OpenTelemetry入門看這一篇就夠了

這篇文章旨在讓您對 OpenTelemetry 有基本的了解。將涵蓋的主題有:
- 分布式追蹤
- OpenTelemetry 是什么?
- OpenTelemetry 檢測(自動和手動)
- OpenTelemetry 協議(OTLP)
- OpenTelemetry Collectors
- OpenTelemetry Collectors 部署模式
- OpenTelemetry 后端
- OpenTelemetry on Kubernetes
- OpenTelemetry Operator
- OpenTelemetry 示例應用程序
在本文結束時,您將了解如何使用 OpenTelemetry Operator 在應用程序中實現跟蹤,而無需更改任何代碼。
分布式追蹤
讓我們首先了解一下什么是分布式跟蹤以及我們為什么需要它。
為什么我們需要追蹤?
我們需要為什么分布式追蹤?為什么我們不能只使用指標和日志呢?假設你有一個如下所示的微服務架構。

現在想象一下來自客戶端的請求。
從上面的架構圖中我們可以看出,一個請求可能要經過幾十個或幾百個網絡調用。這使得我們很難知道請求所經過的整個路徑,如果只有日志和指標,那么故障排查會非常復雜。
當我們的應用出現問題時,我們需要解決很多問題。
- 我們如何找出根本原因?
- 我們如何監視它所經過的所有服務?
分布式跟蹤可以幫助查看整個請求過程中服務之間的交互,并可以讓我們深入了解系統中請求的整個生命周期。它幫助我們發現應用程序中的錯誤、瓶頸和性能問題。
追蹤從用戶與應用程序進行交互的一刻開始,我們應該能夠看到整個請求直到最后一層。
跟蹤數據(以 span 的形式)生成信息(元數據),可以幫助了解請求延遲或錯誤是如何發生的,以及它們對整個請求會產生什么樣的影響。

如果你想了解有關分布式跟蹤的更多信息,請閱讀分布式跟蹤初學者指南,了解如何監控微服務架構。
如何實現追蹤?
為了實現追蹤,我們需要做以下幾件事:
- 檢測我們的應用程序。
- 收集和處理數據。
- 存儲和可視化數據,以便我們可以查詢它。
為此我們可以使用兩個開源項目:OpenTelemetry 和 Jaeger。

OpenTelemetry 是什么?
OpenTelemetry 可以用于從應用程序收集數據。它是一組工具、API 和 SDK 集合,我們可以使用它們來檢測、生成、收集和導出遙測數據(指標、日志和追蹤),以幫助分析應用的性能和行為。

OpenTelemetry 是:
- 開源的
- 受到可觀測領域行業領導者的采用和支持
- 一個 CNCF 項目
- 與供應商無關的
OpenTelemetry 包括可觀測性的三個支柱:追蹤、指標和日志。(本文將重點關注追蹤)
- 分布式追蹤是一種跟蹤服務請求在分布式系統中從開始到結束的方法。
- 指標是對一段時間內活動的測量,以便了解系統或應用程序的性能。
- 日志是系統或應用程序在特定時間點發生的事件的文本記錄。
OpenTelemetry 與供應商無關
OpenTelemetry 提供了一個與供應商無關的可觀測性標準,因為它旨在標準化跟蹤的生成。通過 OpenTelemetry,我們可以將檢測埋點與后端分離。這意味著我們不依賴于任何工具(或供應商)。
我們不僅可以使用任何我們想要的編程語言,還可以挑選任何兼容的存儲后端,從而避免被綁定在特定的商業供應商上面。
開發人員可以檢測他們的應用程序,而無需知道數據將存儲在哪里。
OpenTelemetry 為我們提供了創建跟蹤數據的工具,為了獲取這些數據,我們首先需要檢測應用程序來收集數據。為此,我們需要使用 OpenTelemetry SDK。
檢測(埋點)
應用程序的檢測數據可以使用自動或手動(或混合)方式生成。 要使用 OpenTelemetry 檢測應用程序,可以前往訪問 OpenTelemetry 存儲庫,選擇適用于的應用程序的語言,然后按照說明進行操作。
自動檢測
使用自動檢測是一個很好的方式,因為它簡單、容易,不需要進行很多代碼更改。
如果你沒有必要的知識(或時間)來創建適合你應用程序量身的追蹤代碼,那么這種方法就非常合適。
當使用自動檢測時,將創建一組預定義的 spans,并填充相關屬性。
手動檢測
手動檢測是指為應用程序編寫特定的埋點代碼。這是向應用程序添加可觀測性代碼的過程。這樣做可以更有效地滿足你的需求,因為可以自己添加屬性和事件。這樣做的缺點是需要導入庫并自己完成所有工作。

傳播器
可以將 W3C tracecontext、baggage 和b3 等傳播器(Propagators)添加到配置中。
不同的傳播器定義特定的行為規范,以便跨進程邊界傳播帶上上下文數據。
- Trace Context:用于在 HTTP headers 中編碼 trace 數據,以便在不同的服務間傳遞這些數據。
- Baggage:用于在 span 之間傳遞鍵值對數據,例如用戶 ID、請求 ID 等。
- B3:用于在 HTTP headers 中編碼 trace 數據,以便在不同的服務間傳遞這些數據(主要用于 Zipkin 或其兼容的系統)。
采樣
采樣是一種通過減少收集和發送到后端的追蹤樣本數量來控制 OpenTelemetry 引入的噪聲和開銷的機制。
可以告訴 OpenTelemetry 根據要發送的追蹤/流量的數量執行采樣。(比如只采樣 10% 的追蹤數據)。

兩種常見的采樣技術是頭采樣和尾采樣。
OpenTelemetry 協議(OTLP)
OpenTelemetry 協議(OTLP)規范描述了遙測數據在遙測源、收集器和遙測后端之間的編碼、傳輸和傳遞機制。
每種語言的 SDK 都提供了一個 OTLP 導出器,可以配置該導出器來通過 OTLP 導出數據。然后,OpenTelemetry SDK 會將事件轉換為 OTLP 數據。
OTLP 是代理(配置為導出器)和收集器(配置為接收器)之間的通信。
OpenTelemetry Collectors
應用程序的遙測數據可以發送到 OpenTelemetry Collectors 收集器。

收集器是 OpenTelemetry 的一個組件,它接收遙測數據(span、metrics、logs 等),處理(預處理數據)并導出數據(將其發送到想要的通信后端)。

Receivers
接收器 Receivers 是數據進入收集器的方式,可以是推送或拉取。OpenTelemetry 收集器可以以多種格式接收遙測數據。

以下是接收器在端口 4317(gRPC) 和 4318(http) 上接受 OTLP 數據的配置示例:
otlp:
protocols:
http:
grpc:
endpoint: "0.0.0.0:4317"同樣下面的示例,它可以以 Jaeger Thrift HTTP 協議方式接收遙測數據。
jaeger: # Jaeger 協議接收器
protocols: # 定義接收器支持的協議
thrift_http: # 通過 Jaeger Thrift HTTP 協議接收數據
endpoint: "0.0.0.0:14278"Processors
一旦接收到數據,收集器就可以處理數據。處理器在接收和導出之間處理數據。處理器是可選的,但有些是推薦的。
比如 batch 處理器是非常推薦的。批處理器接收跨度、指標或日志,并將它們放入批次中。批處理有助于更好地壓縮數據,減少傳輸數據所需的傳出連接數量。該處理器支持基于大小和時間的批處理。
processors:
batch:需要注意的是配置處理器并不會啟用它。需要通過 service 部分的 pipelines 啟用。
service:
pipelines:
traces:
receivers: [jaeger]
processors: [batch]
exporters: [zipkin]Exporters
為了可視化和分析遙測數據,我們還需要使用導出器。導出器是 OpenTelemetry 的一個組件,也是數據發送到不同系統/后端的方式。
比如 console exporter 是一種常見的導出器,對于開發和調試任務非常有用,他會將數據打印到控制臺。
在 exporters 部分,可以添加更多目的地。例如,如果想將追蹤數據發送到 Grafana Tempo,只需添加如下所示的配置:
exporters:
logging:
otlp:
endpoint: "<tempo_endpoint>"
headers:
authorization: Basic <api_token>當然最終要生效也需要在 service 部分的 pipelines 中啟用。
service:
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [logging, otlp]OpenTelemetry 附帶了各種導出器,在 OpenTelemetry 收集器 Contrib 存儲庫中可以找到。
Extensions
擴展主要適用于不涉及處理遙測數據的任務。擴展的示例包括健康監控、服務發現和數據轉發。擴展是可選的。
擴展主要用于不涉及處理遙測數據的任務。比如健康監控、服務發現和數據轉發等。擴展是可選的。
extensions:
health_check:
pprof:
zpages:
memory_ballast:
size_mib: 512OpenTelemetry Collector 部署模式/策略
OpenTelemetry 收集器可以通過不同的方式進行部署,所以我們要考慮下如何部署它。具體選擇哪種策略取決于你的團隊和組織情況。
Agent 模式
在這種情況下,OpenTelemetry 檢測的應用程序將數據發送到與應用程序一起駐留的(收集器)代理。然后,該代理程序將接管并處理所有來自應用程序的追蹤數據。
收集器可以通過 sidecar 方式部署為代理,sidecar 可以配置為直接將數據發送到存儲后端。

Gateway 模式
還可以決定將數據發送到另一個 OpenTelemetry 收集器,然后從(中心)收集器進一步將數據發送到存儲后端。在這種配置中,我們有一個中心的 OpenTelemetry 收集器,它使用 deployment 模式部署,具有許多優勢,如自動擴展。

使用中心收集器的一些優點是:
- 消除對團隊的依賴
- 強制執行批處理、重試、加密、壓縮的配置/策略
- 在中心位置進行身份驗證
- 豐富的元數據信息
- 進行抽樣決策
- 通過 HPA 進行擴展
部署模式總結
下面我們總結下常見的一些部署策略。
基本版 - 客戶端使用 OTLP 進行檢測,將數據發送到一組收集器。

可以將數據發送到多個導出器。

在 Kubernetes 上部署 OpenTelemetry Collector 時可以使用的模式。
sidecar 模式:

代理作為 sidecar,其中使用 OpenTelemetry Collector 將容器添加到工作負載 Pod。然后,該實例被配置為將數據發送到可能位于不同命名空間或集群中的外部收集器。
daemonset 模式:
Agent 作為 DaemonSet,這樣我們每個 Kubernetes 節點就有一個代理 pod。

負載均衡 - 基于 trace id 的負載均衡:


多集群 - 代理、工作負載和控制平面收集器:

多租戶模式
兩個租戶,每個租戶都有自己的 Jaeger。


信號模式
兩個收集器,每個收集器對應一種遙測數據類型。


OpenTelemetry 后端
OpenTelemetry 收集器并不提供自己的后端,所以可以使用任何供應商或開源產品!
盡管 OpenTelemetry 不提供自己的后端,但通過使用它,我們不會依賴于任何工具或供應商,因為它與供應商無關。我們不僅可以使用我們想要的任何編程語言,而且還可以選擇存儲后端,并且只需配置另一個導出器即可輕松切換到另一個后端/供應商。
為了可視化和分析遙測數據,我們只需要在 OpenTelemetry 采集器種配置一個導出器。
比如 Jaeger 就是一個非常流行的用于分析和查詢數據的開源產品。

我們可以在 OpenTelemetry 收集器中配置 Jaeger 導出器,以便將數據發送到 Jaeger。
exporters:
jaeger:
endpoint: "http://localhost:14250"OpenTelemetry on Kubernetes
在 Kubernetes 上使用 OpenTelemetry,主要就是部署 OpenTelemetry 收集器。我們建議使用 OpenTelemetry Operator 來部署,因為它可以幫助我們輕松部署和管理 OpenTelemetry 收集器,還可以自動檢測應用程序。
部署
這里我們使用 Helm Chart 來部署 OpenTelemetry Operator,首先添加 Helm Chart 倉庫:
$ helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
$ helm repo update默認情況下會部署一個準入控制器,用于驗證 OpenTelemetry Operator 的配置是否正確,為了使 APIServer 能夠與 Webhook 組件進行通信,Webhook 需要一個由 APIServer 配置為可信任的 TLS 證書。
為了簡單我們這里直接使用自動生成簽名證書的方式,使用下面的命令一鍵安裝 OpenTelemetry Operator:
$ helm upgrade --install --set admissionWebhooks.certManager.enabled=false --set admissionWebhooks.certManager.autoGenerateCert=true opentelemetry-operator open-telemetry/opentelemetry-operator --namespace kube-otel --create-namespace正常部署完成后可以看到對應的 Pod 已經正常運行:
$ kubectl get pods -n kube-otel -l app.kubernetes.io/name=opentelemetry-operator
NAME READY STATUS RESTARTS AGE
opentelemetry-operator-6f77dc895c-4wn8z 2/2 Running 0 33s此外還會自動為我們添加兩個 OpenTelemetry 相關的 CRD:
$ kubectl get crd |grep opentelemetry
instrumentations.opentelemetry.io 2023-09-05T03:23:28Z
opentelemetrycollectors.opentelemetry.io 2023-09-05T03:23:28Z

到這里 OpenTelemetry Operator 就部署完成了。
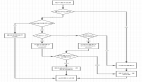
然后我們這里選擇使用中心 OpenTelemetry 收集器,并讓其他 OpenTelemetry 代理將數據發送到該收集器。從代理接收的數據將在此收集器上進行處理,并通過導出器發送到存儲后端。整個工作流如下圖所示:


創建一個如下所示的 OpenTelemetryCollector 實例對象:
# central-collector.yaml
apiVersion: opentelemetry.io/v1alpha1
kind: OpenTelemetryCollector
metadata:
name: simplest
spec:
config: |
receivers:
otlp:
protocols:
grpc:
http:
processors:
memory_limiter:
check_interval: 1s
limit_percentage: 75
spike_limit_percentage: 15
batch:
send_batch_size: 10000
timeout: 10s
exporters:
logging:
otlp:
endpoint: "<tempo_endpoint>"
headers:
authorization: Basic <api_token> # echo -n "<your user id>:<your api key>" | base64
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [logging, otlp]在這里 OpenTelemetry Collector 通過 grpc 和 http 兩種協議來接收遙測數據,并通過日志記錄導出和 Grafana Tempo 來記錄這些 Span,這會將 Span 寫入接收 Span 的 OpenTelemetry Collector 實例的控制臺和 Grafana Tempo 后端去。
然后我們將使用 Sidecar 模式部署 OpenTelemetry 代理。該代理會將應用程序的追蹤發送到我們的中心(網關)OpenTelemetry 收集器。
# sidecar.yaml
apiVersion: opentelemetry.io/v1alpha1
kind: OpenTelemetryCollector
metadata:
name: sidecar
spec:
mode: sidecar
config: |
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
exporters:
logging:
otlp:
endpoint: "<path_to_central_collector>.<namespace>:4317"
service:
telemetry:
logs:
level: "debug"
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [logging, otlp]自動檢測
OpenTelemetry Operator 可以注入和配置 OpenTelemetry 自動檢測庫。目前支持 DotNet、Java、NodeJS、Python 和 Golang(需要手動開啟)。
要使用自動檢測,需要為 SDK 和檢測配置添加一個 Instrumentation 資源。比如對于 Java 應用程序,配置如下。
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: java-instrumentation
spec:
propagators:
- tracecontext
- baggage
- b3
sampler:
type: always_on
java:如果是 Python 應用程序,配置如下:
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: python-instrumentation
spec:
propagators:
- tracecontext
- baggage
- b3
sampler:
type: always_on
python:要啟用檢測,我們需要更新部署文件并向其添加注解。通過這種方式,我們告訴 OpenTelemetry Operator 將 sidecar 和 java 工具注入到我們的應用程序中。
annotations:
instrumentation.opentelemetry.io/inject-java: "true"
sidecar.opentelemetry.io/inject: "true"示例應用
這里我們將使用一個名為 Petclinic 的 Java 應用程序,這是一個使用 Maven 或 Gradle 構建的 Spring Boot 應用程序。該應用程序將使用 OpenTelemetry 生成數據。
對于 Java 應用,我們可以通過下載 OpenTelemetry 提供的 opentelemetry-javaagent 這個 jar 包來使用 OpenTelemetry 自動檢測應用程序。
只需要將這個 jar 包添加到應用程序的啟動命令中即可,比如:
java -javaagent:opentelemetry-javaagent.jar -jar target/*.jarJava 自動檢測使用可附加到任何 Java 8+ 應用程序的 Java 代理 JAR。它動態注入字節碼以從許多流行的庫和框架捕獲遙測數據。它可用于捕獲應用程序或服務“邊緣”的遙測數據,例如入站請求、出站 HTTP 調用、數據庫調用等。通過運行以上命令,我們可以對應用程序進行插樁,并生成鏈路數據,而對我們的應用程序沒有任何修改。
尤其是在 Kubernetes 環境中,我們可以使用 OpenTelemetry Operator 來注入和配置 OpenTelemetry 自動檢測庫,這樣連 javaagent 我們都不需要去手動注入了。
我們首先部署 Petclinic 應用程序。
apiVersion: apps/v1
kind: Deployment
metadata:
name: petclinic
spec:
selector:
matchLabels:
app: petclinic
template:
metadata:
labels:
app: petclinic
spec:
containers:
- name: app
image: cnych/spring-petclinic:latest然后我們為 Java 應用程序添加一個 Instrumentation 資源。
# java-instrumentation.yaml
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: java-instrumentation
spec:
propagators:
- tracecontext
- baggage
- b3
sampler:
type: always_on
java:
image: ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-java:latest為了啟用自動檢測,我們需要更新部署文件并向其添加注解。這樣我們可以告訴 OpenTelemetry Operator 將 sidecar 和 java-instrumentation 注入到我們的應用程序中。修改 Deployment 配置如下:
# petclinic.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: petclinic
spec:
selector:
matchLabels:
app: petclinic
template:
metadata:
labels:
app: petclinic
annotations:
instrumentation.opentelemetry.io/inject-java: "true"
sidecar.opentelemetry.io/inject: "sidecar"
spec:
containers:
- name: app
image: cnych/spring-petclinic:latest然后再創建一個 NodePort 類型的 Service 服務來暴露應用程序。
# petclinic-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: petclinic
spec:
selector:
app: petclinic
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 8080直接應用上面的資源清單即可:
$ kubectl apply -f central-collector.yaml
$ kubectl apply -f sidecar.yaml
$ kubectl apply -f java-instrumentation.yaml
$ kubectl apply -f petclinic.yaml
$ kubectl apply -f petclinic-svc.yaml正常部署完成后可以看到對應的 Pod 已經正常運行:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
petclinic-6fdd56f4d7-qfff7 2/2 Running 0 62s
simplest-collector-87d8bf9bf-dh8pl 1/1 Running 0 36m
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
petclinic NodePort 10.103.6.52 <none> 80:30941/TCP 46s
simplest-collector ClusterIP 10.102.131.126 <none> 4317/TCP,4318/TCP 17m
simplest-collector-headless ClusterIP None <none> 4317/TCP,4318/TCP 17m
simplest-collector-monitoring ClusterIP 10.98.65.171 <none> 8888/TCP 17m然后我們就可以通過 http://<node_ip>:30941 來訪問 Petclinic 應用程序了。
當我們訪問應用程序時,應用程序就將生成追蹤數據,并將其發送到我們的中心收集器。我們可以通過訪問 Grafana Tempo 來查看追蹤數據,同時也可以通過訪問中心收集器的控制臺來查看追蹤數據。因為我們在中心收集器中配置了日志記錄導出器和 Grafana Tempo 兩個導出器,當然也可以配置其他導出器。
$ kubectl logs -f petclinic-6fdd56f4d7-qfff7 -c otc-container
# ......
2023-09-10T04:11:41.164Z info TracesExporter {"kind": "exporter", "data_type": "traces", "name": "logging", "resource spans": 1, "spans": 76}
2023-09-10T04:12:11.012Z info TracesExporter {"kind": "exporter", "data_type": "traces", "name": "logging", "resource spans": 1, "spans": 3}
2023-09-10T04:12:16.221Z info TracesExporter {"kind": "exporter", "data_type": "traces", "name": "logging", "resource spans": 1, "spans": 23}
^C
$ kubectl logs -f simplest-collector-677f4779ff-x8h2m
# ......
2023-09-10T04:11:09.221Z info service/service.go:161 Everything is ready. Begin running and processing data.
2023-09-10T04:11:49.222Z info TracesExporter {"kind": "exporter", "data_type": "traces", "name": "logging", "resource spans": 1, "spans": 76}
2023-09-10T04:12:19.224Z info TracesExporter {"kind": "exporter", "data_type": "traces", "name": "logging", "resource spans": 2, "spans": 26}所以在 Grafana Tempo 中也可以看到對應的追蹤數據:

同樣如果你再添加一個 Jaeger 的導出器,那么你也可以在 Jaeger 中看到對應的追蹤數據。
如果在部署中遇到任何問題,我們可以通過查看應用程序和容器的日志來進行排查。
總結
在這篇文章中,我們演示了如何使用 OpenTelemetry Operator 在應用程序中實現追蹤,而無需更改任何代碼。
當然其中還有很多其他內容沒有涉及到,比如如何在 OpenTelemetry 中使用 Prometheus 來收集指標數據,如何在 OpenTelemetry 中使用 Loki 來收集日志數據等等,也包括一些采樣策略、傳播器、批處理器、手動檢測等等。
參考文檔
- https://medium.com/@magstherdev/opentelemetry-up-and-running-b4c58eaf8c05。
- https://medium.com/@magstherdev/opentelemetry-on-kubernetes-c167f024b35f。
- https://medium.com/@magstherdev/opentelemetry-in-action-fc61263c852。
- https://github.com/open-telemetry/opentelemetry-go-instrumentation。