













MySQL大表如何DDL,你學會了嗎?
大家好,我是藍胖子,mysql對大表(千萬級數據)的ddl語句,在生產上執行時一定要千萬小心,一不小心就有可能造成業務阻塞,數據庫io和cpu飆高的情況。今天我們就來看看如何針對大表執行ddl語句。
通過這篇文章,你能了解到下面的知識點。
傳統ddl 和online ddl的區別
mysql的ddl 經過了幾個版本的演進,Online DDL這個特性是在MySQL5.6.7開始支持,在此之前mysql執行ddl語句時,會生成新表,然后將原表數據復制到新表,整個過程是會阻塞DML語句的。
而online ddl 定義其實就是在執行ddl語句時,不會阻塞dml語句,那么我們就稱這樣的ddl為online ddl。
ddl 的算法參數選項又分為 copy, Inplace, INSTANT ,其中copy就是之前傳統ddl執行的過程,會阻塞dml語句。Inplace, INSTANT 算法執行期間 都是可以執行DML語句的,所以我們稱使用這兩種算法的ddl語句為online ddl。
!! ???? 但需要注意的是,并不是所有的ddl操作都支持這兩種算法,具體什么ddl操作類型支持什么算法需要去查閱官方文檔。
INSTANT 算法是mysql8.0 以后新加的,它能在秒級別對千萬級別的大表進行加字段操作,至于其他ddl 語句類型是不是也支持INSTANT 算法,需要去看下官網了,由于我們線上還是使用的mysql5.7 ,所以我還是會給予mysql5.7去進行分析。
在mysql5.7中,例如我們執行下面的ddl 加字段的語句,
ALTER TABLE tbl_name ADD COLUMN column_name column_definitionmysql會去判斷當前執行的ddl語句類型能不能用online ddl inplace 方式,如果能用,那么它就會采用。
使用Inplace算法的ddl語句,執行過程分為3個階段,
階段1: Initialization初始化
在初始化階段,服務器將考慮存儲引擎功能、語句中指定的操作以及用戶指定的ALGORITHM和LOCK選項,確定操作期間允許多少并發性。在此階段,使用一個可升級MDL讀鎖來保護當前表定義。
階段2:Execution執行
如果評估階段發現ddl語句不能使用inplace算法,則會將mdl讀鎖升級為排它鎖,阻塞DML語句執行。并且,這個階段,會真正的執行ddl語句。
階段3:Commit Table Definition 提交表定義
在提交表定義階段,MDL讀鎖升級為MDL排他鎖,以排除舊表定義并提交新表定義。一旦授予,獨占MDL鎖的持續時間就會很短。
可以看到如果使用inplcae 算法,只有在任務提交階段(時間很短), ddl才會阻塞dml語句,因為任務提交階段會持有MDL 排他鎖,而DML 語句執行時需要獲取MDL讀鎖,所以在此期間,DML語句會被阻塞。
具體哪些ddl操作類型支持Inplace 算法,可以查看官方文檔鏈接,比如下面的mysql5.7的文檔
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-operations.html如下圖所示,可以發現mysql5.7對加字段的ddl 支持inplace 算法,不過執行期間需要rebuild table即建立新表,并且運行并發的dml語句執行。但是改變字段數據類型ddl,則只能按copy算法進行執行。
!! inplace 算法不是不會產生數據的復制,只是復制期間,不會阻塞dml語句的執行。
 圖片
圖片
mysql ddl 的陷阱
online ddl機制是否一定不會阻塞業務?
接著我們來看下ddl時使用inplcae 算法(online ddl)是不是一定不會阻塞業務,其實答案是顯而易見的,業務也有可能阻塞,因為online ddl 在提交表定義階段是會獲取MDL排他鎖的,如果有其他事務獲取了MDL讀鎖,那么online ddl 語句也會阻塞住,從而導致發生在ddl語句執行時間點后面的那些需要獲取MDL鎖的sql阻塞掉。具體的操作例子可以查看mysql官方給出的一個例子,
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-performance.html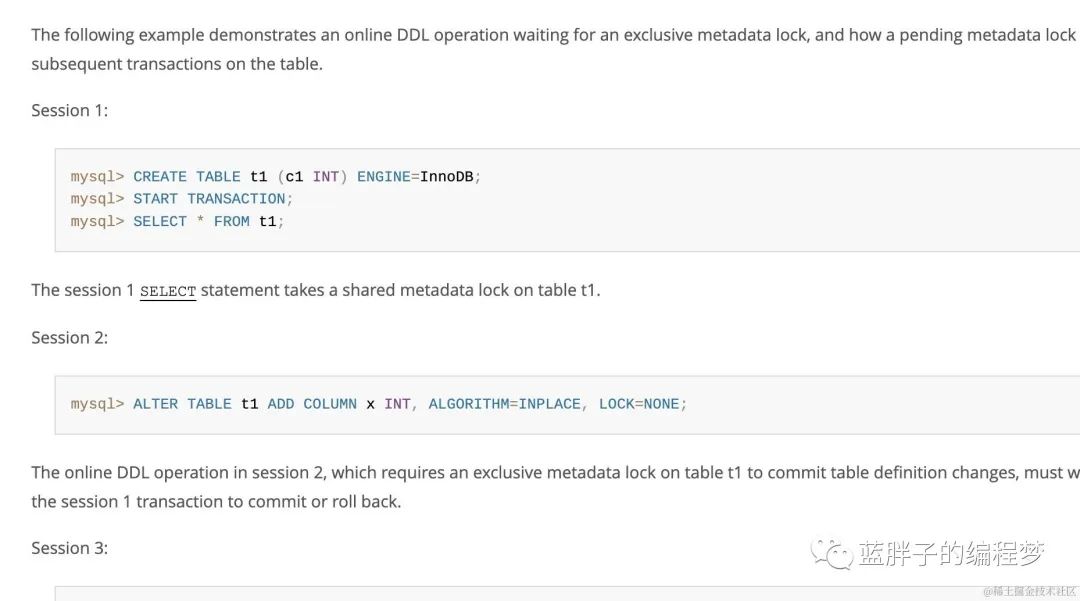
ddl 過程中從庫的延遲性
ddl的第二個陷阱是要注意從庫的延遲性,比如mysql5.7加新列,雖然默認可以使用inplace算法來讓dml語句不阻塞,但是建立新列還是需要表的rebuild操作,如果是大表,整個過程還是很慢的,如果從庫只開啟了一個線程去執行主從復制,就會導致主從庫間出現極大的延遲。
解決辦法是開啟并行復制,可以用下面的語句在從庫上執行,查看從庫是否開啟了并行復制
SHOW VARIABLES LIKE 'slave_parallel_workers';online ddl Duplicate entry...錯誤
雖然使用inplace算法的ddl (online ddl) 可以不阻塞業務操作,但是在大表上執行時,由于ddl過程比較長,還是有可能會出現Duplicate entry 錯誤。下面我來介紹下它出現的場景,比如一張幾千萬的表,里面有一個唯一鍵,在add column ddl期間,對表進行插入,并且插入的值剛好就觸發了唯一鍵約束。那么最后ddl再快完成的時候就會出現這個錯誤。
這是由于add column ddl期間,會發生表的rebuild,相當于新建一個臨時表然后對舊表進行拷貝,但是ddl期間還是允許業務修改,插入數據,所以online ddl將執行期間新的修改記錄到一個叫做row_log的對象里,在ddl最后階段,將mdl鎖升級為排它鎖,然后將row_log對象中的數據和新表的數據進行合并,這樣就達到了ddl期間兼容dml操作的目的。
但是應用row log的過程是不允許報錯,如果期間發生了報錯就會導致ddl回滾,因為在ddl期間,記錄了相同唯一鍵的數據,所以在應用row log的時候,產生了報錯。
官方也給出了online ddl 報錯的場景,鏈接如下
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-failure-conditions.html其實我認為本質原因是mysql5.7 執行add column 的ddl時間還是太長了,在這么長時間里可能就會發生業務對相同唯一鍵的插入操作,如果能縮短ddl執行時間應該就能很大程度避免這種問題。
mysql8.0 在add column 時可以采用instance 算法,能達到秒級別的加新字段的操作,理論上可以避免這個錯誤。
如果不是mysql8.0 ,又想對千萬級的大表添加字段,又要避免Duplicate entry 錯誤,那么可以使用pt-online-schema-change這個工具。
pt-online-schema-change 工具進行字段添加
下面我就來簡單的介紹下pt-online-schema-change,它對表結構的修改原理是創建一張新表(擁有最新的表定義),然后在舊表上創建delete,update,insert的觸發器,來對增量數據進行更新,對舊表數據采取insert ignore 新表 select 老表 LOCK S 的方式進行分塊拷貝,最后拷貝完成后,在一個事務里對舊表進行刪除,新表進行重命名,這樣就完成了對表結構的變更。
同時在變更期間,你能夠通過下面的參數控制從庫延遲
- --max-lag
默認1s
檢查從庫延遲的時間,如果超過,則停止copy data,休息--check-interval秒后,再重新開始copy數據
查看通過延遲時間,是通過從庫show slave status,查看Seconds_Behind_Master
如果指定--check-slave-lag,該工具只檢查該服務器的延遲,而不是所有服務器。
- --check-interval
- 從庫延遲超過指定的--max-lag,中斷copy data休息的時間
- 默認為1s
下面是pt-online-schema-change 語句執行的完整示例,它同時會列出拷貝過程完成的百分比。
pt-online-schema-change --alter "add pkg_source tinyint(2) default 0 not null;" h=主機ip,P=端口,p=密碼,u=用戶名,D=數據庫名,t=表名 --recursion-method=none --execute --statistics如果你的ddl需要拷貝表,那么用pt-online-schema-change 工具再合適不過了。






























