一文總結Kubernetes核心組件-控制器
Kubernetes的資源對象包括Pod、Node、Namespace、Endpoints、Service等,Kubernetes也提供了各種資源對象的控制器,用來驅動對象的當前狀態(status)逼近提交的期望狀態(spec)。本文從原理、類型、使用這3個方面說說控制器。

一、控制器的原理
1.大致原理
在Kubernetes 集群中,Controller通過 API Server提供的(List & Watch)接口實時監控集群中資源對象的狀態變化,當發生故障,導致資源對象的狀態變化時,Controller會嘗試將其狀態調整為期望的狀態。
比如當某個Pod出現故障時,Deployment Controller會及時發現故障并執行自動化修復流程,確保集群里的Pod始終處于預期的工作狀態。
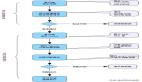
具體流程見下圖:

Kubernetes控制器是通過定期重復執行如下 3 個步驟來完成控制任務的:
- 從API Server讀取資源對象的期望狀態和當前狀態。
- 比較兩者的差異,然后運行控制器操作現實中的資源對象,將資源對象的真實狀態修正為Spec中定義的期望狀態。
- 變動執行成功后,將結果狀態寫回到在API Server上的目標資源對象的status字段中。

2.Controller Manager
Kubernetes 提供了名種資源對象的控制器,每種Controller 都負責一種特定資源的控制流程,而Controller Manager是這些控制器的管理者。
Controller Manager 發現資源的實際狀態和期望狀態有偏差之后,會觸發相應Controller注冊的Event Handler,讓它們去根據資源本身的特點進行調整。之所以叫Controller Manager,是因為Controller Manager 由負責不同資源的多種Controller組成,如 Deployment Controller、Node Controller、Namespace Controller、Service Controller等,這些Controllers各自明確分工,負責集群內各種資源的管理。
3.循環控制和立即控制
Kubernetes集群上運行著大量的控制循環,每個循環都有一組特定的任務要處理,為了避免API Server被大量的請求拖垮,需要設置控制循環以較低的頻率運行,默認每5分鐘一次。
同時,為了能及時觸發由客戶端提交的期望狀態,控制器向API Server注冊監聽資源對象事件,這些資源對象的期望狀態的任何變動都會由Informer組件通知給控制器立即執行而無須等到下一輪的控制循環。
控制器使用工作隊列將需要運行的控制循環進行排隊,從而確保在受控資源對象很多時 或 資源對象變動頻繁時,不會漏掉控制任務。
這個流程類似于做大數據統計時,一方面利用實時計算及時統計出結果,一方面利用批計算按日統計,重新比對和矯正實時計算的結果。
整體流程如下圖:

二、控制器的類型
Kubernetes 提供了Replication Controller、Node Controller、ResourceOuota Controller、Namespace Controller、ServiceAccount Controller、Service Controller、Endpoint Controller、Deploymont Controller等各種資源對象的控制器。常用的控制器有以下幾種。
1.ReplicaSet Controller
ReplicaSet保證在所有時間內,都有特定數量的Pod副本在運行。如果數量太多,ReplicaSet會刪除幾個;如果數量太少,ReplicaSet將創建幾個。與直接創建的Pod不同的是,ReplicaSet會替換掉那些被刪除或者被終止的Pod。
建議通過Deployment管理ReplicaSet,一般無須直接操作ReplicaSet。
ReplicaSet Controller中的 Pod 模板就像一個模具,模具制作出來的東西一旦離開模具,它們之間就再也沒關系了。同樣,一旦Pod被創建完畢,無論模板如何變化也不會影響到已經創建的 Pod 。
2.Deployment Controller
Deployment是管理應用副本的API對象。管理員只需要在Deployment中描述期望的狀態,Deployment就能根據一定的策略將ReplicaSet與Pod更新到管理員預期的狀態。Deployment提供了運行Pod的能力,并且為Pod提供滾動升級、伸縮、副本等功能,一般用于運行無狀態的應用。
需要說明的是,Deployment并不直接控制Pod,而是通過上面介紹的ReplicaSet實現對Pod的管理。
在創建 Deployment 資源對象之后,Deployment Controller 也默默創建了對應的ReplicaSet,Deployment 的滾動升級是Deployment Controller通過自動創建新的ReplicaSet來支持的。
3.StatefulSet Controller
StatefulSet用來管理一組Pod集合的部署和擴縮容,并為這些Pod提供持久化存儲和持久化標識符。與Deployment不同的是,StatefulSet為每個Pod維護了一個固定的ID。這些Pod是基于相同的模板來創建的,但是不能相互替換,無論怎么調度,每個Pod都有一個固定的ID。
4.DaemonSet Controller
DaemonSet確保全部Node上運行一個Pod的副本。當有Node加入集群時,會自動為它們新增一個Pod;當有Node從集群移除時,這些Pod也會被回收。刪除DaemonSet將會刪除它創建的所有Pod。
5.Job Controller
Job負責批量處理短暫的一次性任務,即僅執行一次的任務,它保證批處理任務的一個或多個Pod成功結束。
6.CronJob Controller
CronJob負責周期性的處理任務,根據Cron表達式定時執行Job。
7.Node Controller
kubelet進程在啟動時通過 API Server 注冊自身節點信息,并定時向API Server匯報狀態信息,API Server 在接收到這些信息后,會將這些信息更新到etcd中。在etcd 中存儲的節點信息包括節點健康狀況、節點資源、節點名稱、節點地址信息、操作系統版本、Dooker版本、kubelet版本等。
節點健康狀況包含就緒(True)、未就緒(False)、未知(Unknown)三種。
Node Controller通過API Server實時獲取 Node的相關信息,實現管理和監控集群中各個Node的相關控制功能。
8.ResourceQuota Controller
ResourceQuota Controller(資源配額管理)確保指定的資源對象在任何時候都不會超量占用系統物理資源,避免由于某些業務在設計或實現上的缺陷,導致整個系統運行紊亂甚至宕機。比如可以對容器運行的CPU和Memory進行限制。對Namespace下的Pod數量、Service數量、PV數量等進行限制。
9.Service Controller 與 Endpoints Controller
我們先看看Service、Endpoints與Pod 的關系。如圖下圖所示,Endpoints表示一個Service對應的所有Pod副本的訪問地址,Endpoints Controller就是負責生成和維護所有Endpoints對象的控制器。

Endpoints Controller負責監聽Service和對應的Pod副本的變化,如果監測到Service被刪除,則刪除和該Service同名的Endpoints對象。如果監測到新的 Service 被創建或者修改,則根據該 Service 信息獲得相關的Pod列表,然后創建或者更新 Service 對應的Endpoints 對象。如果監測到Pod的事件,則更新它所對應的Service的Endpoints對象(增加、刪除或者修改對應的 Endpoint 列表)。
那么,Endpoints對象是在哪里被使用的呢?答案是每個 Node 上的kube-proxy進程,kube-proxy進程獲取每個Service的Endpoints,實現了Service的負載均衡功能。
Service Controller則是監聽Service的變化,相應地創建、刪除或者更新路由轉發表(根據Endpoints的列表)。
三、控制器的使用
一個工作負載控制器資源通常包含3 個基本的組成部分。
- 選擇器:匹配并關聯 Pod 對象
- 期望的副本數:期望在集群中運行受控的 Pod 數量。
- Pod模板:用于新建 Pod 對象使用的模板。
工作負載控制器的資源的spec字段通常要包含如下字段:replicas、selector和template,其中template是用于定義 Pod模板。
常用控制器的編排yaml如下。
1.Deployment
管理一組Pod,假設設置副本數 replicas=2,這時 node01和node02上會各自分配一個Pod,現在將node02關閉,則會發現node01上會部署兩個Pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: test
labels:
app: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx-deployment-tp
template:
metadata:
labels:
app: nginx-deployment-tp
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 302.StatefulSet
StatefulSet是幾種工作負載當中較為復雜的一種,當然核心也是管理一組Pod。舉個例子:假設設置副本數replicas=2,那么這一組Pod有如下特性:
- 啟動的有序性:pod-0啟動之后,再啟動pod-1。
- 停止的有序性:pod-1停止之后,再停止pod-0。
- 有狀態:pod的id不變,創建的PVC是是跟Pod綁定的,有獨特的volumeClaimTemplate配置,會利用storgeClass自動創建PVC和PV 。
- 穩定服務發現: Service可以找到自己想找到的pod,因為Pod的id是固定的有狀態的。例如要訪問某個Pod,可以直接使用curl pod名稱.svc名稱.命名空間.svc.cluster.local。
apiVersion: v1
kind: Service
metadata:
name: nginx-statefulset-svc
namespace: test
spec:
# ClusterIP | LoadBalancer |
type: ClusterIP
# headless service
clusterIP: None
selector:
app: nginx-statefulset-tp
ports:
- name: http
port: 80
targetPort: 80
# nodePort: 30080
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulset
namespace: test
labels:
app: nginx-statefulset
spec:
replicas: 2
serviceName: nginx-statefulset-svc
selector:
matchLabels:
app: nginx-statefulset-tp
template:
metadata:
labels:
app: nginx-statefulset-tp
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 30
volumeClaimTemplates:
- metadata:
name: www
spec:
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnce
storageClassName: nfs-client3.DaemonSet
管理一組Pod,相比Deployment和StatefulSet,沒有副本數的概念。它有如下特性:
- 每個node上部署一個pod
- node上部署的pod不會被驅逐,默認添加對所有節點污點的容忍
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-daemonset
namespace: test
labels:
app: nginx-daemonset
spec:
selector:
matchLabels:
app: nginx-daemonset-tp
template:
metadata:
labels:
app: nginx-daemonset-tp
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent4.Job
執行一次就結束的Pod
apiVersion: batch/v1
kind: Job
metadata:
name: hello
namespace: test
spec:
# 嘗試backoffLimit+1次 沒有成功 則退出Job
backoffLimit: 2
completions: 3
template:
spec:
# 僅支持 OnFailure Never
restartPolicy: Never
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- echo "Hello My Job"5.CronJob
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
namespace: test
spec:
# ┌───────────── 分鐘 (0 - 59)
# │ ┌───────────── 小時 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系統上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
schedule: "* * * * *"
# Allow - 允許并發
# Forbid - 不允許并發 丟棄新的job
# Replace - 不允許并發 丟棄老的job
concurrencyPolicy: Allow
# 記錄成功的job數量
successfulJobsHistoryLimit: 3
# 記錄失敗的job數量
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
# 僅支持 OnFailure Never
restartPolicy: Never
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- echo "Hello My Cron Job"Job的基礎上定義Cron表達式,定時執行Job