù)據(jù),從而在一些情況下維持了數(shù)據(jù)多樣性。
九、性能優(yōu)化與實(shí)際應(yīng)用
1、數(shù)據(jù)緩存策略的性能考量
在選擇和配置數(shù)據(jù)緩存策略時(shí),性能是一個(gè)關(guān)鍵因素。不同的緩存策略適用于不同的業(yè)務(wù)場(chǎng)景,因此在做出決策時(shí)需要綜合考慮多個(gè)因素。
(1)緩存大小與命中率的平衡
在配置緩存大小時(shí),需要權(quán)衡緩存的總大小和實(shí)際存儲(chǔ)的數(shù)據(jù)量。一個(gè)過(guò)小的緩存可能導(dǎo)致命中率降低,無(wú)法有效減輕數(shù)據(jù)庫(kù)負(fù)載,而一個(gè)過(guò)大的緩存可能浪費(fèi)內(nèi)存資源。通常可以通過(guò)監(jiān)控命中率和緩存利用率來(lái)優(yōu)化緩存大小。
(2)數(shù)據(jù)訪問(wèn)模式的分析
分析業(yè)務(wù)的數(shù)據(jù)訪問(wèn)模式對(duì)于選擇合適的緩存策略至關(guān)重要。例如,如果某些數(shù)據(jù)被頻繁地訪問(wèn),而另一些數(shù)據(jù)則很少被訪問(wèn),那么選擇適當(dāng)?shù)牟呗钥梢蕴岣呔彺娴男Ч?duì)于頻繁訪問(wèn)的熱數(shù)據(jù),可以選擇LRU或者LFU策略,而對(duì)于較少訪問(wèn)的冷數(shù)據(jù),可以考慮隨機(jī)替換策略。
2、實(shí)際應(yīng)用案例:電子商務(wù)網(wǎng)站
讓我們通過(guò)一個(gè)實(shí)際的應(yīng)用案例,來(lái)展示如何根據(jù)業(yè)務(wù)需求選擇合適的緩存策略。考慮一個(gè)電子商務(wù)網(wǎng)站,用戶經(jīng)常訪問(wèn)商品列表、商品詳情以及購(gòu)物車等頁(yè)面。針對(duì)這個(gè)場(chǎng)景,可以選擇不同的緩存策略來(lái)優(yōu)化性能。
(1)電子商務(wù)網(wǎng)站的緩存策略選擇
商品列表頁(yè):由于商品列表頁(yè)中的商品信息經(jīng)常變動(dòng),可以選擇LRU或者隨機(jī)替換策略。這樣可以保留最近的商品數(shù)據(jù),提高頁(yè)面加載速度。
// 使用LRU算法實(shí)現(xiàn)商品列表頁(yè)緩存
LRUCache<String, List<Product>> productListCache = new LRUCache<>(1000); // 緩存容量1000
List<Product> cachedProductList = productListCache.get("productList");
if (cachedProductList == null) {
// 從數(shù)據(jù)庫(kù)獲取商品列表數(shù)據(jù)
List<Product> productList = database.getProductList();
productListCache.put("productList", productList);
cachedProductList = productList;
}商品詳情頁(yè):商品詳情頁(yè)的數(shù)據(jù)相對(duì)穩(wěn)定,適合選擇LFU策略。這樣可以保留頻繁訪問(wèn)的商品詳情數(shù)據(jù),提高頁(yè)面響應(yīng)速度。
// 使用LFU算法實(shí)現(xiàn)商品詳情頁(yè)緩存
LFUCache<String, ProductDetails> productDetailsCache = new LFUCache<>(500); // 緩存容量500
ProductDetails cachedProductDetails = productDetailsCache.get("product123");
if (cachedProductDetails == null) {
// 從數(shù)據(jù)庫(kù)獲取商品詳情數(shù)據(jù)
ProductDetails productDetails = database.getProductDetails("product123");
productDetailsCache.put("product123", productDetails);
cachedProductDetails = productDetails;
}購(gòu)物車頁(yè):購(gòu)物車頁(yè)的數(shù)據(jù)與用戶關(guān)聯(lián)緊密,可以選擇LRU或者LRUS策略。這樣可以保留最近被訪問(wèn)的購(gòu)物車數(shù)據(jù),提供更好的用戶體驗(yàn)。
// 使用LRUS算法實(shí)現(xiàn)購(gòu)物車頁(yè)緩存
LRUSCache<String, ShoppingCart> shoppingCartCache = new LRUSCache<>(200); // 緩存容量200
ShoppingCart cachedShoppingCart = shoppingCartCache.get("user123");
if (cachedShoppingCart == null) {
// 從數(shù)據(jù)庫(kù)獲取購(gòu)物車數(shù)據(jù)
ShoppingCart shoppingCart = database.getShoppingCart("user123");
shoppingCartCache.put("user123", shoppingCart);
cachedShoppingCart = shoppingCart;
}(2)性能優(yōu)化與實(shí)際應(yīng)用改進(jìn)
在實(shí)際應(yīng)用中,通過(guò)合理配置緩存策略以及優(yōu)化緩存大小,電子商務(wù)網(wǎng)站可以顯著提升頁(yè)面加載速度和用戶體驗(yàn)。同時(shí),通過(guò)監(jiān)控?cái)?shù)據(jù)訪問(wèn)模式的變化,還可以動(dòng)態(tài)調(diào)整緩存策略,進(jìn)一步優(yōu)化性能。
十、總結(jié)與實(shí)踐指導(dǎo)
1、Redis數(shù)據(jù)緩存策略的重要性
數(shù)據(jù)緩存不僅可以提升系統(tǒng)性能,還能降低后端數(shù)據(jù)庫(kù)的壓力,從而實(shí)現(xiàn)更快的響應(yīng)時(shí)間和更好的用戶體驗(yàn)。在現(xiàn)代高并發(fā)應(yīng)用中,優(yōu)化數(shù)據(jù)緩存策略已經(jīng)成為系統(tǒng)設(shè)計(jì)中不可或缺的一環(huán)。
2、如何選擇合適的緩存策略
在實(shí)際應(yīng)用中,選擇合適的緩存策略是至關(guān)重要的。根據(jù)不同的業(yè)務(wù)場(chǎng)景和數(shù)據(jù)訪問(wèn)模式,我們可以靈活地選擇LRU、LFU、LRUS、隨機(jī)替換等緩存策略。同時(shí),還可以根據(jù)實(shí)際需要?jiǎng)討B(tài)地調(diào)整緩存大小,以達(dá)到最佳的性能與資源利用率的平衡。
實(shí)踐指導(dǎo):
- 分析數(shù)據(jù)訪問(wèn)模式:在選擇緩存策略之前,首先需要詳細(xì)分析數(shù)據(jù)的訪問(wèn)模式。哪些數(shù)據(jù)被頻繁訪問(wèn)?哪些數(shù)據(jù)變化較少?根據(jù)這些信息,選擇適合的緩存策略。
- 選擇合適的算法:根據(jù)業(yè)務(wù)需求,選擇合適的緩存算法。LRU適用于保留最近訪問(wèn)的數(shù)據(jù),LFU適用于保留最頻繁訪問(wèn)的數(shù)據(jù),而LRUS則更好地應(yīng)對(duì)訪問(wèn)模式的變化。
- 監(jiān)控與優(yōu)化:緩存策略不是一成不變的,需要不斷監(jiān)控?cái)?shù)據(jù)訪問(wèn)情況,優(yōu)化緩存大小和策略。通過(guò)監(jiān)控緩存的命中率和利用率,可以動(dòng)態(tài)地做出調(diào)整。
- 靈活應(yīng)用:不同的業(yè)務(wù)模塊可能需要不同的緩存策略。根據(jù)實(shí)際情況,可以在系統(tǒng)中采用多種緩存策略,以最大程度地提升性能。


























