正則表達式不用背
正則表達式是一個強大的文本匹配工具。但是,對于初學者來說,眾多的符號和規則可能讓人難以理解。其實,你不需要記住所有的正則表達式語法!本文將分享一些簡單而實用的技巧,幫助理解正則表達式的核心概念,輕松使用正則表達式!

基礎入門
概念
正則表達式(Regular Expression,在代碼中常簡寫為regex、regexp或RE)使用單個字符串來描述、匹配一系列符合某個句法規則的字符串搜索模式。搜索模式可用于文本搜索和文本替換。它用一系列字符定義搜索模式。
正則表達式的用途有很多,比如:
- 表單輸入驗證;
- 搜索和替換;
- 過濾大量文本文件(如日志)中的信息;
- 讀取配置文件;
- 網頁抓取;
- 處理具有一致語法的文本文件,例如 CSV。
創建
正則表達式的語法如下:
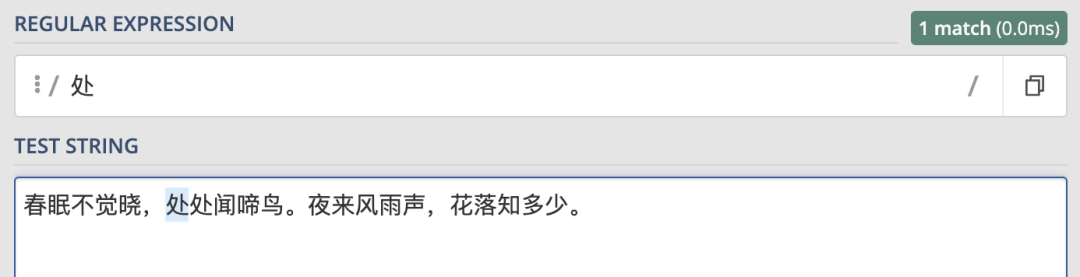
/正則表達式主體/修飾符(可選)先來看一個最基本的正則表達式:/處/,它只匹配到了字符串中的第一個“處”:
這里,正則表達式的主體就是“處”,沒有使用修飾符,我們會在后面來介紹正則表達式的修飾符。
創建正則表達式的方式有兩種:
- 字面量:正則表達式直接放在/ /之中:
const rex = /pattern/;- 構造函數:RegExp 對象表示正則表達式的一個實例:
const rex = new RegExp("pattern");這兩種方法的一大區別是對象的構造函數允許傳遞帶引號的表達式,通過這種方式就可以動態創建正則表達式。
通過這兩種方法創建出來的 Regex 對象都具有相同的方法和屬性:
let RegExp1 = /a|b/
let RegExp2 = new RegExp('a|b')
console.log(RegExp1) // 輸出結果:/a|b/
console.log(RegExp2) // 輸出結果:/a|b/RegExp 實例
實例方法
RegExp 實例置了test()和exec() 這兩個方法來校驗正則表達式。下面來分別看一下這兩個方法。
(1)test()
test()用于檢測一個字符串是否匹配某個模式,如果字符串中含有匹配的文本,則返回 true,否則返回 false。
const regex1 = /a/ig;
const regex2 = /hello/ig;
const str = "Action speak louder than words";
console.log(regex1.test(str)); // true
console.log(regex2.test(str)); // false(2)exec()
exec()用于檢索字符串中的正則表達式的匹配。該函數返回一個數組,其中存放匹配的結果。如果未找到匹配,則返回值為 null。
const regex1 = /a/ig;
const regex2 = /hello/ig;
const str = "Action speak louder than words";
console.log(regex1.exec(str)); // ['A', index: 0, input: 'Action speak louder than words', groups: undefined]
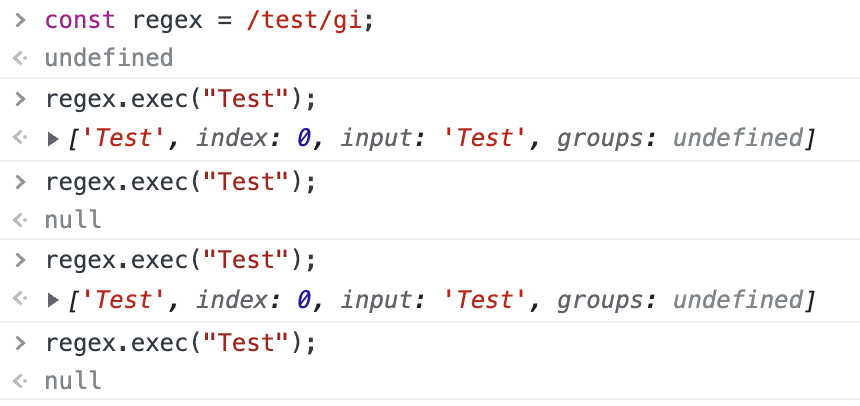
console.log(regex2.exec(str)); // null在當在全局正則表達式中使用 exec 時,每隔一次就會返回null,如圖:
這是怎么回事呢?MDN 的解釋如下:
在設置了 global 或 sticky 標志位的情況下(如 /foo/g or /foo/y),JavaScript RegExp 對象是有狀態的。他們會將上次成功匹配后的位置記錄在 lastIndex 屬性中。使用此特性,exec() 可用來對單個字符串中的多次匹配結果進行逐條的遍歷(包括捕獲到的匹配),而相比之下, String.prototype.match() 只會返回匹配到的結果。
為了解決這個問題,我們可以在運行每個exec命令之前將lastIndex賦值為 0:

實例屬性
RegExp 實例還內置了一些屬性,這些屬性可以獲知一個正則表達式的各方面的信息,但是用處不大。
屬性 | 描述 |
| 布爾值,表示是否設置了g標志 |
| 布爾值,表示是否設置了i標志 |
| 整數,表示開始搜索下一個匹配項的字符位置,從0算起 |
| 布爾值,表示是否設置了m標志 |
| 正則表達式的字符串表示,按照字面量形式而非傳入構造函數重大的字符串模式匹配 |
模式匹配
關于正則表達式最復雜的地方就是如何編寫正則規則了,下面就來看如何編寫正則表達式。
修飾符
正則表達式的修飾符是一種可以在正則表達式模式中添加的標記,用于修改搜索模式的行為。這些修飾符通常以單個字符形式出現在正則表達式的末尾,并且可以通過在正則表達式模式前添加該字符來啟用修飾符。
常見的修飾符如下:
- g:表示全局模式,即運用于所有字符串;
- i:表示不區分大小寫,即匹配時忽略字符串的大小寫;
- m:表示多行模式,強制 $ 和 ^ 分別匹配每個換行符。
最開始的例子中,字符串中有兩個“處”,但是只匹配到了一個。這是因為正則表達式默認匹配第一個符合條件的字符。如果想要匹配所有符合條件的字符,就可以使用 g 修飾符:
/處/g這樣就匹配到了所有符合條件的字符:
 圖片
圖片
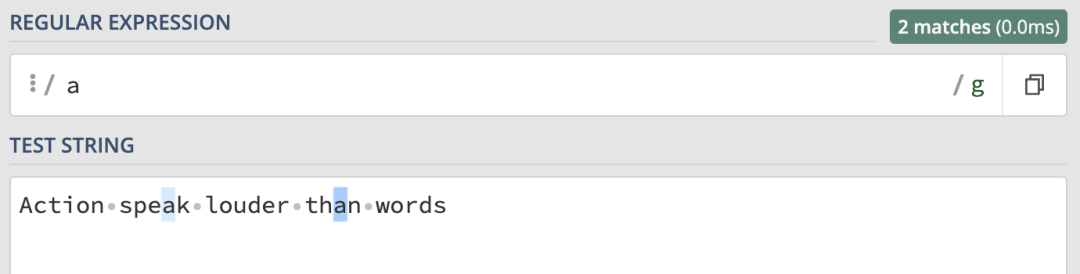
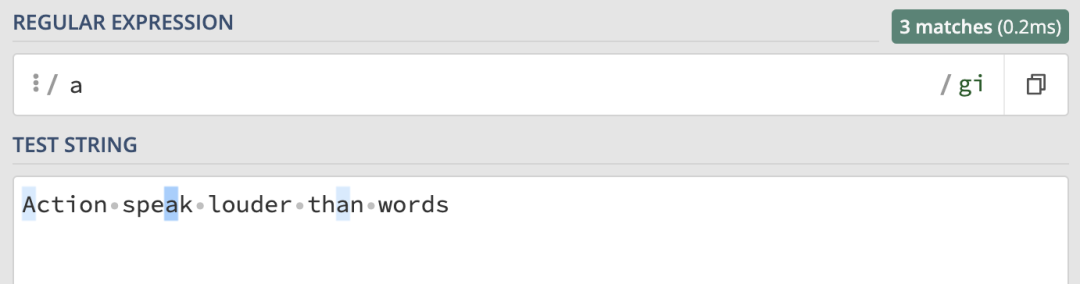
當需要匹配引英文字符串,并且忽略字符串的字母大小寫時,i 修飾符就派上用場了。先來看下面的表達式:
/a/g在進行匹配時,它匹配到了字符串中所有的 a 字符。但是最開始的 A 是沒匹配到的,因為兩者大小寫不一致:
那我們來添加上 i 修飾符:
/a/gi這時所有的 a 都被匹配到了,無論是大寫還是小寫,總共匹配到了三個 a:
 還有一個小疑問, 如果是對象構造函數的方式來構造正則表達式使,如何添加這些修飾符呢?其實很簡單,只要將修飾符作為第二個參數傳遞給 構造函數就可以了:
還有一個小疑問, 如果是對象構造函數的方式來構造正則表達式使,如何添加這些修飾符呢?其實很簡單,只要將修飾符作為第二個參數傳遞給 構造函數就可以了:
let regExp = new RegExp('[2b|^2b]', 'gi')
console.log(regExp) // 輸出結果:/[2b|^2b]/gi字符集合
如果我們想匹配 bat、cat 和 fat 這種類型的字符串該怎么辦?可以通過使用字符集合來做到這一點,用 [] 表示,它會匹配包含的任意一個字符。這里就可以使用/[bcf]at/ig:
 圖片
圖片
可以看到,這里匹配到了字符串中的 bat、cat、fat。因為我們使用了 g 修飾符,所以匹配到了三個結果。
當然,字符集也可以用來匹配數字:
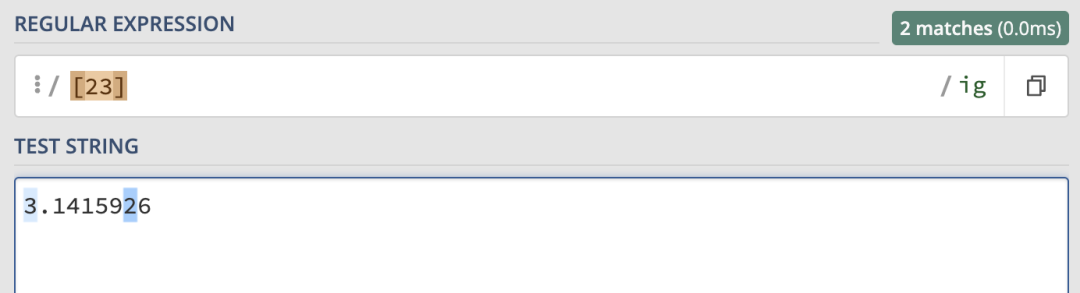
字符范圍
如果我們想要在字符串中匹配所有以 at 結尾的單詞,最直接的方式是使用字符集,并在其中提供所有的字母。對于這種在一個范圍中的字符, 就可以直接定義字符范圍,用-表示。它用來匹配指定范圍內的任意字符。這里就可以使用/[a-z]at/ig:
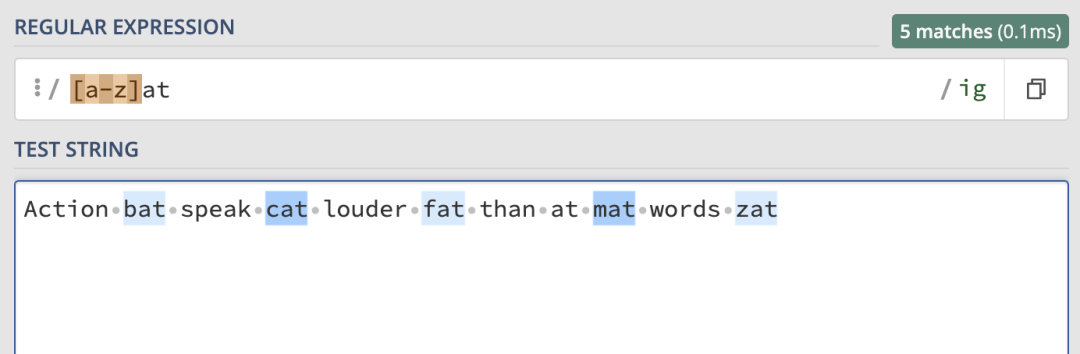 可以看到,正則表達式按照我們的預期匹配了。
可以看到,正則表達式按照我們的預期匹配了。
常見的使用范圍的方式如下:
- 部分范圍:[a-f],匹配 a 到 f 的任意字符;
- 小寫范圍:[a-z],匹配 a 到 z 的任意字符;
- 大寫范圍:[A-Z],匹配 A 到 Z 的任意字符;
- 數字范圍:[0-9],匹配 0 到 9 的任意字符;
- 符號范圍:[#$%&@];
- 混合范圍:[a-zA-Z0-9],匹配所有數字、大小寫字母中的任意字符。
數量字符
如果想要匹配三個字母的單詞,根據上面我們學到的字符范圍,可以這樣來寫:
[a-z][a-z][a-z]這里我們匹配的三個字母的單詞,那如果想要匹配10個、20個字母的單詞呢?難道要一個個來寫范圍嗎?有一種更好的方法就是使用花括號{}來表示,來看例子:
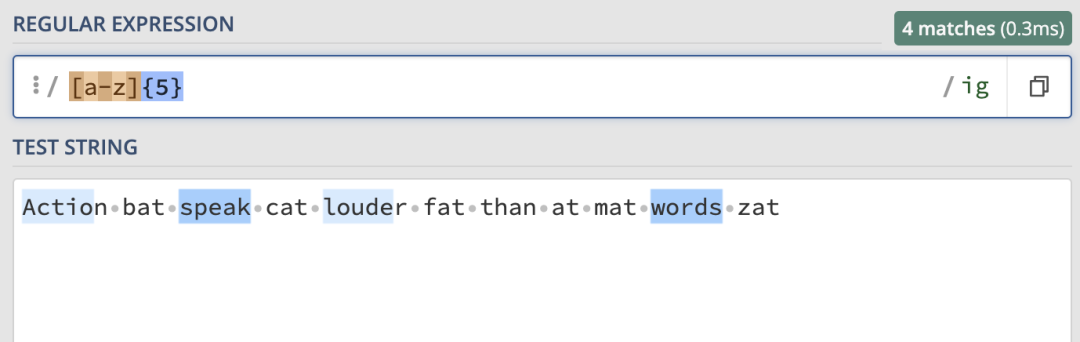
可以看到,這里我們匹配到了所有連續5個字母的單詞(包括超過5個字母的單詞,不過只會匹配到前5個字母)。
其實匹配重復字符的完整語法是這樣的:{m,n},它會匹配前面一個字符至少 m 次至多 n 次重復,{m}表示匹配 m 次,{m,}表示至少 m 次。
所以,當我們給5后面加上逗號時,就表示至少匹配五次:
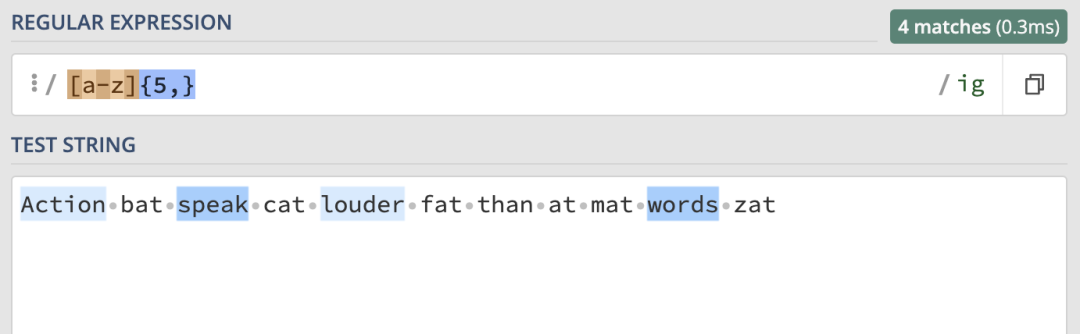 所以這里就匹配到了所有連續5個或5個以上的單詞。
所以這里就匹配到了所有連續5個或5個以上的單詞。
當匹配次數為至少4次,至多5次時,匹配結果如下:
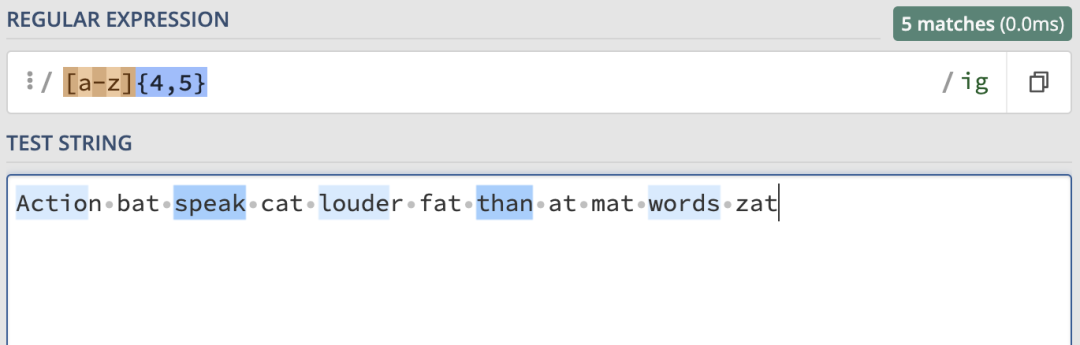
除了可以使用大括號來匹配一定數量的字符,還有三個相關的模式:
- +:匹配前面一個表達式一次或者多次,相當于 {1,};
- *:匹配前面一個表達式0次或者多次,相當于 {0,};
- ?:單獨使用匹配前面一個表達式零次或者一次,相當于 {0,1},如果跟在量詞*、+、?、后面的時候將會使量詞變為非貪婪模式(盡量匹配少的字符),默認是使用貪婪模式。
來看一個簡單的例子,這里我們匹配的正則表達式為/a+/ig,結果如下:
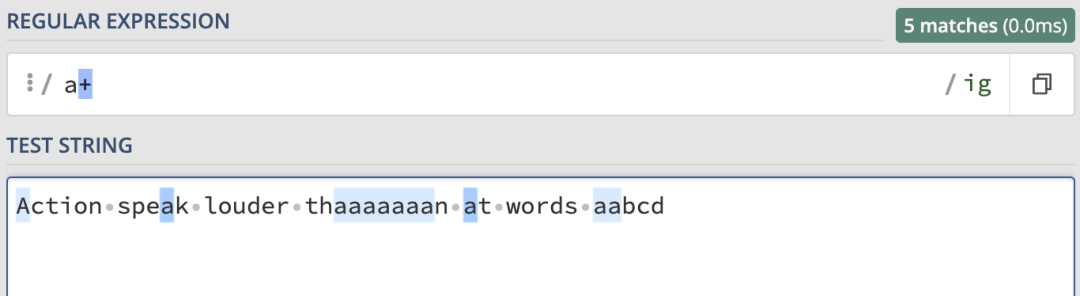
它和/a{1,}/ig的匹配結果是一樣的: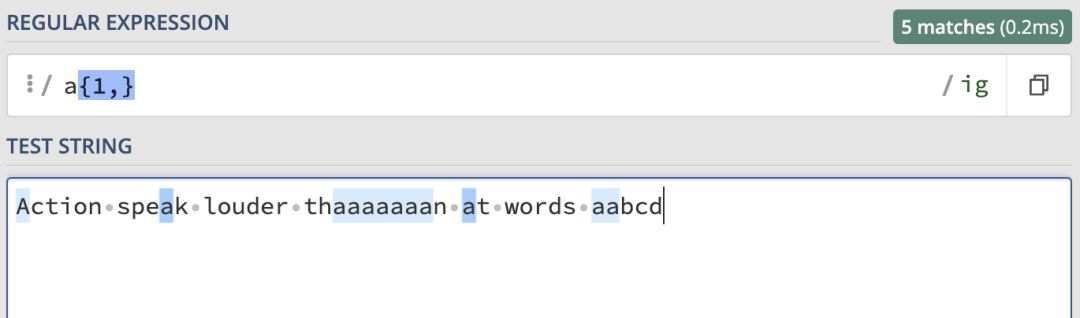 使用/[a-z]+/ig就可以匹配任意長度的純字母單詞:
使用/[a-z]+/ig就可以匹配任意長度的純字母單詞: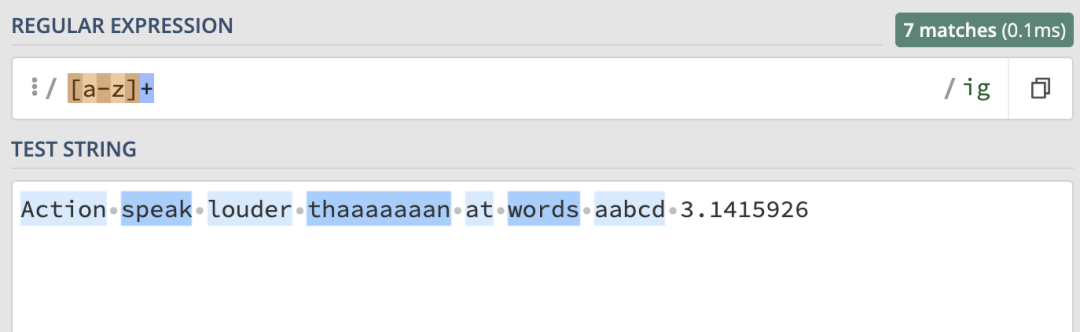
元字符
使用元字符可以編寫更緊湊的正則表達式模式。常見的元字符如下:
- \d:相當于[0-9],匹配任意數字;
- \D:相當于[^0-9];
- \w:相當于[0-9a-zA-Z],匹配任意數字、大小寫字母和下劃線;
- \W:相當于:[^0-9a-zA-Z];
- \s:相當于[\t\v\n\r\f],匹配任意空白符,包括空格,水平制表符\t,垂直制表符\v,換行符\n,回車符\r,換頁符\f;
- \S:相當于[^\t\v\n\r\f],表示非空白符。
來看一個簡單的例子:
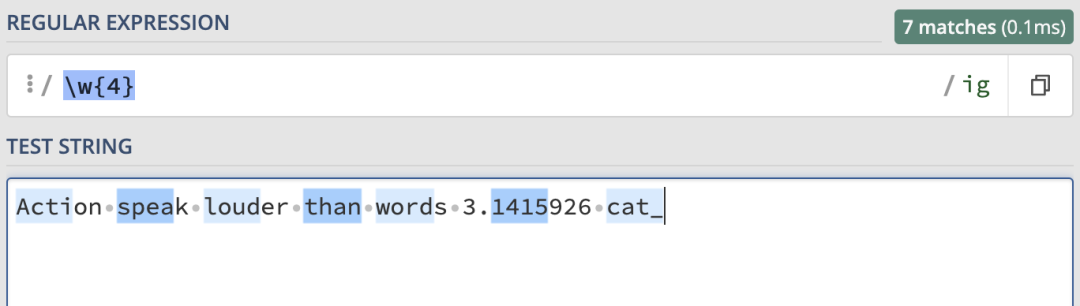 這里使用\d來匹配任意數字、字母和下劃線。這里就匹配到了7個連續四位的字符。
這里使用\d來匹配任意數字、字母和下劃線。這里就匹配到了7個連續四位的字符。
特殊字符
使用特殊字符可以編寫更高級的模式表達式,常見的特殊字符如下:
- .:匹配除了換行符之外的任何單個字符;
- \:將下一個字符標記為特殊字符、或原義字符、或向后引用、或八進制轉義符;
- |:邏輯或操作符;
- [^]:取非,匹配未包含的任意字符。
來看一個簡單的例子,如果我們使用 /ab*/ig 進行匹配,結果就如下:
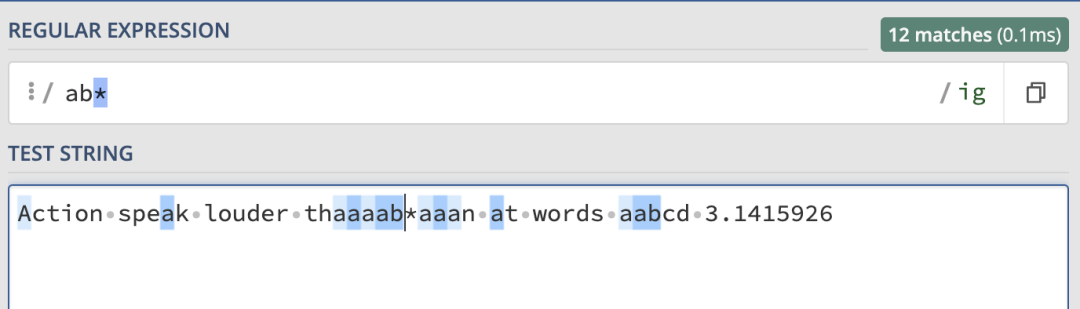
那我們就是想要匹配 * 怎么辦?就可以使用 \ 對其進行轉義:
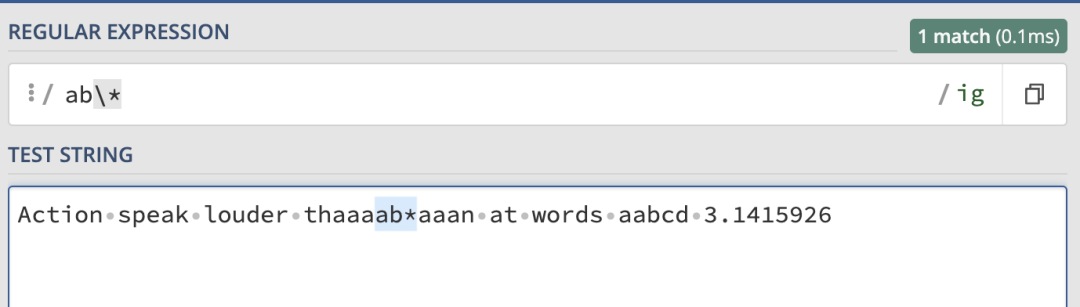
這樣就只會匹配到 ab* 了。
或匹配也很簡單,來看例子,匹配規則為:/ab|cd/ig,匹配結果如下:
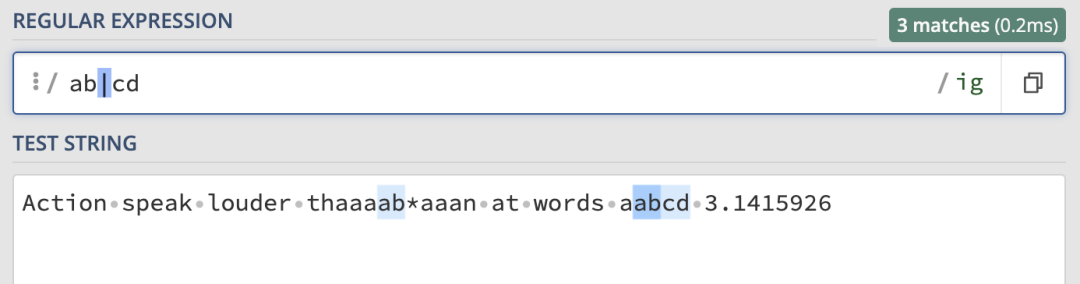
這里就會匹配到字符串中所有 ab 和 cd 字符。那如果想要匹配 sabz 或者scdz呢?開頭和結尾是相同的,只有中間的兩個字符是可選的。其實只需要給中間的或部分加上括號就可以了: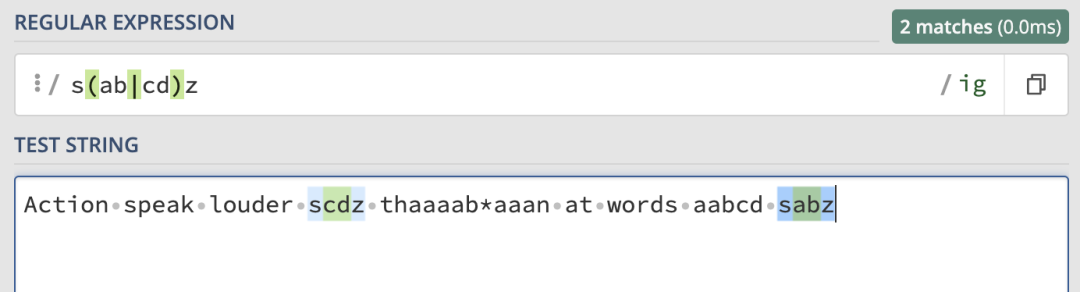 取非規則在范圍中使用,來看例子:
取非規則在范圍中使用,來看例子: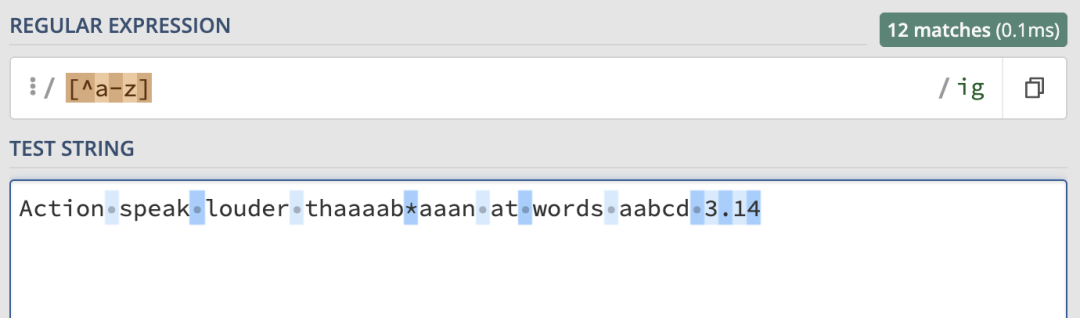 這里匹配到了所有非字母的字符。
這里匹配到了所有非字母的字符。
位置匹配
如果我們想匹配字符串中以某些字符結尾的單詞,以某些字符開頭的單詞該如何實現呢?正則表達式中提供了方法通過位置來匹配字符:
- \b:匹配一個單詞邊界,也就是指單詞和空格間的位置;
- \B:匹配非單詞邊界;
- ^:匹配開頭,在多行匹配中匹配行開頭;
- $:匹配結尾,在多行匹配中匹配行結尾;
- (?=p):匹配 p 前面的位置;
- (?!=p):匹配不是 p 前面的位置。
最常見的就是匹配開始和結束位置。先來看一個開始位置的匹配,這里使用 /^ex/igm 來匹配多行中以ex 開頭的行:
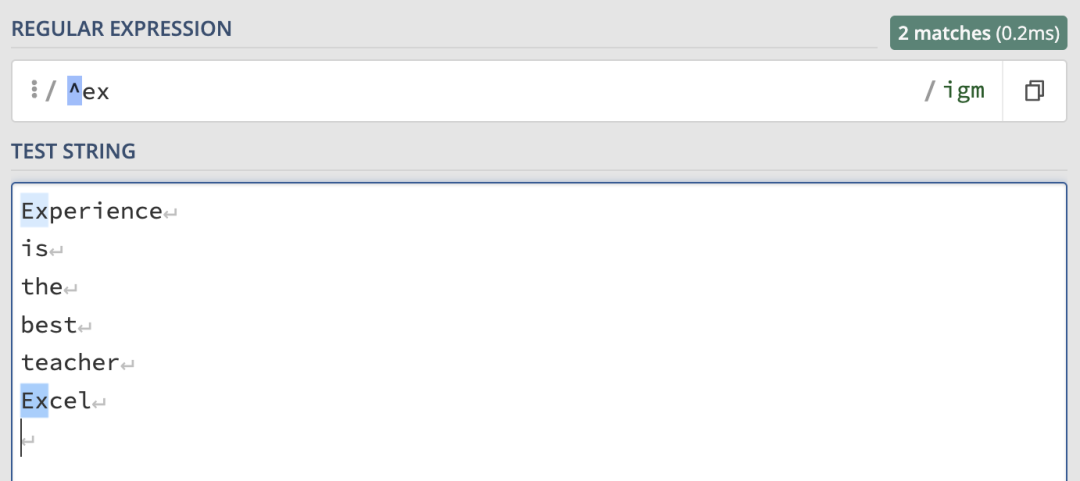
使用/e$/igm來匹配以 e 結尾的行:
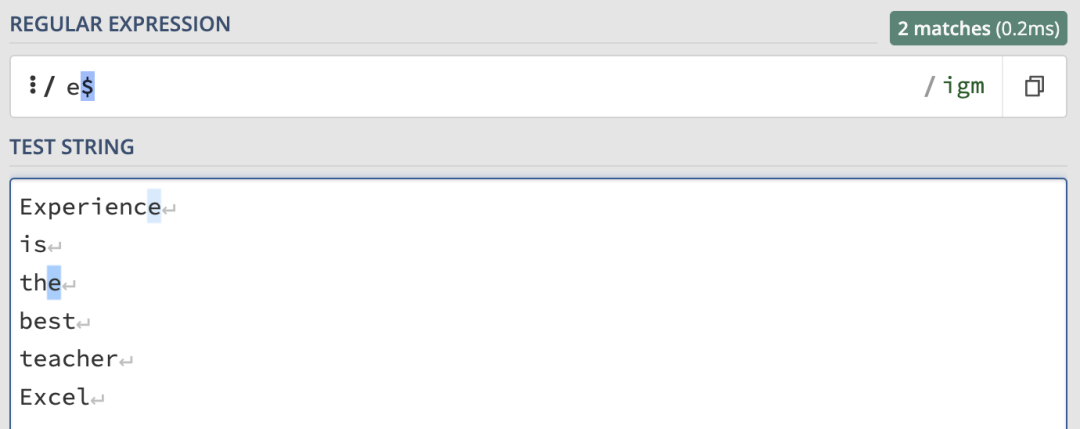
可以使用 \w+$ 來匹配每一行的最后一個單詞: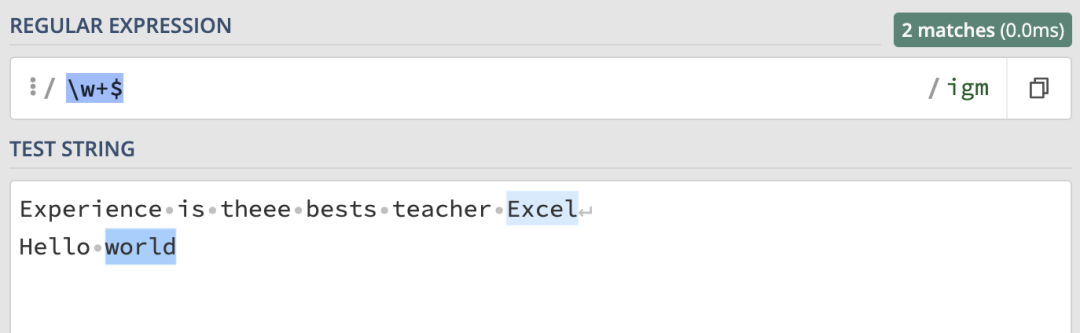 需要注意,這里我們都使用 m 修飾符開啟了多行模式。
需要注意,這里我們都使用 m 修飾符開啟了多行模式。
使用 /(?=the)/ig 來匹配字符串中the前的面的位置:

我們可以使用\b來匹配單詞的邊界,匹配的結果如下:
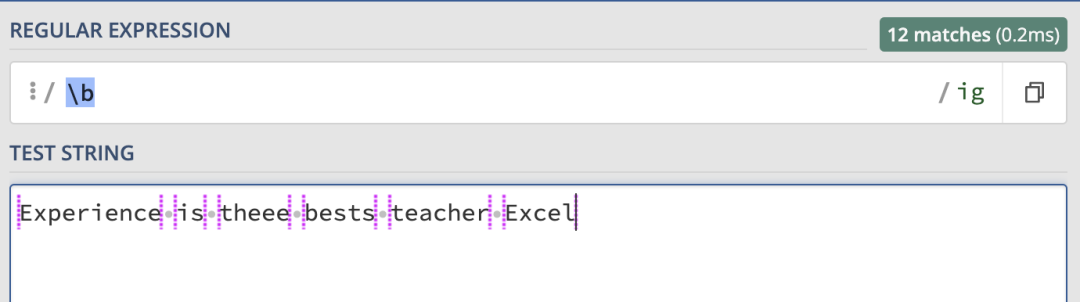
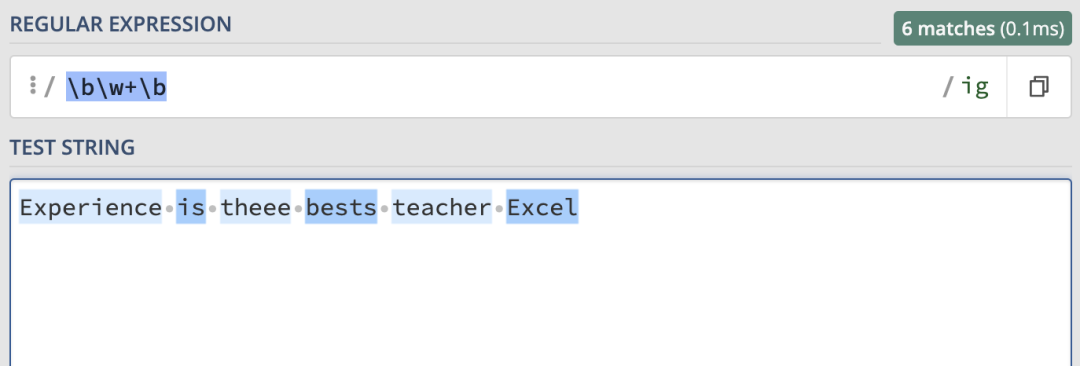
這可能比較難理解,我們可以使用以下正則表達式來匹配完整的單詞:\b\w+\b,匹配結果如下:
捕獲組
正則表達式中的“捕獲組”是指使用括號 () 將子模式括起來,以便于在搜索時同時匹配多個項或將匹配的內容單獨提取出來。組可以根據需要進行嵌套,形成復雜的匹配模式。
使用捕獲組,可以直接在正則表達式 /(Testing|tests) 123/ig 中匹配到 "Testing 123" 和 "Tests 123",而不需要重復寫 "123" 的匹配項。
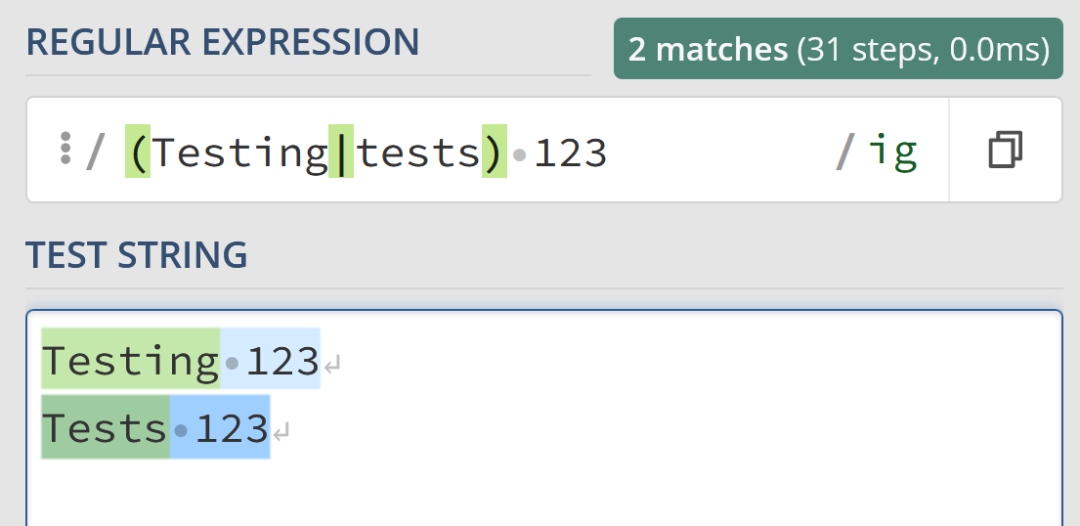
正則表達式中的兩種常見組類型:
- (...):捕獲組,用于匹配任意三個字符。
- (?:...):非捕獲組,也是用于匹配任意三個字符,但不進行捕獲。
可以使用以下 JavaScript 將文本替換為Testing 234和tests 234:
const regex = /(Testing|tests) 123/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1 234');
console.log(str);
// Testing 234
// Tests 234被括號包圍的子模式稱為“捕獲組”,捕獲組可以從匹配的字符串中提取出指定的部分并單獨使用。這里我們使用 $1 來引用第一個捕獲組 (Testing|tests)。也可以匹配多個組,比如同時匹配 (Testing|tests) 和 (123)。
const regex = /(Testing|tests) (123)/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1 #$2');
console.log(str);
// Testing #123
// Tests #123"這只適用于捕獲組。如果把上面的正則表達式變成這樣:
/(?:Testing|tests) (123)/ig;那么只有一個被捕獲的組:(123),與之前相同的代碼將輸出不同的結果:
const regex = /(?:Testing|tests) (123)/ig;
let str = `
Testing 123
Tests 123
`;
str = str.replace(regex, '$1');
console.log(str);
// 123
// 123修改后的正則表達式只有一個捕獲組 (123)。因為 (?: ) 的語法用于創建非捕獲組,所以它不會將其內容作為一個捕獲組來使用。
命名捕獲組
雖然捕獲組非常有用,但是當有很多捕獲組時很容易讓人困惑。$3 和 $5 這些名字并不是一目了然的。為了解決這個問題,正則表達式引入了“命名捕獲組”的概念。例如,(?<name>...) 就是一個命名捕獲組,名為 "name",用于匹配任意三個字符。
可以像這樣在正則表達式中使用它來創建一個名為 "num" 的組,用于匹配三個數字:
/Testing (?<num>\d{3})/然后,可以在替換操作中像這樣使用它:
const regex = /Testing (?<num>\d{3})/
let str = "Testing 123";
str = str.replace(regex, "Hello $<num>")
console.log(str); // "Hello 123"命名反向引用
有時候需要在查詢字符串中引用一個命名捕獲組,這就是“反向引用”的用武之地。
假設有一個字符串,其中包含多個單詞,我們想要找到所有出現兩次或以上的單詞。可以使用具名捕獲組和命名反向引用來實現。
const regex = /\b(?<word>\w+)\b(?=.*?\b\k<word>\b)/g;
const str = 'I like to eat pizza, but I do not like to eat sushi.';
const result = str.match(regex);
console.log(result); // like這里使用了具名捕獲組 (?<word>\w+)來匹配單詞,并將其命名為 "word"。然后使用命名反向引用 (?=.*?\b\k<word>\b) 來查找文本中是否存在具有相同內容的單詞。
前瞻組和后顧組
前瞻組(Lookahead)和后顧組(Lookbehind)是正則表達式中非常有用的工具,它們用于在匹配過程中進行條件約束,而不會實際匹配這些約束的內容。它們使得我們可以更精確地指定匹配模式。
前瞻組:
- 正向前瞻((?=...)):用于查找在某個位置后面存在的內容。例如,A(?=B) 可以匹配 "A",但只有在后面跟著 "B" 時才進行匹配。
- 負向前瞻((?!...)):用于查找在某個位置后面不存在的內容。例如,A(?!B) 可以匹配 "A",但只有在后面不跟著 "B" 時才進行匹配。
后顧組:
- 正向后顧((?<=...)):用于查找在某個位置前面存在的內容。例如,(?<=A)B 可以匹配 "B",但只有在其前面跟著 "A" 時才進行匹配。
- 負向后顧((?<!...)):用于查找在某個位置前面不存在的內容。例如,(?<!A)B 可以匹配 "B",但只有在其前面不跟著 "A" 時才進行匹配。
這些前瞻組和后顧組可以用于各種場景,例如:
- 在匹配郵箱地址時,使用正向前瞻來確保地址的結尾是以特定的域名結尾。
- 在匹配密碼時,使用正向前瞻來確保密碼滿足特定的復雜度要求。
- 在提取文本中的日期時,使用正向后顧來確保日期的前面有特定的前綴。
例如,使用負向前瞻可以匹配 BC,但不會匹配 BA。
/B(?!A)/
我們甚至可以將負向前瞻組合使用,并使用 ^ 和 $ 這些元字符來嘗試匹配完整的字符串。例如,以下的正則表達式將匹配任何不以 "Test" 開頭的字符串:
/^(?!Test).*$/gm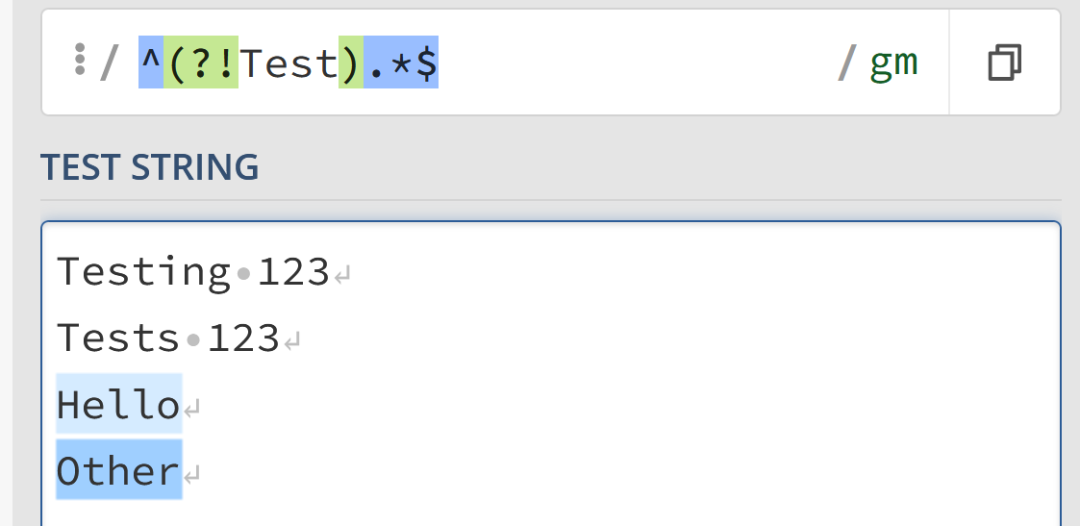
這個正則表達式可以匹配 Hello 和 Other,但無法匹配 Testing 123 和 Tests 123。
同樣,可以將其切換為正向前瞻,以強制字符串必須以“Test”開頭:
/^(?=Test).*$/gm
字符串方法
在 JavaScript 內置了 6 個常用的方法是支持正則表達式的,下面來分別看看這些方法。
search()
search() 方法用于檢索字符串中指定的子字符串,或檢索與正則表達式相匹配的子字符串,并返回子串的起始位置。如果沒有找到任何匹配的子串,則返回 -1。
const regex1 = /a/ig;
const regex2 = /p/ig;
const regex3 = /m/ig;
const str = "Action speak louder than words";
console.log(str.search(regex1)); // 輸出結果:0
console.log(str.search(regex2)); // 輸出結果:8
console.log(str.search(regex3)); // 輸出結果:-1可以看到,search() 方法只會返回匹配到的第一個字符的索引值,當沒有匹配到相應的值時,就會返回-1。
match()
match() 方法可在字符串內檢索指定的值,或找到一個或多個正則表達式的匹配。如果沒有找到任何匹配的文本, match() 將返回 null。否則,它將返回一個數組,其中存放了與它找到的匹配文本有關的信息。
const regex1 = /a/ig;
const regex2 = /a/i;
const regex3 = /m/ig;
const str = "Action speak louder than words";
console.log(str.match(regex1)); // 輸出結果:['A', 'a', 'a']
console.log(str.match(regex2)); // 輸出結果:['A', index: 0, input: 'Action speak louder than words', groups: undefined]
console.log(str.match(regex3)); // 輸出結果:null可以看到,當沒有 g 修飾符時,就只能在字符串中執行一次匹配,如果想要匹配所有符合條件的值,就需要添加 g 修飾符。
matchAll()
matchAll() 方法返回一個包含所有匹配正則表達式的結果及分組捕獲組的迭代器。因為返回的是遍歷器,所以通常使用for...of循環取出。
for (const match of 'abcabc'.matchAll(/a/g)) {
console.log(match)
}
//["a", index: 0, input: "abcabc", groups: undefined]
//["a", index: 3, input: "abcabc", groups: undefined]需要注意,該方法的第一個參數是一個正則表達式對象,如果傳的參數不是一個正則表達式對象,則會隱式地使用 new RegExp(obj) 將其轉換為一個 RegExp 。另外,RegExp必須是設置了全局模式g的形式,否則會拋出異常 TypeError。
replace()
replace() 用于在字符串中用一些字符串替換另一些字符串,或替換一個與正則表達式匹配的子串。
const regex = /A/g;
const str = "Action speak louder than words";
console.log(str.replace(regex, 'a')); // 輸出結果:action speak louder than words可以看到,第一個參數中的正則表達式匹配到了字符串的第一個大寫的 A,并將其替換為了第二個參數中的小寫的 a。
replaceAll()
replaceAll() 方法用于在字符串中用一些字符替換另一些字符,或替換一個與正則表達式匹配的子串,該函數會替換所有匹配到的子字符串。
const regex = /a/g;
const str = "Action speak louder than words";
console.log(str.replaceAll(regex, 'A')); // 輸出結果:Action speAk louder thAn words需要注意,當使用一個 regex 時,您必須設置全局("g")標志, 否則,它將引發 TypeError:"必須使用全局 RegExp 調用 replaceAll"。
split()
split() 方法用于把一個字符串分割成字符串數組。其第一個參數是一個字符串或正則表達式,從該參數指定的地方分割字符串。
const regex = / /gi;
const str = "Action speak louder than words";
console.log(str.split(regex)); // 輸出結果:['Action', 'speak', 'louder', 'than', 'words']這里的 regex 用來匹配空字符串,所以最終在字符串的每個空格處將字符串拆成了數組。
七、應用場景
上面介紹了正則表達式的用法,下面就來看看正則表達式的實際應用場景。
數據驗證
數據驗證應該是正則表達式最常見的場景了,經常用于用戶的輸入是否符合所需的條件。數據驗證可確保輸入或導入的數據準確、一致,并符合預定義的規則。
驗證手機號:
const phoneNumber = "13712345678";
const regex = /^1[3-9]\d{9}$/;
console.log("手機號格式正確:", regex.test(phoneNumber));驗證郵箱:
const email = "example@example.com";
const regex = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;
console.log("電子郵件格式正確:", regex.test(email));驗證密碼(要求:至少包含一個數字,一個字母,一個特殊字符,長度在8~18之間):
const password = "Abcdef.123";
const regex = /^(?=.*\d)(?=.*[a-zA-Z])(?=.*[\W_]).{8,18}$/;
console.log("密碼格式正確:", regex.test(password))驗證輸入內容不能包含 emoji 表情:
function hasEmoji(str) {
const emojiRegex = /[\uD800-\uDFFF]|[\u2600-\u27FF]|[\u1F000-\u1F9FF]/g;
return emojiRegex.test(str);
}
// 測試樣例
const text1 = 'Hello, world!';
const text2 = '你好,??!';
console.log(hasEmoji(text1)); // false
console.log(hasEmoji(text2)); // true搜索和替換
搜索和替換是正則表達式的很常見的用例。它允許查找文本中的特定模式并將其替換為所需的內容。
筆者之前做個一個需求:
- 獲取 HTML 字符串中所有圖片,也就是獲取所有 img 標簽的 src 屬性值,這個需求屬于數據提取,第三部分會講到;
- 將獲取到的圖片轉灰度圖,轉灰度成功的圖片的名稱會加一個-gray后綴,將這個圖片替換 HTML 原來的圖片。也就將轉換成功的圖片的src地址加-gray后綴。
灰度圖替換:
const grayImgReplace = (html: string, imgUrl: string) => {
const regex = /(https?:\/\/[^\s"']+\.[^\s"']+(?<!-gray))\.(jpg|jpeg|png)/;
const match = regex.exec(html);
if (match) {
return html.replace(match[0], `${imgUrl}`);
}
return html;
};注意:這里僅替換一張圖,若需要替換多張,每個圖片都執行該方法即可。
另一個例子就是在 IDE 中進行正則表達式搜索和替換操作。比如,在 VS Code 中,只需在搜索欄中點擊搜索欄左側的正則表達式按鈕(.*)或按下快捷鍵 Alt + R,就可以激活正則表達式搜索模式。
比如,有一個動態接口路徑:/app/api/:modal/list,想要看看哪些地方調用了這個接口。這個路徑中間的 modal 是動態的,沒辦法直接通過字符串進行搜索,怎么辦呢?可以借助正則表達式輕松實現:
\/app\/api\/([^\/]+)\/list不管 modal 是什么,都可以輕松搜索到:

除此之外,還可以通過搜索替換輕松實現數據的格式化。例如,將數字轉換為貨幣格式:
const formatMoney = (money) => {
return money.replace(new RegExp(`(?!^)(?=(\\d{3})+${money.includes('.') ? '\\.' : '$'})`, 'g'), ',')
}
formatMoney('123456789') // '123,456,789'
formatMoney('123456789.123') // '123,456,789.123'
formatMoney('123') // '123'數據提取
數據提取是正則表達式的另一個常見用例。正則表達式使我們能夠根據定義的模式從較大的文本中有效地提取特定信息。
上面提到了從 HTML 字符串中獲取所有圖片 URL 的需求,下面來實現一下:
const getImgs = (domContent) => {
const imgs = [];
const imgPattern = /<img[^>]+src=['"]((?!.*\.svg).+?)['"]/g;
let match = null;
while ((match = imgPattern.exec(domContent)) !== null) {
imgs.push(match[1]);
}
return imgs;
};再比如,獲取所有 a 標簽鏈接,也就是獲取 href 屬性值:
const html = '<a >Link 1</a> <a >Link 2</a>';
// 使用正則表達式提取 <a> 標簽鏈接
const linkRegex = /<a\s+(?:[^>]*?\s+)?href=(["'])(.*?)\1/g;
const links = [];
let match;
while ((match = linkRegex.exec(html)) !== null) {
const link = match[2];
links.push(link);
}
console.log(links);輸出結果如下:
[
'https://www.example.com',
'https://www.google.com'
]再比如,提取 URL 中的域名:
const url = 'https://www.example.com/path/to/page?param1=value1?m2=value2#section';
const domainRegex = /https?:\/\/([\w.-]+)/;
const match = url.match(domainRegex);
const domain = match && match[1];
console.log(domain); // www.example.com數據清洗
通過適當使用正則表達式,可以輕松地從文本數據中查找、匹配和替換特定的模式和字符,從而對數據進行清理和預處理。以下是一些常見的數據清洗任務,可以使用正則表達式來完成:
- 移除多余空格:使用正則表達式將連續的多個空格或制表符替換為單個空格,或者完全移除所有空格。
- 格式化日期:使用正則表達式解析和提取日期字符串,并將其格式化為指定的格式或日期對象。
- 清除特殊字符:使用正則表達式從文本數據中移除不需要的特殊字符和標點符號,例如 emoji 表情符號、HTML 標簽、URL 等。
- 提取信息:使用正則表達式從文本數據中提取特定的信息,例如電話號碼、郵件地址、IP 地址等。
- 替換錯誤或不一致的數據:使用正則表達式查找和替換文本數據中的錯誤拼寫、大小寫、顛倒順序等問題,使得數據更加一致和規范化。
比如,刪除字符串中的標簽和 emoji 表情:
const text = 'Hello, <b>world</b>! ??';
const cleanText = text.replace(/<\/?[^>]+(>|$)/g, '').replace(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g, '');
console.log(cleanText); // Hello, world!這里使用了兩個正則表達式替換操作:
- /<\/?[^>]+(>|$)/g:這個正則表達式用于匹配并移除 HTML 標簽。它會匹配尖括號內的任何內容,并將其替換為空字符串。
- /[\uD800-\uDBFF][\uDC00-\uDFFF]/g:這個正則表達式用于匹配并移除 emoji 表情符號。由于 emoji 符號采用 Unicode 編碼的多個字符表示,我們使用這個正則表達式匹配并移除這些字符。
八、實用工具
Regex101
Regex101 是學習正則表達式最有效的工具網站之一,本文的示例使用的就是這個工具。在REGULAR EXPRESSION欄中可以輸入正則表達式,可以在輸入框右側選擇需要的修飾符,在下面的TEST STRING欄中輸入要測試的字符串,即可顯示出匹配到的結果。在右側的EXPLANATION區域會顯示出對輸入的正則表達式的詳細解釋。右下角的 QUICK REFERENCE 欄會顯示正則表達式速查表。
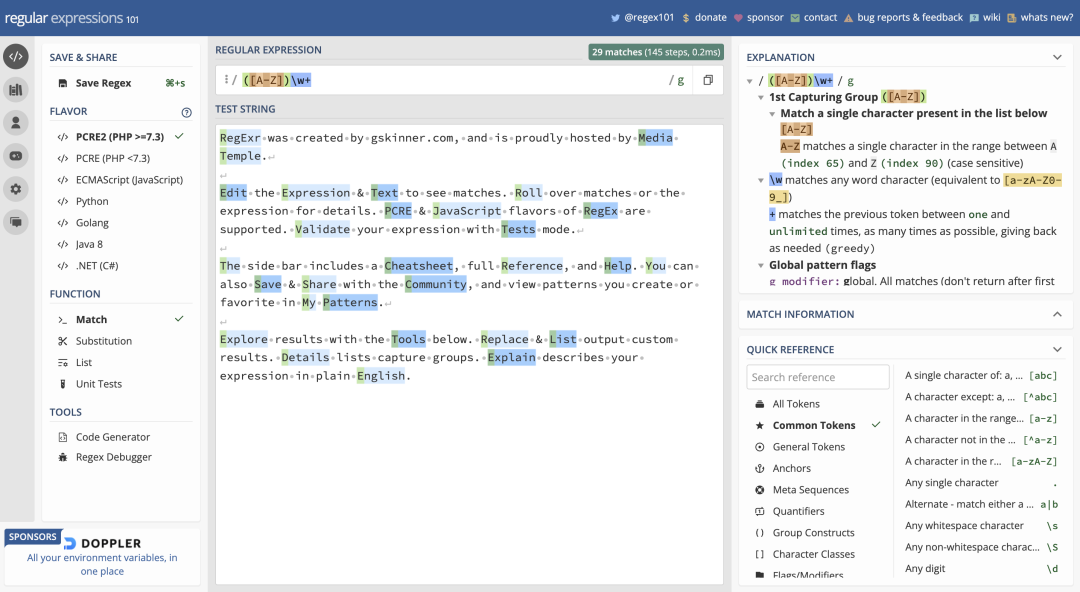
Regex101 還支持在上面練習編寫正則表達式:

可以在上面搜索一些正則表達式的庫:
除此之外,我們還可以使用 RegexDebugger 來跟蹤匹配的過程。更多功能可以在Regex101 上進行探索。
官網:https://regex101.com/
RegExr
RegExr 是一個基于 JavaScript 開發的在線工具,用來創建、測試和學習正則表達式。它是一個開源的工具,具有以下特性:
- 輸入時,結果會實時更新;
- 支持 JavaScript 和 PHP/PCRE RegEx;
- 將匹配項或表達式移至詳細信息;
- 保存并與他人共享表達式;
- 使用工具探索結果;
- 瀏覽參考以獲取幫助和示例;
- 在編輯器中使用 cmd-Z/Y 撤消和重做。
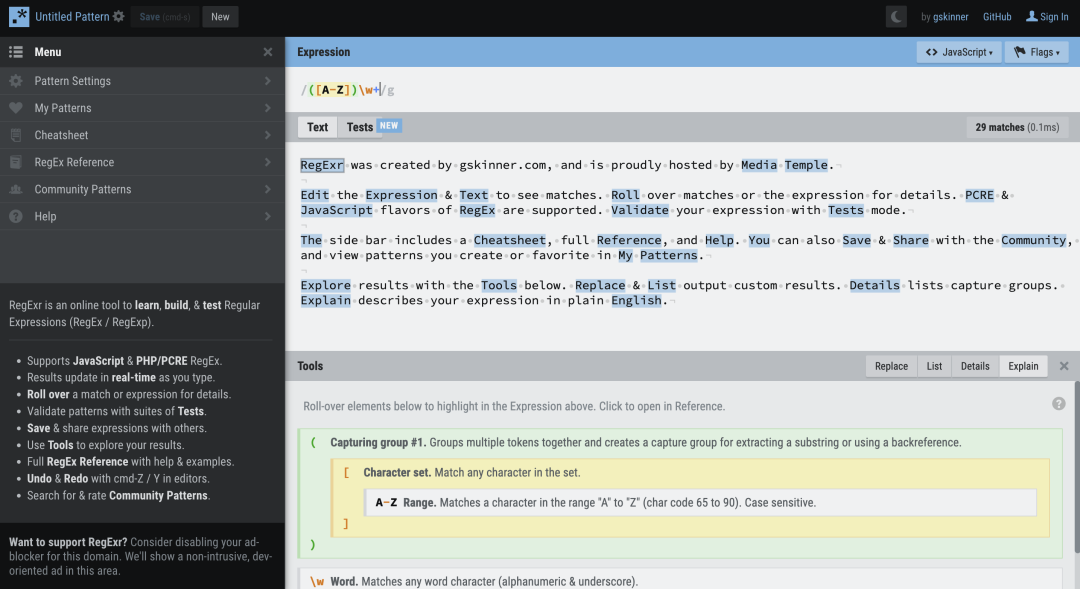
官網:https://regexr.com/
Regex Pal
Regexpal 是一個基于 Javascript 的在線正則表達式驗證工具。它的頁面非常簡潔,只有兩個輸入框,上面的輸入框中可以輸入正則表達式(匹配規則),下面的輸入框可以輸入待匹配的數據。此外,根據具體要求,還可以設置忽略大小寫、多行匹配等參數。

官網:https://www.regexpal.com/
Regex-Vis
Regex-Vis 是一個輔助學習、編寫和驗證正則的工具。它不僅能對正則進行可視化展示,而且提供可視編輯正則的能力。在輸入一個正則表達式后,會生成它的可視化圖形。然后可以點選或框選圖形中的單個或多個節點,再在右側操作面板對其進行操作,具體操作取決于節點的類型,比如在其右側插入空節點、為節點編組、為節點增加量詞等。

官網:https://regex-vis.com/
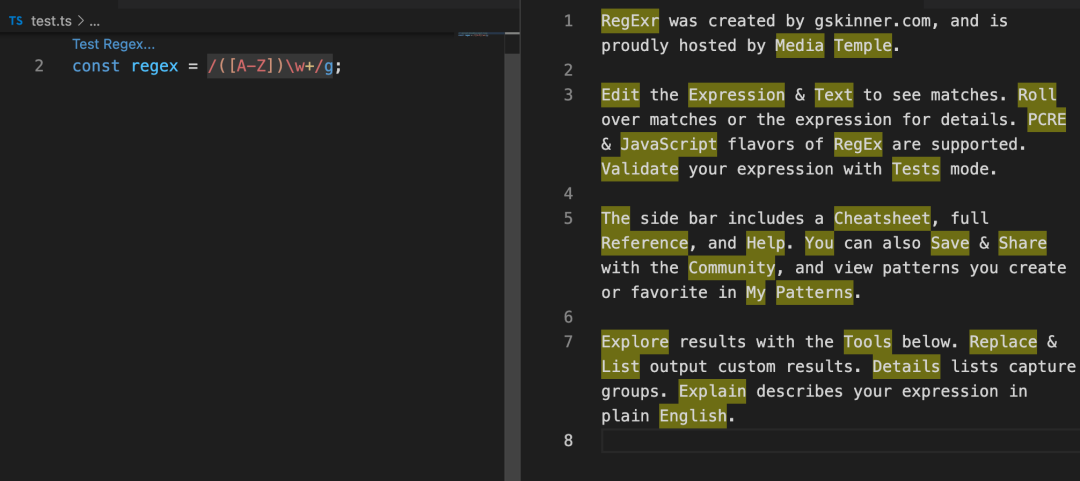
Regex previewer
Regex previewer 是一個 VScode 插件,在插件市場搜索名稱即可安裝。當我們在編寫正則表達式時,可以直接使用快捷鍵 Ctrl+Alt+M (windows)或者 ?+?+M(Mac)在編輯器右側啟動一個標簽頁,我們可以在這個標簽頁寫一寫測試用例,用來測試我們寫的正則表達式,寫完字符串用例之后,點擊我們編寫的正則表達式上方的 Test Regex...即可,這樣右側匹配到字符就會高亮顯示了,如下圖: