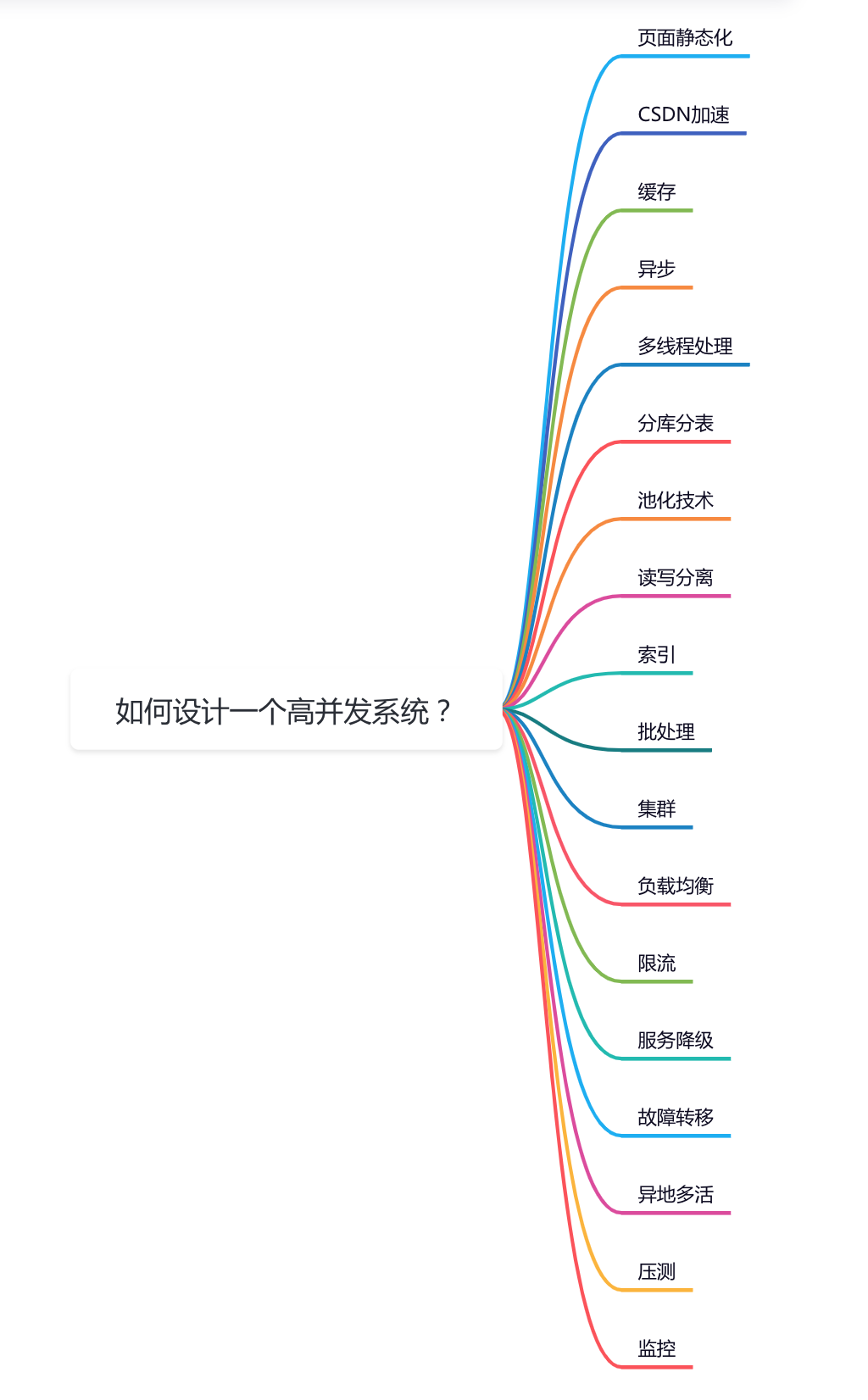
如何設(shè)計(jì)一個(gè)高并發(fā)系統(tǒng)?

前言
最近有位粉絲問了我一個(gè)問題:如何設(shè)計(jì)一個(gè)高并發(fā)系統(tǒng)?
這是一個(gè)非常高頻的面試題,面試官可以從多個(gè)角度,考查技術(shù)的廣度和深度。
今天這篇文章跟大家一起聊聊高并發(fā)系統(tǒng)設(shè)計(jì)一些關(guān)鍵點(diǎn),希望對(duì)你會(huì)有所幫助。
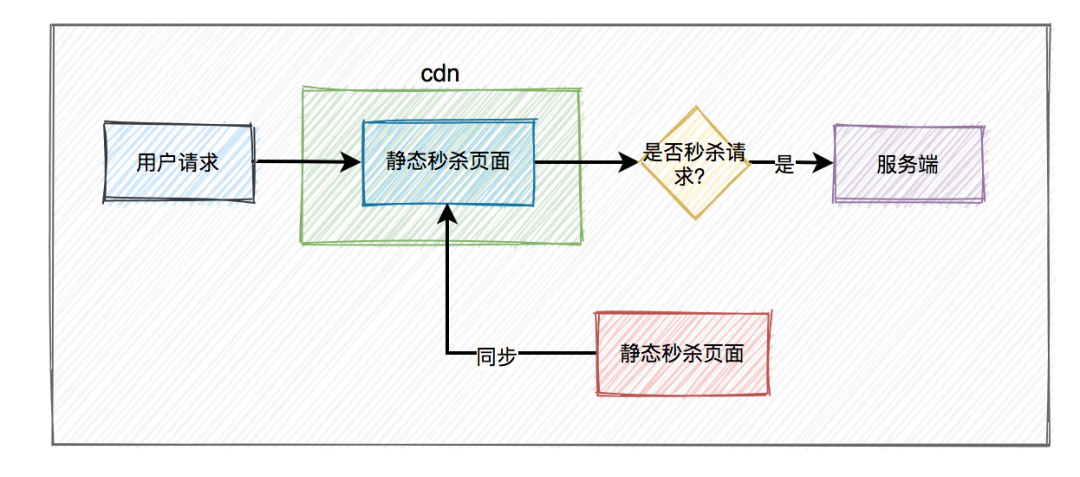
1、頁面靜態(tài)化
對(duì)于高并發(fā)系統(tǒng)的頁面功能,我們必須要做靜態(tài)化設(shè)計(jì)。
如果并發(fā)訪問系統(tǒng)的用戶非常多,每次用戶訪問頁面的時(shí)候,都通過服務(wù)器動(dòng)態(tài)渲染,會(huì)導(dǎo)致服務(wù)端承受過大的壓力,而導(dǎo)致頁面無法正常加載的情況發(fā)生。
我們可以使用Freemarker或Velocity模板引擎,實(shí)現(xiàn)頁面靜態(tài)化功能。
以商城官網(wǎng)首頁為例,我們可以在Job中,每隔一段時(shí)間,查詢出所有需要在首頁展示的數(shù)據(jù),匯總到一起,使用模板引擎生成到html文件當(dāng)中。
然后將該html文件,通過shell腳本,自動(dòng)同步到前端頁面相關(guān)的服務(wù)器上。
2、CSDN加速
雖說頁面靜態(tài)化可以提升網(wǎng)站網(wǎng)頁的訪問速度,但還不夠,因?yàn)橛脩舴植荚谌珖鞯兀行┤嗽诒本行┤嗽诔啥迹行┤嗽谏钲冢赜蛳嗖詈苓h(yuǎn),他們?cè)L問網(wǎng)站的網(wǎng)速各不相同。
如何才能讓用戶最快訪問到活動(dòng)頁面呢?
這就需要使用CDN,它的全稱是Content Delivery Network,即內(nèi)容分發(fā)網(wǎng)絡(luò)。
使用戶就近獲取所需內(nèi)容,降低網(wǎng)絡(luò)擁塞,提高用戶訪問響應(yīng)速度和命中率。
CDN加速的基本原理是:將網(wǎng)站的靜態(tài)內(nèi)容(如圖片、CSS、JavaScript文件等)復(fù)制并存儲(chǔ)到分布在全球各地的服務(wù)器節(jié)點(diǎn)上。
當(dāng)用戶請(qǐng)求訪問網(wǎng)站時(shí),CDN系統(tǒng)會(huì)根據(jù)用戶的地理位置,自動(dòng)將內(nèi)容分發(fā)給離用戶最近的服務(wù)器,從而實(shí)現(xiàn)快速訪問。
國內(nèi)常見的CDN提供商有阿里云CDN、騰訊云CDN、百度云加速等,它們提供了全球分布的節(jié)點(diǎn)服務(wù)器,為全球范圍內(nèi)的網(wǎng)站加速服務(wù)。
3、緩存
在高并發(fā)的系統(tǒng)中,緩存可以說是必不可少的技術(shù)之一。
目前緩存有兩種:
- 基于應(yīng)用服務(wù)器的內(nèi)存緩存,也就是我們說的二級(jí)緩存。
- 使用緩存中間件,比如:Redis、Memcached等,這種是分布式緩存。
這兩種緩存各有優(yōu)缺點(diǎn)。
二級(jí)緩存的性能更好,但因?yàn)槭腔趹?yīng)用服務(wù)器內(nèi)存的緩存,如果系統(tǒng)部署到了多個(gè)服務(wù)器節(jié)點(diǎn),可能會(huì)存在數(shù)據(jù)不一致的情況。
而Redis或Memcached雖說性能上比不上二級(jí)緩存,但它們是分布式緩存,避免多個(gè)服務(wù)器節(jié)點(diǎn)數(shù)據(jù)不一致的問題。
緩存的用法一般是這樣的:
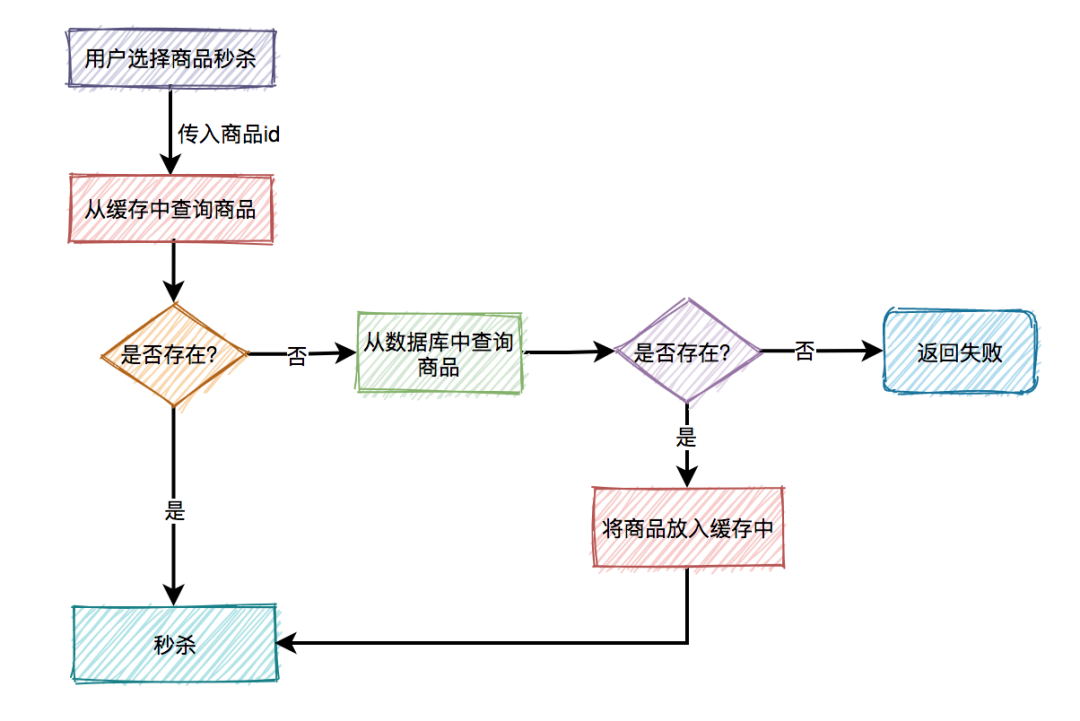
使用緩存之后,可以減輕訪問數(shù)據(jù)庫的壓力,顯著的提升系統(tǒng)的性能。
有些業(yè)務(wù)場(chǎng)景,甚至?xí)植际骄彺婧投?jí)緩存一起使用。
比如獲取商品分類數(shù)據(jù),流程如下:
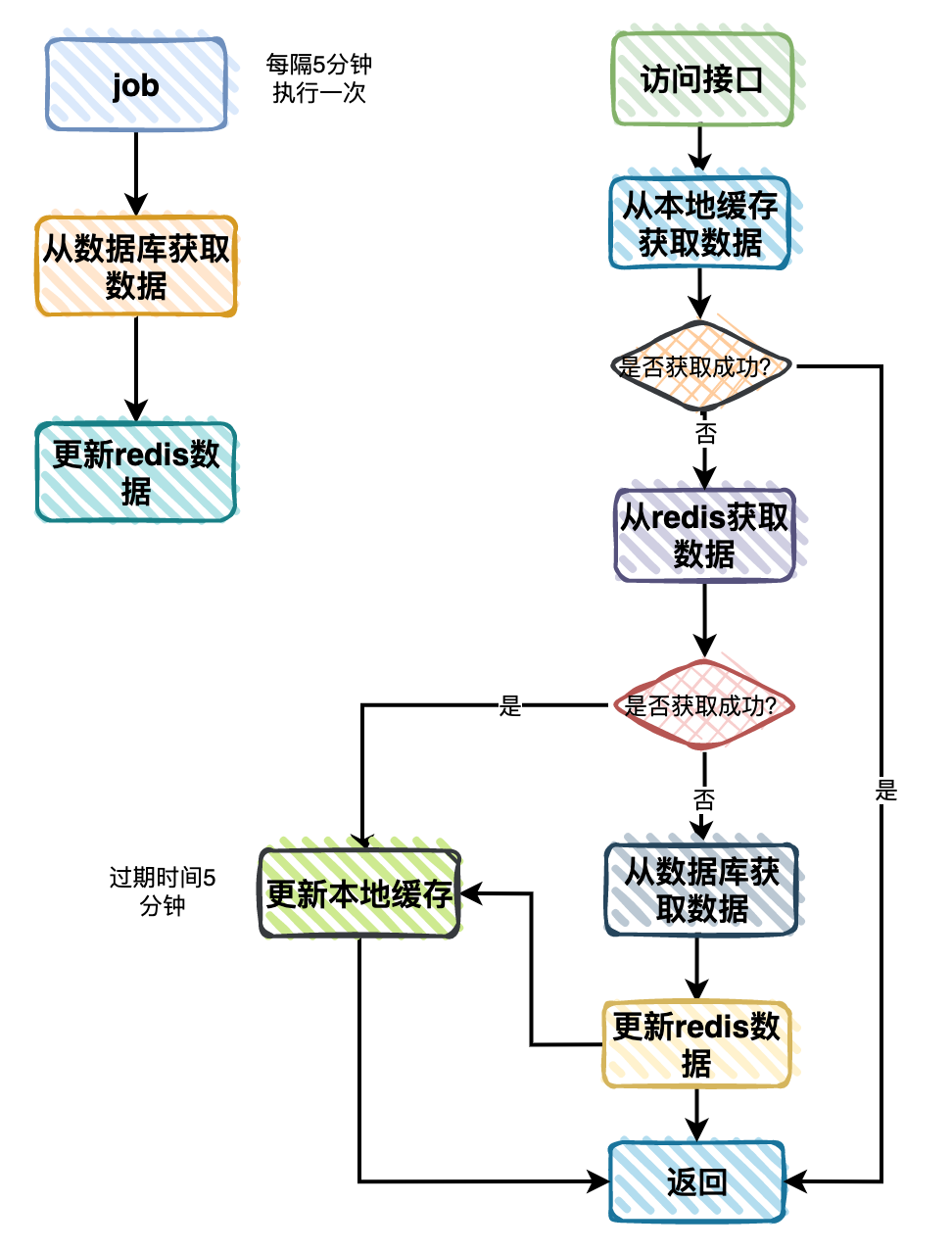
不過引入緩存,雖說給我們的系統(tǒng)性能帶來了提升,但同時(shí)也給我們帶來了一些新的問題,比如:《數(shù)據(jù)庫和緩存雙向數(shù)據(jù)庫一致性問題》、《緩存穿透、擊穿和雪崩問題》等。
我們?cè)谑褂镁彺鏁r(shí),一定要結(jié)合實(shí)際業(yè)務(wù)場(chǎng)景,切記不要為了緩存而緩存。
4、異步
有時(shí)候,我們?cè)诟卟l(fā)系統(tǒng)當(dāng)中,某些接口的業(yè)務(wù)邏輯,沒必要都同步執(zhí)行。
比如有個(gè)用戶請(qǐng)求接口中,需要做業(yè)務(wù)操作,發(fā)站內(nèi)通知,和記錄操作日志。為了實(shí)現(xiàn)起來比較方便,通常我們會(huì)將這些邏輯放在接口中同步執(zhí)行,勢(shì)必會(huì)對(duì)接口性能造成一定的影響。
接口內(nèi)部流程圖如下:
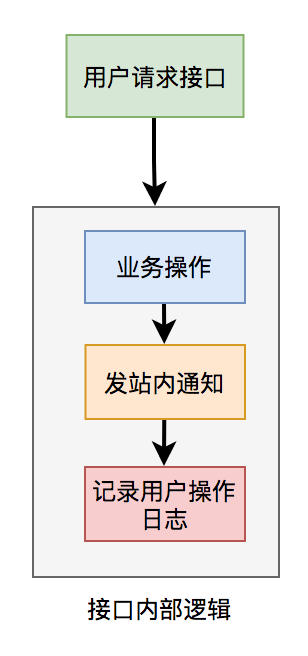
這個(gè)接口表面上看起來沒有問題,但如果你仔細(xì)梳理一下業(yè)務(wù)邏輯,會(huì)發(fā)現(xiàn)只有業(yè)務(wù)操作才是核心邏輯,其他的功能都是非核心邏輯。
在這里有個(gè)原則就是:核心邏輯可以同步執(zhí)行,同步寫庫。非核心邏輯,可以異步執(zhí)行,異步寫庫。
上面這個(gè)例子中,發(fā)站內(nèi)通知和用戶操作日志功能,對(duì)實(shí)時(shí)性要求不高,即使晚點(diǎn)寫庫,用戶無非是晚點(diǎn)收到站內(nèi)通知,或者運(yùn)營晚點(diǎn)看到用戶操作日志,對(duì)業(yè)務(wù)影響不大,所以完全可以異步處理。
通常異步主要有兩種:多線程 和 mq。
(1)線程池
使用線程池改造之后,接口邏輯如下:
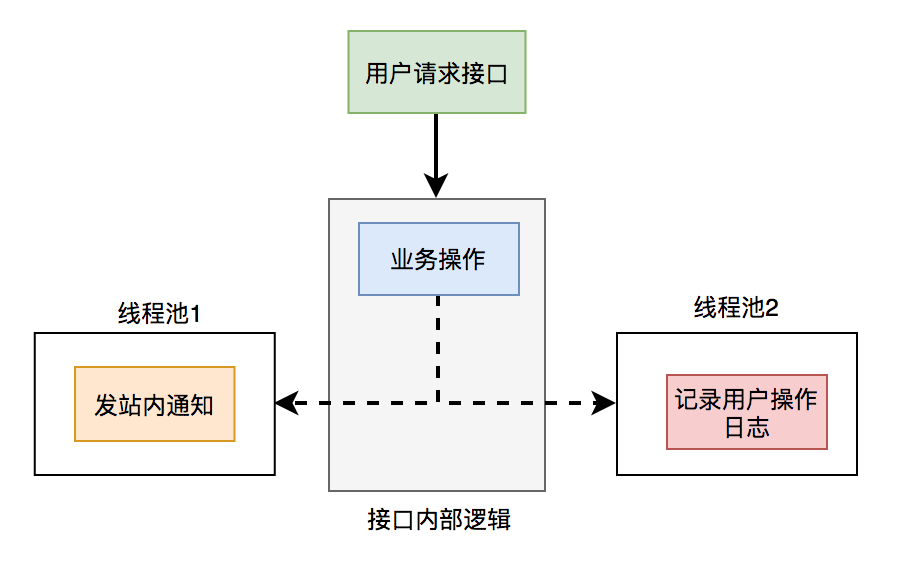
發(fā)站內(nèi)通知和用戶操作日志功能,被提交到了兩個(gè)單獨(dú)的線程池中。
這樣接口中重點(diǎn)關(guān)注的是業(yè)務(wù)操作,把其他的邏輯交給線程異步執(zhí)行,這樣改造之后,讓接口性能瞬間提升了。
但使用線程池有個(gè)小問題就是:如果服務(wù)器重啟了,或者是需要被執(zhí)行的功能出現(xiàn)異常了,無法重試,會(huì)丟數(shù)據(jù)。
那么這個(gè)問題該怎么辦呢?
(2)mq
使用mq改造之后,接口邏輯如下:
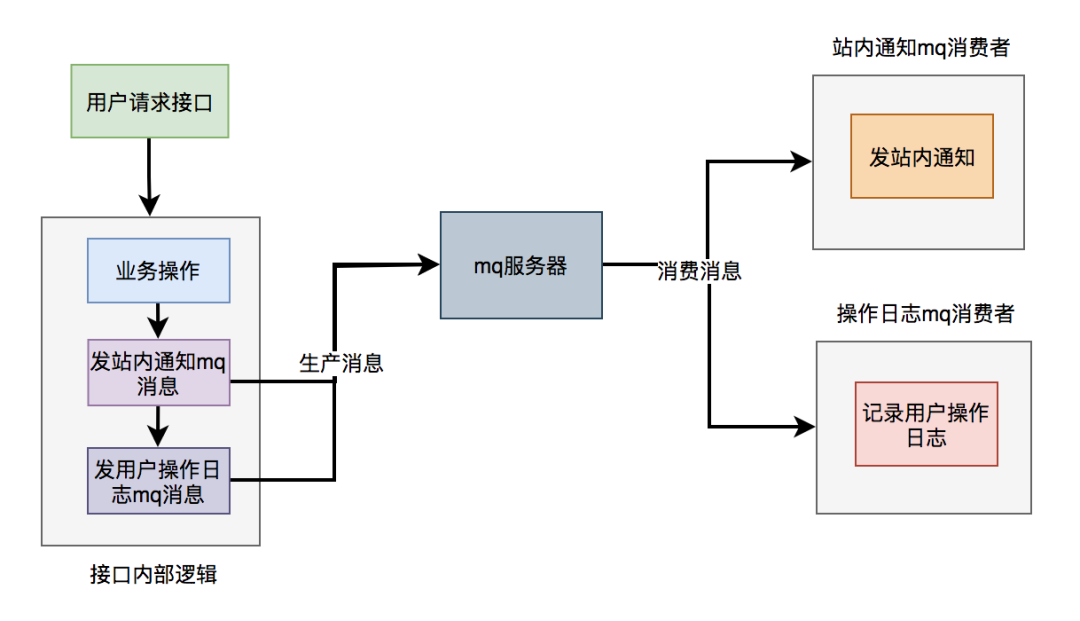
對(duì)于發(fā)站內(nèi)通知和用戶操作日志功能,在接口中并沒真正實(shí)現(xiàn),它只發(fā)送了mq消息到mq服務(wù)器。然后由mq消費(fèi)者消費(fèi)消息時(shí),才真正的執(zhí)行這兩個(gè)功能。
這樣改造之后,接口性能同樣提升了,因?yàn)榘l(fā)送mq消息速度是很快的,我們只需關(guān)注業(yè)務(wù)操作的代碼即可。
5、多線程處理
在高并發(fā)系統(tǒng)當(dāng)中,用戶的請(qǐng)求量很大。
假如我們現(xiàn)在用mq處理業(yè)務(wù)邏輯。
一下子有大量的用戶請(qǐng)求,產(chǎn)生了大量的mq消息,保存到了mq服務(wù)器。
而mq的消費(fèi)者,消費(fèi)速度很慢。
可能會(huì)導(dǎo)致大量的消息積壓?jiǎn)栴}。
從而嚴(yán)重影響數(shù)據(jù)的實(shí)時(shí)性。
我們需要對(duì)消息的消費(fèi)者做優(yōu)化。
最快的方式是使用多線程消費(fèi)消息,比如:改成線程池消費(fèi)消息。
當(dāng)然核心線程數(shù)、最大線程數(shù)、隊(duì)列大小 和 線程回收時(shí)間,一定要做成配置的,后面可以根據(jù)實(shí)際情況動(dòng)態(tài)調(diào)整。
這樣改造之后,我們可以快速解決消息積壓?jiǎn)栴}。
除此之外,在很多數(shù)據(jù)導(dǎo)入場(chǎng)景,用多線程導(dǎo)入數(shù)據(jù),可以提升效率。
溫馨提醒一下:使用多線程消費(fèi)消息,可能會(huì)出現(xiàn)消息的順序問題。如果你的業(yè)務(wù)場(chǎng)景中,需要保證消息的順序,則要用其他的方式解決問題。感興趣的小伙伴,可以找我私聊。
6、分庫分表
有時(shí)候,高并發(fā)系統(tǒng)的吞吐量受限的不是別的,而是數(shù)據(jù)庫。
當(dāng)系統(tǒng)發(fā)展到一定的階段,用戶并發(fā)量大,會(huì)有大量的數(shù)據(jù)庫請(qǐng)求,需要占用大量的數(shù)據(jù)庫連接,同時(shí)會(huì)帶來磁盤IO的性能瓶頸問題。
此外,隨著用戶數(shù)量越來越多,產(chǎn)生的數(shù)據(jù)也越來越多,一張表有可能存不下。由于數(shù)據(jù)量太大,sql語句查詢數(shù)據(jù)時(shí),即使走了索引也會(huì)非常耗時(shí)。
這時(shí)該怎么辦呢?
答:需要做分庫分表。
如下圖所示:
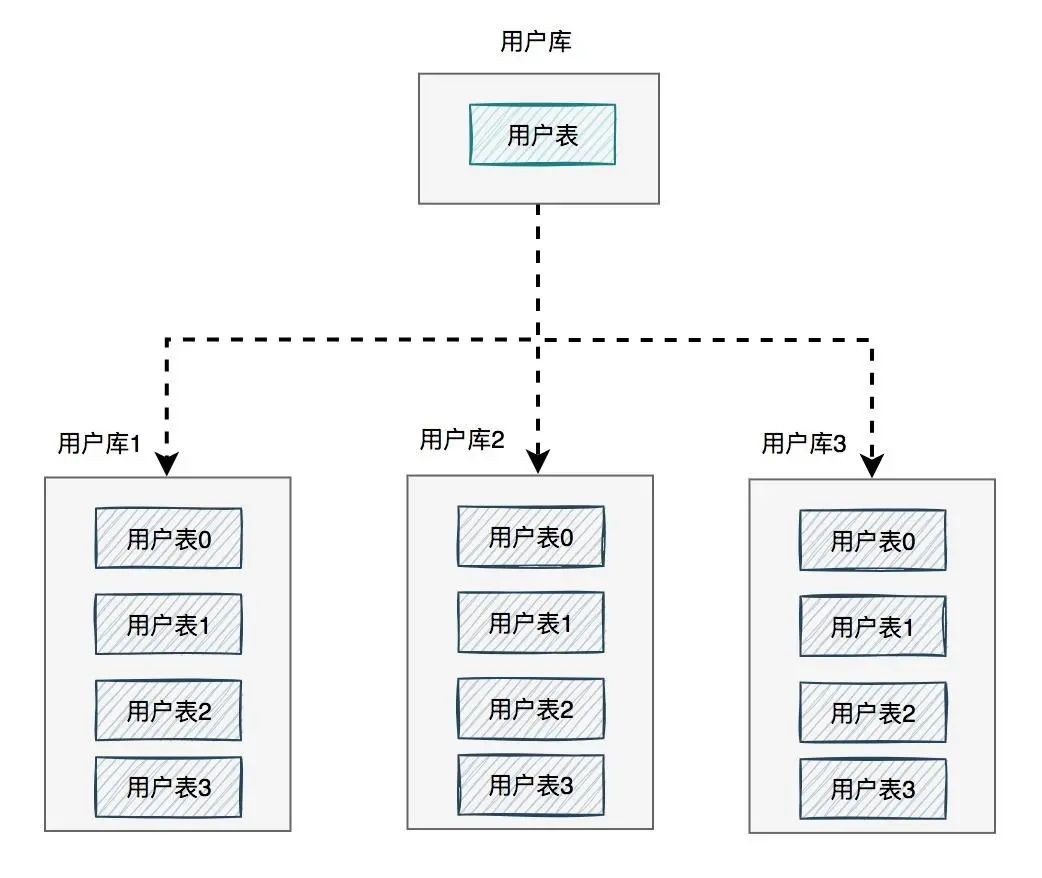
圖中將用戶庫拆分成了三個(gè)庫,每個(gè)庫都包含了四張用戶表。
如果有用戶請(qǐng)求過來的時(shí)候,先根據(jù)用戶id路由到其中一個(gè)用戶庫,然后再定位到某張表。
路由的算法挺多的:
- 根據(jù)id取模,比如:id=7,有4張表,則7%4=3,模為3,路由到用戶表3。
- 給id指定一個(gè)區(qū)間范圍,比如:id的值是0-10萬,則數(shù)據(jù)存在用戶表0,id的值是10-20萬,則數(shù)據(jù)存在用戶表1。
- 一致性hash算法
分庫分表主要有兩個(gè)方向:垂直和水平。
說實(shí)話垂直方向(即業(yè)務(wù)方向)更簡(jiǎn)單。
在水平方向(即數(shù)據(jù)方向)上,分庫和分表的作用,其實(shí)是有區(qū)別的,不能混為一談。
- 分庫:是為了解決數(shù)據(jù)庫連接資源不足問題,和磁盤IO的性能瓶頸問題。
- 分表:是為了解決單表數(shù)據(jù)量太大,sql語句查詢數(shù)據(jù)時(shí),即使走了索引也非常耗時(shí)問題。此外還可以解決消耗cpu資源問題。
- 分庫分表:可以解決 數(shù)據(jù)庫連接資源不足、磁盤IO的性能瓶頸、檢索數(shù)據(jù)耗時(shí) 和 消耗cpu資源等問題。
如果在有些業(yè)務(wù)場(chǎng)景中,用戶并發(fā)量很大,但是需要保存的數(shù)據(jù)量很少,這時(shí)可以只分庫,不分表。
如果在有些業(yè)務(wù)場(chǎng)景中,用戶并發(fā)量不大,但是需要保存的數(shù)量很多,這時(shí)可以只分表,不分庫。
如果在有些業(yè)務(wù)場(chǎng)景中,用戶并發(fā)量大,并且需要保存的數(shù)量也很多時(shí),可以分庫分表。
關(guān)于分庫分表更詳細(xì)的內(nèi)容,可以看看我另一篇文章,里面講的更深入《阿里二面:為什么分庫分表?》
7、池化技術(shù)
其實(shí)不光是高并發(fā)系統(tǒng),為了性能考慮,有些低并發(fā)的系統(tǒng),也在使用池化技術(shù),比如:數(shù)據(jù)庫連接池、線程池等。
池化技術(shù)是多例設(shè)計(jì)模式的一個(gè)體現(xiàn)。
我們都知道創(chuàng)建和銷毀數(shù)據(jù)庫連接是非常耗時(shí)耗資源的操作。
如果每次用戶請(qǐng)求,都需要?jiǎng)?chuàng)建一個(gè)新的數(shù)據(jù)庫連接,勢(shì)必會(huì)影響程序的性能。
為了提升性能,我們可以創(chuàng)建一批數(shù)據(jù)庫連接,保存到內(nèi)存中的某個(gè)集合中,緩存起來。
這樣的話,如果下次有需要用數(shù)據(jù)庫連接的時(shí)候,就能直接從集合中獲取,不用再額外創(chuàng)建數(shù)據(jù)庫連接,這樣處理將會(huì)給我們提升系統(tǒng)性能。
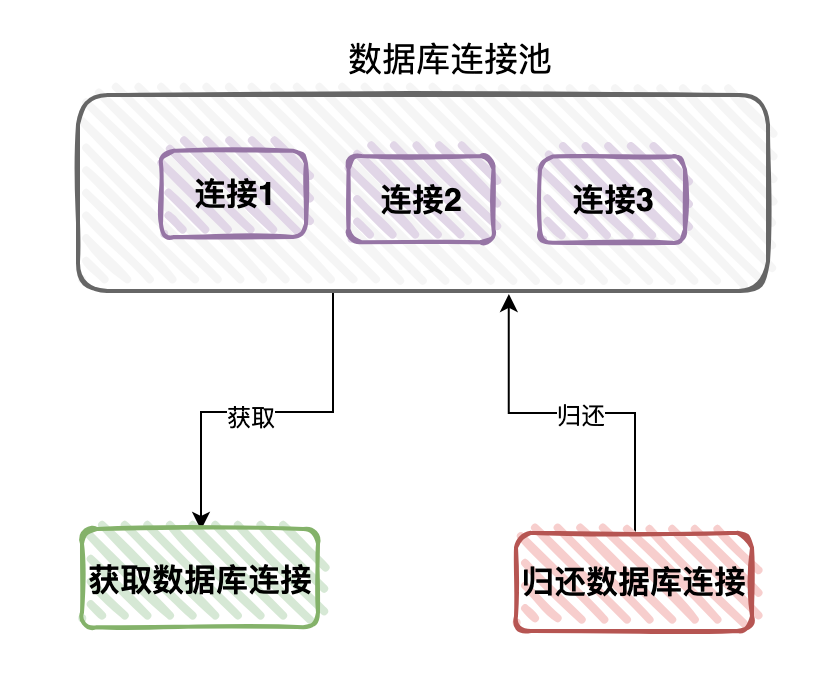
當(dāng)然用完之后,需要及時(shí)歸還。
目前常用的數(shù)據(jù)庫連接池有:Druid、C3P0、hikari和DBCP等。
8、讀寫分離
不知道你有沒有聽說過二八原則,在一個(gè)系統(tǒng)當(dāng)中可能有80%是讀數(shù)據(jù)請(qǐng)求,另外20%是寫數(shù)據(jù)請(qǐng)求。
不過這個(gè)比例也不是絕對(duì)的。
我想告訴大家的是,一般的系統(tǒng)讀數(shù)據(jù)請(qǐng)求會(huì)遠(yuǎn)遠(yuǎn)大于寫數(shù)據(jù)請(qǐng)求。
如果讀數(shù)據(jù)請(qǐng)求和寫數(shù)據(jù)請(qǐng)求,都訪問同一個(gè)數(shù)據(jù)庫,可能會(huì)相互搶占數(shù)據(jù)庫連接,相互影響。
我們都知道,一個(gè)數(shù)據(jù)庫的數(shù)據(jù)庫連接數(shù)量是有限,是非常寶貴的資源,不能因?yàn)樽x數(shù)據(jù)請(qǐng)求,影響到寫數(shù)據(jù)請(qǐng)求吧?
這就需要對(duì)數(shù)據(jù)庫做讀寫分離了。
于是,就出現(xiàn)了主從讀寫分離架構(gòu):
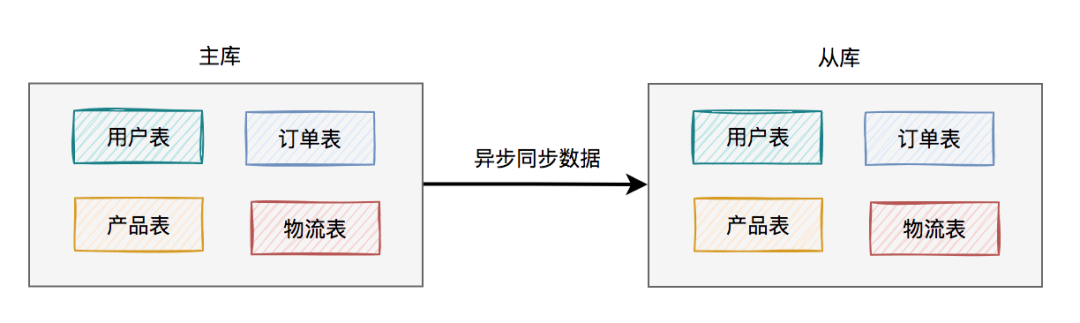
考慮剛開始用戶量還沒那么大,選擇的是一主一從的架構(gòu),也就是常說的一個(gè)master,一個(gè)slave。
所有的寫數(shù)據(jù)請(qǐng)求,都指向主庫。一旦主庫寫完數(shù)據(jù)之后,立馬異步同步給從庫。這樣所有的讀數(shù)據(jù)請(qǐng)求,就能及時(shí)從從庫中獲取到數(shù)據(jù)了(除非網(wǎng)絡(luò)有延遲)。
但這里有個(gè)問題就是:如果用戶量確實(shí)有些大,如果master掛了,升級(jí)slave為master,將所有讀寫請(qǐng)求都指向新master。
但此時(shí),如果這個(gè)新master根本扛不住所有的讀寫請(qǐng)求,該怎么辦?
這就需要一主多從的架構(gòu)了:
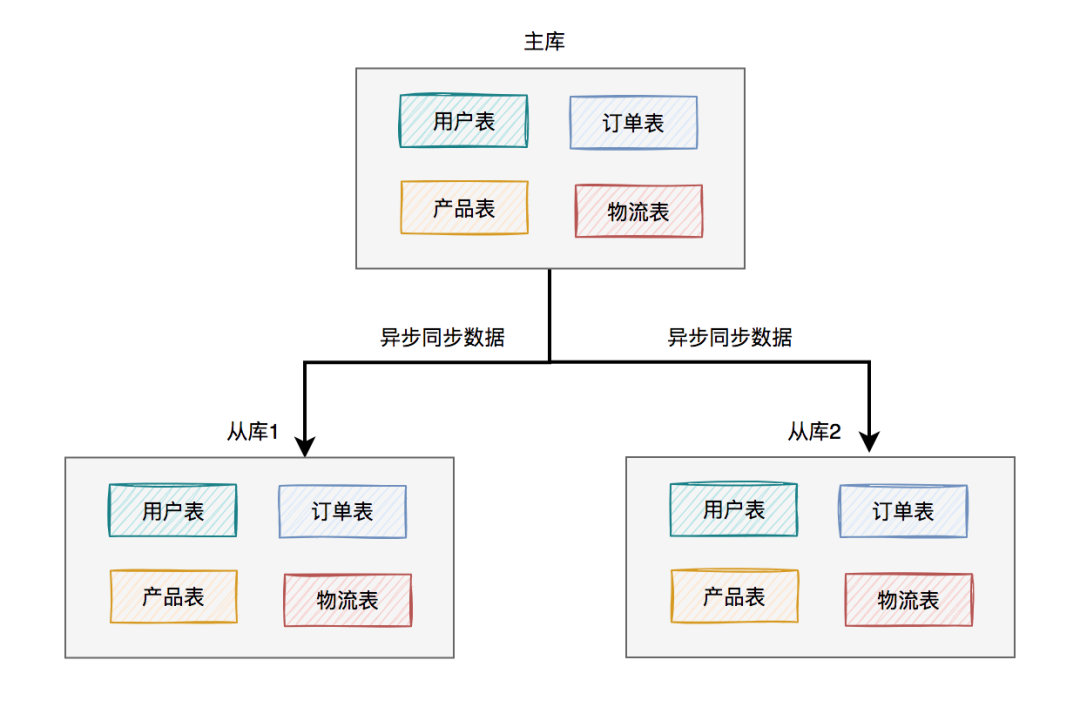
上圖中我列的是一主兩從,如果master掛了,可以選擇從庫1或從庫2中的一個(gè),升級(jí)為新master。假如我們?cè)谶@里升級(jí)從庫1為新master,則原來的從庫2就變成了新master的的slave了。
調(diào)整之后的架構(gòu)圖如下:
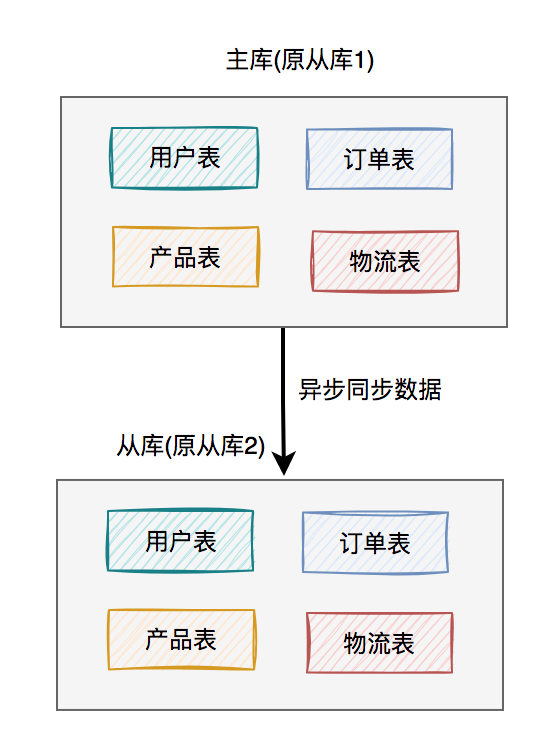
這樣就能解決上面的問題了。
除此之外,如果查詢請(qǐng)求量再增大,我們還可以將架構(gòu)升級(jí)為一主三從、一主四從...一主N從等。
9、索引
在高并發(fā)的系統(tǒng)當(dāng)中,用戶經(jīng)常需要查詢數(shù)據(jù),對(duì)數(shù)據(jù)庫增加索引,是必不可少的一個(gè)環(huán)節(jié)。
尤其是表中數(shù)據(jù)非常多時(shí),加了索引,跟沒加索引,執(zhí)行同一條sql語句,查詢相同的數(shù)據(jù),耗時(shí)可能會(huì)相差N個(gè)數(shù)量級(jí)。
雖說索引能夠提升SQL語句的查詢速度,但索引也不是越多越好。
在insert數(shù)據(jù)時(shí),需要給索引分配額外的資源,對(duì)insert的性能有一定的損耗。
我們要根據(jù)實(shí)際業(yè)務(wù)場(chǎng)景來決定創(chuàng)建哪些索引,索引少了,影響查詢速度,索引多了,影響寫入速度。
很多時(shí)候,我們需要經(jīng)常對(duì)索引做優(yōu)化。
- 可以將多個(gè)單個(gè)索引,改成一個(gè)聯(lián)合索引。
- 刪除不要索引。
- 使用explain關(guān)鍵字,查詢SQL語句的執(zhí)行計(jì)劃,看看哪些走了索引,哪些沒有走索引。
- 要注意索引失效的一些場(chǎng)景。
- 必要時(shí)可以使用force index來強(qiáng)制查詢sql走某個(gè)索引。
10、批處理
有時(shí)候,我們需要從指定的用戶集合中,查詢出有哪些是在數(shù)據(jù)庫中已經(jīng)存在的。
實(shí)現(xiàn)代碼可以這樣寫:
public List<User> queryUser(List<User> searchList) {
if (CollectionUtils.isEmpty(searchList)) {
return Collections.emptyList();
}
List<User> result = Lists.newArrayList();
searchList.forEach(user -> result.add(userMapper.getUserById(user.getId())));
return result;
}這里如果有50個(gè)用戶,則需要循環(huán)50次,去查詢數(shù)據(jù)庫。我們都知道,每查詢一次數(shù)據(jù)庫,就是一次遠(yuǎn)程調(diào)用。
如果查詢50次數(shù)據(jù)庫,就有50次遠(yuǎn)程調(diào)用,這是非常耗時(shí)的操作。
那么,我們?nèi)绾蝺?yōu)化呢?
答:批處理。
具體代碼如下:
public List<User> queryUser(List<User> searchList) {
if (CollectionUtils.isEmpty(searchList)) {
return Collections.emptyList();
}
List<Long> ids = searchList.stream().map(User::getId).collect(Collectors.toList());
return userMapper.getUserByIds(ids);
}提供一個(gè)根據(jù)用戶id集合批量查詢用戶的接口,只遠(yuǎn)程調(diào)用一次,就能查詢出所有的數(shù)據(jù)。
這里有個(gè)需要注意的地方是:id集合的大小要做限制,最好一次不要請(qǐng)求太多的數(shù)據(jù)。要根據(jù)實(shí)際情況而定,建議控制每次請(qǐng)求的記錄條數(shù)在500以內(nèi)。
11、集群
系統(tǒng)部署的服務(wù)器節(jié)點(diǎn),可能會(huì)down機(jī),比如:服務(wù)器的磁盤壞了,或者操作系統(tǒng)出現(xiàn)內(nèi)存不足問題。
為了保證系統(tǒng)的高可用,我們需要部署多個(gè)節(jié)點(diǎn),構(gòu)成一個(gè)集群,防止因?yàn)椴糠址?wù)器節(jié)點(diǎn)掛了,導(dǎo)致系統(tǒng)的整個(gè)服務(wù)不可用的情況發(fā)生。
集群有很多種:
- 應(yīng)用服務(wù)器集群
- 數(shù)據(jù)庫集群
- 中間件集群
- 文件服務(wù)器集群
我們以中間件Redis為例。
在高并發(fā)系統(tǒng)中,用戶的數(shù)據(jù)量非常龐大時(shí),比如用戶的緩存數(shù)據(jù)總共大小有40G,一個(gè)服務(wù)器節(jié)點(diǎn)只有16G的內(nèi)存。
這樣需要部署3臺(tái)服務(wù)器節(jié)點(diǎn)。
該業(yè)務(wù)場(chǎng)景,使用普通的master/slave模式,或者使用哨兵模式都行不通。
40G的數(shù)據(jù),不能只保存到一臺(tái)服務(wù)器節(jié)點(diǎn),需要均分到3個(gè)master服務(wù)器節(jié)點(diǎn)上,一個(gè)master服務(wù)器節(jié)點(diǎn)保存13.3G的數(shù)據(jù)。
當(dāng)有用戶請(qǐng)求過來的時(shí)候,先經(jīng)過路由,根據(jù)用戶的id或者ip,每次都訪問指定的服務(wù)器節(jié)點(diǎn)。
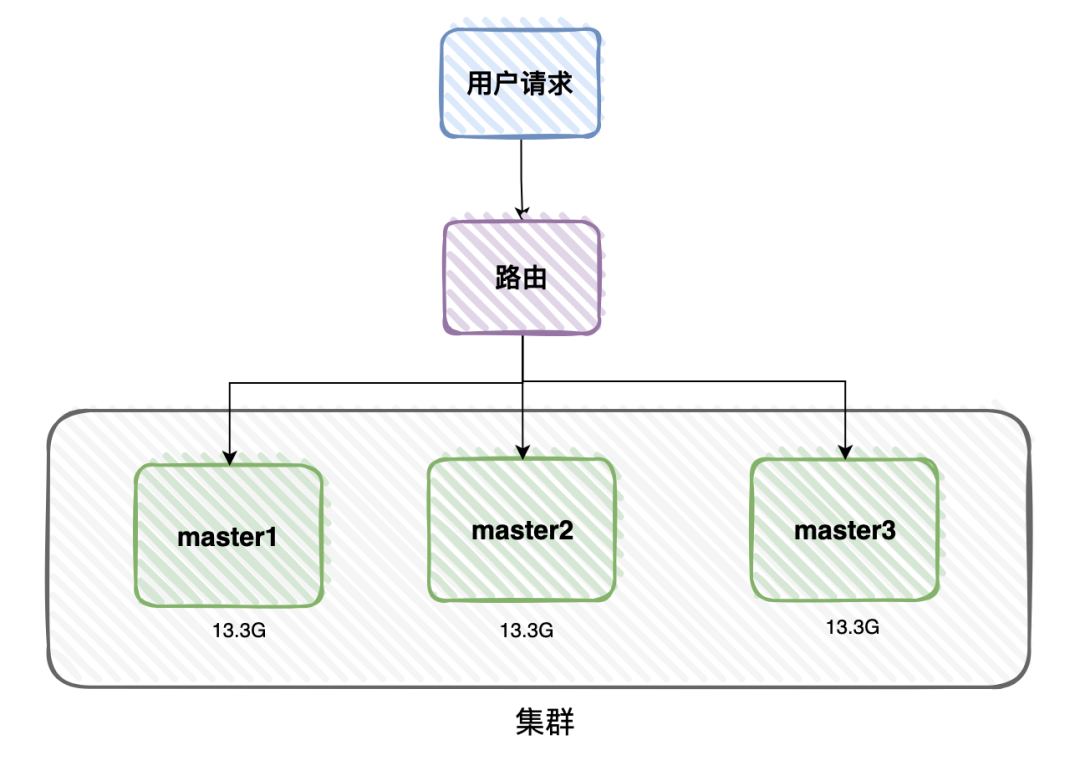
這用就構(gòu)成了一個(gè)集群。
但這樣有風(fēng)險(xiǎn),為了防止其中一個(gè)master服務(wù)器節(jié)點(diǎn)掛掉,導(dǎo)致部分用戶的緩存訪問不了,還需要對(duì)數(shù)據(jù)做備份。
這樣每一個(gè)master,都需要有一個(gè)slave,做數(shù)據(jù)備份。
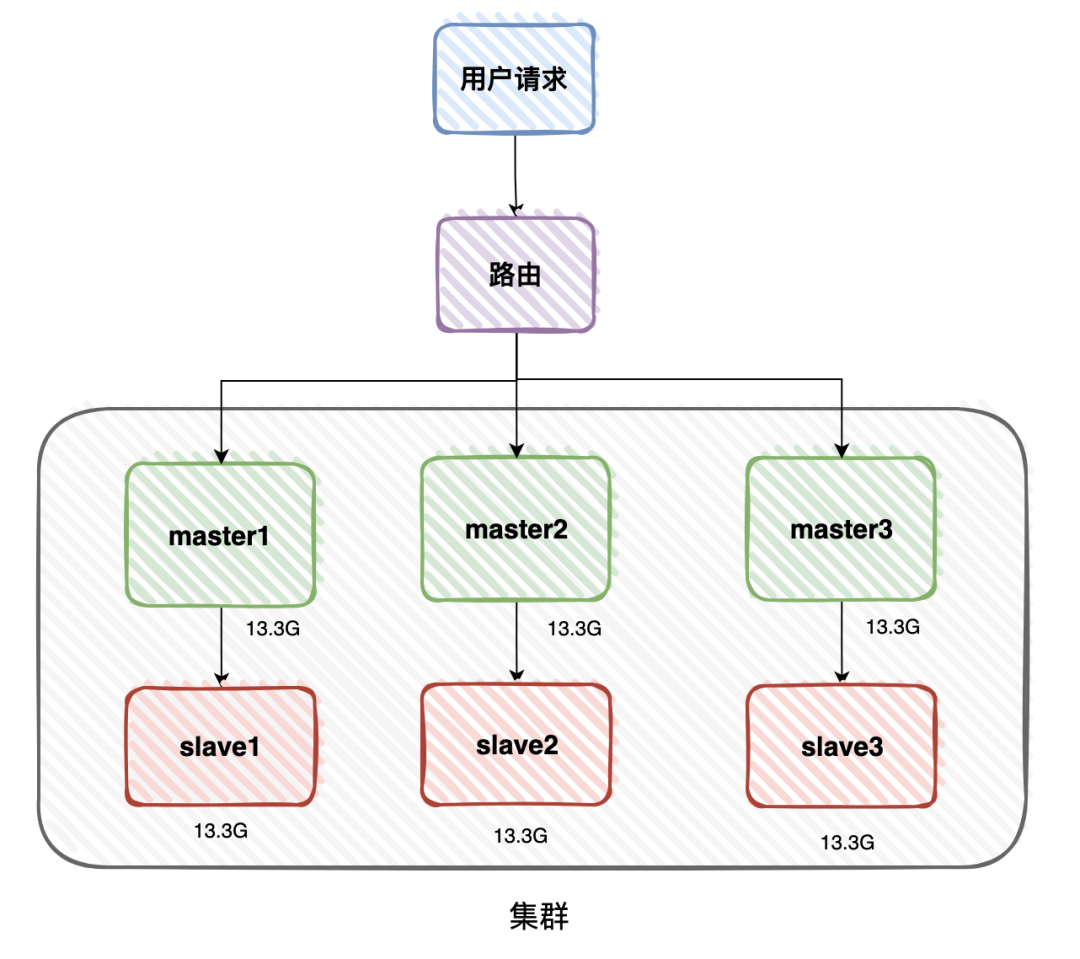
如果master掛了,可以將slave升級(jí)為新的master,而不影響用戶的正常使用。
12、負(fù)載均衡
如果我們的系統(tǒng)部署到了多臺(tái)服務(wù)器節(jié)點(diǎn)。那么哪些用戶的請(qǐng)求,訪問節(jié)點(diǎn)a,哪些用戶的請(qǐng)求,訪問節(jié)點(diǎn)b,哪些用戶的請(qǐng)求,訪問節(jié)點(diǎn)c?
我們需要某種機(jī)制,將用戶的請(qǐng)求,轉(zhuǎn)發(fā)到具體的服務(wù)器節(jié)點(diǎn)上。
這就需要使用負(fù)載均衡機(jī)制了。
在linux下有Nginx、LVS、Haproxy等服務(wù)可以提供負(fù)載均衡服務(wù)。
在SpringCloud微服務(wù)架構(gòu)中,大部分使用的負(fù)載均衡組件就是Ribbon、OpenFegin或SpringCloud Loadbalancer。
硬件方面,可以使用F5實(shí)現(xiàn)負(fù)載均衡。它可以基于交換機(jī)實(shí)現(xiàn)負(fù)載均衡,性能更好,但是價(jià)格更貴一些。
常用的負(fù)載均衡策略有:
- 輪詢:每個(gè)請(qǐng)求按時(shí)間順序逐一分配到不同的服務(wù)器節(jié)點(diǎn),如果服務(wù)器節(jié)點(diǎn)down掉,能自動(dòng)剔除。
- weight權(quán)重:weight代表權(quán)重默認(rèn)為1,權(quán)重越高,服務(wù)器節(jié)點(diǎn)被分配到的概率越大。weight和訪問比率成正比,用于服務(wù)器節(jié)點(diǎn)性能不均的情況。
- ip hash:每個(gè)請(qǐng)求按訪問ip的hash結(jié)果分配, 這樣每個(gè)訪客固定訪問同一個(gè)服務(wù)器節(jié)點(diǎn),它是解訣Session共享的問題的解決方案之一。
- 最少連接數(shù):把請(qǐng)求轉(zhuǎn)發(fā)給連接數(shù)較少的服務(wù)器節(jié)點(diǎn)。輪詢算法是把請(qǐng)求平均的轉(zhuǎn)發(fā)給各個(gè)服務(wù)器節(jié)點(diǎn),使它們的負(fù)載大致相同;但有些請(qǐng)求占用的時(shí)間很長,會(huì)導(dǎo)致其所在的服務(wù)器節(jié)點(diǎn)負(fù)載較高。這時(shí)least_conn方式就可以達(dá)到更好的負(fù)載均衡效果。
- 最短響應(yīng)時(shí)間:按服務(wù)器節(jié)點(diǎn)的響應(yīng)時(shí)間來分配請(qǐng)求,響應(yīng)時(shí)間短的服務(wù)器節(jié)點(diǎn)優(yōu)先被分配。
當(dāng)然還有其他的策略,在這里就不給大家一一介紹了。
13、限流
對(duì)于高并發(fā)系統(tǒng),為了保證系統(tǒng)的穩(wěn)定性,需要對(duì)用戶的請(qǐng)求量做限流。
特別是秒殺系統(tǒng)中,如果不做任何限制,絕大部分商品可能是被機(jī)器搶到,而非正常的用戶,有點(diǎn)不太公平。
所以,我們有必要識(shí)別這些非法請(qǐng)求,做一些限制。那么,我們?cè)撊绾维F(xiàn)在這些非法請(qǐng)求呢?
目前有兩種常用的限流方式:
- 基于nginx限流
- 基于redis限流
(1)對(duì)同一用戶限流
為了防止某個(gè)用戶,請(qǐng)求接口次數(shù)過于頻繁,可以只針對(duì)該用戶做限制。
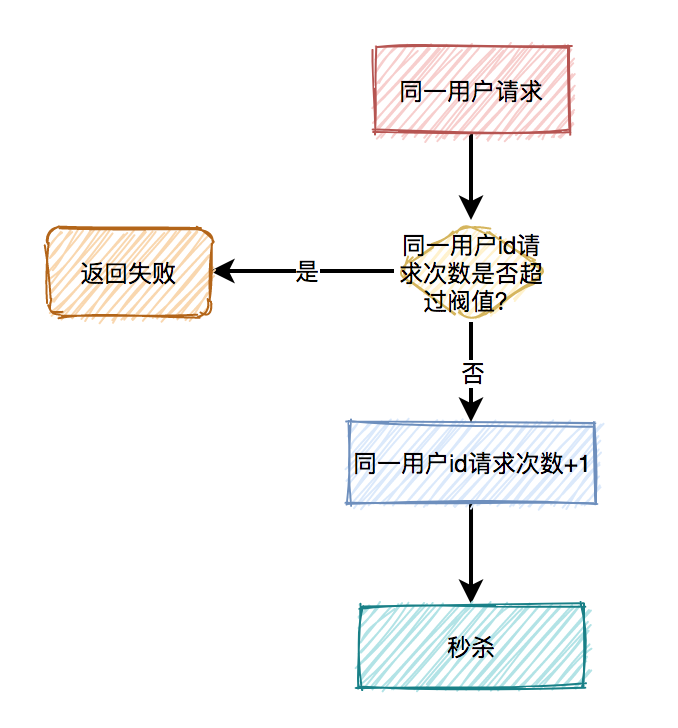
限制同一個(gè)用戶id,比如每分鐘只能請(qǐng)求5次接口。
(2)對(duì)同一ip限流
有時(shí)候只對(duì)某個(gè)用戶限流是不夠的,有些高手可以模擬多個(gè)用戶請(qǐng)求,這種nginx就沒法識(shí)別了。
這時(shí)需要加同一ip限流功能。
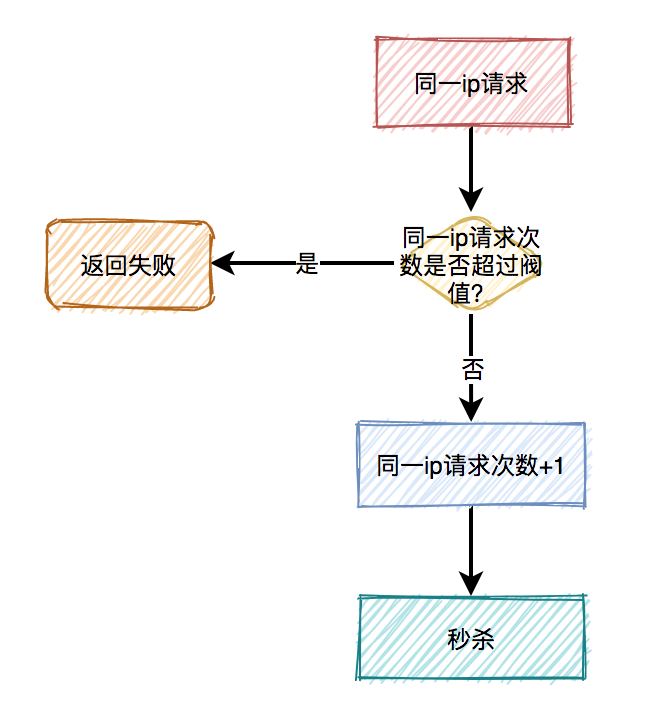
限制同一個(gè)ip,比如每分鐘只能請(qǐng)求5次接口。
但這種限流方式可能會(huì)有誤殺的情況,比如同一個(gè)公司或網(wǎng)吧的出口ip是相同的,如果里面有多個(gè)正常用戶同時(shí)發(fā)起請(qǐng)求,有些用戶可能會(huì)被限制住。
(3)對(duì)接口限流
別以為限制了用戶和ip就萬事大吉,有些高手甚至可以使用代理,每次都請(qǐng)求都換一個(gè)ip。
這時(shí)可以限制請(qǐng)求的接口總次數(shù)。
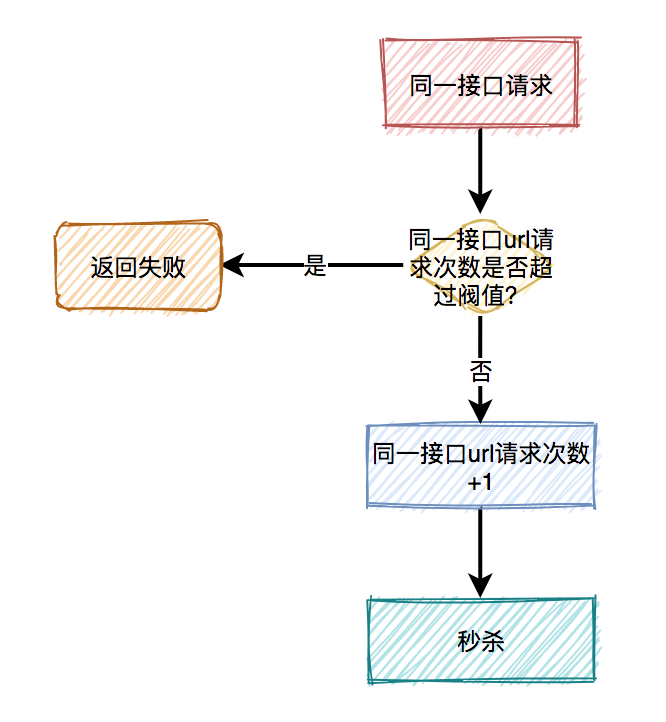
在高并發(fā)場(chǎng)景下,這種限制對(duì)于系統(tǒng)的穩(wěn)定性是非常有必要的。但可能由于有些非法請(qǐng)求次數(shù)太多,達(dá)到了該接口的請(qǐng)求上限,而影響其他的正常用戶訪問該接口。看起來有點(diǎn)得不償失。
(4)加驗(yàn)證碼
相對(duì)于上面三種方式,加驗(yàn)證碼的方式可能更精準(zhǔn)一些,同樣能限制用戶的訪問頻次,但好處是不會(huì)存在誤殺的情況。
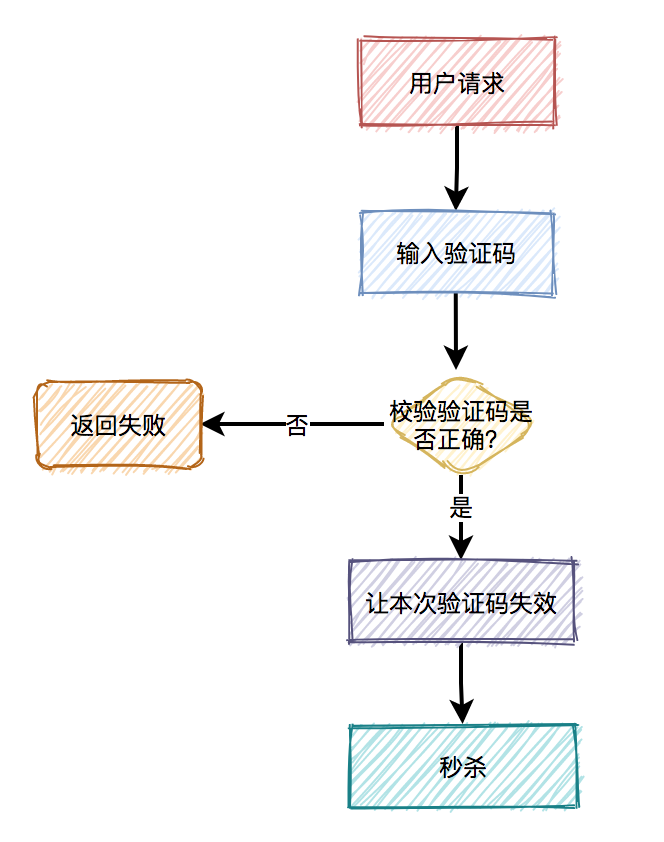
通常情況下,用戶在請(qǐng)求之前,需要先輸入驗(yàn)證碼。用戶發(fā)起請(qǐng)求之后,服務(wù)端會(huì)去校驗(yàn)該驗(yàn)證碼是否正確。只有正確才允許進(jìn)行下一步操作,否則直接返回,并且提示驗(yàn)證碼錯(cuò)誤。
此外,驗(yàn)證碼一般是一次性的,同一個(gè)驗(yàn)證碼只允許使用一次,不允許重復(fù)使用。
普通驗(yàn)證碼,由于生成的數(shù)字或者圖案比較簡(jiǎn)單,可能會(huì)被破解。優(yōu)點(diǎn)是生成速度比較快,缺點(diǎn)是有安全隱患。
還有一個(gè)驗(yàn)證碼叫做:移動(dòng)滑塊,它生成速度比較慢,但比較安全,是目前各大互聯(lián)網(wǎng)公司的首選。
14、服務(wù)降級(jí)
前面已經(jīng)說過,對(duì)于高并發(fā)系統(tǒng),為了保證系統(tǒng)的穩(wěn)定性,需要做限流。
但光做限流還不夠。
我們需要合理利用服務(wù)器資源,保留核心的功能,將部分非核心的功能,我們可以選擇屏蔽或者下線掉。
我們需要做服務(wù)降級(jí)。
我們?cè)谠O(shè)計(jì)高并發(fā)系統(tǒng)時(shí),可以預(yù)留一些服務(wù)降級(jí)的開關(guān)。
比如在秒殺系統(tǒng)中,核心的功能是商品的秒殺,對(duì)于商品的評(píng)論功能,可以暫時(shí)屏蔽掉。
在服務(wù)端的分布式配置中心,比如:apollo中,可以增加一個(gè)開關(guān),配置是否展示評(píng)論功能,默認(rèn)是true。
前端頁面通過服務(wù)器的接口,獲取到該配置參數(shù)。
如果需要暫時(shí)屏蔽商品評(píng)論功能,可以將apollo中的參數(shù)設(shè)置成false。
此外,我們?cè)谠O(shè)計(jì)高并發(fā)系統(tǒng)時(shí),還可以預(yù)留一些兜底方案。
比如某個(gè)分類查詢接口,要從redis中獲取分類數(shù)據(jù),返回給用戶。但如果那一條redis掛了,則查詢數(shù)據(jù)失敗。
這時(shí)候,我們可以增加一個(gè)兜底方案。
如果從redis中獲取不到數(shù)據(jù),則從apollo中獲取一份默認(rèn)的分類數(shù)據(jù)。
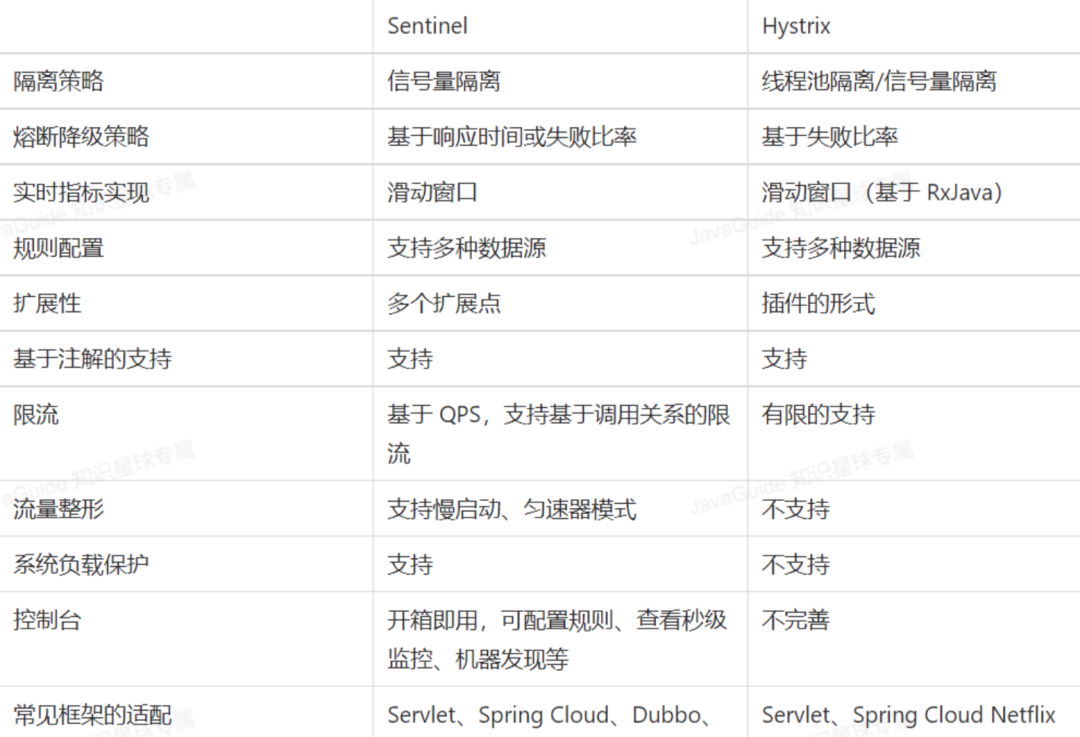
目前使用較多的熔斷降級(jí)中間件是:Hystrix 和 Sentinel。
- Hystrix是Netflix開源的熔斷降級(jí)組件。
- Sentinel是阿里中間件團(tuán)隊(duì)開源的一款不光具有熔斷降級(jí)功能,同時(shí)還支持系統(tǒng)負(fù)載保護(hù)的組件。
二者的區(qū)別如下圖所示:
15、故障轉(zhuǎn)移
在高并發(fā)的系統(tǒng)當(dāng)中,同一時(shí)間有大量的用戶訪問系統(tǒng)。
如果某一個(gè)應(yīng)用服務(wù)器節(jié)點(diǎn)處于假死狀態(tài),比如CPU使用率100%了,用戶的請(qǐng)求沒辦法及時(shí)處理,導(dǎo)致大量用戶出現(xiàn)請(qǐng)求超時(shí)的情況。
如果這種情況下,不做任何處理,可能會(huì)影響系統(tǒng)中部分用戶的正常使用。
這時(shí)我們需要建立故障轉(zhuǎn)移機(jī)制。
當(dāng)檢測(cè)到經(jīng)常接口超時(shí),或者CPU打滿,或者內(nèi)存溢出的情況,能夠自動(dòng)重啟那臺(tái)服務(wù)器節(jié)點(diǎn)上的應(yīng)用。
在SpringCloud微服務(wù)當(dāng)中,可以使用Ribbon做負(fù)載均衡器。
Ribbon是Spring Cloud中的一個(gè)負(fù)載均衡器組件,它可以檢測(cè)服務(wù)的可用性,并根據(jù)一定規(guī)則將請(qǐng)求分發(fā)至不同的服務(wù)節(jié)點(diǎn)。在使用Ribbon時(shí),需要注意以下幾個(gè)方面:
- 設(shè)置請(qǐng)求超時(shí)時(shí)間,當(dāng)請(qǐng)求超時(shí)時(shí),Ribbon會(huì)自動(dòng)將請(qǐng)求轉(zhuǎn)發(fā)到其他可用的服務(wù)上。
- 設(shè)置服務(wù)的健康檢查,Ribbon會(huì)自動(dòng)檢測(cè)服務(wù)的可用性,并將請(qǐng)求轉(zhuǎn)發(fā)至可用的服務(wù)上。
此外,還需要使用Hystrix做熔斷處理。
Hystrix是SpringCloud中的一個(gè)熔斷器組件,它可以自動(dòng)地監(jiān)測(cè)所有通過它調(diào)用的服務(wù),并在服務(wù)出現(xiàn)故障時(shí)自動(dòng)切換到備用服務(wù)。在使用Hystrix時(shí),需要注意以下幾個(gè)方面:
- 設(shè)置斷路器的閾值,當(dāng)故障率超過一定閾值后,斷路器會(huì)自動(dòng)切換到備用服務(wù)上。
- 設(shè)置服務(wù)的超時(shí)時(shí)間,如果服務(wù)在指定的時(shí)間內(nèi)無法返回結(jié)果,斷路器會(huì)自動(dòng)切換到備用服務(wù)上。到其他的能夠正常使用的服務(wù)器節(jié)點(diǎn)上。
16、異地多活
有些高并發(fā)系統(tǒng),為了保證系統(tǒng)的穩(wěn)定性,不只部署在一個(gè)機(jī)房當(dāng)中。
為了防止機(jī)房斷電,或者某些不可逆的因素,比如:發(fā)生地震,導(dǎo)致機(jī)房掛了。
需要把系統(tǒng)部署到多個(gè)機(jī)房。
我們之前的游戲登錄系統(tǒng),就部署到了深圳、天津和成都,這三個(gè)機(jī)房。
這三個(gè)機(jī)房都有用戶的流量,其中深圳機(jī)房占了40%,天津機(jī)房占了30%,成都機(jī)房占了30%。
如果其中的某個(gè)機(jī)房突然掛了,流量會(huì)被自動(dòng)分配到另外兩個(gè)機(jī)房當(dāng)中,不會(huì)影響用戶的正常使用。
這就需要使用異地多活架構(gòu)了。
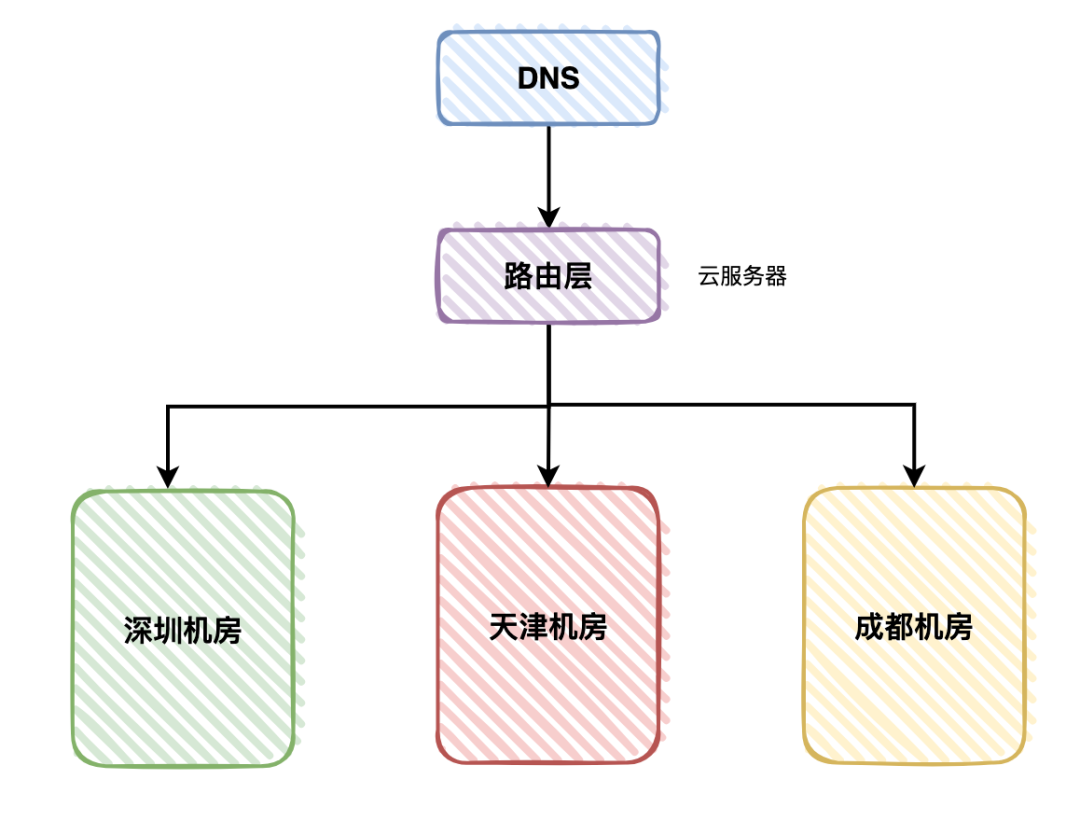
用戶請(qǐng)求先經(jīng)過第三方的DNS服務(wù)器解析,然后該用戶請(qǐng)求到達(dá)路由服務(wù)器,部署在云服務(wù)器上。
路由服務(wù)器,根據(jù)一定的算法,會(huì)將該用戶請(qǐng)求分配到具體的機(jī)房。
異地多活的難度是多個(gè)機(jī)房需要做數(shù)據(jù)同步,如何保證數(shù)據(jù)的一致性?
17、壓測(cè)
高并發(fā)系統(tǒng),在上線之前,必須要做的一件事是做壓力測(cè)試。
我們先要預(yù)估一下生產(chǎn)環(huán)境的請(qǐng)求量,然后對(duì)系統(tǒng)做壓力測(cè)試,之后評(píng)估系統(tǒng)需要部署多少個(gè)服務(wù)器節(jié)點(diǎn)。
比如預(yù)估有10000的qps,一個(gè)服務(wù)器節(jié)點(diǎn)最大支持1000pqs,這樣我們需要部署10個(gè)服務(wù)器節(jié)點(diǎn)。
但假如只部署10個(gè)服務(wù)器節(jié)點(diǎn),萬一突增了一些新的用戶請(qǐng)求,服務(wù)器可能會(huì)扛不住壓力。
因此,部署的服務(wù)器節(jié)點(diǎn),需要把預(yù)估用戶請(qǐng)求量的多一些,比如:按3倍的用戶請(qǐng)求量來計(jì)算。
這樣我們需要部署30個(gè)服務(wù)器節(jié)點(diǎn)。
壓力測(cè)試的結(jié)果跟環(huán)境有關(guān),在dev環(huán)境或者test環(huán)境,只能壓測(cè)一個(gè)大概的趨勢(shì)。
想要更真實(shí)的數(shù)據(jù),我們需要在pre環(huán)境,或者跟生產(chǎn)環(huán)境相同配置的專門的壓測(cè)環(huán)境中,進(jìn)行壓力測(cè)試。
目前市面上做壓力測(cè)試的工具有很多,比如開源的有:Jemter、LoaderRunnder、Locust等等。
收費(fèi)的有:阿里自研的云壓測(cè)工具PTS。
18、監(jiān)控
為了出現(xiàn)系統(tǒng)或者SQL問題時(shí),能夠讓我們及時(shí)發(fā)現(xiàn),我們需要對(duì)系統(tǒng)做監(jiān)控。
目前業(yè)界使用比較多的開源監(jiān)控系統(tǒng)是:Prometheus。
它提供了 監(jiān)控 和 預(yù)警 的功能。
架構(gòu)圖如下:
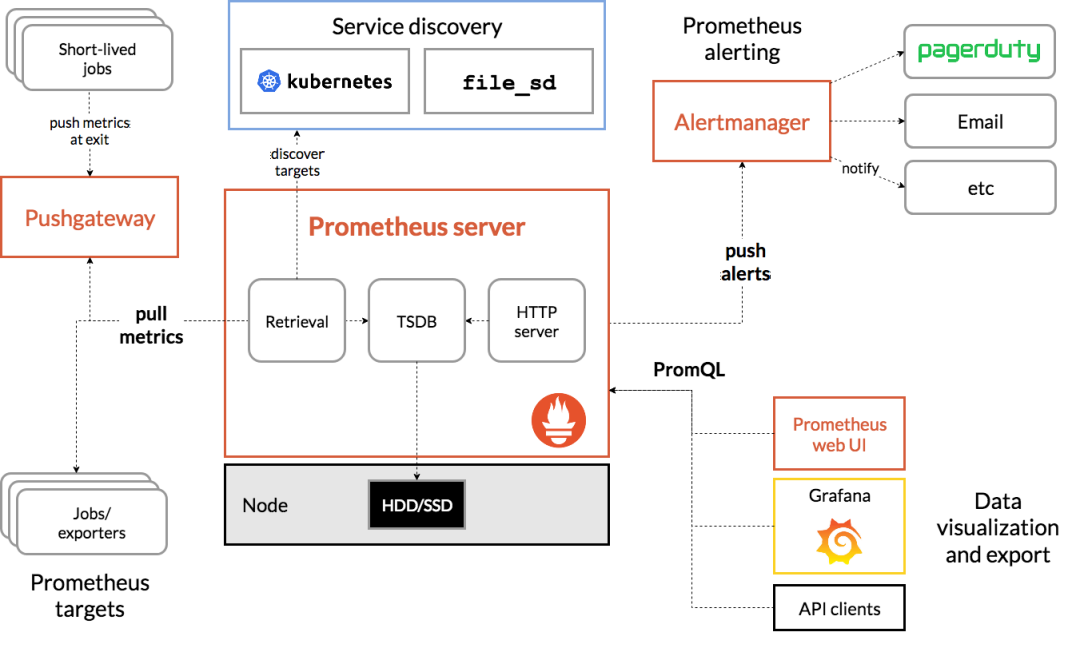
我們可以用它監(jiān)控如下信息:
- 接口響應(yīng)時(shí)間
- 調(diào)用第三方服務(wù)耗時(shí)
- 慢查詢sql耗時(shí)
- cpu使用情況
- 內(nèi)存使用情況
- 磁盤使用情況
- 數(shù)據(jù)庫使用情況
等等。。。
它的界面大概長這樣子:
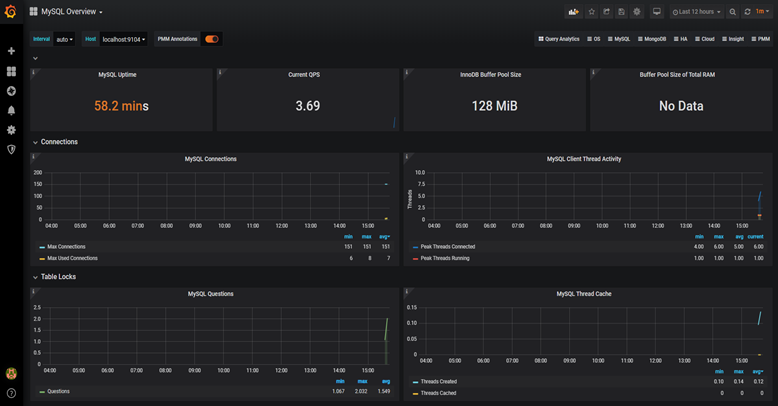
可以看到mysql當(dāng)前qps,活躍線程數(shù),連接數(shù),緩存池的大小等信息。
如果發(fā)現(xiàn)數(shù)據(jù)量連接池占用太多,對(duì)接口的性能肯定會(huì)有影響。
這時(shí)可能是代碼中開啟了連接忘了關(guān),或者并發(fā)量太大了導(dǎo)致的,需要做進(jìn)一步排查和系統(tǒng)優(yōu)化。
截圖中只是它一小部分功能,如果你想了解更多功能,可以訪問Prometheus的官網(wǎng):https://prometheus.io/
其實(shí),高并發(fā)的系統(tǒng)中,還需要考慮安全問題,比如:
- 遇到用戶不斷變化ip刷接口怎辦?
- 遇到用戶大量訪問緩存中不存在的數(shù)據(jù),導(dǎo)致緩存雪崩怎么辦?
- 如果用戶發(fā)起ddos攻擊怎么辦?
- 用戶并發(fā)量突增,導(dǎo)致服務(wù)器扛不住了,如何動(dòng)態(tài)擴(kuò)容?